개발자를 위한 AWS 클라우드 보안 (3) - 인프라 보안과 사고 대응
이것만 알아도 클라우드 보안 마스터


핑퐁팀에서 AWS 보안 강화를 위해 작업했던 내용을 AWS Well-Architected Framework와 함께 소개하는 마지막 글로, 인프라 보안 영역과 사고 대응 영역을 소개하려고 합니다. 이전 내용이 궁금하신 분들은 1편과 2편에서 확인하실 수 있습니다.
목차
Infrastructure Security
인프라 보안 영역은 AWS에서 서비스 인프라를 구성하며 발생할 수 있는 보안 위협을 사전에 탐지하고 차단할 수 있는 기술적 보호조치를 적용하는 것을 목표로 합니다.
네트워크 인프라 구성
AWS에서는 VPC를 통해 가상 네트워크 환경을 구성하고 리소스를 네트워크 레벨에서 격리할 수 있습니다. VPC에서도 on-premise 환경과 동일하게 네트워크 보안 위협을 최소화하기 위해 노력해야 합니다. 이를 위해 불필요한 서브넷간 통신을 제한하거나 특정 포트만 트래픽을 허용하는 등의 방법을 소개합니다.
VPC 및 서브넷 구성
VPC는 다양한 AWS 리소스들을 네트워크 레벨에서 격리할 수 있는 단위입니다. AWS 계정을 처음 생성하게 되면 Default VPC가 생성됩니다. Default VPC는 작은 팀에서 별도의 과정 없이 빠르게 네트워크 환경을 구성하는 경우에는 유용하게 사용할 수 있습니다. 그러나 서브넷, 라우팅 테이블 등을 직접 구성하는 경우에는 VPC를 직접 생성해야 합니다.
다음은 VPC 및 서브넷 구성을 고민할 때 고려해야 할 대표적인 예시 항목입니다.
- 팀별로 개발하는 서비스가 다르고, 각 서비스간 통신이 있나요?
- 다중 계정 구조를 사용할 계획이 있나요?
- 여러 리전에서 서비스를 운영할 계획이 있나요?
- 내부에서 동작할 수 있는 인스턴스 개수는 몇 개인가요?
- 법률 또는 내부 정책에 의해 망 분리를 해야 하나요?
VPC와 서브넷은 구성 변경이 어려워 위 항목들 외에도 각각의 비즈니스 상황에 맞는 항목들을 나열해 신중히 고려해야 합니다.
특히, 서브넷은 Availability Zone (AZ)과 연결되어 구성되기 때문에 가용성과도 연관이 있습니다. 핑퐁팀에서는 실제로 서로 다른 AZ에 구성된 서브넷 위에 각각 백엔드 서버를 운영 중이며, Application Load Balancer가 적절히 트래픽을 분산하도록 구성하였습니다. 이를 통해 한 개의 AZ에서 장애가 발생하더라도 다른 AZ에 구성된 백엔드 서버가 트래픽을 처리하도록 하여 서비스 가용성을 높입니다.
불필요한 외부 노출을 방지하기 위해 서브넷은 외부에 직접 노출할 수 있는 Public 서브넷과 외부 노출이 불가능한 Private 서브넷으로 나누어 구성하는 것을 권장합니다. Private 서브넷에 구성된 서비스는 외부에서 직접 접근할 수 없고, 무조건 Public 서브넷을 통해서만 접근할 수 있도록 하는 것입니다. 단, 이 경우 Private 서브넷에서 외부로 요청하기 위해서는 NAT Gateway를 구성해야 합니다.
데이터베이스에 민감한 개인정보가 포함되어 추가 보안 조치가 필요한 경우 Private 서브넷 외에도 데이터베이스 서브넷을 생성할 수 있습니다. 데이터베이스 서브넷은 Private 서브넷을 통해서만 접근할 수 있습니다.
