핑퐁팀과 함께하는 ACL 2020 리뷰
ACL 2020에 발표되었던 논문들을 추려서 리뷰해보았습니다.








Annual Meeting of the Association for Computational Linguistics (ACL)는 자연어 처리(NLP) 분야를 주도하는 주요 국제 컨퍼런스 중 하나로, 매년 많은 NLP 연구자들이 주목하는 학회입니다. 이번 ACL 2020은 COVID-19로 인해서 여타 다른 학회들처럼 온라인 형식으로 진행되었습니다. 이에 핑퐁팀은 메인 컨퍼런스가 진행되는 일정(7월 6~8일)에 다같이 모여 서로 관심 있는 발표들을 시간마다 나누어가며 들어보았습니다.
학회에서 보고 들었던 논문들 중 팀원 별로 관심있어 하는 논문을 각자 세 편씩을 선정하였고, 그 논문들을 간단히 리뷰 형태로 정리해보았습니다. 그 내용을 여러분께 공유드리려 합니다. 또한 주홍님이 roomylee/ACL-2020-Papers에 올려주신 시각화 자료를 기반으로, 이번 학회의 키워드, 주제, 게재 비율 등을 분석한 내용을 첨부하오니, 학회 논문을 참고하시는 여러분들께 도움이 되면 좋겠습니다.
학회 추이
합격률 추이
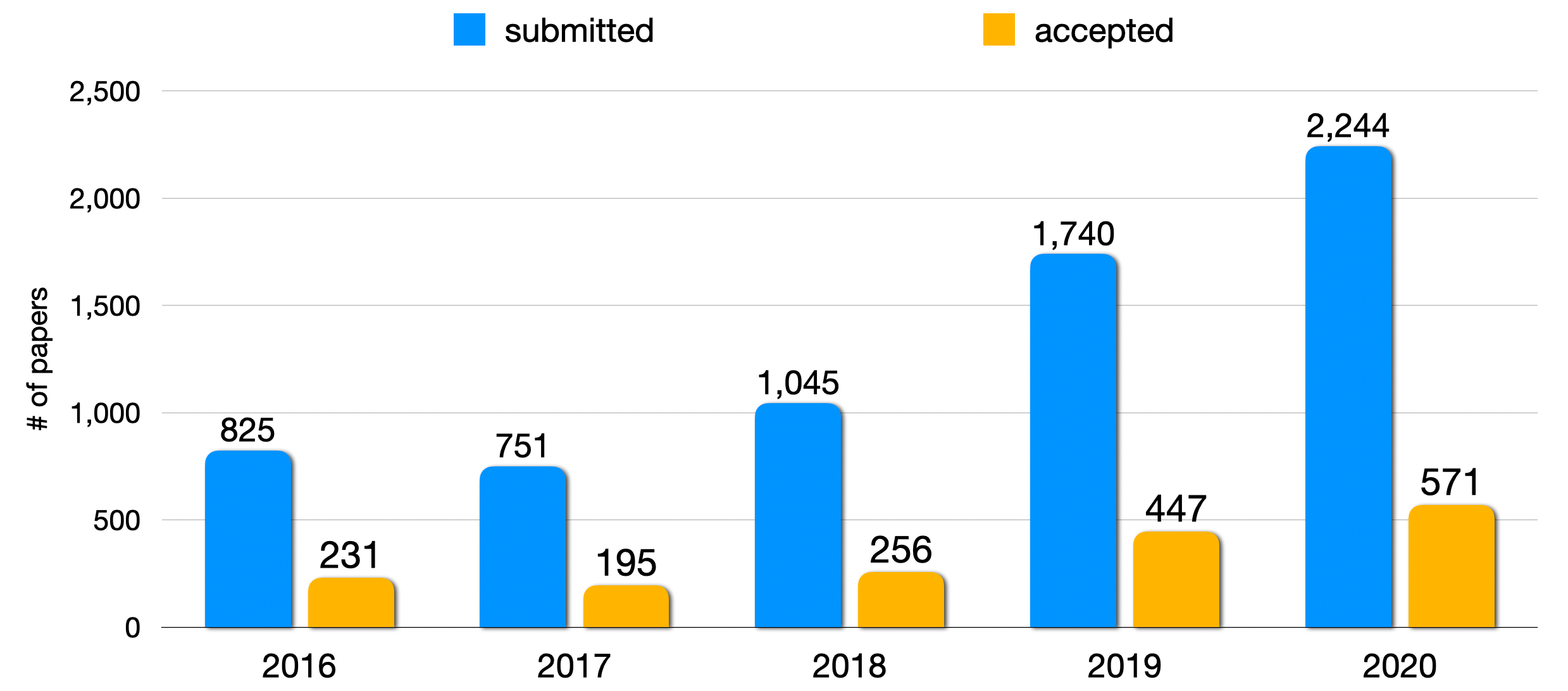
금년도에 제출된 논문 수는 최초로 2000편을 넘긴 2244편이었으며, 이는 2016년에 비해서는 약 2.7배 증가한 수치입니다. 작년에 비해서는 약 29% 증가하였는데, 제출되는 논문의 수가 꾸준히 증가하고 있는 것을 보며 NLP 분야의 관심도가 날이 갈수록 높아짐을 체감할 수 있었습니다. Acceptance Rate는 작년이 25.68%, 올해는 25.44% 으로 작년과 거의 동일한 비율을 유지하였습니다. EMNLP 역시 약 25% 정도의 Acceptance Rate 유지하면서, 두 학회 모두 퀄리티를 보장하기 위해서 엄격한 심사 기준을 유지하고 있음을 알 수 있습니다.
키워드로 보는 학회 추이
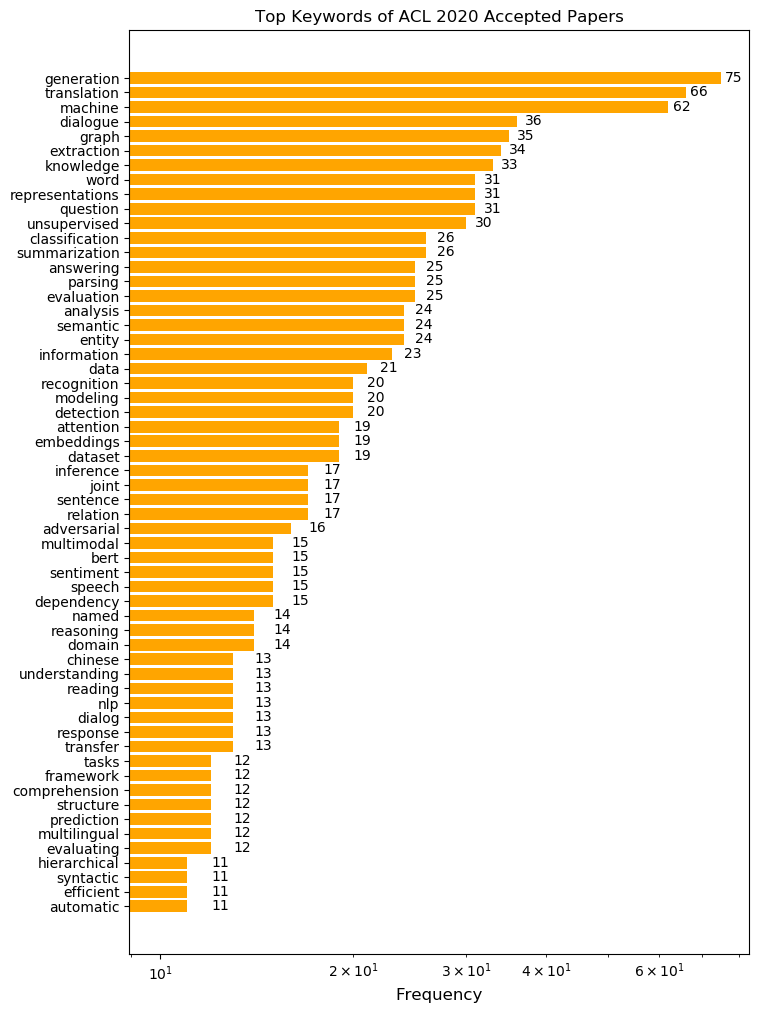
이번 ACL2020의 트렌드를 간접적으로 파악해 보고자, 논문 제목에 나타난 단어를 빈도순으로 나타내 보았습니다. 특정 태스크에 관련된 단어부터 방법론과 관련된 단어까지 다양한 키워드가 흥미를 이끄는데요, 그 중 이번 ACL에서 특히 주목할 만한 키워드를 네 가지만 살펴 보겠습니다.
Generation
가장 많이 사용된 키워드는 ‘Generation’ (생성)입니다. EMNLP-IJCNLP 2019 프리뷰에서 키워드 분석을 진행해 보았을 때와 동일하게 1위를 차지했는데요, 특히 다른 키워드에 비해서 압도적으로 빈도가 높다는 점도 주목해 볼만 합니다. 최근의 GPT-3나 Meena 등 파라미터가 엄청나게 많은 Transformer 계열들이 괄목할만한 성능을 보여주고 있는데, 이런 추세를 반영하듯 많은 연구자들이 기존에 하지 못했던 생성과 관련된 연구에 집중하고 있는 것을 알 수 있습니다.
Translation
생성의 뒤를 이어서, ‘Translation’ (번역)이 2위를 차지했습니다. 사실 번역은 수요도 많이 있었고 연구할만한 문제들도 많이 있었기 때문에 늘 인기가 있었던 주제입니다. NLP 연구 주제의 집약체같은 느낌입니다. 다만 역시 번역 또한 생성과 밀접하게 연관되어 있는 주제다보니, 위에서 말씀드렸던 거대 Transformer 들의 등장이 영향을 주었을거라 생각합니다.
Dialogue
이번 키워드 통계에서 주목할 수 있는 부분은 Dialogue (대화)의 급부상입니다. 지난 EMNLP 2019에서 대화 키워드는 굉장히 낮은 순위에 위치해 있었습니다. 하지만 이번 ACL 2020에서는 전체 키워드 빈도에서 Dialogue 키워드는 전체에서 4위를 차지하였습니다. 특히 작년과 올해 generation을 기반으로 하는 일상 대화 모델들이 많이 공개 되었는데 이런 경향들이 반영된 것이 아닌가 합니다. 이 분야 연구에 매진하는 핑퐁팀으로서는 대화와 관련된 연구들이 이전보다 활발하게 이루어진다는 것이 기쁩니다.
