ACL 2023 Review
핑퐁팀과 함께하는 ACL 2023 Review

자연어 처리 분야의 최고 국제 컨퍼런스인 ACL 2023을 맞아 리서치팀 워크샵을 진행했습니다. ML 리서치 유닛, 데이터 기획 유닛의 팀원들이 회사를 떠나 다같이 모여서 3박4일 동안 온라인으로 ACL 논문 발표를 듣고 함께 토론하는 즐거운 시간을 가졌어요!
발표된 논문 중 인상 깊었던 논문을 각자 한 편씩 선정하여 총 18편을 간단히 리뷰해보았습니다. 현재 핑퐁팀이 관심있게 보고있는 연구라고 할 수 있을 것 같아요! 재미있게 읽어주세요 😀
- Do Androids Laugh at Electric Sheep? Humor “Understanding” Benchmarks from the New Yorker Caption Contest
- Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
- Can Large Language Models Be an Alternative to Human Evaluations?
- Benchmarking Large Language Model Capabilities for Conditional Generation
- LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
- NLPositionality: Characterizing Design Biases of Datasets and Models
- Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
- Is GPT-3 a Good Data Annotator?
- Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
- Pre-trained Language Models Can be Fully Zero-Shot Learners
- Crosslingual Generalization through Multitask Finetuning
- Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
- Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
- Symbolic Chain-of-Thought Distillation: Small Models Can Also “Think” Step-by-Step
- PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
- Towards Boosting the Open-Domain Chatbot with Human Feedback
- Large Language Models Are Reasoning Teachers
- Weaker Than You Think: A Critical Look at Weakly Supervised Learning
Do Androids Laugh at Electric Sheep? Humor “Understanding” Benchmarks from the New Yorker Caption Contest
작성자: 장성보
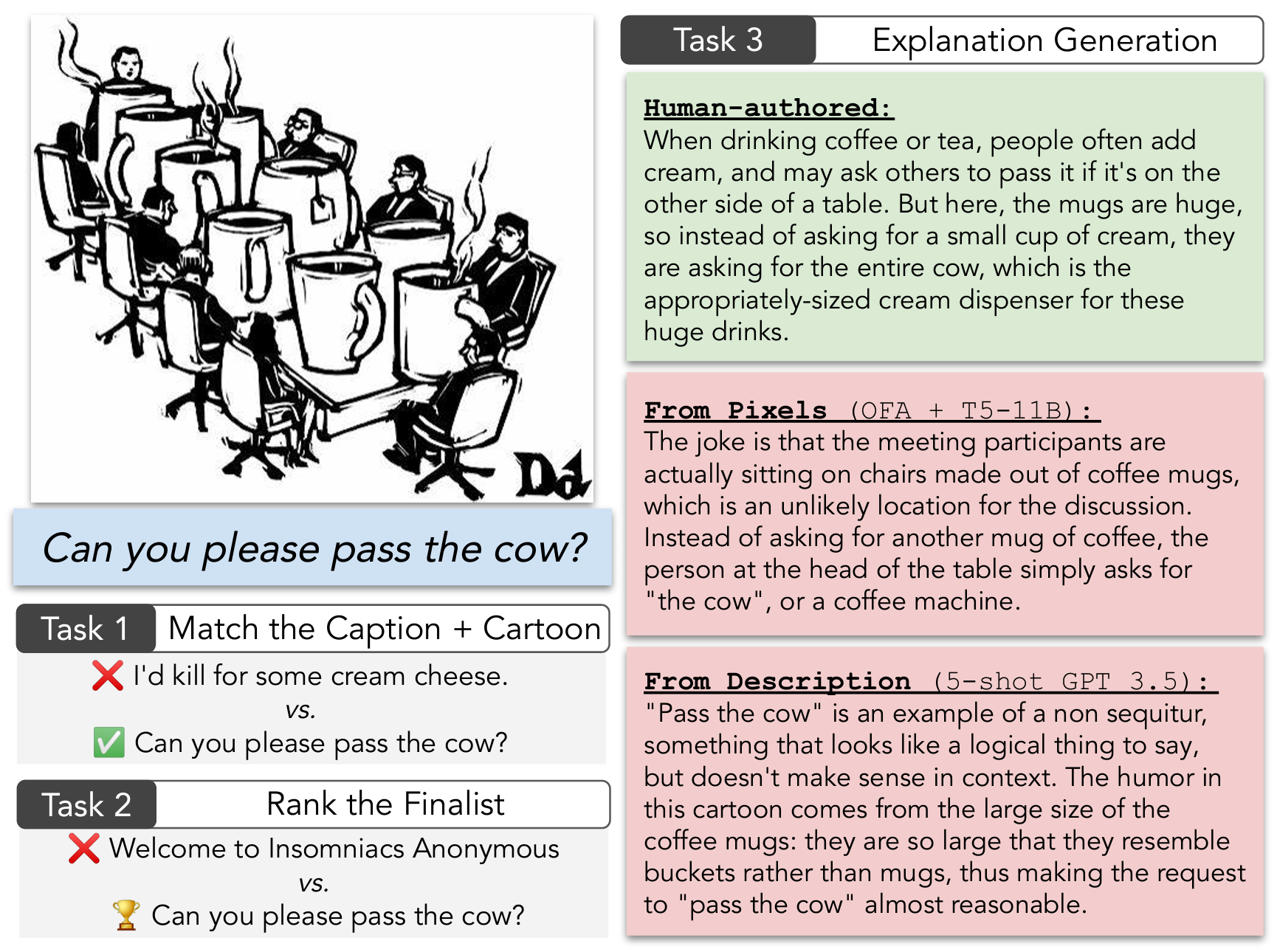
본 논문은 LLM이 유머를 이해하고 구사할 수 있는지를 다각도로 살펴봅니다. 이를 위해 저자들은 먼저 New Yorker 신문의 Cartoon Caption Contest 데이터를 모았습니다. 데이터는 하나의 그림과 이에 대한 독자들의 유머러스한 캡션 응모작, 편집자가 꼽은 3개의 입상작, 각 응모작에 대한 독자들의 평가(Funny, Somewhat Funny, Unfunny) 평균 점수, 그리고 유머가 웃긴 이유로 이루어져 있습니다. 저자들은 세 가지 태스크로 여러 가지 Vision+Language 모델과 LLM을 평가합니다.
- Matching: 5개의 캡션 중 그림과 가장 어울리는 ground truth 캡션 1개 고르기
- Quality Ranking: 입상작과 아닌 것 둘 중에 어떤 게 더 높은 평가를 받았는지 고르기
- Explanation: 캡션이 왜 웃긴지 설명하기
실험 결과 GPT-3, GPT-4 같은 SOTA LLM들은 Matching과 Quality Ranking 태스크에서 준수한 성능을 나타냈지만 아직 사람의 능력까지는 미치지 못하는 모습을 보였습니다. 반면 Explanation에서는 LLM조차도 디테일한 부분에서 틀린 정보를 생성하는 등 여전히 많은 개선이 필요함을 보였습니다.
Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
작성자: 고상민

Chain-of-Thought(CoT) Prompting은 LLM의 Multi-step Reasoning Ability를 매우 크게 높여줍니다. 직관적으로 CoT의 큰 폭의 성능 향상은 논리적이고 올바른 여러 단계의 Reasoning Step을 거쳤기 때문이라 생각됩니다. 이 논문의 실험 결과, 올바르지 않은 Reasoning Step을 거친 CoT로도 보통 CoT로 얻을 수 있는 성능의 80~90% 성능을 얻을 수 있음을 확인했습니다.
이 실험 결과는 LLM에서 CoT Prompting이 왜 잘 되는지에 대한 질문을 던집니다. 추가적인 실험 결과, 논리적인 근거들이 Query와 얼마나 Relevant한지, 올바른 순서로 Reasoning이 진행되었는지가 CoT의 성능 향상에 중요한 요인임을 확인하였습니다. 이 발견은 LLM이 Reason in Context를 하는지 여부에 대한 질문을 열었으며 CoT의 원리에 대한 더 깊은 이해를 할 수 있게 합니다.
Can Large Language Models Be an Alternative to Human Evaluations?
