Apache Beam으로 머신러닝 데이터 파이프라인 구축하기 1편 - 도입과 사용
빠르고 효율적인 병렬 데이터 파이프라인 도입기


핑퐁팀은 Apache Beam을 사용하여 사용자 데이터의 가명처리, 대규모 데이터 정제, 임베딩 벡터를 사용한 데이터 샘플링과 TFRecord 변환에 이르는 다양한 작업을 처리하고 있습니다. 핑퐁팀이 왜 Apache Beam을 사용하는지, 어떻게 사용하는지 자세하게 소개해볼게요.
Apache Beam이란?
Apache Beam은 Batch 혹은 Stream으로 주어지는 데이터에 대해 효율적으로 병렬 처리할 수 있도록 해주는 파이프라인 모델이에요. Beam SDK를 사용하여 파이프라인을 만들면 여러 개의 Runner에서 이를 효율적으로 실행할 수 있도록 해줘요.
Beam SDK는 Java, Python, Go의 세 언어로 제공되므로, 각자의 전문성과 환경에 맞게 사용할 수 있어요.
또한 Portability SDK를 통해 다른 언어로 기술되어 있는 파이프라인 Op을 가져와서 사용할 수도 있죠.
예를 들어 ReadFromKafka 와 같은 I/O 인터페이스는 Java로 완성도 있게 구현된 경우가 많아요.
Beam은 Python으로 파이프라인을 만들더라도 이 Op을 포함하여 만들 수 있도록 지원하고, 실행될 때 별도의 Java 실행 환경에서 해당 IO 작업을 수행하는 식으로 처리해요.
반대로 Java로 만들어진 파이프라인에서 Python으로 짜여진 TFX Component를 사용하는 예도 가능하고요.
Runner는 Beam 파이프라인을 실행할 수 있는 일종의 Backend로, 보통 분산 처리를 지원하는 시스템을 사용해요. 대표적으로는 아래 Runner들이 있어요.
- Direct Runner
- 파이프라인을 로컬 환경에서 실행합니다. 보통 디버깅 목적으로 많이 사용해요.
- Portable Runner
- 파이프라인을 컨테이너 환경에서 실행해요.
- Google Cloud Dataflow Runner
- 대표적인 Apache Beam의 Managed Service입니다.
이외에도 Apache Flink, Apache Spark, Apache Samza, Apache Nemo, Hazelcast Jet Runner, Twister2 Runner 등 다양한 종류의 Runner가 있어요. 매우 다양한 Runner들을 제공하기 때문에 각 조직의 상황과 환경에 맞추어 도입할 수 있습니다.
어떤 장점이 있었을까요? 🤔
가장 큰 장점은 매우 큰 크기의 데이터를 병렬로 쪼개서 효율적으로 처리할 수 있다는 점이에요. Beam 파이프라인은 입력으로 들어온 데이터를 작은 처리 단위로 나누고, 수많은 Worker들에게 각 처리 단위를 분배하여 분산 처리하는 방식을 사용합니다. 그러면서도 매우 직관적인 프로그래밍 인터페이스를 제공하기 때문에 쉽고 빠르게 파이프라인을 구축해서 실행해볼 수 있죠.
Direct Runner를 사용해서 로컬 환경에서 디버깅해볼 수 있다는 점도 큰 장점이에요. 여러 개의 Container 기반으로 만들어지거나 DAG가 실행 환경에 강하게 엮인 파이프라인 프레임워크들은 디버깅을 위해 테스트 환경을 별도로 만들어야 하는 경우가 많은데, Beam은 그럴 필요 없이 외부로 향하는 I/O 부분만 잘 처리해준다면 로컬에서 모든 과정을 쉽게 실행해볼 수 있어요.