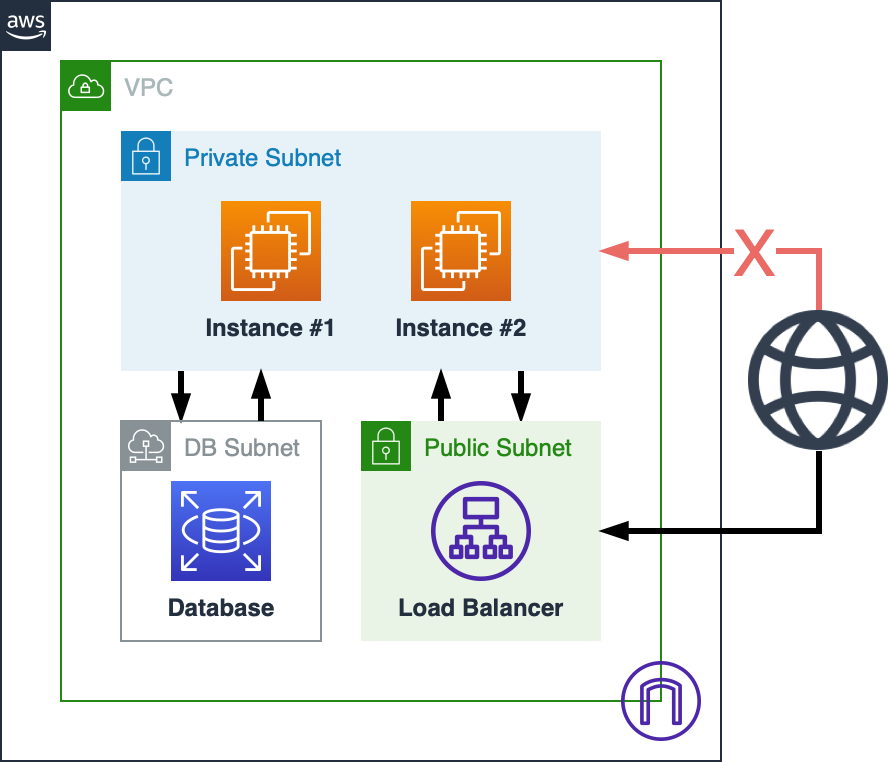
Network ACL 및 Security Group
VPC 및 서브넷을 구성할 때 기본적인 방화벽으로 Network ACL과 Security Group을 사용할 수 있습니다. 서브넷간 통신은 Network ACL로 통제할 수 있고, 인스턴스 단위에서는 Security Group으로 통제할 수 있습니다.
또 다른 큰 차이는 Security Group은 stateful이고, Network ACL은 stateless라는 점입니다. Security Group으로 허용해 받은 inbound 요청은 outbound 트래픽을 허용하지 않아도 응답할 수 있고, 반대로 Network ACL은 outbound 트래픽도 명시적으로 허용해줘야 합니다.
서브넷 단위로 적용하는 Network ACL과 달리 Security Group은 인스턴스 단위에서 적용하기 때문에 인스턴스마다 Security Group을 각각 만들 수도 있습니다. 그러나 Security Group이 무차별적으로 만들어지면 관리하기 어려울 수 있습니다. 그렇기 때문에 공통된 규칙들을 찾아(예를 들어 웹 서버를 구동하는 인스턴스들은 공통으로 80번 또는 443번 포트를 열어야 하므로) 한 개의 Security Group으로 관리해야 합니다.
가장 좋은 방법은 사전에 보안 담당자가 Security Group을 미리 생성해두고, 개발자는 Security Group을 생성할 수 없게 IAM(또는 Control Tower를 사용하는 경우 Guardrails)으로 통제하는 것입니다. 그러나 개발자가 Security Group을 만들고 싶을 때마다 매번 보안 담당자와 소통하게 되면 개발자의 생산성이 저하될 수 있으므로 작은 조직에서는 Security Group을 생성할 수 있는 담당자를 몇 명만 지정하고 생성되는 Security Group들을 문서화하는 것으로 대체할 수 있습니다.
Transit Gateway vs. VPC Peering
여러 개의 VPC를 생성해 사용하는 경우 VPC간 통신이 필요할 수 있습니다. 이때 Transit Gateway 또는 VPC Peering을 고민하게 될 것입니다. 이 두 서비스는 두 개 이상의 VPC를 연결한다는 점은 동일하지만, 그 작동 방식에 있어서 다른 점이 많습니다. VPC 설계 과정에서 Transit Gateway와 VPC Peering 중 무엇을 사용하면 좋을지 설명합니다.