작성자: 정다운
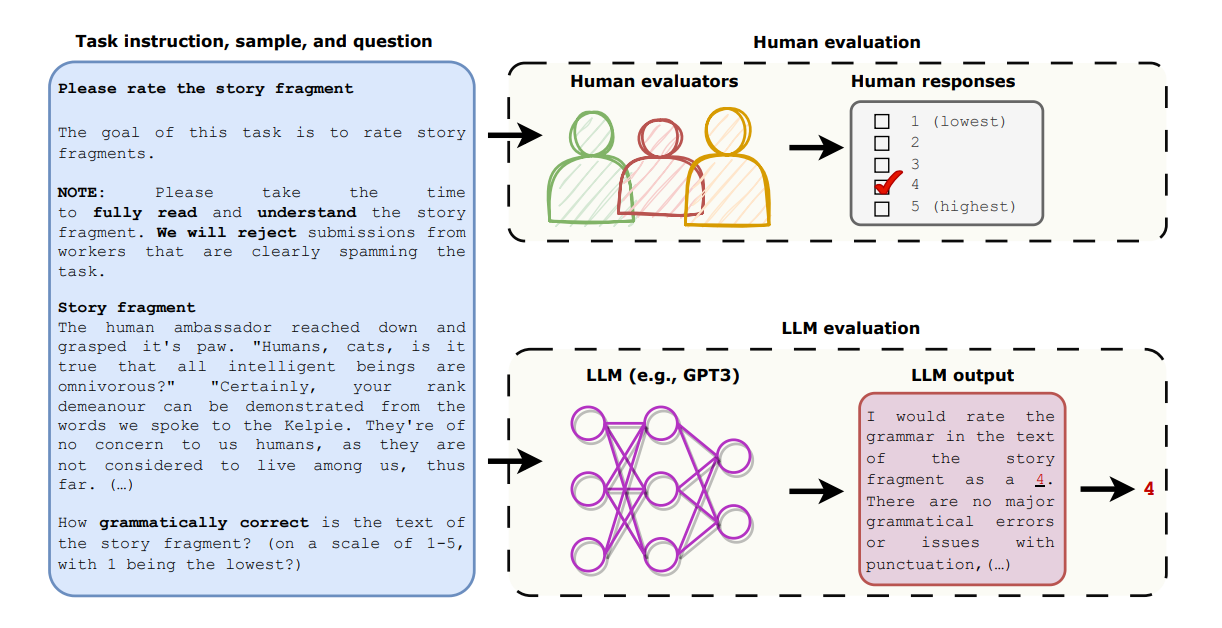
Automatic Evaluation이 어려운 NLP 태스크들은 사람들이 직접 모델을 평가하는 경우가 많습니다. 하지만, 사람이 직접 평가할 때는 재현성 및 일관성 등의 문제가 있습니다. 최근 LLMs은 언어에 대한 이해를 바탕으로 사람의 평가를 대체할 수 있을 거란 가능성을 보여주고 있습니다.
본 논문은 Open-Ended Story Generation 태스크 및 Adversarial Attack 태스크에서 ChatGPT의 평가와 사람의 평가를 비교하여 LLM 평가의 장단점을 분석한 결과, LLM은 사람에 비해 재현성이 높고 비용적으로 저렴하며 각 평가 예시를 독립적으로 평가할 수 있다는 장점이 있지만, 사실 여부가 중요한 태스크에 부적합하고, 평가 결과에 편향이 있을 수도 있다는 단점을 확인했습니다.
Benchmarking Large Language Model Capabilities for Conditional Generation
작성자: 이성현
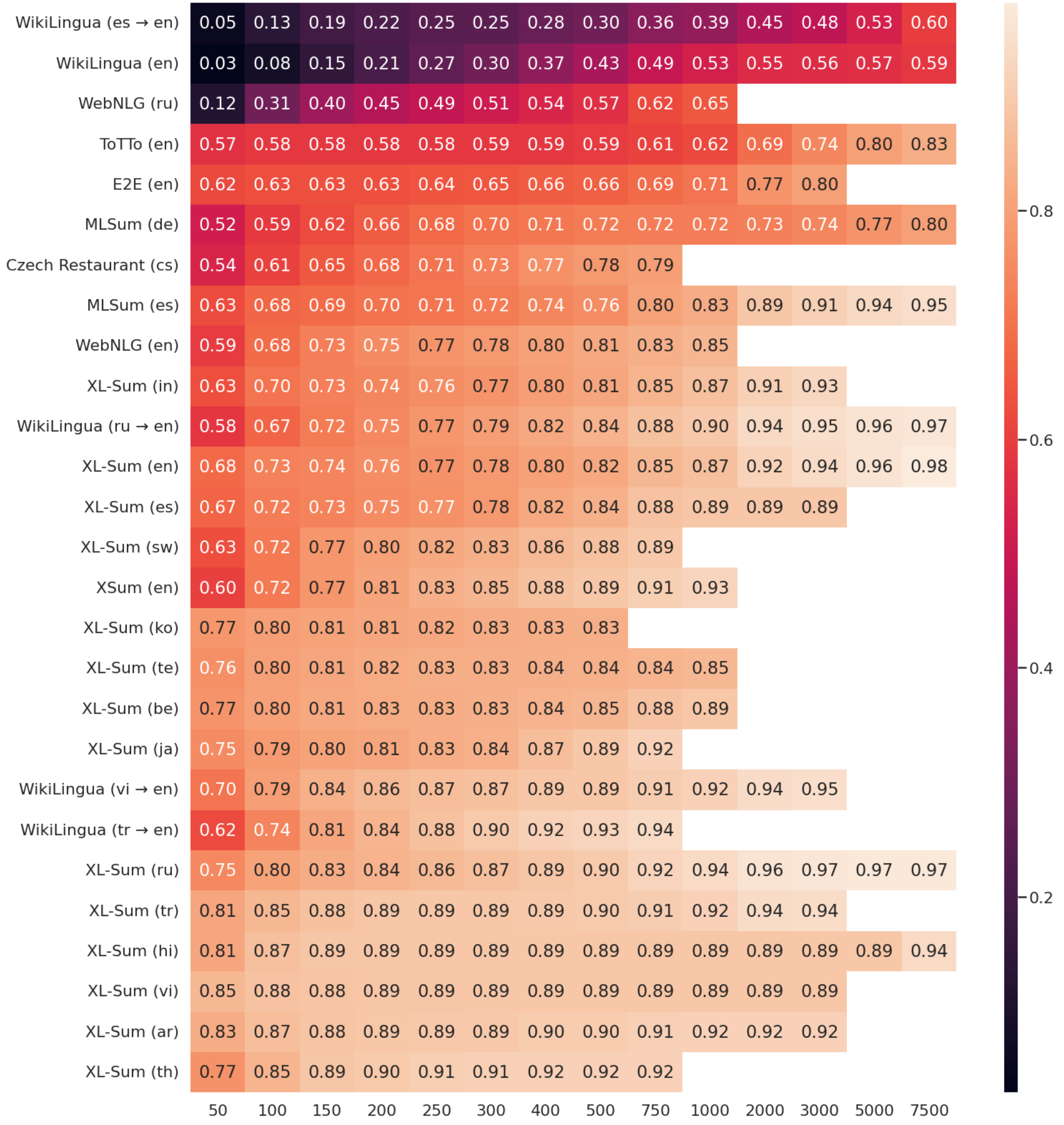
이 연구는 “어떻게 해야 학습된 모델들의 자연어 생성 능력을 평가하고 공정하게 비교할 수 있을까?” 라는 근본적인 문제에 대해서 답하려고 합니다. 이를 위해, 기존의 다양한 최신 사전학습 모델들을 다국어를 포함한 다양한 테스크에서 Few-shot Prompting과 Fine-tuning 방법론을 모두 적용해 평가해봅니다. 연구진들이 발견한 실험 결과들 중 인상깊었던 점은 테스크마다 Few-shot Prompting과 Fine-tuning했을 때의 성능 차이가 크기 때문에 Few-shot Prompting만으로 언어 모델의 능력을 비교하기는 어렵다는 것입니다. 또한, Few-shot Prompting의 경우, 프롬프트를 작성할 때 모델 간 공정한 비교를 위해 특정 모델의 특성에 치우치지 않도록 작성하는 것을 추천한다고 합니다. 마지막으로, 저자들은 언어 모델은 빠른 속도로 다양한 테스크에 수렴할 수 있기 때문에 하나의 테스크에 대해서 많은 예제를 수집하기 보다 다양한 테스크에 적은 예제를 수집해 언어 모델의 다양한 측면을 포괄적으로 평가하도록 발전하는 것을 추천합니다.