대부분의 데이터 파이프라인에 잘 어울리기 때문에 간단한 ETL 작업부터 실시간 로그 정제 파이프라인까지 다양한 작업에 사용할 수 있어요. 핑퐁팀은 더 나아가 사용자 데이터의 가명처리, 대규모 코퍼스 정제, 임베딩 벡터를 사용한 데이터 샘플링과 TFRecord 변환 등 머신러닝 과정에서도 Beam을 사용하여 전체 연구 과정을 가속하고 있어요.
핑퐁팀이 Beam을 사용하는 방법
데이터셋 정제 파이프라인
모델 학습을 위해 데이터를 정제할 때는 보통 큰 코퍼스를 읽어와서 여러 가지 처리를 한 후 데이터셋의 형태로 만들어서 저장해요. Beam은 이 과정을 매우 직관적으로 프로그래밍할 수 있도록 지원하고, 동시에 매우 많은 수의 Worker를 통해 병렬로 실행할 수 있도록 해줘요.
핑퐁팀은 파이프라인의 Runner로 Google Cloud의 Dataflow Runner를 사용하고 있습니다. Dataflow가 가진 몇 가지 장점 중 가장 큰 것은 순식간에 몇백 대의 Worker를 만들어서 데이터를 나눠주고 처리하도록 명령할 수 있다는 점이에요. 또한 이 과정에서 데이터 처리 인프라나 클러스터 유지 관리 같은 것에 신경 쓰지 않아도 된다는 점도 매우 큰 장점이죠. 데이터가 Google Cloud Storage와 BigQuery에 적재된 핑퐁팀 연구 환경 특성상 가장 잘 맞는 Runner이기도 합니다.
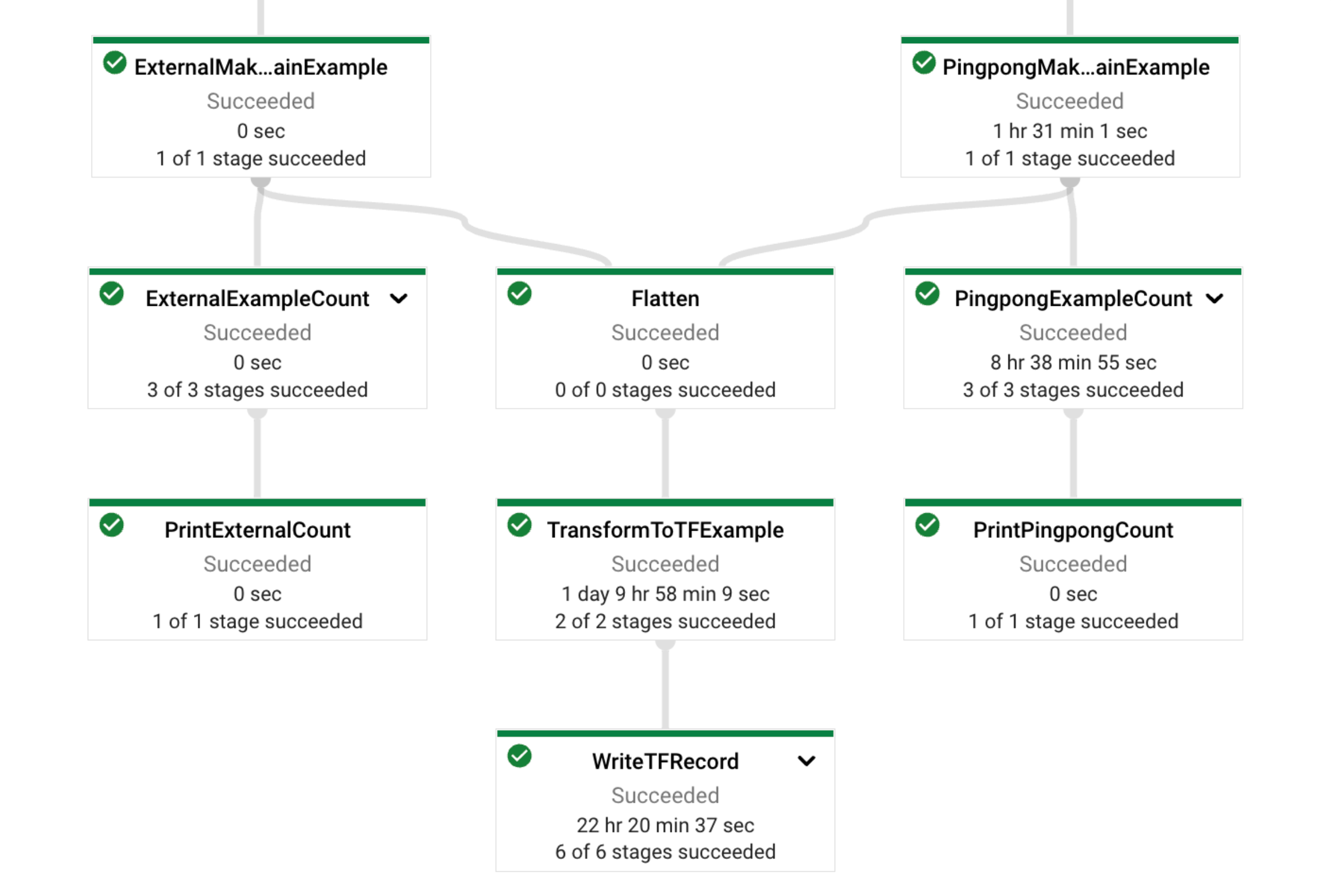
위 그림은 최근 저희가 모델 학습 데이터 정제 용도로 만든 파이프라인의 실행 결과 중 일부를 캡쳐한 거예요.
핑퐁팀이 가지고 있던 내부 데이터와 외부에서 가져온 공개 데이터를 각각 용도에 맞게 정제한 후 하나로 합쳐서 TFRecord 형태로 쓰는 (WriteTFRecord) 파이프라인입니다.
이와 동시에, 각 데이터 소스에서 몇 개의 데이터가 정제되었는지를 세어서 Metric으로 함께 출력하고 있어요. (Print___Count)