가장 큰 차이점은 VPC Peering은 모든 VPC간의 간선을 연결해야 하고, Transit Gateway는 VPC를 연결만 하면 이 Transit Gateway와 연결된 모든 VPC가 서로 연결된다는 점입니다.
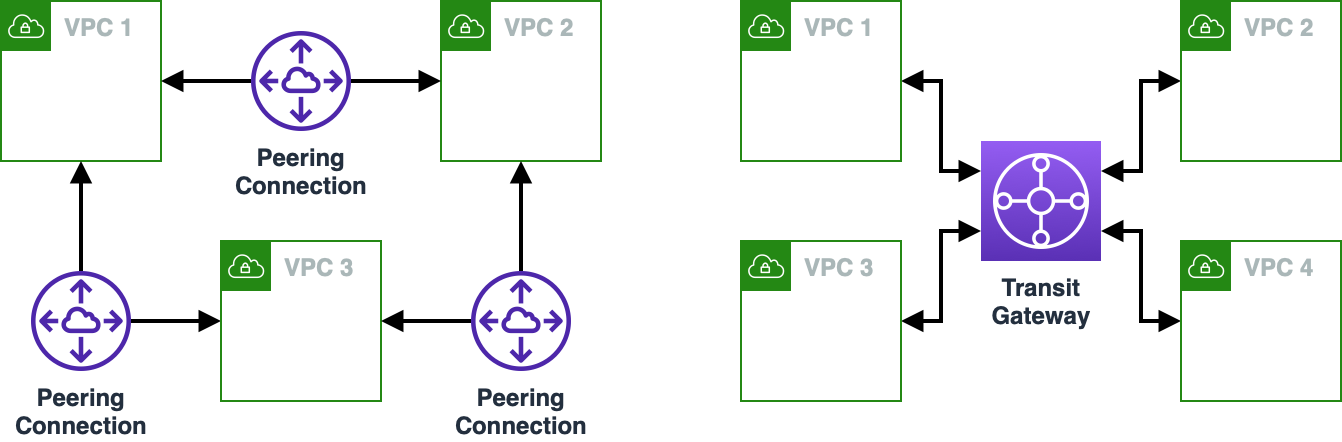
VPC Peering은 리전 내 표준 네트워크 과금 방식이 사용되며 Transit Gateway는 이를 거쳐 가는 트래픽의 양만큼 과금됩니다. 가능하다면(아마 3개의 VPC까지) VPC Peering을 통해 연결하고, 4개 이상의 VPC를 사용하는 등 관리가 힘들어지는 순간 Transit Gateway를 도입하는 게 전략이 될 수 있습니다. 하지만 트래픽이 많으면 비용이 많이 청구될 수 있으니 주의해야 합니다.
다중 계정 환경에서 네트워크 인프라 구성
다중 계정 환경에서 네트워크 인프라를 구성하는 경우 여러 계정에서 공통으로 VPC를 사용하고 싶을 수 있습니다. 그런데 VPC는 기본적으로 계정에 귀속되는 개념이기 때문에 Resource Access Manager(RAM)라는 서비스가 필요합니다. 이 서비스는 한 계정의 리소스를 다른 계정에 공유하여 사용할 수 있게 해줍니다.
VPC를 생성한 계정에서 RAM 서비스를 사용해 네트워크를 공유할 수 있지만, 몇 가지 제약이 있습니다. 먼저, VPC를 직접 공유할 수는 없고 서브넷만 공유할 수 있습니다. 또한, 공유받은 계정에서는 서브넷 설정을 수정할 수 없습니다.
다중 계정 환경에서 권장하는 네트워크 구조는 하나의 계정에서 VPC를 생성하고 관리하고, 그중 일부 서브넷들만 RAM을 통해 다른 계정에 공유한 다음, 나머지 계정에서는 VPC를 생성할 수 없게 권한을 설정하는 것입니다. 다만 이때 주의해야 할 점은 한 계정에서 최대 5개의 VPC만 생성할 수 있고, 그 이상으로 생성하려면 할당량 신청을 해야 한다는 점입니다.