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
작성자: 강경필
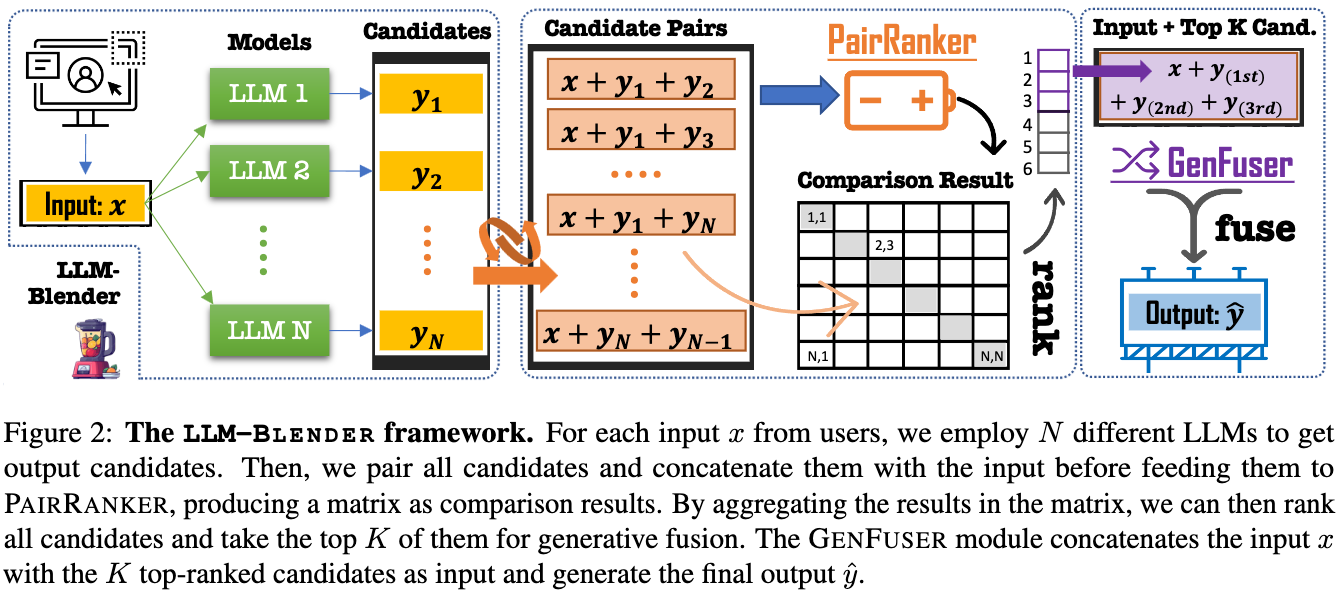
이 연구에서는 LLM-Blender라는 방법론을 제안하고 있습니다. LLM-Blender는 크게 PairRanker와 GenFuser로 이루어져 있습니다. PairRanker는 LLM 모델들이 생성한 $N$ 개의 문장들의 모든 쌍에 대해서 상대 평가 스코어를 계산하하고 이를 합산하여 답변들의 순위를 계산하고, $K$ 개의 상위 답변을 뽑게 됩니다. GenFuser는 Seq2Seq 모델로 컨텍스트와 $K$ 개의 상위 답변들을 Concat하여 입력으로 넣어, 컨텍스트와 상위 답변들을 참고하여 개선된 답변을 생성하게 됩니다. 이렇게 Adaptive하게 각 예제별로 LLM 모델들의 답변들을 취사선택하고, 선택한 좋은 답변들을 참고하여 더 좋은 답변을 생성하게 됩니다.
이 논문은 LLM들을 효과적으로 블렌딩하여 더 좋은 성능을 낼 수 있음을 보여주었습니다. 하지만 추론시 여러 LLM들의 추론 또한 필요하기 때문에 추론 시간이 더 오래 걸리는 단점이 있습니다. 그래서 앞으로 생성된 문장 기준이 아니라 특정 Space나 모델 Weight 자체를 블렌딩하는 등 더 효율적인 방식의 연구들도 나오지 않을까 생각됩니다. 사전학습에는 많은 비용이 소모가 되는데, 이 연구처럼 공개된 LLM들을 앙상블하면 적은 비용으로도 더 좋은 LLM을 만들 수 있지 않을까 기대됩니다.
NLPositionality: Characterizing Design Biases of Datasets and Models
작성자: 구상준
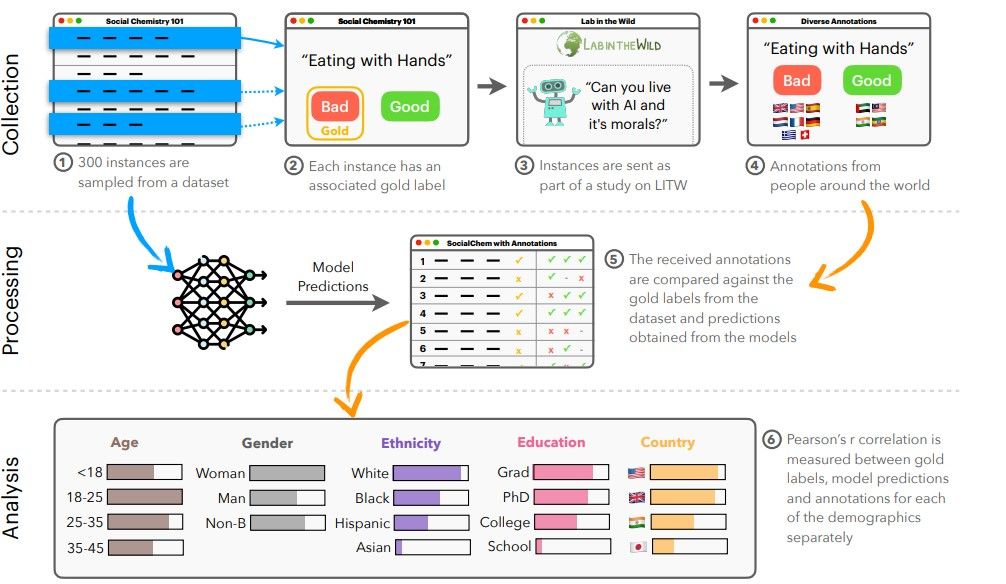
NLP 모델, 대형 생성 모델은 주로 영어권 연구자들이 영어권 사용자들의 데이터를 활용해서 만들어져 왔습니다. 그러다보니, 다른 언어를 사용하는 문화권의 윤리를 반영하지 못해 성능이 떨어지는 문제가 있었습니다.
본 저자들은 NLP 모델들과 데이터셋들의 편향을 표현할 수 있는 프레임워크인 NLPositionality 프레임워크를 제안합니다. 논문 저자들은 이미 존재하는 데이터셋들에 대해서 다양한 문화권의 다양한 유형의 레이블러들로 하여금, 새로 레이블을 달도록 주문했습니다. 만약 새 레이블이 기존 레이블과 일치율이 높다면, “기존 모델/데이터셋은 해당 레이블을 단 작업자들과 도덕적 기준이 비슷하다 = 해당 문화권의 도덕적 관점을 견지하고 있다” 라고 해석할 수 있는 것이죠.
논문의 결론은 다음과 같습니다: 1) 현존하는 모델은 인구통계학적 편향이 있으며, 2) 특히 서구 문화권의 관점을 많이 반영하고 있다. 따라서 3) 데이터셋을 만들 때에는, 다양한 레이블러들을 활용하며 획일화된 기준에 의존하는 것은 피해야 한다.
Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
작성자: 이봉석
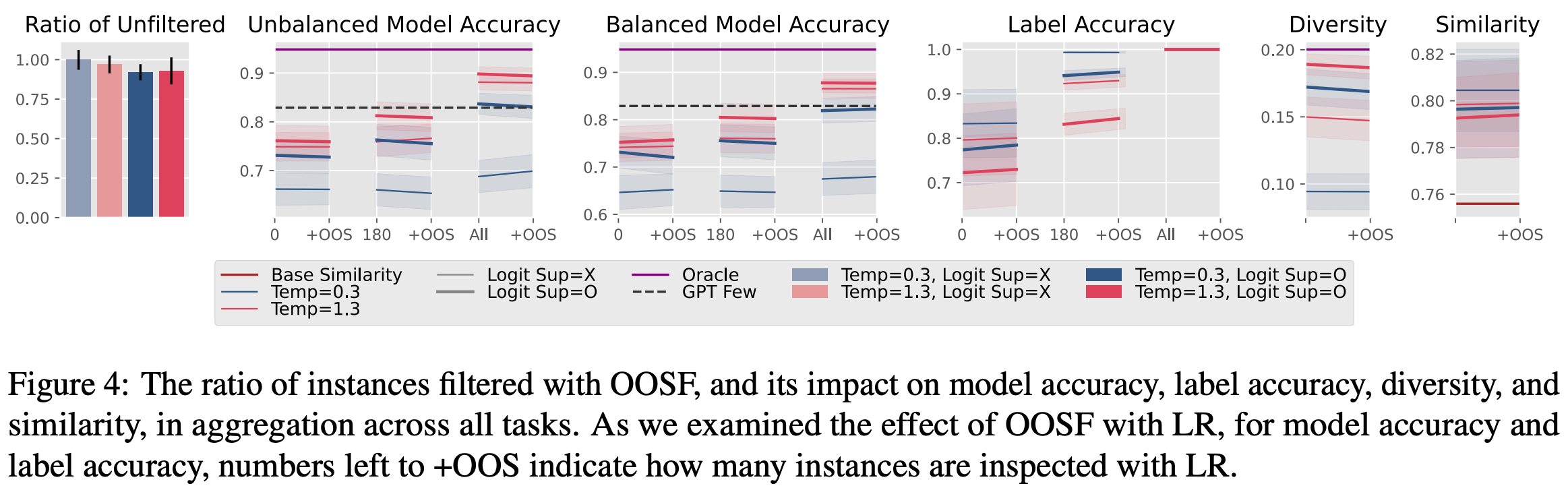
좋은 품질의 데이터는 높은 다양성과 커버리지를 가져야 하며 Target Task와 관련성이 높고 정확한 라벨을 가지고 있어야 합니다. LLM은 다른 모델의 학습데이터와 평가데이터 생성을 위해 사용될 수 있지만 좋은 품질의 데이터를 만들기는 어렵습니다. 본 논문에서는 사람과 AI의 협업을 통해 고품질 데이터를 생성하는 효율적인 방법을 제안합니다. 먼저 두 가지 방식(Logit Suppression, Temperature Sampling)을 사용하여 높은 다양성을 가진 데이터를 LLM으로 생성합니다. 두 방법을 통해 데이터의 다양성을 높일 수는 있었지만, 종종 데이터의 정확성을 희생시키는 경향이 나타났습니다. 이를 해결하기 위해 사람이 두 가지 방식(Label Replacement, Out-of-scope Filtering)으로 개입합니다. Label Replacement 방식을 사용한 데이터를 이용해 모델을 학습했을 때는 높은 성능 향상을 볼 수 있었지만, Out-of-scope Filtering 방식은 성능 변화에 영향을 주지 못했습니다.
Is GPT-3 a Good Data Annotator?
작성자: 류성원
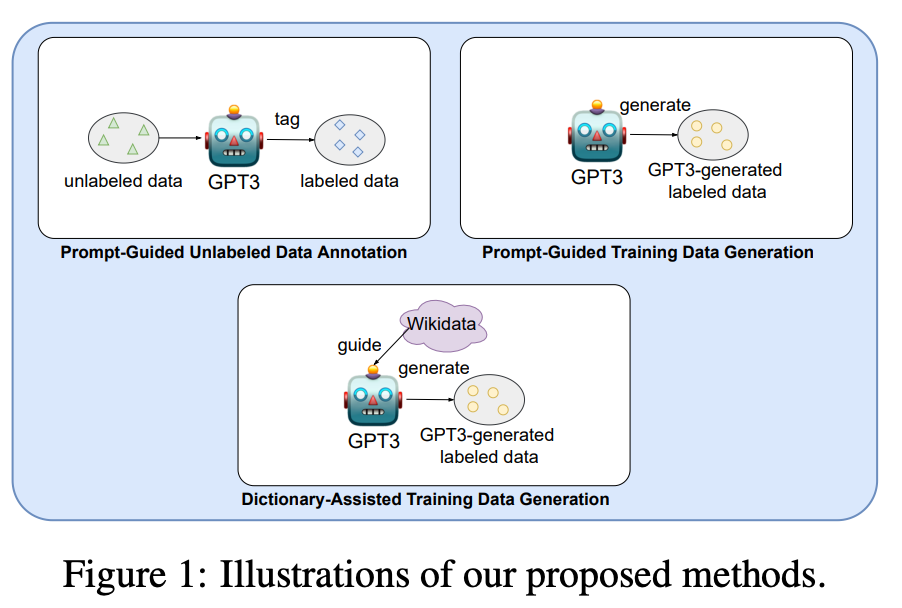
본 연구는 GPT3로 데이터를 제작하는 세 가지 방식을 제시하였습니다.
- Prompt-Guided Unlabeled Data Annotation(PGDA)
- Prompt-Guided Training Data Generation(PGDG)
- Dictionary-Assisted Training Data Generation(DADG)
위의 방법으로 생성한 데이터를 학습시켜서 다양한 NLU Tasks에 대해서 성능이 향상되는지 실험을 했고, Unlabeled 데이터가 필요한 PGDA가 가장 효과적이라는 결과를 얻었습니다. GPT를 이용한 데이터 제작의 초창기 연구라고 보입니다. 성능 향상이 아주 유의미하지 않다는 점, 이미 GPT4가 널리 쓰이는 현재 상황 등이 다소 아쉬웠습니다.
Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
작성자: 송제인

본 연구에서는 In-Context Learning으로 Unseen Task를 풀 때, LLM이 자연어로 작성된 인스트럭션을 얼마나 이해하고 있는지, 어떤 요소가 성능 향상에 큰 영향 혹은 적은 영향을 끼치는지 살펴봅니다. 먼저 인스트럭션을 구성하는 콘텐츠를 Figure 1과 같이 분류 및 정의 하였고, NIv2에 포함된 태스크에 대해서 레이블링하였습니다. 이후에 각 요소를 제거해 보면서 성능 변화를 살펴보았습니다. 분류 태스크에서는 레이블 관련 정보(설명)가 가장 중요했고, 그 외의 정보는 모델의 크기가 증가함에 따라 중요성이 커지는 경향이 있었습니다. 나아가 구문 분석(Parse Tree)을 이용해서 문장을 압축해 보는 실험을 진행했고, LLM이 인스트럭션의 일부만 집중적으로 이해하고 있음을 밝혔습니다. 본 논문에서 활용한 방법론들은 저희의 문제를 풀기 위해 프롬프트를 작성할 때, 성능 향상을 위해 어떤 부분을 개선 혹은 제거해야하는지 고민하는 과정에서 활용해 볼 만할 것 같습니다.