이 파이프라인은 하루 이틀 정도의 시간에 Python으로 개발되었고, 약 600GB의 데이터를 처리하는 복잡한 로직을 51분 만에 실행한 후 GCS에 TFRecord 파일들을 출력해냈어요. Beam 파이프라인 도입 이후부터, 머신러닝 모델을 위한 대용량 데이터 정제나 EDA는 더 이상 팀의 속도를 느리게 하지 않아요. ✨
‘이루다’ 서비스 로그의 가명처리와 ETL
‘이루다’ 서비스에서 발생하는 로그들은 Kubernetes 상에서 수집되어 BigQuery에 쌓이게 되며, 핑퐁팀은 이 데이터들을 연구 환경에서 사용하기 위하여 엄격한 기준의 가명처리를 정기적으로 수행해요. 가명처리 로직은 사용자가 발화한 문장에서 휴대폰 번호를 찾아서 지우는 간단한 로직부터 시작해서, 머신러닝 모델을 활용하여 사람의 이름을 찾고 지우거나 치환하는 복잡한 과정들도 포함하고 있어요. 핑퐁팀은 이 과정을 Beam 파이프라인으로 작성하여 효율적으로 유지보수하고 있어요.
Flex Template으로 실행 환경 의존성 분리하기
이 파이프라인은 다양한 의존성(Dependency)을 갖고 있어요. 예를 들어 머신러닝 모델 추론을 위해 TensorFlow나 PyTorch와 같은 거대한 Python Package가 필요하거나, 다운로드 받아오려면 보안 토큰이 필요한 사내 라이브러리들이 있죠. 만약 이 파이프라인을 그냥 Airflow에서 정기적으로 실행하려고 했다면 파이프라인을 빌드하는 과정에서 이 의존성들을 Airflow Worker가 전부 가지고 있어야 하고, 그러면 파이프라인이 새로 생기거나 업데이트할 때마다 그 Worker들의 의존성을 전부 업데이트해줘야 해요. 이러면 유지보수할 때마다 따로 신경 써야 할 게 많겠죠? 😅
Dataflow의 Flex Template으로 이 문제를 해결할 수 있어요. Beam 파이프라인을 Flex Template으로 빌드하게 되면 필요한 의존성과 파이프라인 코드들을 YAML 파일 하나와 상응하는 Docker Image 하나로 묶을 수 있고, 파이프라인 실행을 호출하는 쪽에서는 이 파일 하나만 Dataflow에 제출하면 의존성을 보유하고 있지 않고도 파이프라인을 트리거할 수 있게 되죠.
