AWS Inferentia를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 2탄
우당탕탕 Inferentia 배포하기


지난 글에서는 AWS Inferentia 소개와 사용법, GPU와의 성능 비교 등을 설명해 드렸어요! 이번 글에서는 Inferentia를 실제 서비스에 도입하기 위해 핑퐁팀에서 어떤 과정들을 거쳤는지 소개해드릴게요.😋
정합성 검증
AWS Inferentia는 모델의 정확도는 유지하면서 모델 추론 속도를 빠르게 하도록 BF16을 이용한 mixed precision을 지원하고 있어요. BF16은 부호 비트 1개, 지수 비트 8개, 가수 비트 7개로 구성된 16비트 부동 소수점 형식을 의미해요. 16 bits로 이루어져 있어 FP32에서 필요한 메모리의 절반만 필요하지만, 표현할 수 있는 범위는 FP32와 같아요. Overflow, Underflow, NaN 등을 맞추기 위해 loss scaling이 필요한 FP16과는 달리, 아무런 변경 없이 BF16을 이용해 FP32를 대체할 수 있어요. 하지만, 가수부가 더 적은 비트로 표현되기 때문에 정확도는 살짝 떨어질 수 있게 돼요. BF16에 대해 더 궁금하신 분들은 해당 논문을 참고해주세요.

기본적으로 Neuron Hardware에서는 BF16 또는 FP16 값에 대해 행렬 곱셈 연산 후 FP32로 누적합니다. Compile 시에는 기본으로 FP32로 학습된 모델을 BF16으로 자동 캐스팅해서 FP16의 속도로 추론할 수 있게 해줘요. 그렇다면 자연스럽게 추론 속도와 모델 정확도 사이의 trade-off가 발생하게 되겠죠? 저희는 간단한 정합성 검증을 통해 GPU 위에서 FP32 포맷으로 모델을 추론했을 때와 Inferentia 위에서 추론했을 때의 모델의 정확성을 비교해보았어요.
실험 세팅
두 문장이 얼마나 유사한지를 측정하는 KLUE STS 태스크를 통해 정합성 검증을 진행했어요. KLUE STS는 두 문장을 주면 문장 사이의 의미적 유사성을 0에서 5 사이의 실숫값으로 예측하고, threshold인 3을 넘으면 유사하다, 넘지 않으면 유사하지 않다고 이진화해서 F1 Score를 계산해요. 저희는 간단하게 정합성을 테스트하기 위해 1) 0~5 사이의 모델 추론 값 비교, 2) 추론 값을 0, 1로 이진화했을 때 값이 달라지는 지를 확인했어요.
KLUE 측에서 제공한 학습 데이터셋을 이용하여 사전 학습된 klue/roberta-base 모델을 Fine-Tuning 했어요. 학습이 완료된 모델을 GPU에서 추론하기 위해 SavedModel 형식으로 저장하고, Inferentia 위에서 추론하기 위해 Neuron Compile 후 SavedModel 형식으로 한 번 더 저장해주었습니다. Neuron Compile하는 법은 이전 포스트인 AWS Inferentia를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 1탄에서 소개하고 있으니 참고해주세요.
GPU 인스턴스로는 g5.xlarge를 사용하였고, Inferentia 인스턴스로는 inf1.xlarge를 사용했어요. 실험은 Tensorflow로 진행했으며 sequence length는 128로 고정했습니다. 길이가 128보다 작은 입력은 0으로 padding을 붙여 길이를 128로 만들어 주었습니다.
실험 결과
KLUE 측에서 제공한 519개의 문장 쌍으로 이루어진 DEV 데이터셋을 이용하여 각각 GPU와 Inferentia 위에서 추론하였고, 그 결과는 아래와 같았어요. logit 간의 차이가 미세하게 존재했지만, 두 방법 간의 0/1 불일치 개수는 0개로 동일한 태스크 성능을 얻을 수 있었습니다. 만약 Inferentia를 도입할 계획이시라면 저희처럼 실제 사용하실 태스크의 성능을 GPU와 비교해 도입했을 때 성능상의 손실이 어느 정도 발생하는지 꼭 확인하시길 권장해 드려요!
| 0 / 1 불일치 개수 | 차의 최댓값 | 차의 최솟값 | 차의 평균 | 차의 표준편차 |
|---|---|---|---|---|
| 0 | 0.004072 | 0.000005 | 0.000946 | 0.000698 |
AWS Neuron에서는 Tensor transpose 방법이나 Casting 방법을 변경해 각자의 니즈에 맞게 속도와 정합성 간의 Trade-off를 조절할 수 있도록 —-fast-math라는 옵션을 제공하고 있어요. 서비스마다 필요로 하는 정확성 등이 다르니 AWS Neuron - Neuron compiler CLI Reference Guide를 참고해보시고, Inferentia를 도입하는 데 도움이 되었으면 좋겠어요.