Graph
마지막으로 5위를 차지한, ‘Graph’ (그래프)입니다. 역시 대화와 마찬가지로 지난번 EMNLP 2019 때보다 순위가 많이 상승한 것을 확인할 수 있었습니다. 이를 통해 NLP 분야에서도 그래프를 기반으로 하는 모델들에 대한 연구가 지속적으로 발전하고 있음을 알 수 있습니다. 사실 그래프라는 것은 결국 관계를 수치화한 것이니까요.
논문 Review
총 24편의 논문을 abstract와 핵심 figure를 기반으로 간략하게 리뷰해 보았습니다.
DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering
저자: Qingqing Cao, Harsh Trivedi, Aruna Balasubramanian, Niranjan Balasubramanian (Stony Brook University)
키워드: Sentence Representation
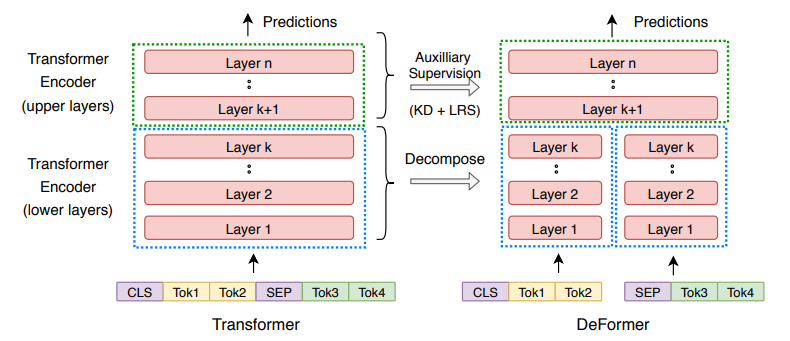
- 기존의 Transformer 기반 QA 모델은 쿼리와 답변 후보를 하나의 입력으로 간주하였습니다. 이 Cross-encoder 방식은 성능은 높으나 느리고 비효율적입니다.
- 논문의 저자들은 쿼리와 답변 후보 간의 상호작용을 나타내기 위해서 모든 Attention Layer가 필요한 것은 아니라고 지적합니다. 아울러 각 레이어의 결과물들의 분산이 후반 Layer로 갈수록 더 증가하는 것을 발견했습니다. 즉, 전반 Layer (하위 Layer)들은 문장의 통사/의미 정보를 추출하는 것에 집중되어있으며 후반 Layer (상위 Layer)들은 세부 Task를 푸는 것에 집중되어있다는 것입니다.
- 따라서 전반부 Layer는 별도의 입력으로 간주하고 후반부 Attention Layer를 공유하는 구조를 고안하고, 이를 Similarity Loss와 Task-specific Loss 그리고 Knowledge Distillation Loss로 학습시켰습니다. 중간 입력을 Decompose하기 때문에 논문의 구조는 Deformer가 되었습니다.
Logical Natural Language Generation from Open-Domain Tables
저자: Wenhu Chen, Jianshu Chen, Yu Su, Zhiyu Chen, William Yang Wang (University of California, Santa Barbara., Tencent AI Lab and Ohio State University)
키워드: Generation, Surface Realization
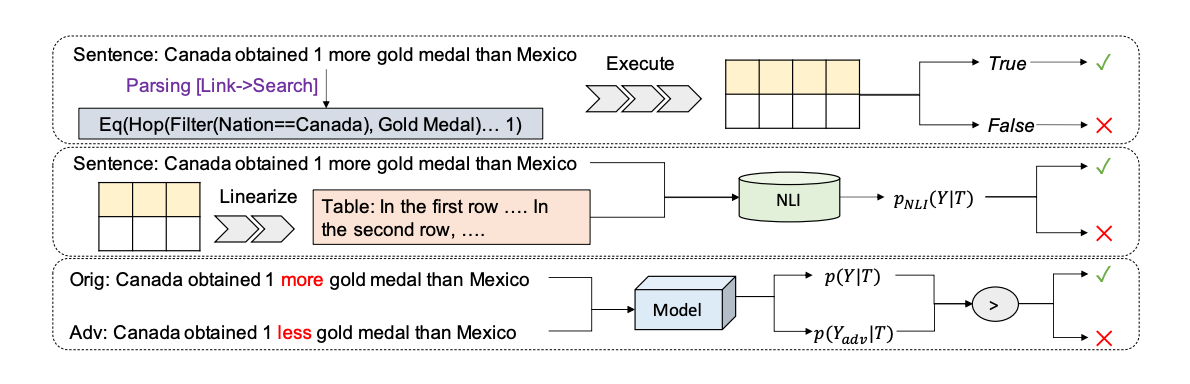
- Generation의 중요한 부분은 표면화 (Surface Realization)입니다. 지금까지의 표면화는 주로 데이터 자체를 나타내는 작업에 집중되었습니다.
- 저자들은 논리적으로 유도된 문장을 만드는 작업을 제안합니다. 저자들은 실제 사용자들이 표면적인 문장으로부터 논리적으로 추론되는 문장을 만들어 낼 수 있기 때문에, 조금 더 도전적이고 모델의 성능을 잘 표현할 수 있는 Task라고 생각하였습니다.
- 기존의 IE 기반 Evaluation은 한계가 있으므로, Parsing 기반 방법(문장의 결과를 다시 Parsing해서 원 데이터 Table과 일치하는지 확인하기), NLI 기반 방법(주어진 테이블과 모순된 문장인지 확인하기)과 Adversarial Method 기반 Auto Evaluation 방법(일부 단어를 반대로 바꾼 후, 원 문장과 비교하기)을 새로 제안하였습니다.
“None of the Above”: Measure Uncertainty in Dialog Response Retrieval
저자: Yulan Feng, Shikib Mehri, Maxine Eskenazi, Tiancheng Zhao (Carnegie Mellon University and SOCO.AI)
키워드: Dialog Response Retrieval, Uncertainty
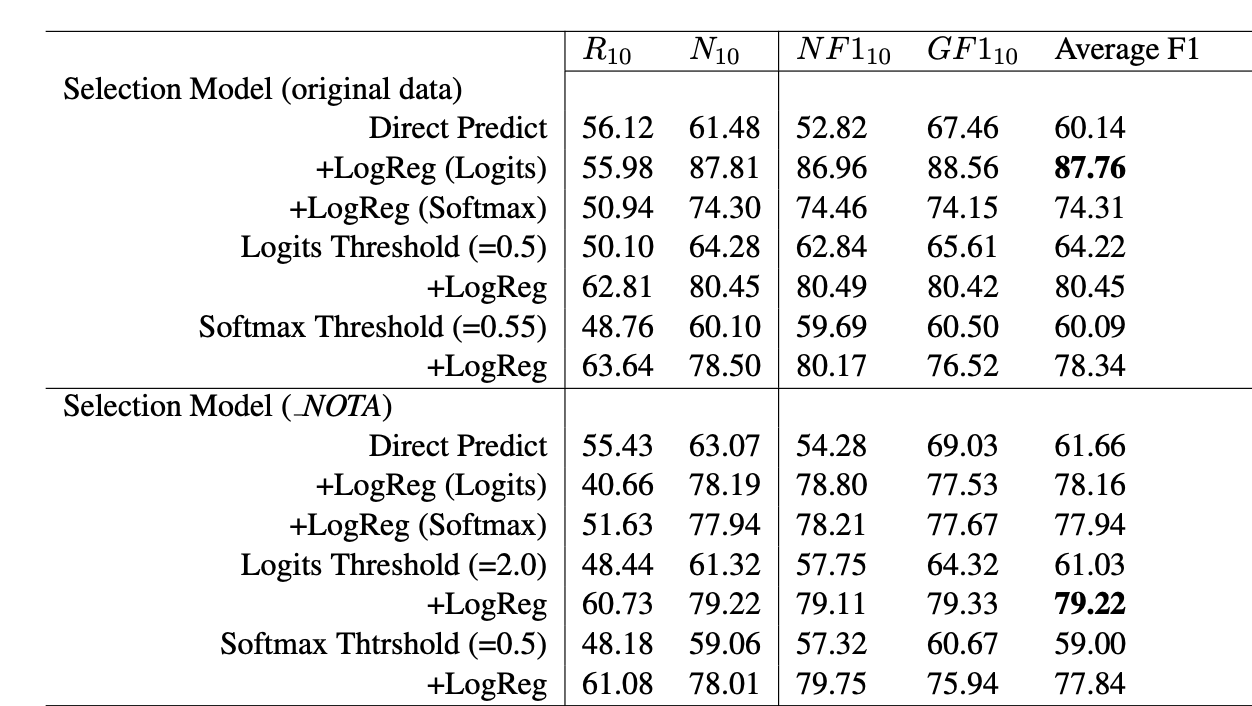
- 일반적으로 대화 시스템은 사용자의 말에 대해서 응답 후보군들을 만들고 그 중에서 가장 좋은 응답을 선택합니다. 본 논문에서는 모든 응답 후보군이 마땅하지 않은 경우 (보기에 없음, None of the above: NOTA)가 존재하며 문제가 될 수 있다고 주장합니다.
- 본 논문에서 NOTA를 검증하는 방법으로 직접 NOTA 레이블을 예측하는 방법, 1-best가 특정 Threshold를 넘지 못하면 NOTA로 간주하는 방법, 응답 Layer에 Logistic Regression Layer를 하나 더 두어 logit 값이 0.5를 넘지 못하면 NOTA로 판정하는 방법을 제시합니다.
- 이를 검증하기 위해 Ubuntu Dialog Corpus로 응답 선택기를 훈련하여, 임의의 정답을 NOTA로 치환한 후 그 결과를 확인하였습니다. 실험 결과 Logistic Regression Layer를 둔 방법이 가장 NOTA를 잘 검출하는 것으로 확인되었습니다.
Efficient Dialogue State Tracking by Selectively Overwriting Memory
저자: Sungdong Kim, Sohee Yang, Gyuwan Kim, Sang-Woo Lee (Clova AI and Naver Corp.)