핑퐁팀은 Flex Template을 빌드해주는 CI/CD 파이프라인을 구축해서 파이프라인이 업데이트될 때마다 Flex Template을 빌드하고, 방금 빌드한 Template Image와 Dataflow Worker가 실행될 Custom Worker Image를 만들어서 GCS와 GCR에 자동으로 업로드하게 해 두었어요.
일정 주기마다 Airflow DAG가 자동으로 트리거되고, DataflowStartFlexTemplateOperator가 Flex Template의 GCS Path를 Dataflow에 제출함으로써 정기적으로 가명처리 파이프라인이 실행되는 것이죠.
덕분에 저희는 아주 편리하게 파이프라인 로직을 업데이트하고 실제 워크로드에 빠르게 반영하고 있어요. 🙂
Beam 파이프라인에서 모델 추론하기: Dataflow Prime
위에서 설명했듯, 가명처리 로직 중에는 머신러닝 모델을 추론해야 하는 것들이 있습니다. Beam 파이프라인에서 머신러닝 모델을 추론하려면 해당 로직 실행 중에는 Worker에 GPU나 TPU 같은 가속기가 붙어야 해요.
GCP의 Dataflow Prime은 기존에 Dataflow가 갖고 있던 기능 이상으로 여러 Feature들을 추가로 지원하며, 그 중 Right Fitting이라는 Feature는 Beam Op에 Resource Hint를 부여할 수 있도록 지원합니다.
pcoll | PTransformUsingGPU().with_resource_hints(
min_ram="4GB",
accelerator="type:nvidia-tesla-k80;count:1;install-nvidia-driver"
)
위 코드는 with_resource_hints 함수를 통해 PTransformUsingGPU PTransform을 실행할 때 최소 4GB의 RAM을 가지면서 NVIDIA Tesla K80 GPU 하나를 가지는 Worker가 필요함을 알리고 있습니다.
이렇게 명시하면 Dataflow에서 파이프라인이 실행될 때 저 Op이 있는 부분은 필요한 사양이 확보된 Worker를 사용하게 됩니다.
리소스나 인프라에 대한 걱정 없이 코드에서 한두 줄만으로 필요한 사양을 요청할 수 있는 것이죠.
다만 주의해야 할 점이 있는데, Reshuffle() 등을 통해 Op들을 적절히 나눠주지 않으면 GPU가 필요 없는 Op에서도 GPU Worker를 쓰게 되어 Compute Engine 요금이 과다하게 청구될 수 있어요.
Worker의 할당 형태를 잘 확인하여 불필요한 요금 청구를 미리 방지해야 해요.
Beam으로 만드는 Custom TFX Component
핑퐁팀은 TensorFlow Extended (TFX) Pipeline을 사용하여 모델 학습 파이프라인을 구축하고 있어요. 여기에서도 Beam에 데이터 처리 작업을 맡기고 있습니다.
TFX에는 ExampleGen이라는, 데이터를 불러와서 파이프라인에 올리는 Op이 있어요.
이 Op은 내부적으로 Beam을 사용해서 데이터를 불러오도록 되어 있고, 애초에 TFX의 DSL에 BaseBeamComponent 구현체가 있기 때문에 커스텀해서 사용할 수 있어요.