Pre-trained Language Models Can be Fully Zero-Shot Learners
작성자: 이주홍
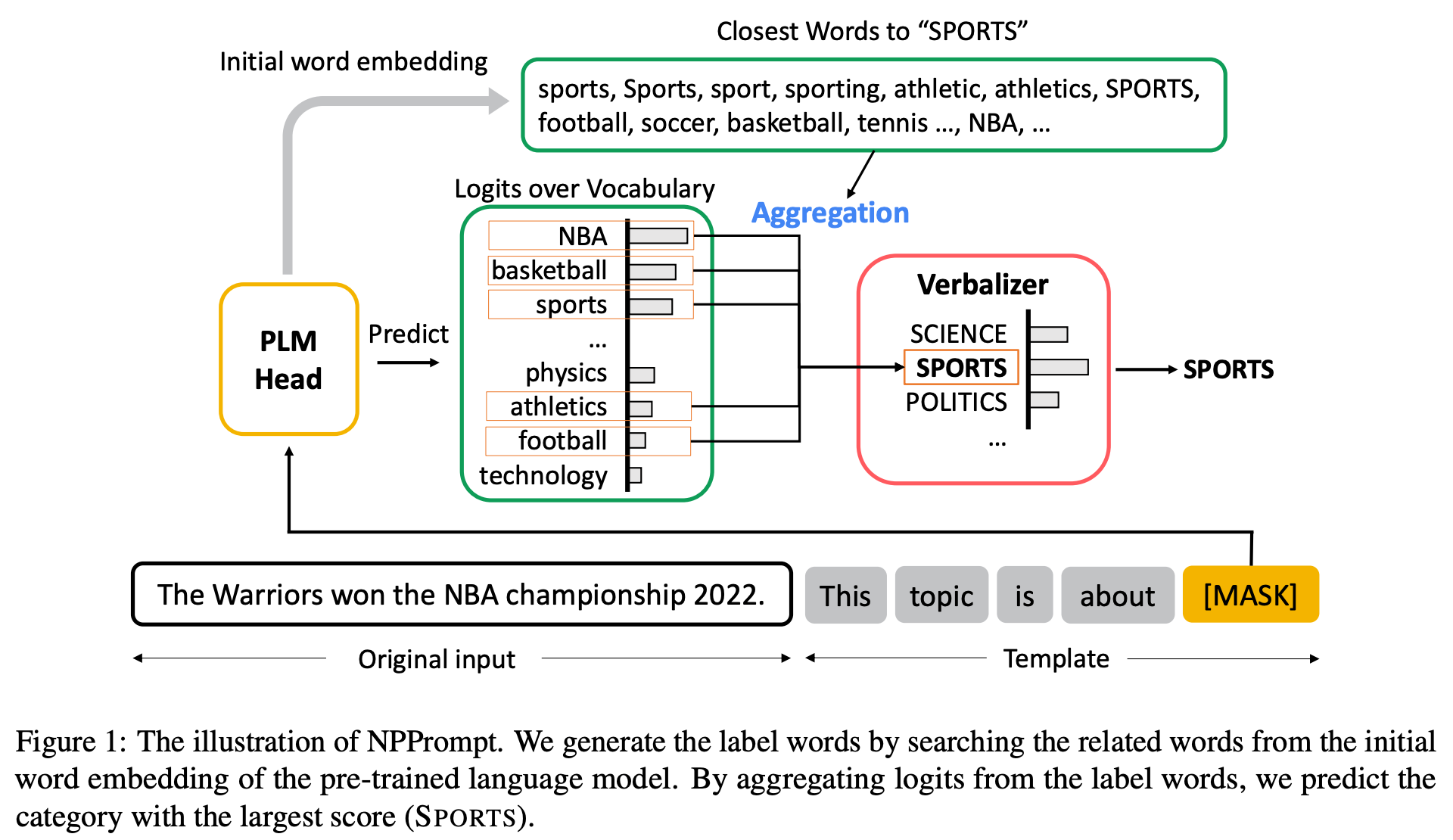
BERT나 RoBERTa와 같은 초기 PLM을 활용하여 Zero-shot Learner로서 Fine-tuning 없이 다양한 NLU 태스크를 푸는 Non-parametric Prompting PLM(NPPrompt)라는 기법을 제안합니다.
태스크의 Original Input 뒤에 태스크에 알맞는 Prompt를 붙이고 [MASK] 위치의 토큰을 예측해서 Label로 변환(Verbalize)합니다.
결과적으로 다양한 Text Classification 태스크와 GLUE 벤치마크에서 GPT-3와 ChatGPT 등을 포함한 Zero-shot 방법론들에 비해 성능을 크게 향상시켰습니다.
Crosslingual Generalization through Multitask Finetuning
작성자: 김대진
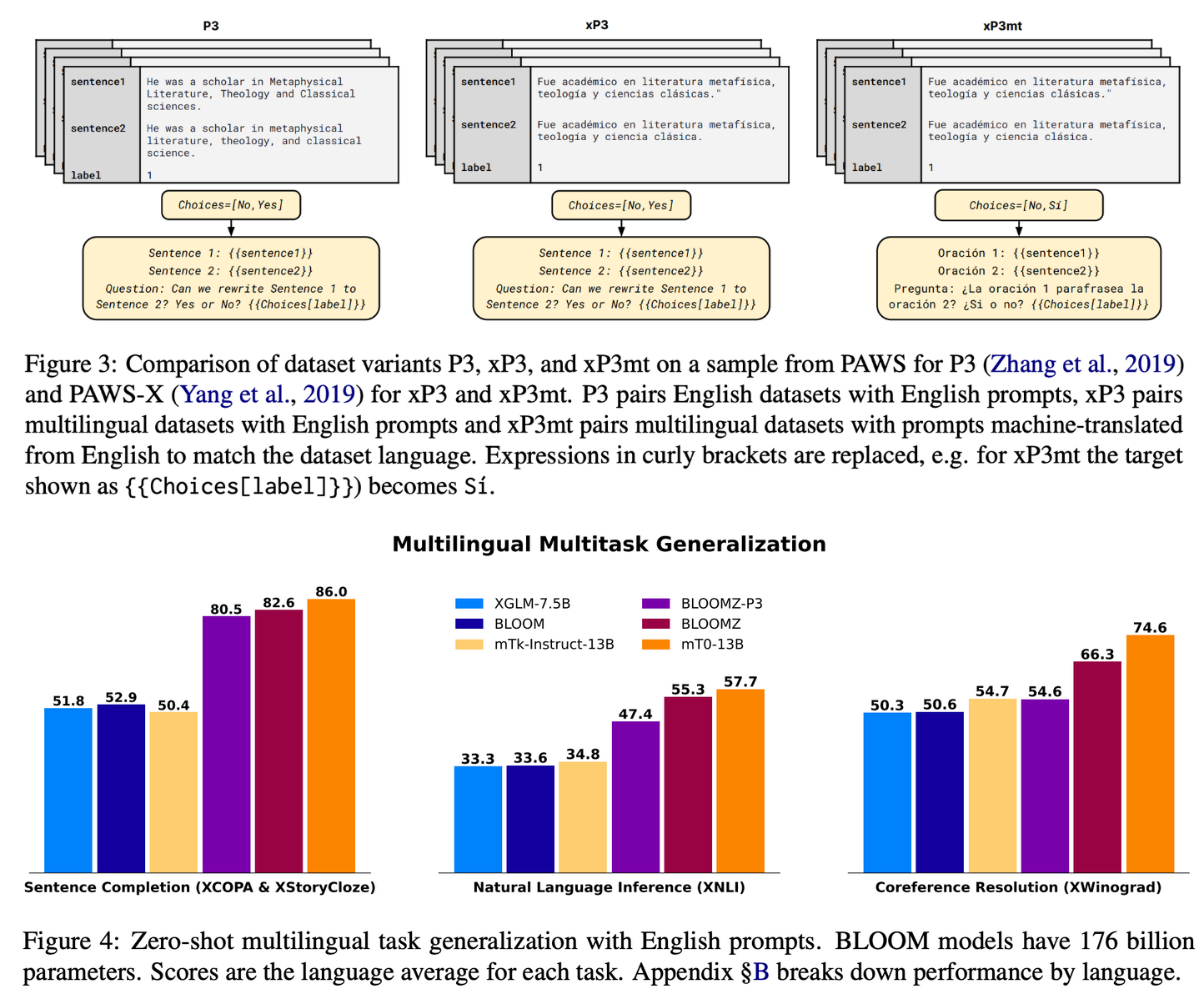
다국어에 대해 파인튜닝했을 때의 효과를 확인하기 위해, BLOOM과 mT5에 대해서 3가지 다른 버전으로 파인튜닝을 진행했습니다.
- P3: 영어 데이터셋만을 이용
- xP3: 다국어 데이터셋에 대해서 영어 프롬프트를 매칭
- xP3mt: 다국어 데이터셋에 대해 해당 언어로 기계번역된 프롬프트를 사용
실험 결과, 다국어 태스크에 대해 영어로만 파인튜닝을 한 경우에도 P3 성능이 크게 올랐으며, 다국어 데이터셋을 사용했을 때는 더욱 성능이 향상되었습니다. 사람이 직접 다국어로 작성한 태스크에 대해서는 기계번역을 이용한 모델이 좋은 성능을 보였습니다.
Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
작성자: 서상우
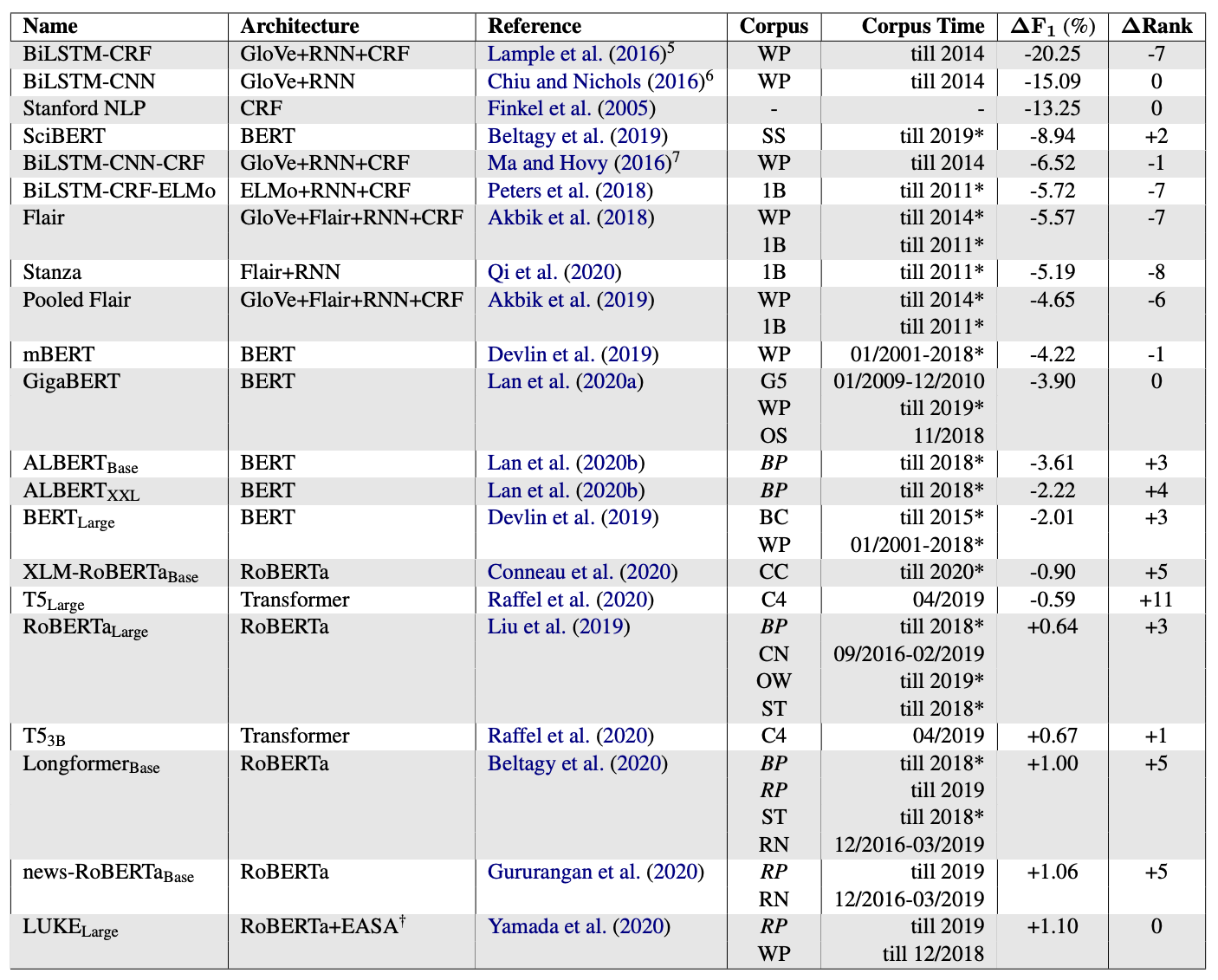
CoNLL-2003은 English NER 분야에서 매우 널리 사용되는 데이터 셋이지만 20년 전에 만들어진 테스트 셋을 그대로 사용하여 평가하기 때문에 최신 데이터에서 대해서는 얼마나 일반화가 이루어지고 있는지를 평가하지 못합니다. 본 논문은 최신 버전의 NER 테스트 셋인 CoNLL++을 제안하여 기존의 NER 모델들이 최신의 테스트 셋에서도 충분히 일반화가 되고 있는지를 평가합니다. 실제로 평가해보면 RoBERTa 및 T5 같은 Pre-trained Transformer에 대해서는 충분히 일반화가 잘 이루어지는 반면에 특정한 다른 데이터셋에 대해서는 성능이 기존 테스트셋에 비해 하락하는 결과를 보이기도 합니다. 논문에서는 이를 좀 더 분석하여 Model Architecture, Model Parameters의 수, Pre-training corpus의 시기, Fine-tuning 데이터의 수등이 일반화 능력에 영향을 미치는 요소라고 보고하였습니다.
Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
작성자: 이녕우
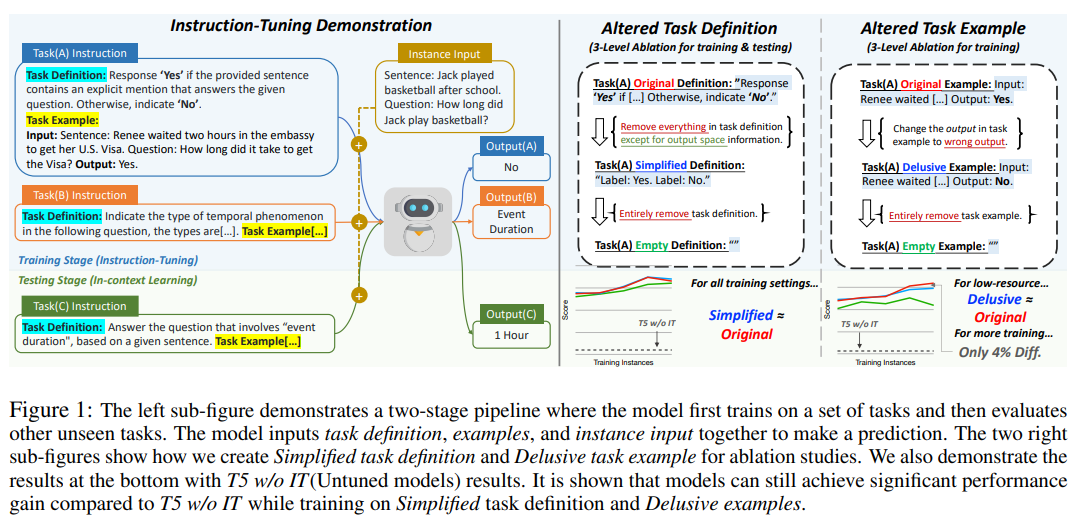
Instruction Tuning(IT)은 대규모 언어 모델에 작업 정의와 예제로 구성된 추가 컨텍스트를 학습하는 일종의 Fine-Tuning 과정입니다. IT를 거친 모델은 그렇지 않은 모델보다 제로샷 작업에서 훨씬 높은 성능을 달성할 수 있습니다. 인상적인 성능 향상에도 불구하고, 모델이 IT 과정에서 배우는 내용은 아직 충분히 연구되지 않았습니다.
본 연구는 학습 데이터셋을 Original, Simplified, Delusive 버전으로 변형하여 모델이 IT 중에 instruction을 어떻게 활용하는지 분석합니다. 실험 결과에 따르면, Simplified 및 Delusive 버전으로 IT한 모델은 Original 버전으로 학습한 모델과 비슷한 성능을 가집니다. 심지어, Simplified 및 Delusive 버전으로 학습한 모델은 제로샷 분류 작업에서 IT 과정을 거치지 않은 T5 모델의 성능을 훨씬 능가합니다. 따라서, 저자들은 현재 IT 모델들이 답변 출력 형식을 학습하는 등의 피상적인 패턴을 학습함으로써 인상적인 결과를 얻었을거라 주장합니다.
본 연구는 IT의 잠재적 취약성을 밝히기 위한 연구이나, 대부분의 실험은 770M~11B parameters 정도 규모의 모델에서만 진행되었습니다. 따라서, 피상적인 패턴 학습은 작은 모델에 국한된 현상일 수 있습니다. 더 큰 모델을 학습하거나 RLHF와 같은 개선된 IT 과정을 거친다면 일반화 능력이 개선될 수 있습니다.