키워드: Dialog State Tracking (DST), State Operation Predictor
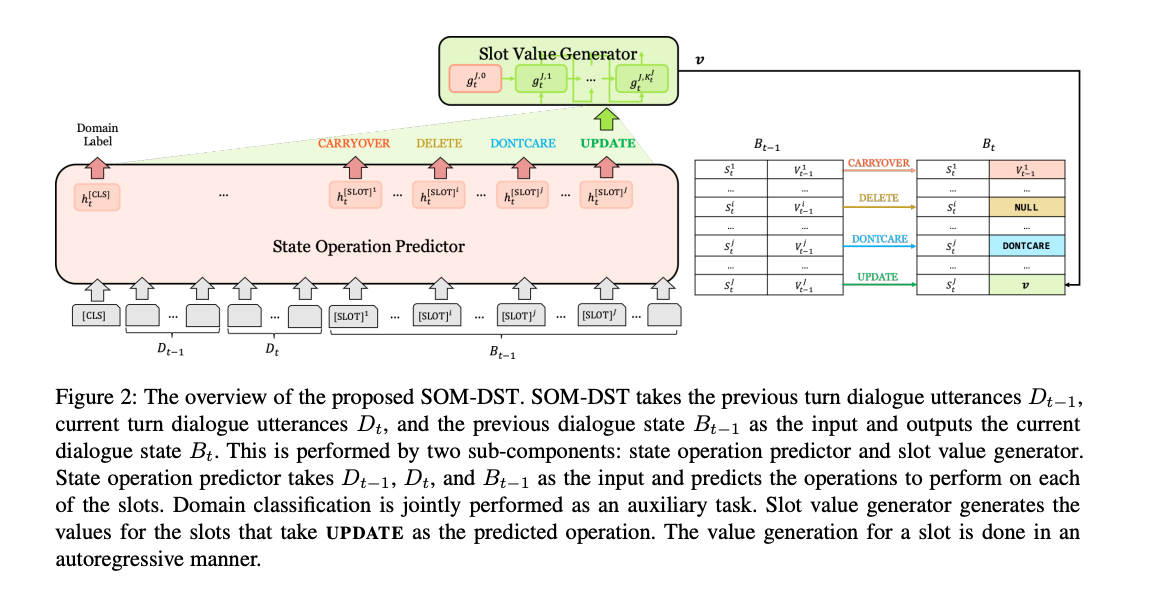
- Dialog State Tracking에서 최근 연구는 확장성의 한계 때문에 open vocabulary 세팅으로 문제를 푸는 것에 집중해왔습니다. 그러나 기존 연구들은 매 턴마다 dialogue state를 예측하는 데 충분한 성능을 보이지 않았습니다.
- 본 논문에서는 Dialog state를 고정된 사이즈의 메모리로 생각하고, 선택적으로 덮어쓰는 방식(selectively overwriting)의 효율적인 DST 방법을 새로 제안하였습니다.
- 이 방법은 총 2가지 스텝으로 나누어져 있습니다.
- state operation을 각 메모리 슬롯에 대해서 예측합니다.
- 예측된 state operation에 따라서 몇 개의 소수 메모리에만 새 값을 덮어 씌웁니다.
- 이 방법은 DST를 총 2가지 subtask로 분리하였고, decoder가 한 가지의 태스크에만 집중하게 해서 디코더가 많은 일을 하지 않아도 되도록 했습니다.
- 이 방법은 학습의 효율성과 DST의 성능 향상에 도움을 주었습니다. SOM-DST (Selectively Overwriting Memory for Dialog State Tracking)은 MultiWoZ 2.0과 2.1에서 SOTA를 달성하였습니다.
- 추가적으로 본 논문에서는 현재 상황과 정답이 주어진 상황이 정확도 차이가 나는 원인을 분석하였으며, 그 결과 DST 성능을 높이기 위해서는 본 논문에서 제시한 방향으로 나아가야 한다는 것을 제안합니다.
Image-Chat: Engaging Grounded Conversations
저자: Kurt Shuster, Samuel Humeau, Antonie Bordes, Jason Weston (Facebook AI Research)
키워드: Image Conversation, Dataset, TransResNet

- 사람과 오래 대화하기 위해서는 파트너의 관심 있는 부분을 이해할 수 있는 능력이 필요합니다.
- 사람들끼리 어떤 사진을 주제로 대화를 나누는 것을 곳곳에서 자연스레 볼 수 있습니다.
- 본 논문에서는 사진에 대해서 대화를 할 수 있는 모델과 데이터셋을 다루었습니다.
- 사람-사람 간 대량의 대화 데이터를, 구체적으로는 주어진 분위기나 스타일을 이용해 특정 이미지에 대해서 대화하는 데이터셋을 모았습니다.
- Image-Chat 데이터셋은 202K개의 dialog를 포함하고 2015개의 style 속성을 사용하였습니다.
- 본 논문에서 제안한 접근은 기존의 Image Grounded Conversations (IGC) 태스크에서 높은 성능 향상을 가져왔습니다.
Spelling Error Correction with Soft-Masked BERT
저자: Shaohua Zhang, Haoran Huang, Jicong Liu and Hang Li (ByteDance AI Lab and Fudan University)
키워드: Spelling Error Correction, Soft Masking
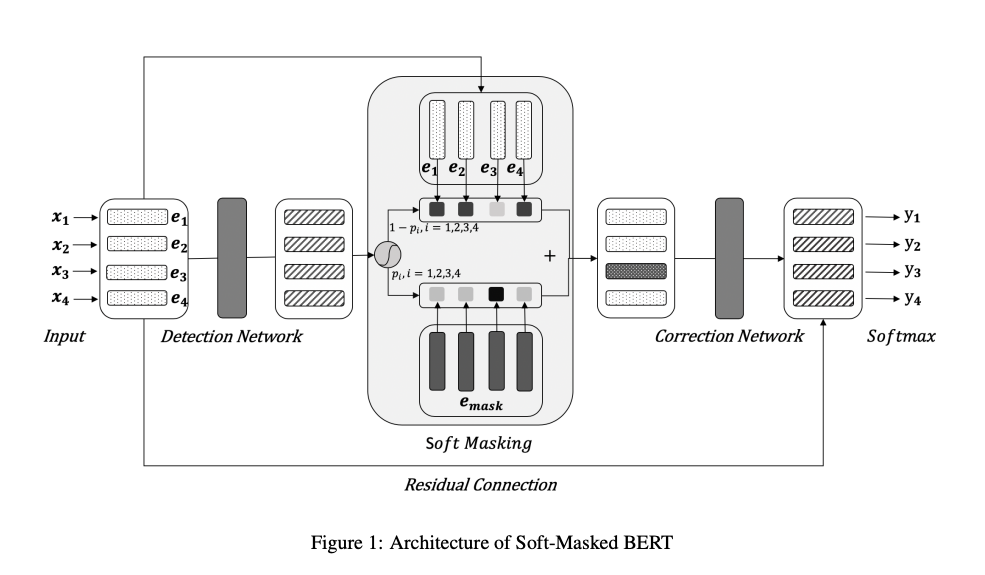
- 오타교정 문제를 풀 때 기존 접근 방식은 틀린 부분을 masking해서 BERT를 fine-tuning하고 inference 시에는 각 토큰 별로 masking하고 예측하는 방식을 사용했습니다.
- 하지만 기존 방식은 어떤 토큰이 오타이고 오타가 아닌지에 대한 정보가 없어서, BERT가 오타 토큰은 그대로 내보내고(비수정), 오타가 아닌 토큰을 교정해 버리는 문제(과수정)가 발생했습니다.
- 본 논문에서는 오타 detection 모델과 correction 모델을 나누고 detect 모델의 예측 값을 correction에 전달해서 correction 모델이 틀린 것만 맞히도록 변경하였습니다.
- 구체적으로는 GRU 기반의 error detection 모델이 binary classification해서 각 토큰 별 error 확률을 계산합니다.
- BERT의 [MASK] token의 embedding error 확률 + 원본 토큰 embedding (1 - error 확률)을 correction network에 넣어서 decoding할 토큰을 예측하는 방식인 soft-masking이라는 방법을 제안합니다.
- loss = detection network loss + correction network loss로 학습함.
Generating Counter Narratives against Online Hate Speech: Data and Strategies
저자: Serra Sinem Tekiroglu, Yi-Ling Chung and Marco Guerini (Fondazione Bruno Kessler and University of Trento)
키워드: Hate Speech, Text Generation, Crowdsourcing
- 웹에 존재하는 hate speech를 방지하는 것은 중요한 문제이지만, 이는 곧 검열 및 over blocking 등의 이슈와 맞닿아있기도 합니다.
- 이에 대한 타협점으로써, 최근에는 직접적인 수정 및 삭제 대신에 hate speech로 판단되는 글에 대한 counter narrative를 자동으로 생성하여 hate speech를 완화하고자 하는 연구들이 진행되고 있습니다.
- 하지만 이를 생성 관점의 태스크로 접근하기 위해서는 counter narrative에 해당하는 다량의 데이터가 필요합니다.
- 본 논문은 이러한 어려움을 해결하기 위해 다음과 같은 three-step pipeline 시스템을 제안합니다:
- 사전 학습된 언어모델을 통한 counter narrative silver data 생성
- Amazon Mechanical Turk (AMT)와 같은 crowdsourcing을 통한 1차 필터링
- 전문가를 통한 검수 및 수정.
- 이 중 AMT를 통한 crowd filtering 과정을 딥러닝 기반의 분류기로 대체하여도 합리적인 수준의 성능을 얻을 수 있었다고 합니다.
Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?
저자: Yada Pruksachatkun, Jason Phang, Haokun Liu, Phu Mon Htut, Xiaoyi Zhang, Richard Yuanzhe Pang, Clara Vania, Katharina Kann, Samuel R. Bowman (New York University)
키워드: Curriculum Learning, Pretrained Language Model
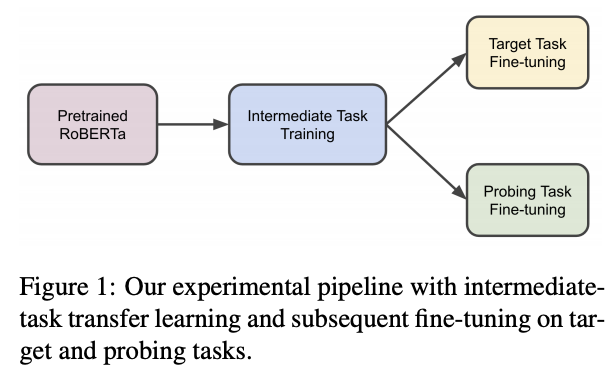
- 사전 학습된 언어 모델을 타겟 태스크에 fine-tuning하기 전에 또다른 task에 대한 훈련을 거치면 성능이 보다 향상됨을 나타내는 연구들이 존재합니다.