Tokenizer Server 분리하기
기존 핑퐁팀에서는 토크나이저(SentencePiece)도 Tensorflow SavedModel의 Graph에 같이 저장해 사용하고 있었어요. 이렇게 하면 Tensorflow Serving에 string으로 된 문장을 입력으로 넣어주기만 하면 모델의 결괏값이 나와 인터페이스를 매우 간결하게 만들 수 있어요. 하지만 이런 구조는 토크나이저가 실행되는 동안 GPU 연산이 이루어지지 않다 보니 GPU Utilization을 충분히 활용할 수 없다는 문제점이 존재했어요. 또한 Neuron Compile 시 SentencePiece Ops를 지원하지 않아 동일한 Graph 내에 포함할 수 없는 것도 문제였어요.. 🥲 따라서 저희는 전처리를 담당하는 토크나이저 서버를 별도의 컴포넌트로 분리했어요.
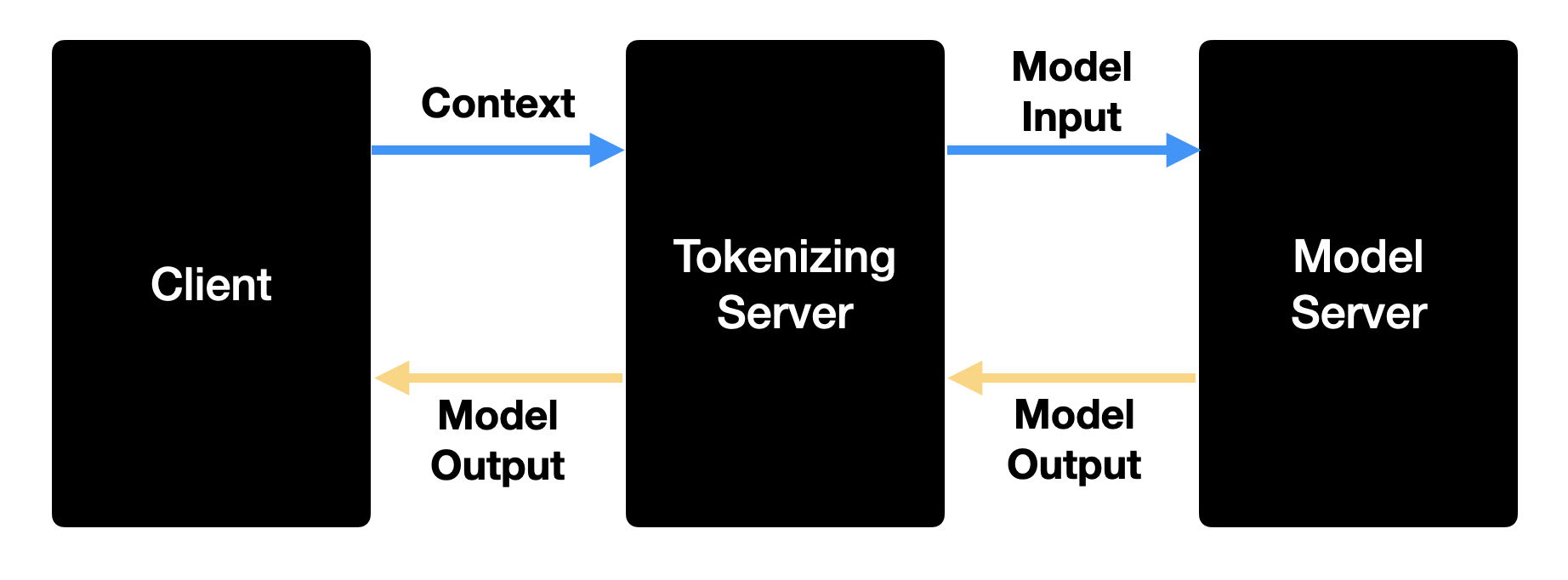
전처리 서버(Tokenizer Server)는 아래와 같은 순서로 동작해요.
- string으로 된 문장들을 입력으로 받아요.
- 토크나이저를 이용하여 입력으로 들어온 문장들을 토크나이징 해줘요.
- 토크나이징 된 문장들(토큰)을 모델 서버에 전송해 모델 추론 결과를 받아요.
- async 하게 모델 결과의 반환을 기다리고 있고, 그동안 다른 request를 처리하고 있어요.
- 모델의 결과가 Tensorflow Serving으로부터 반환되면 해당 결과를 client에 forward 해요.