확장 가능성
네트워크 구조를 설계하면서 고려해야 할 부분이 바로 확장 가능성입니다. 특히 스타트업과 같은 소규모 팀에서는 새로운 서비스가 개발되고, 잘 운영될 것 같았던 서비스가 종료되거나, 같은 서비스더라도 내부 구성이 완전히 달라지는 경우 등 구성 변경이 자주 발생할 수 있습니다. 그렇기 때문에 현재 비즈니스 상황에 맞는 확장 및 변경 가능성을 충분히 고려하여 설계하시길 바랍니다.
설계 과정에서 확장 및 변경 가능성을 고려하는 것만큼 중요한 게 있다면 바로 문서화입니다. 현재 서비스가 어떻게 구성되어 있고, 서비스가 추가, 변경되는 상황에서 어떻게 네트워크 구성을 변경해야 할지 가이드라인 문서를 만들어 공유해야 합니다. 실제로 핑퐁팀에서는 AWS 클라우드에서 구성한 내용과 가이드라인을 하나의 문서로 모아 누구나 보고 구성을 이해할 수 있도록 공유하고 있습니다.
방어
VPC와 서브넷 구성을 완료했다면 이제는 외부 네트워크에서 들어오는 보안 위협을 막아야 합니다. 이번에는 방어에 초점을 맞춰 방화벽 서비스 2가지를 소개합니다.
WAF
만약 팀에서 웹 서비스를 운영 중이라면 네트워크 레이어뿐만 아니라 애플리케이션 레이어 보안에도 신경 써야 합니다. 이때 고려할 수 있는 게 바로 Web Application Firewall(WAF)입니다. WAF는 웹 애플리케이션 레벨에서 SQL Injection, XSS와 같은 잘 알려진 취약점에 대한 방어를 제공하는 방화벽입니다.
WAF는 AWS만의 개념이 아니고 웹 서버 방화벽으로써 이미 많은 연구가 되었던 분야입니다. 즉, 이미 상용 WAF 솔루션이 매우 많고 물리 서버를 운영 중인 조직의 경우에는 이미 WAF를 도입하여 사용 중일 수 있습니다. 클라우드에서 서비스를 운영하더라도 충분히 기존의 상용 WAF 솔루션을 도입하여 활용할 수 있습니다.
상용 WAF 솔루션을 도입하기에 비용이나 인력이 부족한 경우, AWS에서 제공하는 WAF 서비스를 사용하여 간편하게 적용할 수 있습니다. AWS WAF는 CloudFront, Application Load Balancer(ALB), API Gateway 등에 손쉽게 붙여 웹 트래픽을 방어할 수 있습니다.
AWS WAF 서비스는 전 세계적으로 보고된 침해사고 패턴들을 모아 관리형 규칙 형태로 제공하고, 이 중 필요한 규칙을 선택하여 적용할 수 있습니다. 또한 관리형 규칙은 자동으로 업데이트되므로, 규칙에 대해서 일일이 신경 쓰지 않아도 된다는 장점이 있습니다.
WAF의 경우에는 기본적인 접속 정보를 담은 WAF ACL Log를 남길 수 있습니다. 어떻게 로그를 수집하고 모니터링할지 고민되신다면 이전 글을 참고해주세요.