Symbolic Chain-of-Thought Distillation: Small Models Can Also “Think” Step-by-Step
작성자: 이재훈
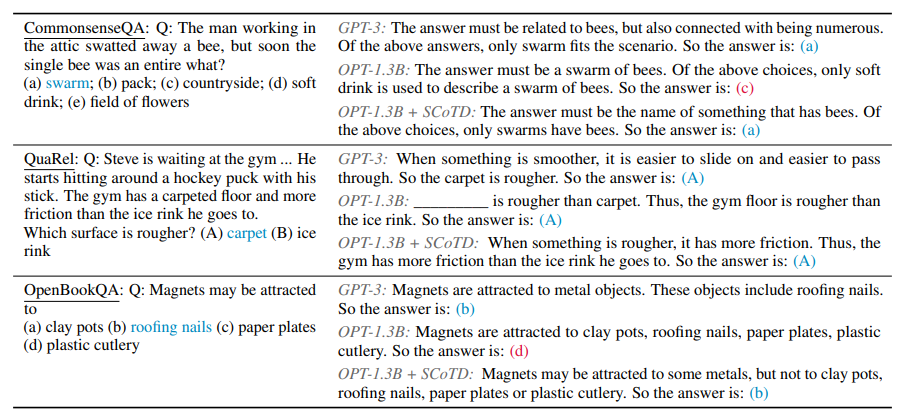
Chain-of-Thought Prompting은 모델의 추론적인 사고를 통해 문제를 해결하는 방법으로 이 능력은 보통 충분히 큰 LLM에서 나타나는 현상입니다. 본 논문에서는 작은 모델(OPT 125M - 1.3B)로도 CoT Prompting을 통해 능력을 발현시킬 수 있도록 큰 모델의 CoT 능력을 보고 배우는 Symbolic Chain-of-Thought Distillation(SCoTD) 방법을 제안하였습니다. 실험을 통해 SCoTD 방법으로 학습한 작은 모델들의 Downstream Task 성능이 오르는 것을 확인했습니다. 그리고 Teacher Model의 CoT Sample 개수를 늘려서 같은 문제에 대한 다양한 추론 방식을 배우고 CoT Sample에서 정답이 틀린 경우를 필터링하여 배울수록 Student Model의 성능이 더 오른다고 주장합니다.
PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
작성자: 김지오
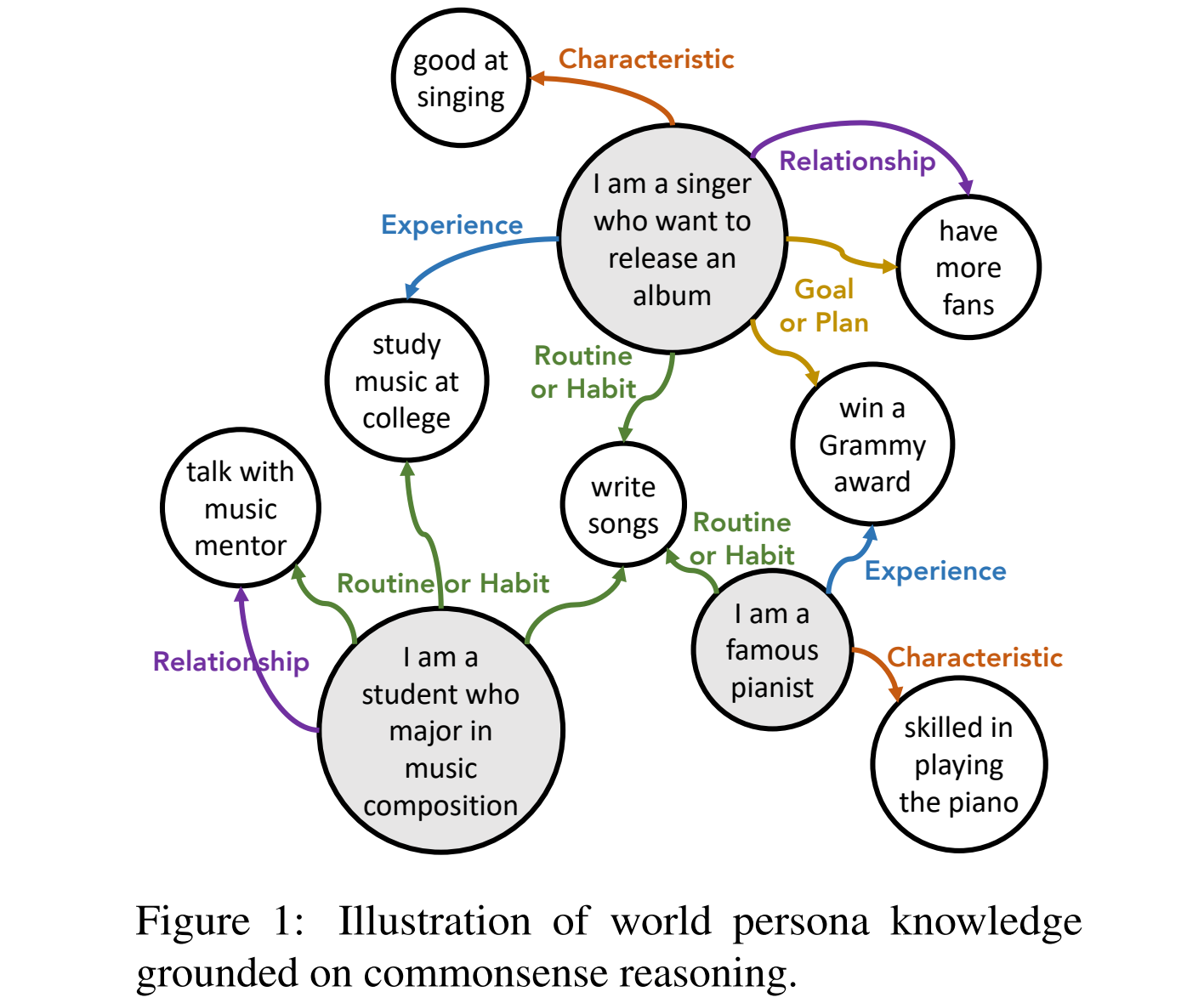
한 페르소나는 여러 특징을 가지고 있고, 그 특징은 또 다른 페르소나와 공유되기도 합니다. 예를 들어, “가수”와 “작곡과 학생”은 “음악 대학교를 나왔다”는 경험적 특징을 공유할 수 있습니다. 이처럼, 저자는 한 페르소나가 가질 수 있는 특징을 5가지로 유형화를 했습니다: Characteristics, Routines or Habits, Goals or Plans, Experiences, Relationships. 그리고 페르소나와 그 페르소나가 가질 수 있는 특징을 Knowledge Graph 형태로 연결해서 PeaCoK을 만들었습니다. 저자는 Dialogue System에서 에이전트의 페르소나를 풍부하게 구축할 때 PeaCoK을 사용했다고 하며 방법은 다음과 같습니다.
- 에이전트의 프로필에 있는 모든 문장과, 에이전트가 발화한 모든 문장을 추출합니다.
- Off-the-shelf인 ComFact를 이용해서 추출된 문장과 관련된 Facts들을 PeaCoK에서 추출합니다.
- 그 중에서 Generic한 것들을 제거합니다.
- 랜덤하게 5개 샘플링하고, 그것을 자연스러운 문장으로 바꿔서 페르소나를 확장합니다.
Towards Boosting the Open-Domain Chatbot with Human Feedback
작성자: 고유미

기존의 Open-Domain Chatbot을 위한 모델들은 주로 소셜 미디어의 댓글 데이터를 활용하여 학습합니다. 본 논문에서는 실제 사람간의 데이터 부족, 모델과 사람의 선호도 불일치 문제를 해결하고자 합니다. Diamante라고 정의한 저자의 접근 방식에는 크게 두 가지 방법이 있는데, 첫 번째는 위와 같은 레이블링 환경에서 모델이 생성한 응답 중 사람이 답변을 선택하거나 수정, 또는 직접 작성하는 방법입니다. 이 과정을 최소 7라운드 동안 반복하여 어느 정도의 길이가 보장되는 대화를 효율적, 고품질로 만들 수 있습니다. 두 번째는 모델을 사람의 선호도와 일치시키기 위해서 Generation-Evaluation Training을 하는 것입니다. 답변 선택 과정에서 암묵적으로 드러나는 사람의 선호도를 활용하여, 고품질의 응답 생성과 사람의 선호도 추정을 동시에 최적화합니다. 이 과정을 통해 학습된 모델은 현재 상용 중국어 대화 모델들보다 Coherence, Informativeness, Safety, Engagingness 측면에서 모두 우월함을 보여줍니다.