- 본 논문은 이렇게 중간 다리 역할을 하는 학습 과정을 Intermediate task training으로 명명합니다.
- 하지만 이러한 학습 전략은 언제나 성능 향상을 돕지는 않고, 어떠한 이유로 어떠한 상황에서 유효한지 또한 아직 명확하지 않습니다.
- 본 논문은 이를 자세히 분석하기 위해, 11개의 intermediate task와 10개의 target task 간의 조합에 해당하는 110개의 쌍으로 정량적인 분석을 합니다.
- 추가적으로, intermediate task training 단계에서 모델이 어떠한 언어 능력을 배웠는지 확인하기 위한 25개의 probing task를 수행합니다.
Towards Holistic and Automatic Evaluation of Open-Domain Dialogue Generation
저자: Bo Pang, Erik Nijkamp, Wenjuan Han, Linqi Zhou, Yixian Liu, Kewei Tu (University of California, Los Angeles., National University of Singapore and ShanghaiTech University)
키워드: Automatic Dialog Evaluation

- 생성 모델이 만든 일상 대화를 자동으로 평가하는 것은 아직 뚜렷한 해답이 없는 문제입니다.
- 그 중 하나는, 하나의 입력에 대해 존재할 수 있는 정답의 다양성이 너무 크기에 레퍼런스에 기반한 평가 방법이 사람의 평가와 일치하기 힘들다는 점입니다.
- 본 논문은 4개의 자동화된 평가 방법을 종합하여 이를 해결하고자 합니다:
- GPT-2를 통한 context coherence
- GPT-2를 통한 Fluency
- n-gram based response diversity
- NLI 데이터를 이용한 논리적 self-consistency
- 이러한 평가 방법을 종합한 결과, 기존의 방법들보다 사람이 평가한 점수와의 correlation이 높게 나타났다고 합니다.
BERTRAM: Improved Word Embeddings Have Big Impact on Contextualized Model Performance
저자: Timo Schick, Hinrich Schütze (Sulzer GmbH and LMU Munich)
키워드: Rare Word

- 트렌스포머 구조로 언어모델을 사전학습하여 Contextualized 임베딩을 얻는 방법(BERT, RoBERTa 등)은 NLP에서 많은 성능 개선을 가져왔습니다.
- 하지만 최근 연구에서 이 모델들이 희귀한 단어에 취약하다는 문제점이 발견되었습니다. Word2Vec과 같은 고정 임베딩 방법에서는 이 문제를 해결하기 위해 희귀한 단어에 대한 추가적인 학습을 진행하거나 형태와 컨텍스트에 따른 추가적인 임베딩을 만들었습니다.
- 본 논문의 저자들은 BERT와 같은 방법에서 희귀한 단어에 대응할 수 있는 새로운 방법(BERTRAM)을 제시합니다.
- 이 방법은 위 그림과 같이 BERT에 입력으로 들어가는 임베딩에서 희귀한 단어를 위핸 임베딩을 새로 만드는데, N-gram 임베딩을 이용해 형태적인 표현을 만들고 pre-trained BERT와 Attention Mimicking 기법을 이용해서 이를 Contextualized합니다.
- 또한 기존의 세 가지 데이터셋(MNLI, AGNews, DBPedia)의 검증셋을 자동으로 희귀한 단어를 포함하는 셋으로 변경하여 제시한 방법론의 타당성을 증명합니다.
- 결과적으로 만들어진 데이터셋에서 베이스라인인 BERT, RoBERTa에 비해 큰 성능 향상을 보여줍니다.
schuBERT: Optimizing Elements of BERT
저자: Ashish Khetan, Zohar Karin (Amazon AWS)
키워드: Model Compression, Pruning
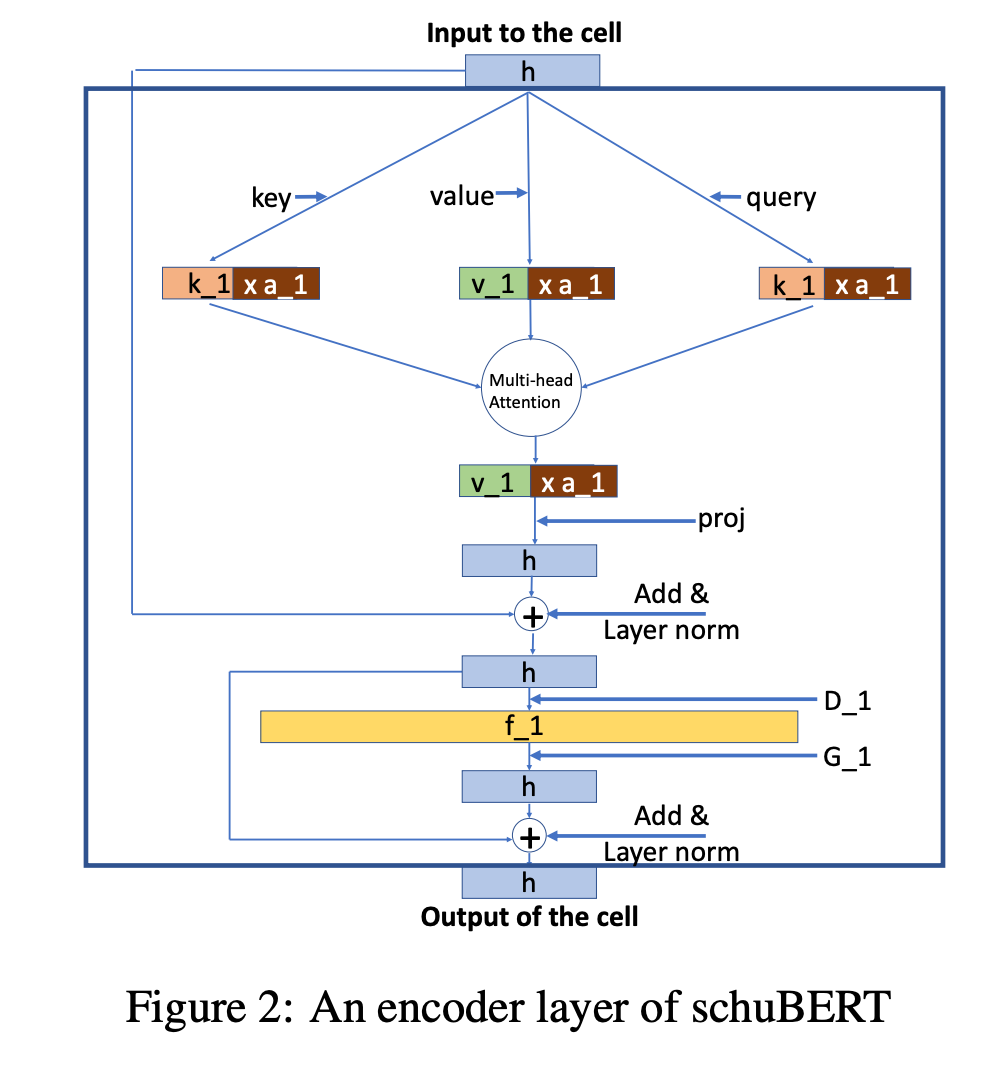
- BERT 기반의 모델들은 트랜스포머 인코더를 이용합니다. 트랜스포머 인코더는 레이어 수나 각 레이어의 크기 등 몇몇 하이퍼파라미터를 통해 구성되는데요, 일반적으로 모델의 크기를 줄이기 위해서는 이 하이퍼파라미터를 임의로 줄여서 학습한 모델을 이용합니다.
- 본 논문에서는 이렇게 구성된 하이퍼파라미터들이 충분히 최적화되지 않았다고 제안합니다.
- 이를 해결하기 위해 하이퍼파라미터를 더 세분화하여 가능한 모델 구조 수를 늘리고 프루닝 기반의 기법으로 제한된 파라미터 크기 내에서 구조 자체를 최적화합니다.
- 결과적으로 BERT-base를 제안한 방법으로 프루닝 했을 때, 동일한 파라미터 크기를 갖는 모델들보다 우수한 성능을 보였습니다.
BLEURT: Learning Robust Metrics for Text Generation
저자: Thibault Sellam, Dipanjan Das, Ankur P. Parikh (Google Research)
키워드: Learning Metrics, Pre-training, WMT Metrics shared task

- generation 모델의 눈부신 발전에 비해 생성 평가를 위한 메트릭(e.g., BLEU and ROUGE)의 양상은 사람의 판단과 관계가 크지 않았습니다.
- 이를 극복하기 위해 BERT 기반으로 학습된 평가 메트릭인 BELURT를 제안합니다.
- 이 메트릭의 key가 되는 측면은 모델의 generalize를 돕기 위해서 수백만 개의 synthetic examples를 통한 새로운 pre-train을 제안했다는 것입니다.
- 이렇게 얻은 (examples, synthetic examples) pair를 이용하여 BLEU나 BERT score, NLI 등을 예측하는 task를 푸는 pre-training을 합니다.