Network Firewall
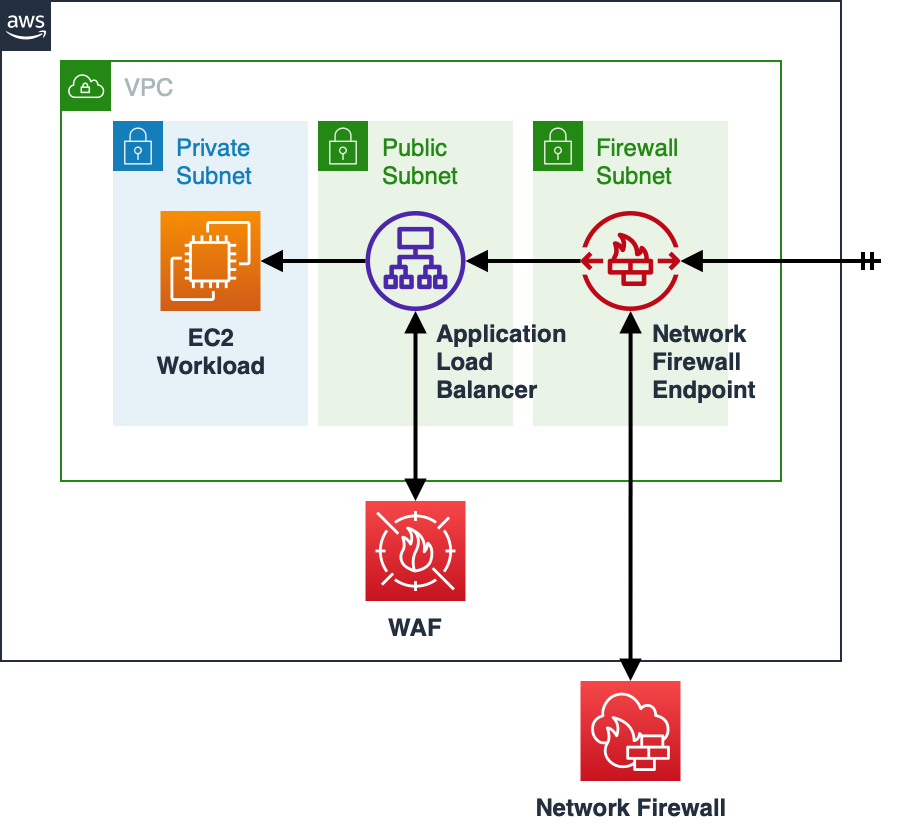
WAF는 애플리케이션 레이어에서 보안을 제공합니다. 그러나 전통적인 방화벽은 네트워크 레이어에서 동작합니다. 네트워크 레이어 방화벽을 도입하면서 클라우드의 이점은 그대로 유지하고 싶은 경우 AWS Network Firewall을 고려해볼 수 있습니다.
WAF에 비해 Network Firewall은 더 낮은 레이어에서 규칙을 설정할 수 있기 때문에 훨씬 더 범용적으로 사용할 수 있습니다. 예를 들어 DDoS 공격을 받아 특정 IP 목록을 차단해야 하는 경우 WAF보다는 Network Firewall이 훨씬 더 효과적입니다.
다만 Network Firewall은 구성이 복잡합니다. Network Firewall 전용 서브넷을 생성하고, Network Firewall Endpoint를 만들어야 합니다. 이 Endpoint가 AWS Network Firewall 서비스와 통신하며 방화벽 서비스를 제공합니다. AWS를 통해 WAF와 Network Firewall을 모두 구성한 경우 아래와 같은 구조로 통신하게 됩니다.
AWS Shield
AWS에서는 DDoS 방어를 위해 AWS Shield 서비스를 제공합니다.
기본적으로 모든 계정은 추가 비용 및 설정 없이 AWS Shield Standard의 보호를 받습니다. 만약 AWS에서 더 많은 지원을 받고 싶은 경우 AWS Shield Advanced를 사용할 수 있습니다. AWS Shield Advanced는 추가 비용(1달에 $3000)을 지불하고 AWS의 Shield Response Team(SRT) 지원, DDoS가 발생했을 경우 요금 보호, WAF와 Network Firewall에 대한 전문적인 통합 등을 지원해줍니다.
Infrastructure as Code (IaC)
다중 계정 환경에서 서브넷을 나누고 각각에 Network ACL을 설정하고 필요한 서브넷들만 골라 각각의 계정에 공유하는 과정에는 많은 노력과 시간이 필요합니다. 실제로 계정이 하나 생성될 때마다 설정해줘야 하는 리소스는 VPC, 서브넷, 라우팅 테이블, NAT Gateway, Internet Gateway, RAM Sharing 등 수십 개 이상입니다.
이를 직접 콘솔에 들어가 손으로 생성하는 것은 상당히 어렵습니다. 그렇기에 Terraform, CloudFormation과 같은 IaC 도구를 활용하는 것을 추천합니다. 각 도구에서 제공하는 모듈화 기능을 잘 활용하면 새로운 계정 또는 VPC가 생성되더라도 유연하고 빠르게 설정하고 대응할 수 있습니다.