핑퐁팀은 사내에서 자주 쓰이는 TFX Component들을 별도 라이브러리로 만들어서 관리하고 있는데, 그중 하나로 사내 Dataset Registry에서 데이터를 읽어오는 ExampleGen을 따로 만들어서 사용하고 있어요. 그래서 아래와 같이 간편하게 로딩해서 사용할 수 있죠.
# 1. 간단한 Dataset 로딩
example_gen = DatasetsExampleGen("klue_sts/train")
# 2. Split을 나눠서 로딩
input_config = Input(
Input.Split(name="train", pattern="klue_sts/v1.1-train")
Input.Split(name="eval", pattern="klue_sts/v1.1-test")
)
example_gen = DatasetsExampleGen(input_config=input_config)
DatasetsExampleGen 은 데이터셋의 이름과 버전이 주어지면 그 데이터셋을 로딩해서 tf.Example 로 반환하는데, 그 과정이 Beam으로 작성되어 있어요.
# 내부 PTransform 구현체의 일부
def expand(self, pipeline: beam.Pipeline) -> beam.PCollection[tf.train.Example]:
return (
pipeline
| "LoadDatasets" >> _LoadDatasets(self.split_pattern)
| "ParseExample" >> beam.ParDo(_TransformToSerialized(self.transform_fn))
| "ToTFExample" >> beam.Map(tf.train.Example.FromString)
)
데이터셋을 Dataset Registry에서 불러오는 DoFn을 작성하고 그것을 Example의 형태로 변환한 후, tf.train.Example.FromString Method를 이용해서 tf.Example 로 반환하도록 구축할 수 있죠.
필요하다면 직접 transform_fn 을 작성해서 Python 기반으로 약간의 전처리를 추가할 수도 있어요.
TFX 표준에 맞게 사내 MLOps 인프라를 연동해서 사용할 수 있어서 연구 과정이 굉장히 편해졌답니다.
마치며
Apache Beam은 핑퐁팀의 전체 연구 과정에서 병목으로 작용하고 있던 여러 데이터 처리 작업을 빠르고 간편하게 핸들링할 수 있게 해주었어요. 도입 후 리서처들과 엔지니어들 모두 크게 만족하면서 사용하고 있어요.
혹시 이 글을 읽으며 “팀에서 다 같이 공부해서 도입해볼까?”하는 생각을 하셨다면, Beam College를 강력하게 추천해 드려요. Google의 Dataflow 엔지니어들과 Beam을 효과적으로 사용하고 있는 여러 회사의 엔지니어들이 약 5일 정도 길이로 들을 수 있는 강의를 매년 하고 있는데, 강의 자체와 강의에서 사용한 코드가 YouTube와 Github에 올라와 있으니 살펴보시길 추천해 드려요. 핑퐁팀도 이 자료를 사용해서 사내 스터디를 진행했답니다. 😊
이번 글에서는 핑퐁팀이 Beam을 도입한 이유와 어떻게 사용하고 있는지를 중점적으로 다루어보았어요. 다음 글에서는 어떻게 하면 더 최적화하여 잘 쓸 수 있는지를 다룰 예정입니다! 아마도 아래와 같은 주제들이 있을 것 같아요.
- 파이프라인 위에서 매우 큰 양의 임베딩 벡터들을 Faiss로 인덱싱하기
- Beam 파이프라인에서 큰 크기의 머신러닝 모델을 병렬적으로 추론하기
Reshuffle()Op의 역할과 사용 방법- 기타 여러 가지 최적화 테크닉들
MLOps의 여러 복잡한 문제들을 저희와 함께 풀어보고 싶으시다면, 언제든 채용 공고를 참고해주세요! 🚀
참고할 만한 페이지들
- Apache Beam 공식 사이트
- Apache Beam 공식 사이트 - Beam Capability Matrix
- Google Cloud Dataflow Documentation
- Dataflow Flex Template Documentation
- Dataflow Prime Right Fitting Documentation
- TFX ExampleGen Documentation
- Beam College 2022