Grounded Conversation Generation as Guided Traverses in Commonsense Knowledge Graphs
저자: Houyu Zhang, Zhenghao Liu, Chenyan Xiong, Zhiyuan Liu (Brown University, Tsinghua University and Microsoft Research AI)
키워드: Commonsense Knowledge Graphs, Graph Neural Networks, Conversation Generation
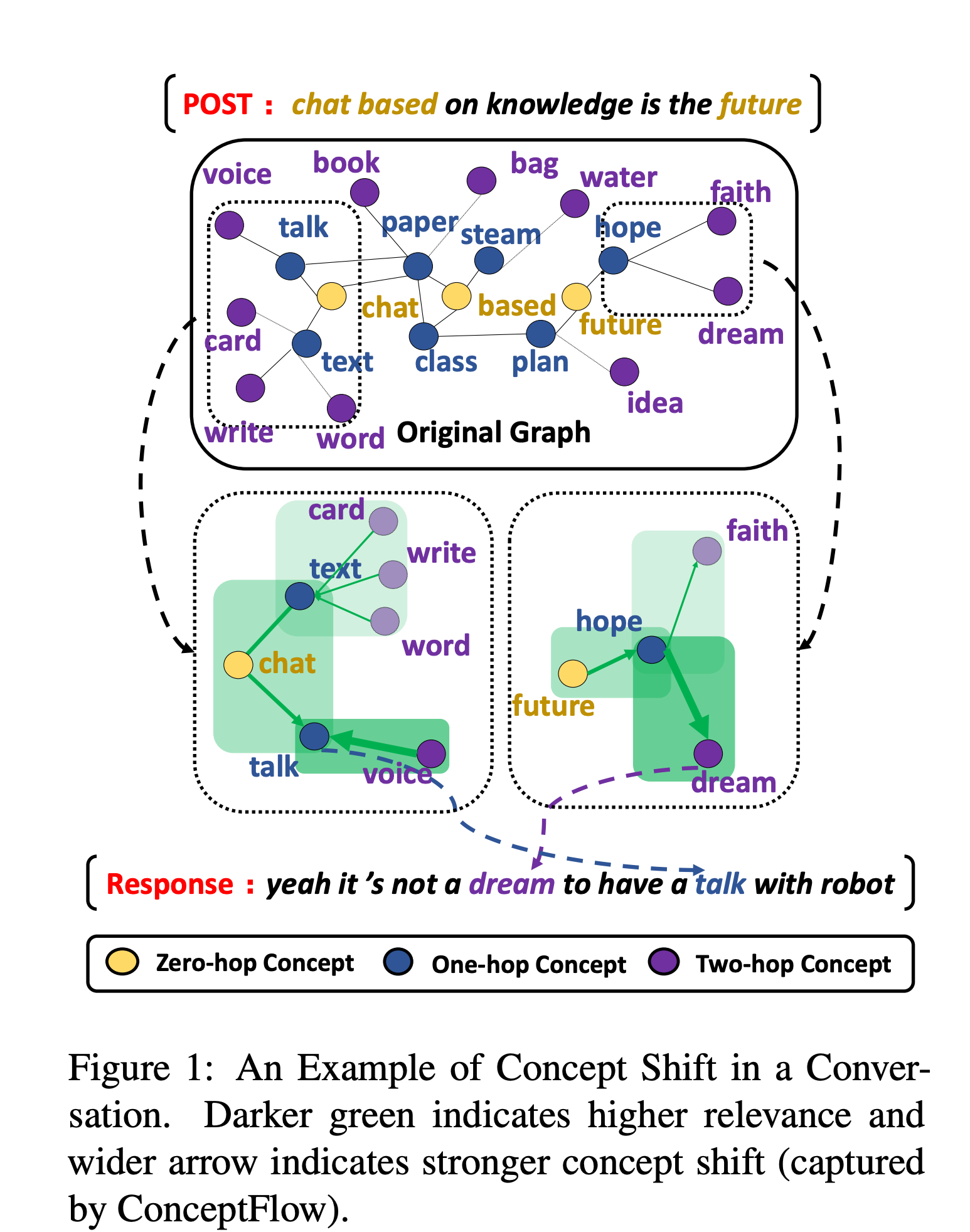
- 인간의 대화는 관련된 컨셉을 통해 발전해 왔으며 기존 NLG의 degeneration 문제를 해결하기 위해 external knowledge가 큰 역활을 해왔습니다.
- 해당 모델은 commonsense knowledge graphs를 대화 생성에 적용하기 위한 모델입니다.
- Reddit 대화 데이터베이스를 사용해 자동 평가와 사람 평가에서 seq2seq 모델을 능가했을 뿐만 아니라 70% 더 적은 파라미터로 GPT-2 모델의 성능을 넘는 결과를 보여줍니다.
Unsupervised Domain Clusters in Pretrained Language Models
저자: Roee Aharoni, Yoav Goldberg (Bar Ilan University and Allen Institute for Artificial Intelligence)
키워드: Pretrained Language Models, Domain Clusters, Data selection method, machine translation
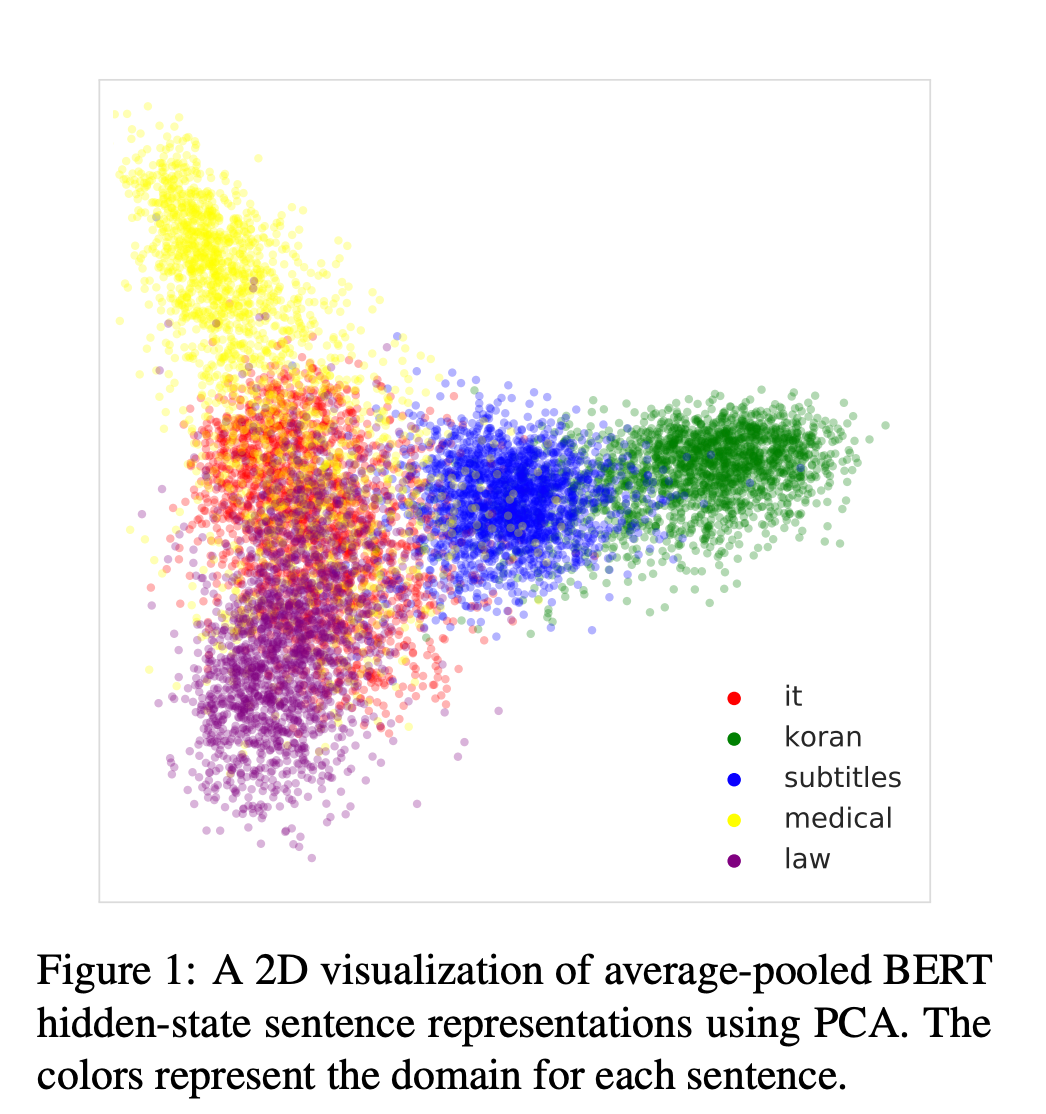
- Text data는 토픽, 스타일, 형식 수준 등과 같은 언어적인 측면 때문에 “in-domain data”라고 부르는 것은 때때로 지나친 단순화일 수 있으며 모호한 측면이 존재합니다. 또한 이러한 언어의 다양성 때문에 정확한 요구 사항을 만족하는 데이터를 찾기가 어렵습니다.
- 이러한 성질 때문에 저자는 data-driven definition이 필요하다고 합니다.
- 거대한 pre-trained 모델은 도메인을 어떠한 supervision 없이 클러스터링하면서 문장의 표현을 내재적으로 학습합니다. 이를 통해 간단하면서도 data-driven한 도메인의 정의를 제안합니다.
- 또한 이러한 성질을 활용하여 작은 in-domain 데이터만을 사용하는 도메인 기반의 Data selection 방식을 제안합니다.
- 이러한 Data selection 방법을 평가하기 위해 다섯 종류의 서로 다른 NMT 데이터셋을 활용하였고 BLEU와 oracle에 대한 sentence selection에서 베이스라인보다 나은 성능을 보였습니다.
BPE-Dropout: Simple and Effective Subword Regularization
저자: Ivan Provikov, Dmitrii Emelianenko, Elena Voita (Yandex, Moscow Institute of Physics and Technology, National Research University Higher School of Economics, University of Edinburgh and University of Amsterdam)
키워드: BPE-Dropout, Subword Segmentation, Subword Regularization

- 대표적인 Subword Segmentation 기법인 Byte Pair Encoding (BPE)은 많은 자연어처리 태스크에서 효과적인 성능을 보입니다.
- 하지만 BPE는 하나의 단어를 단 하나의 Subword Sequence로 분절하기 때문에, 단어의 Compositionality를 학습하기 어렵고 segmentation error에 강건하지 못하다는 문제가 있습니다.
- 본 논문은 이런 문제를 해결하기 위해 단어를 다양한 Subword Sequence로 분절하는 BPE-dropout 기법을 제안합니다.
- BPE-dropout은 기존 BPE의 merge 후보를 확률적으로 건너뜀으로써 최종 Subword Sequence가 다양하게 생성되도록 합니다. 이는 매우 간단하고 효과적인 Subword Regularization 기법으로 기존 BPE 프레임워크와 호환됩니다.