실제로 핑퐁팀에서는 모든 VPC 구조를 Terraform을 이용해 작성하였고, 모듈화 기능을 활용하여 50줄의 코드만으로 수백 개의 리소스를 생성하고 관리할 수 있도록 구성하였습니다. 이는 실제로 루다 전체 인프라의 리전을 변경하거나 새로운 서비스를 개발할 때 빠르고 효율적으로 네트워크 인프라를 구성할 수 있도록 해주었습니다.
컨테이너 보안
VM보다 가벼운 컨테이너라는 개념이 등장하고, Docker와 Kubernetes와 같은 컨테이너를 활용하는 오픈소스가 등장하면서 컨테이너는 이제 없어서는 안 될 존재가 되었습니다. 컨테이너를 활용하면 서비스를 유연하고 빠르게 배포할 수 있기에 기업에서도 많이 사용하고 있고, 그렇기 때문에 컨테이너 보안에 대한 중요도도 함께 높아졌습니다.
ECR Scan on Push
도커를 통해 컨테이너 이미지를 만들고 클라우드에서 활용하기 위해서는 원격 이미지 레포지토리에 업로드해야 합니다. AWS에서는 Elastic Container Registry(ECR) 서비스를 통해 컨테이너 이미지 저장소를 제공하고 있습니다.
ECR에서는 이미지 스캔 기능을 제공합니다. AWS Inspector와 통합하여 취약점을 점검해주는 고급 스캔과 Clair 오픈소스를 활용해 이미 알려진 취약점들을 점검해주는 기본 스캔이 있습니다. 또한 ECR에서는 이미지가 푸시되면 자동으로 기본 스캔을 실행해주도록 scan on push를 설정할 수 있습니다.
Scan on push, EventBridge 서비스와 Lambda를 함께 사용하여 이미지를 푸시하면 자동으로 기본 스캔을 실행하고, 이 결과를 슬랙에 알려주는 파이프라인을 만들 수 있습니다. (scan on push 이벤트)

다만 ECR에서 모든 레포지토리에 일괄 적용할 수는 없고, 레포지토리를 생성할 때 scan on push를 설정해야 합니다. Control Tower Guardrails 또는 AWS Config에서 scan on push를 설정하지 않은 레포지토리를 탐지하여 경고 알림을 보낼 수 있습니다.
Incident Response
사고 대응 영역은 사고가 일어났을 때 이를 빠르게 탐지하고, 정해진 프로세스대로 대응하여 상황을 완화하거나 추가 피해를 막을 수 있는 아키텍처를 구성하는 것을 목표로 합니다.
KISA와 방송통신위원회가 발간한 ≪침해사고 분석 절차 안내서≫를 참고하여, 사고 대응 프로세스를 7단계로 구분하여 정리할 수 있습니다. 1단계는 ‘사고 전 준비’로, 조직적인 준비를 다룹니다. 이후 2~5단계 과정에서는 사고를 탐지, 조사, 대응하기 위한 기술적인 준비를, 마지막으로 6~7단계에서는 사후 처리와 이 전반적인 사고 대응 과정을 체계화한 프로세스의 준비를 다룹니다.
사고 대응을 위한 아키텍처를 구성하기 위해 조직, 기술, 프로세스 측면에서 어떤 일을 해야 하는지 정리했습니다.
조직
침해사고 대응 프로세스를 사내에 적용하고 운영하기 위해서는 침해사고 대응을 담당할 전담 조직을 구성해야 합니다. 이 조직에는 실제로 대응에 참여하는 기술 인력뿐만 아니라 의사 결정에 관여하는 위원회도 포함되어야 합니다.
다음과 같은 조직 구성이 권장됩니다. (조직의 규모가 작은 경우 겸임할 수 있습니다.)
- 정보보호위원회: 사내 정보보호 관련 최고 의사 결정 위원회로, CEO, CTO, 각 팀의 팀장 및 CISO(최고정보보안책임자)로 구성합니다. 정보보호 관련 프로세스를 변경하거나 주요한 의사 결정 사항이 있을 때 소집되어 적극적인 논의를 통해 내용을 확정하고 공표하는 역할을 수행합니다.
- 보안 조직: 사내 정보보호 활동과 보안 관련 인프라 운영을 다루는 조직으로, 정보보안에 위협이 되는 이벤트를 발견하고 조치하는 과정을 담당합니다.