Large Language Models Are Reasoning Teachers
작성자: 최예찬
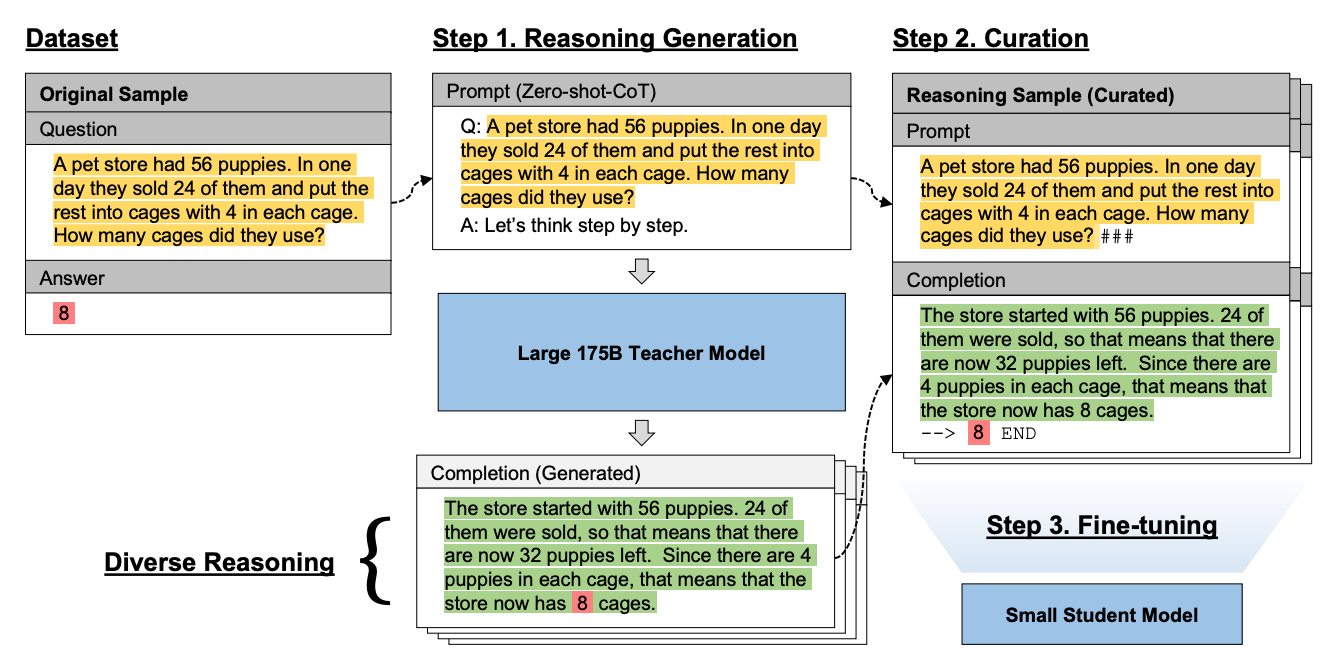
Chain-of-thought(CoT) 프롬프팅 기법은 언어 모델을 이용해 복잡한 추론 과정을 수행할 수 있습니다. 하지만, CoT 프롬프팅 기법은 GPT-3 와 같이 쉽게 서빙하기 어려운 대규모 언어 모델에 의존적이라는 한계점을 가지고 있습니다. 이 논문에서는, Fine-tune-CoT이라는 방법론을 제안하여, 상대적으로 작은 규모의 LM도 상당한 추론 능력을 갖출 수 있게 하였습니다.
Fine-tune-CoT 방법론이란, 상대적으로 거대한 언어모델을 Teacher로 상정한 후, 복잡한 작업에 대해 서로 다른 추론 경로를 가진 다양한 Output을 도출합니다. 이 과정에서 사용된 Prompt - Completion Output을 상대적으로 작은 0.3B의 Student 언어모델에 파인튜닝시켜, 뛰어난 추론 능력을 학습시킵니다.
결과적으로, MultiArith Dataset 을 이용한 실험에서 Baseline 모델에 Few-shot-CoT을 이용했을 때나 단순 Fine-tuning 모델보다 더 좋은 성능을 보여줬으며, 심지어 Shuffled Objects나 Coin Flip 같은 과제에서는 1.3B나 6.7B의 Teacher 모델을 능가했습니다.
Weaker Than You Think: A Critical Look at Weakly Supervised Learning
작성자: 김수정
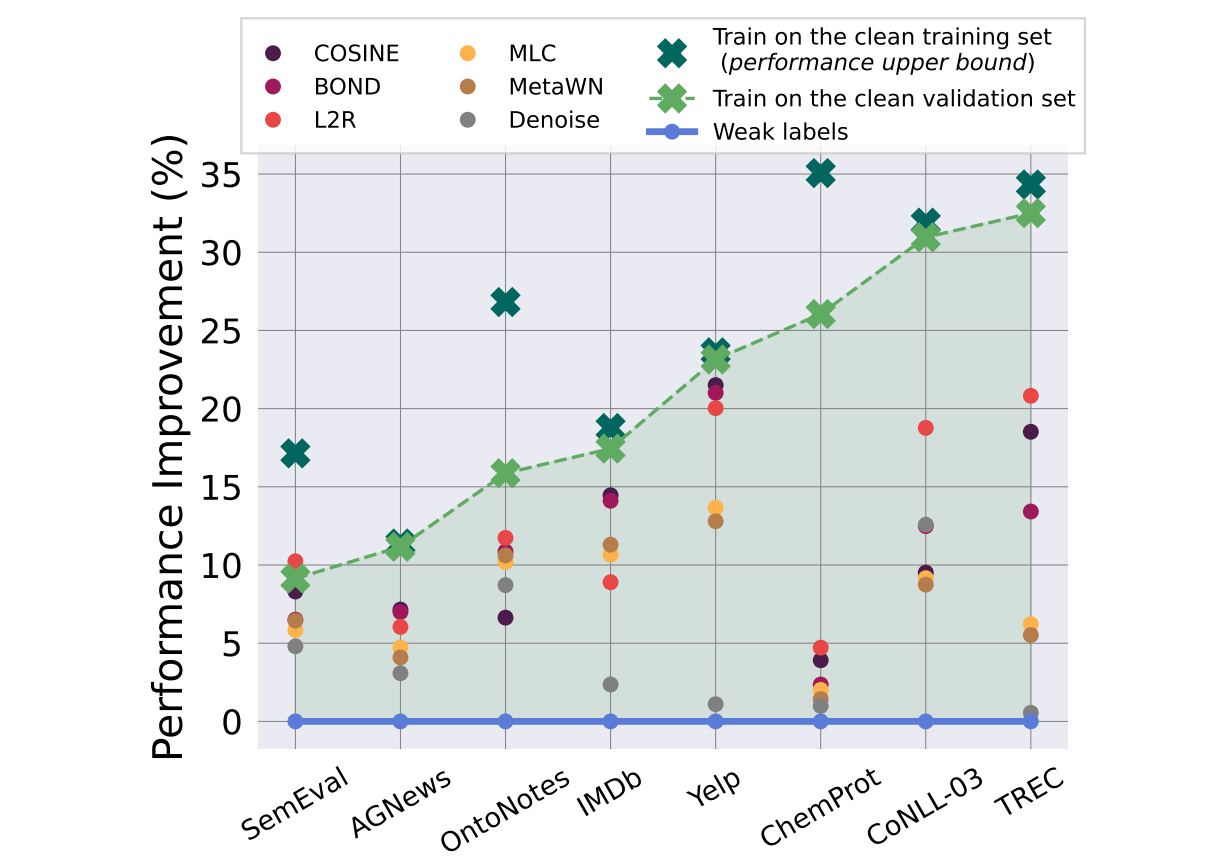
Weakly Supervised Learning(WSL)은 적은 리소스의 Noisy Data로 학습함으로써 비싼 휴먼 레이블링 보틀넥을 줄여주는 기법으로 인기가 많습니다. 하지만 본 논문의 저자들은 기존 WSL의 성능은 Clean Validation set에 매우 의존적이며, 해당 Clean Validation Splits을 간단하게 Fine-tuning하는 것이 WSL보다 훨씬 모델 성능을 향상시키는 실용적인 방법이라고 말합니다. 실제로 Clean Validation Sample이 없을 때 Weak Labels보다도 성능이 하락함을 보여줍니다. 결과적으로 Clean한 Validation Set에 의존하는 복잡한 WSL 방법론은 상당히 과평가되었으며 실제 상황에서 실용적이지 않은 방법론이라고 주장합니다.