- 실험을 통해서 BPE-dropout을 Standard BPE 뿐만 아니라 기존의 Subword Regularization 기법인 Unigram-LM (Kudo, 2018)과도 비교하고 있으며, 결과적으로 Machine Translation 태스크에서 각각 2.3, 0.9의 BLEU 스코어 성능 향상이 있었습니다.
Dialogue-Based Relation Extraction
저자: Dian Yu, Kai Sun, Claire Cardie, Dong Yu (Tencent AI Lab and Cornell University)
키워드: Dialogue-based Relation Extraction, Dialogue, Relation Extraction

- 본 논문은 대화 속에서 등장하는 두 Argument 사이의 관계를 예측하는 Dialogue-based Relation Extraction 태스크를 위한 데이터셋인 DialogRE를 제안합니다.
- TAC-KBP에서 사용하는 Relation Schema를 기반으로 36개의 관계 타입을 사용하였으며, 총 1788개의 대화에 대해 10168개의 관계 Triplet (Subject, Relation Type, Object)을 만들었습니다.
- 이와 함께 대화의 각 턴 별로 Precision과 Recall을 측정함으로써, 대화 데이터의 특성을 효과적으로 반영하는 새로운 Metric도 제안합니다.
Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
저자: Joongbo Shin, Yoonhyung Lee, Seunghyun Yoon, Kyomin Jung (Seoul National University)
키워드: Transformer-based Text Autoencoder(T-TA), Language Autoencoding(LAE), Language Representation
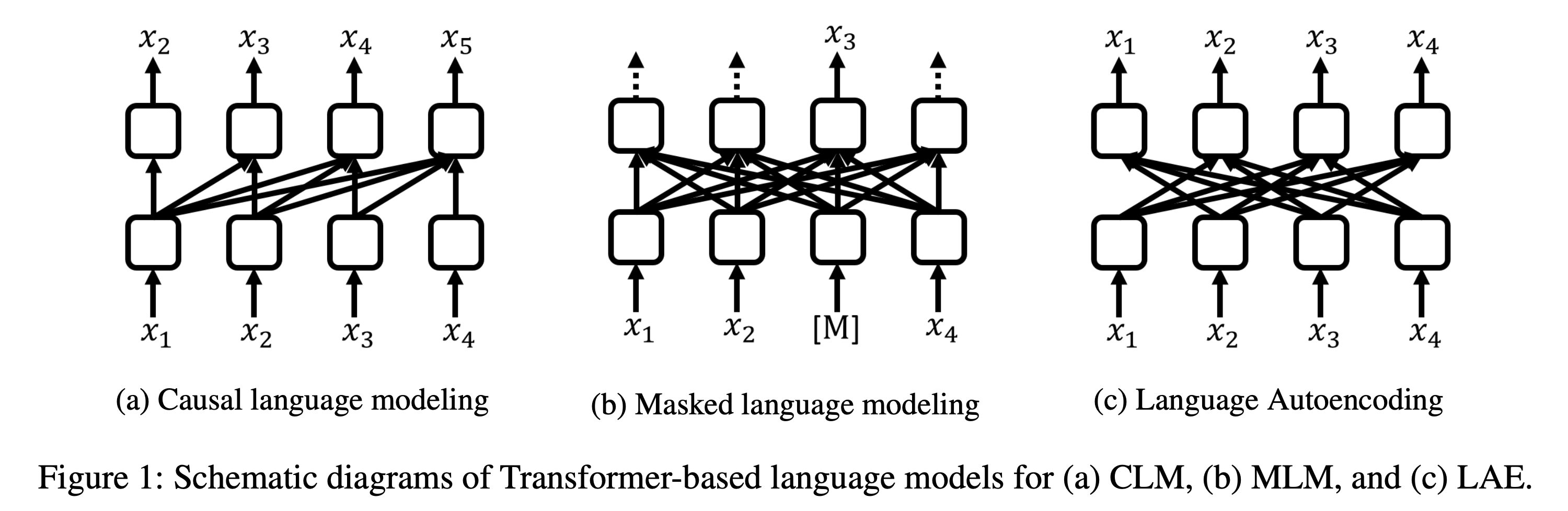
- BERT가 다양한 태스크에서 좋은 성능을 보이고 있지만, Contextual Language Representation을 뽑기 위해서 반복적인 Inference가 필요하다는 한계가 있습니다.
- 본 논문은 이런 문제를 해결하기 위해 Deep Bidirectional Language Model인 Transformer-based Text Autoencoder (T-TA)를 제안합니다.
- T-TA는 Bidirectional 구조를 유지하면서도 반복적인 Inference 없이 Contextual Language Representation을 효과적으로 계산합니다.
- 이와 함께 모델의 입력을 그대로 복원하는 새로운 Objective인 Language Autoencoding (LAE) 태스크도 제안합니다.
- 결과적으로 T-TA는 기존의 BERT 기반의 모델보다 Reranking 태스크에서는 6배, Semantic Similarity 태스크에서는 12배 빠르면서도 BERT와 비슷하거나 더 나은 Accuracy를 보였습니다.
Pretraining with Contrastive Sentence Objectives Improves Discourse Performance of Language Models
저자: Dan Iter, Kelvin Guu, Larry Lansing, Dan Jurafsky (Stanford University and Google Research)
키워드: Discourse representation, Unsupervised representation learning
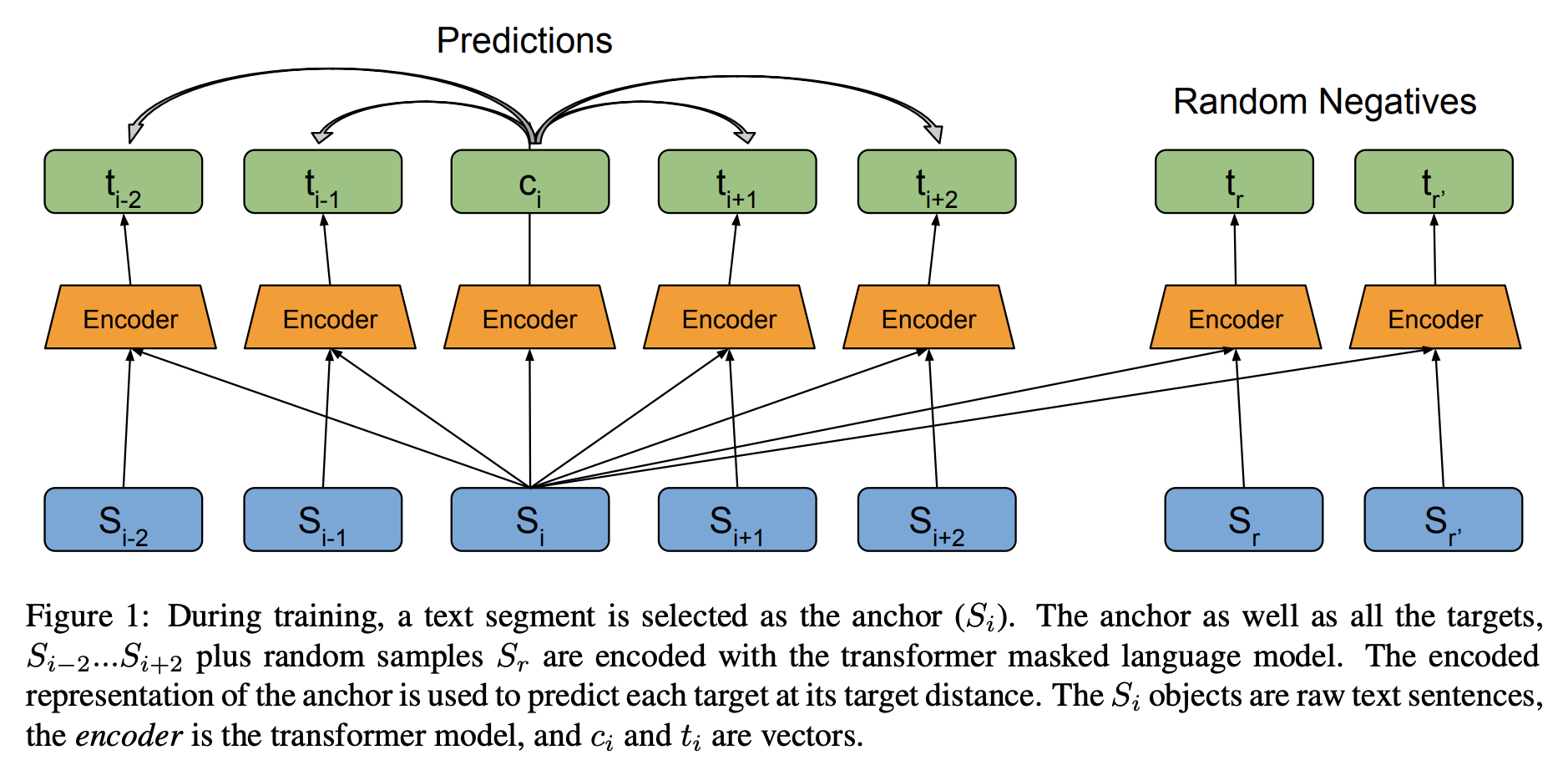
- 최근 자연어처리 분야에서 unsupervised representation learning 연구는 주로 어떻게 하면 contextual word representation을 잘 만들지에 집중되어 왔습니다. 반면 discourse-level representation을 향상시키기 위한 연구는 많지 않았습니다.
- 본 논문에서는 문장 간의 상관 관계를 고려하는 사전학습 목적함수로 discourse coherence와 sentence distance를 모델링하는 CONPONO를 제안합니다.
- 모델은 anchor 문장이 주어졌을 때 k 문장만큼 떨어진 텍스트를 예측하도록 학습됩니다. 이때 candidate은 주변 문장과 몇 개의 랜덤 문장으로 이루어집니다.
- discourse representation 벤치마크인 DiscoEval로 평가했을 때 7개 태스크에서 최대 13%, 평균 4%의 성능을 향상시켰습니다. 제안된 모델은 BERT-Base와 같은 크기지만 더 큰 BERT를 비롯한 최근 모델들을 능가했습니다.
- 심지어 직접적으로 discourse 관련 능력을 평가하지 않는 RTE, COPA, ReCoRD에서도 2%-6% 가량의 성능 향상을 보였습니다.