- 침해사고 대응팀: 실제로 보안 사고가 일어났을 경우 대응하는 조직으로, 사내 기술 인력 중 서비스, 비즈니스, 플랫폼을 담당하는 인력으로 구성됩니다.
- 보안 교육 담당 조직: 사내 구성원들에게 사고 방지 교육 및 사고 대응 교육을 시행하는 조직입니다. 조직의 각 구성원이 사고 발생 시 각자에게 주어진 역할을 이해하고 프로세스에 따라 대응하려는 의식 수준을 높이는 역할을 합니다.
기술
보안 위협이 발생했을 때 위협에 대응할 수 있는 기술적 장치를 마련해야 합니다. 로깅 및 모니터링 영역에서 언급했던 것처럼, 각종 서비스에서 로그를 수집하고 이벤트 탐지 규칙을 설정한 뒤 이벤트가 탐지되어 알림이 발생하면 신속하게 조치할 수 있도록 설계해야 합니다. 위협 탐지에서 그치지 않고 위협에 대응할 수 있도록 클라우드 인프라와 보안 기술에 대한 전반적인 지식을 미리 갖춰야 합니다.
프로세스
사고 대응을 위한 프로세스를 수립해야 침해사고 발생 시 효율적으로 대비할 수 있습니다. 크게 사고 전 준비 단계, 사고 탐지 및 분석 단계, 사고 해결 및 사후 처리 단계로 나누어 생각할 수 있습니다.
먼저 사고 전 준비 단계에서는 어떤 자산에 어떤 사고가 발생할 수 있는지 파악해야 합니다. 이를 바탕으로 사고의 유형, 서비스, IT 인프라 별로 대응할 세부 계획과 담당자를 정해야 하고, 역할과 책임이 적절하게 분배될 수 있도록 유의해야 합니다. 그리고 각 자산에 대하여 중요도를 산정하여 중요도에 따라 대응할 수 있도록 해야 하며, 조직적인 대응을 위해 초기 대응 시나리오를 작성해두는 것이 좋습니다. 더불어 자산의 중요도를 산정할 때는 사고가 실제로 발생할 확률과 사고가 발생했을 때 서비스에 미치는 영향을 종합적으로 고려해야 합니다.
사고 탐지 및 분석 단계에서는 로깅 모니터링 기술을 통해 사고를 탐지하고, 앞서 준비 단계에서 정의된 프로세스에 따라 초기 대응을 수행합니다. 초기 대응에서는 사고 발생 사실을 내외부에 전파하고, 기본적인 사고 내용을 조사하며, 사고 대응팀을 소집하여 사고에 대응할 준비를 하는 것이 주목적입니다. 구체적인 사고의 분석보다는 전체 조직이 빠르게 개괄을 파악하고 본격적인 대응에 나설 수 있도록 준비합니다. 다음으로는 침해사고 대응팀과 논의하여 대응을 위한 전략을 정하고, 필요한 경우 KISA나 관련 수사 기관에 도움을 요청할 수도 있습니다. 전략이 결정되면 사고 원인에 대한 상세 분석이 이뤄집니다.
마지막 사고 해결 및 사후 처리 단계에서는 분석을 바탕으로 사고에 대한 정보를 기록으로 남기고, 원인을 제거하고 장애를 복구하여 사고를 해결합니다. 이후에는 문제의 원인이 된 사항을 모니터링 항목에 추가하여 재발 방지 대책을 수립해야 하며, 사고가 발생한 자산을 점검하여 자산의 중요도를 조정할 수도 있습니다.
지금까지 개발자를 위한 클라우드 보안 시리즈를 읽어주신 모든 분께 감사드립니다. AWS Well-Architected Framework의 Security Pillar에서 가이드하는 내용은 굉장히 방대합니다. AWS에서 제공하는 공식 문서에서 영상 및 문서 자료와 함께 각 영역을 소개하고 있으니, 더 깊은 공부를 원하시는 분들께서는 참고해보시면 좋을 것 같습니다.
핑퐁팀은 루다의 친구들이 속마음을 편하게 이야기할 수 있는 안전한 환경을 만들어줄 엔지니어를 채용하고 있습니다. 채용에도 많은 관심 부탁드립니다!