The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents
저자: Kurt Shuster, Da Ju, Stephen Roller, Emily Dinan, Y-Lan Boureau, Jason Weston (Facebook AI Research)
키워드: Open-domain dialogue system, Multitask learning
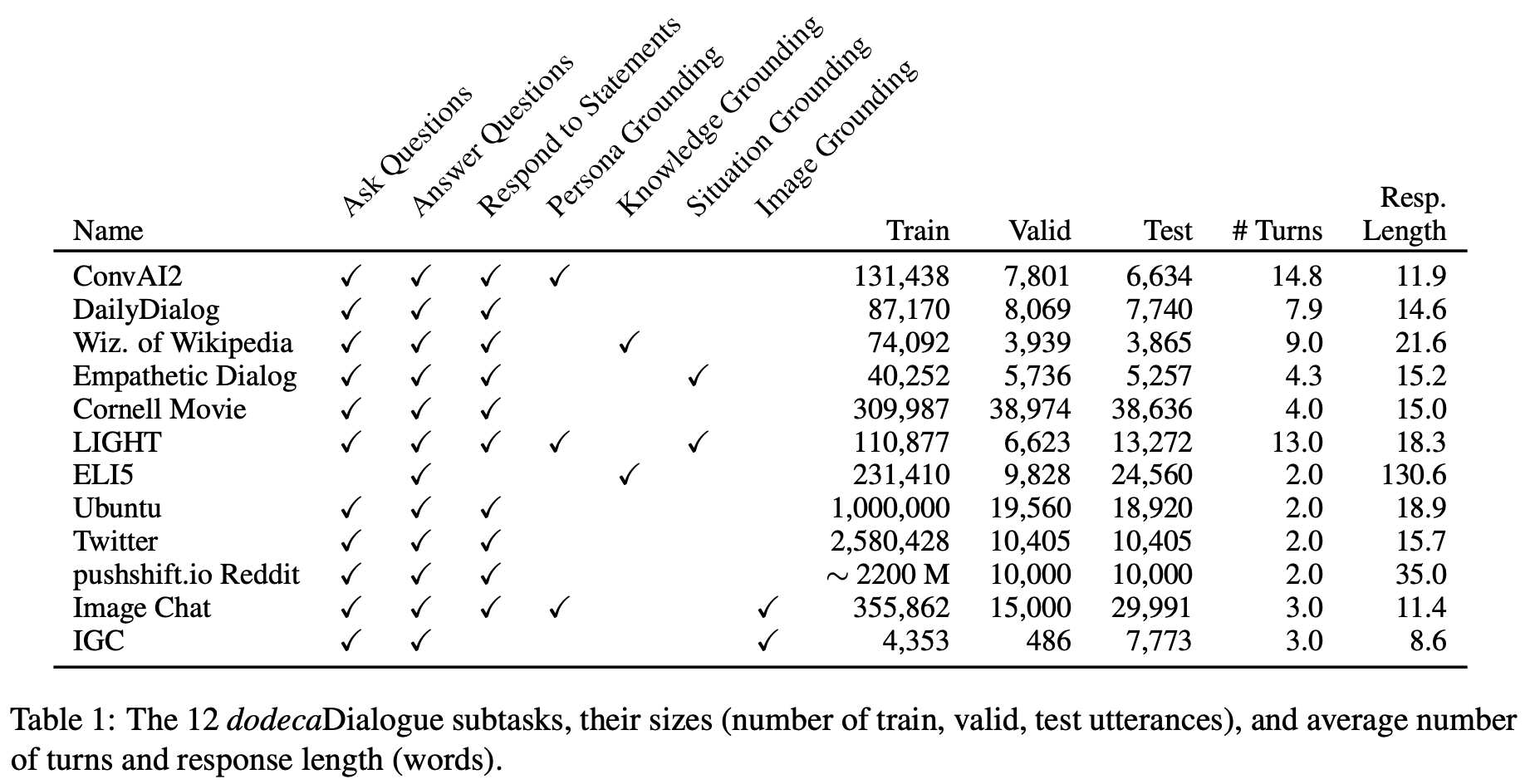
- 본 논문에서는 대화 에이전트가 personality와 empathy를 가지고 engaging하게 대화하는지, 질문할 수 있는지, 외부 지식을 활용해 질문에 답할 수 있는지, 토픽과 상황에 대해 토론할 수 있는지, 이미지를 인식하고 이에 대해 얘기할 수 있는지 등의 능력을 평가하는 12가지 태스크인 dodecaDialogue를 소개합니다.
- 저자들은 이렇게 다양한 분야의 큰 데이터로 멀티태스크 학습을 함으로써 하나의 오픈 도메인 대화 에이전트가 인식하고, 추론하고, 사람과 대화할 수 있는 능력을 향상시킴과 동시에 관련된 기술의 진보를 평가하는 데 유용하기를 희망합니다.
- 제안된 모델은 비슷한 분야에 걸쳐 있는 매우 큰 데이터로 멀티태스킹 함으로써 사전학습된 BERT를 능가했습니다. 이는 본 챌린지(Dodecathlon)의 강한 베이스라인이 될 것입니다.
A Mixture of h-1 Heads is Better than h Heads
저자: Hao Peng, Roy Schwartz, Dianqi Li, Noah A. Smith (University of Washington)
키워드: Multi-head attention, Mixture of Experts
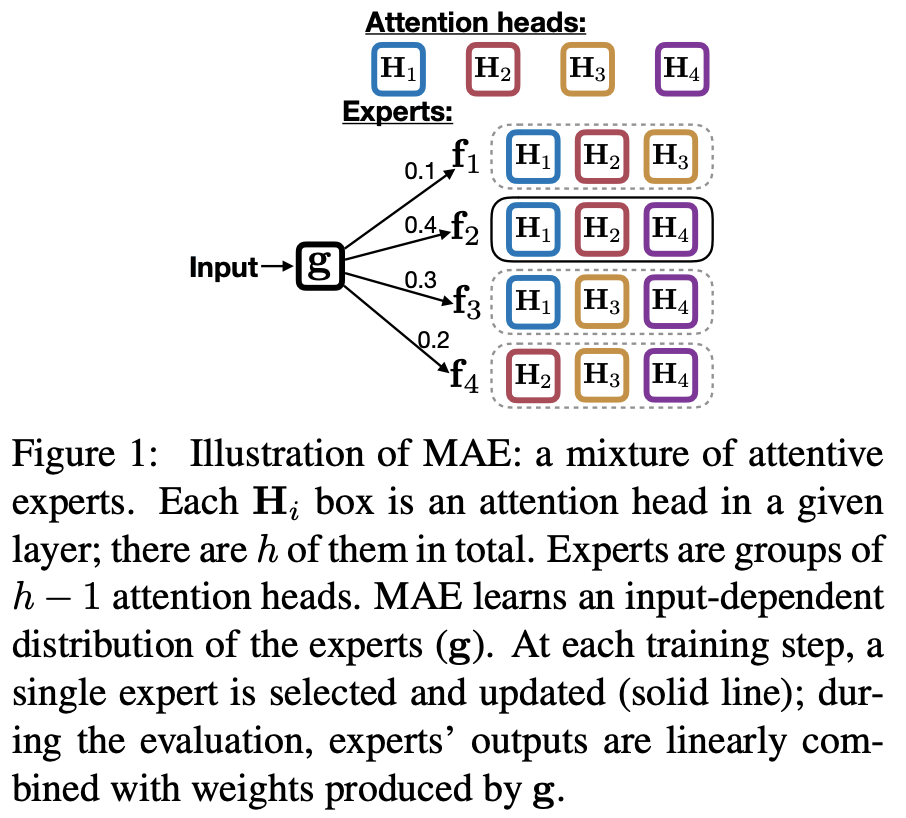
- Transformer 이후로 Multi-head attention 기반의 모델이 널리 쓰이며 활약하고 있습니다. 그러나 최근 몇 연구에서 over-parametrize 되었다는 증거가 발견되었고, 이를 해결하기 위한 pruning 연구가 활발히 이루어지고 있습니다.
- 저자는 pruning 대신 입력에 따라 활성화 할 헤드를 모델이 직접 배워서 선택하는 방법을 제안하고 이를 mixture of experts (MoE)와 접목시켜 mixture of attentive experts (MAE)라 명명합니다.
- MAE는 block coordinate descent 알고리즘을 이용해 expert가 담당하는 헤드의 비중과 그것들의 파라미터를 번갈아 가며 업데이트 하는 방식으로 최적화 됩니다.
- 기계번역과 언어 모델링 태스크로 실험한 결과 베이스라인 성능을 능가했습니다. 특히 WMT14 영-독 데이터셋에서는 transformer-base보다 BLEU가 0.8 높았습니다. 분석해보니 모델이 입력에 따라 다른 experts를 specialize함을 확인했습니다.
Attention Module is Not Only a Weight: Analyzing Transformers with Vector Norms
저자: Goro Kobayashi, Tatsuki Kuribayashi, Sho Yokoi, Kentaro Inui (Tohoku University, Langsmith Inc. and RIKEN)
키워드: Attention, BERT Analysis
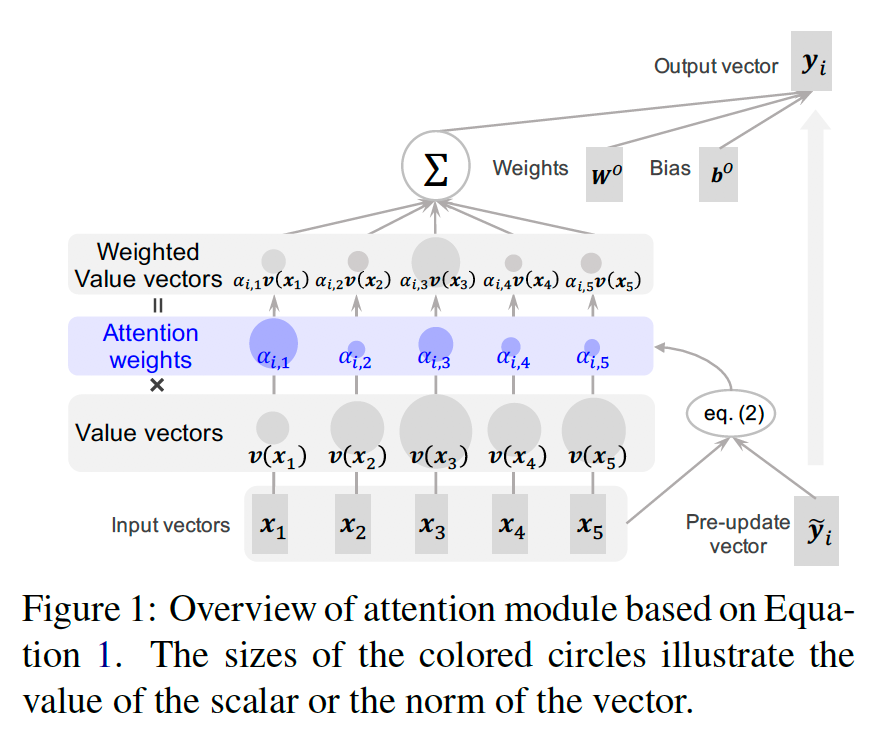
- 일반적으로 Transformer 기반의 모델에서 입력 시퀀스와 출력 시퀀스 사이의 관계를 조사할 때 Attention Weights를 구하여 입출력의 관계를 설명하는 경우가 많습니다.
- 하지만, Attention 연산은 위 그림처럼 Attention Weight가 Value Vector와 가중합된 형태로 Output Vector가 결정되기 때문에, 실제로 Attention을 분석할 때는 Attention Weight만이 아니라, Attention Weight로 가중합된 벡터의 크기 (Norm)도 고려되어야 한다는 점을 지적하는 논문입니다.
- 본 논문에서 제안한 방식대로 BERT의 Self-Attention 구조를 분석해본 결과, Attention Weight만 고려할 때는 [CLS], [SEP], 온점, 반점 등에 Attention이 많이 걸리는 경향을 보이지만, Weighted Value Vectors의 크기는 작아, 실제로는 이러한 토큰들의 영향력이 크지 않다는 사실을 확인했습니다.
Improved Natural Language Generation via Loss Truncation
저자: Daniel Kang, Tatsunori B. Hashimoto (Stanford University)
키워드: Generation
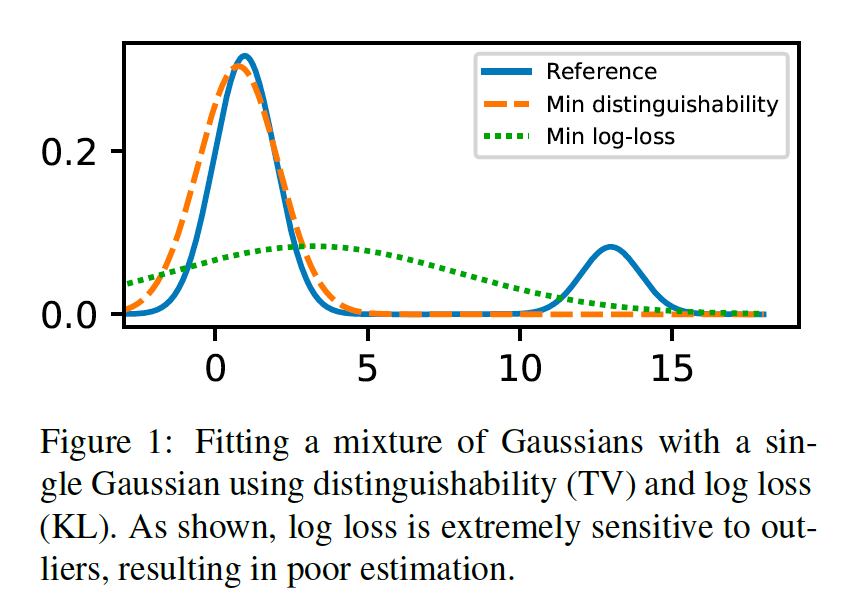
- 일반적으로 문장 생성에 많이 사용되는 log loss (cross entropy loss)를 최소화하는 학습 전략은 적은 양의 noisy 데이터에도 크게 영향을 받아, 성능이 낮아지는 경향이 있습니다. 이는 문서 요약 등의 태스크에서 hallucinated fact 문제 등을 야기합니다.
- 본 논문에서는 reference 문장과 모델이 생성한 문장 사이의 distinguishability를 학습하기 위한 로스를 제안하여 noisy 데이터에 robust한 모델을 학습하는 방법을 제안합니다.
Single Model Ensemble using Pseudo-Tags and Distinct Vectors
저자: Ryosuke Kuwabara, Jun Suzuki, Hideki Nakayama (University of Tokyo, Tohoku University and RIKEN)
키워드: Ensemble
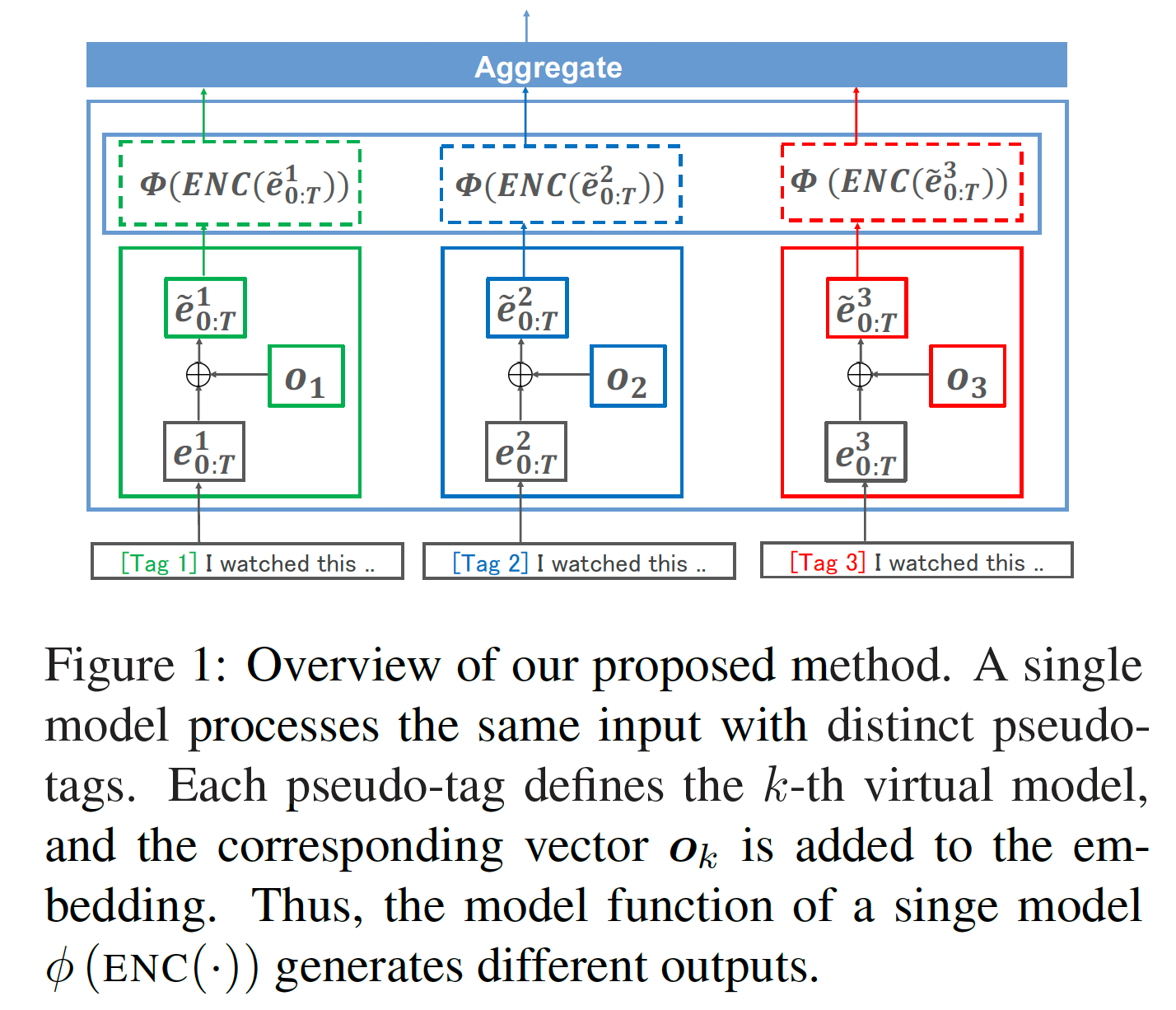
- 모델 앙상블 기법은 컴페티션에서 성능을 끌어올리기 위해 일반적으로 자주 쓰이는 기법이지만, 추론 시 앙상블용 모델을 모두 들고 있어야 하기 때문에, 실사용을 하기에는 무리가 있습니다.
- 본 논문에서는 모델 앙상블 기법이 독립된 복수 개의 공간에서 학습된 복수 개의 모델을 집약하는 방식인 것과 달리, 단일 공간 내에 복수 개의 모델을 가상으로 학습하여 집약하는 방식을 이용하여 단일 모델을 이용한 pseudo-ensemble 기법을 제안합니다. 구체적으로는 훈련 데이터를 K배 확장하여, K개의 pseudo 태그를 입력 문장의 선두에 입력하고, K개의 임베딩을 단어 임베딩에 선형합합니다.
- 본 논문에서 제안한 pseudo-model ensemble 기법을 다양한 text classification 및 sequence labeling 태스크에 적용하여 유효성을 검증했습니다.
결론
최근에 진행된 자연어처리 연구들을 살펴보면서 떠올랐던 질문은 크게는 다음 두 가지였습니다.
- 만약 Parameter 수를 늘리는 것이 성능을 향상시킨다면 우리는 어디까지 모델 크기를 키울 수 있을까?
- 만약 BERT 등이 정말로 모델 크기에 비해 데이터가 부족하다면 풀고자 하는 문제를 어떻게 모델에 효과적으로 학습시킬 수 있을까?
이번 ACL 2020을 보면서 다른 연구자들도 저희와 비슷한 종류의 고민을 하고 있다는 것을 어렴풋이나마 느낄 수 있었습니다. 그런 점에서 이런 학회는 저희에게 신선한 자극이 됩니다. 거인들의 어깨 위에 서서 사람만큼 사람 같은 챗봇을 만드는 길을 찾고자 저희는 오늘도 노력하겠습니다.