저희는 Python Web Framework 중 하나인 FastAPI를 이용해 전처리 서버를 구현했어요. 모델 서버에 추론 요청 후 응답을 받기까지 3번 부분에서 오랜 시간 blocking이 되기 때문에 해당 요청이 반환되기 전까지 다른 요청을 처리할 수 있도록 비동기 웹 프레임워크를 사용해야 했어요. 보다 높은 성능 효율을 생각하면 Go나 C++서버를 사용해도 되겠지만, 리서치 조직에서 개발한 전/후처리 로직과의 통일성을 높이는 것이 유지보수성을 높이는 방향이라고 판단해서 Python 기반의 웹 프레임워크를 사용하기로 하였어요.
Python 웹 프레임워크 중 어떤 프레임워크를 사용할까 고민하다 요즘 가장 많이 사용되는 FastAPI를 사용하기로 했습니다. FastAPI는 Flask나 django에 비해 훨씬 빠르면서도, Pydantic을 기반으로 한 Data validation과 Starlette을 기반으로 한 비동기 프로그래밍이 가능하다는 점이 가장 큰 장점이에요.
아래는 FastAPI를 기반으로 개발한 전처리 서버의 간단한 예시 코드입니다.
from typing import List
import aiohttp
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
settings = ...
tokenizer = ...
class ModelRequest(BaseModel):
input_text: str
class ModelOutput(BaseModel):
outputs: List[float]
@app.post("/inference", response_model=ModelOutput)
async def model_process(request: ModelRequest):
model_input = tokenizer(request.input_text)
model_payload = {
"inputs": {
"input_ids": [model_input["input_ids"]],
"attention_mask": [model_input["attention_mask"]],
}
}
async with aiohttp.ClientSession() as session:
async with session.post(settings.model_url, json=model_payload) as res:
model_raw_output = await res.json()
return ModelOutput(outputs=model_raw_output["outputs"][0])
저희는 요청 중간에 전처리 서버가 추가됨에 따라 큰 overhead가 생길까 우려되었어요. 이에 1) 모델 추론 서버에 직접 요청 후 응답을 받아오기까지의 시간과 2) 전처리 서버를 통해 모델 서버로부터 응답을 받아오기까지의 시간을 측정해보았어요. 모델 추론 서버에만 요청할 때 비해 전처리 서버를 거쳐도 지연 시간이 많이 늘어나지 않는 것을 확인했어요. FastAPI가 충분한 성능을 내고 있다는 점과, 큰 overhead가 발생하지 않다는 점을 알 수 있었어요.
Model Serving 하기
이제 드디어!!! Inferentia에서 TFserving을 이용하여 Tensorflow 2.X로 학습된 모델을 추론하는 방법을 소개해볼게요. Inferentia에서도 약간의 차이는 존재하지만 Tensorflow Serving API를 동일하게 사용할 수 있어요.
Compile 후 SavedModel로 저장하기
Inferentia에서 모델을 추론하기 위해서는 Neuron Compile 된 모델이 필요해요. 지난 1탄에서 Neuron Compile 하는 방법을 자세히 다뤘으니 이번에는 간략하게 설명해볼게요. 저희는 아래 예시를 통해서 roberta-base 모델에 입력을 넣었을 때 encoder output을 계산하는 서빙 API를 만들고자 합니다.
import tensorflow as tf
import tensorflow.neuron as tfn
from transformers import TFRobertaModel
# 사전학습된 RoBERTa 모델 불러오기
model = TFRobertaModel.from_pretrained("klue/roberta-base", from_pt=True)
# 모델의 예시 입력 (shape 만 동일하면 되고, 랜덤한 값을 넣어주면 됩니다)
dummy_input_ids = tf.random.uniform([1, 128], maxval=10000, dtype=tf.int32)
dummy_attention_mask = tf.ones([1, 128], maxval=10000, dtype=tf.float32)
# trace 를 통해서 추론 그래프를 생성합니다.
model_neuron = tfn.trace(model, [dummy_input_ids, dummy_attention_mask])
# signature 정의
@tf.function(
input_signature=[
tf.TensorSpec([None, None], dtype=tf.int32, name="input_ids"),
tf.TensorSpec([None, None], dtype=tf.float32, name="attention_mask"),
]
)
def serve(input_ids: tf.Tensor, attention_mask: tf.Tensor):
return model_neuron((input_ids, attention_mask))[0]
# Neuron Complie 된 모델을 signature와 함께 SavedModel로 저장합니다.
tf.saved_model.save(model_neuron, "./roberta-base-neuron/1", signature=serve)
지난 1탄과 다르게 signature가 추가됐죠? Inferentia에서도 TFserving의 Input & Output은 기본적으로 동일해요. SavedModel로 저장 시 signature를 주지 않으면 입력의 이름은 input_1, input_2 등 default 값으로 고정되게 됩니다. 따라서 Serving 시 input_ids, attention_mask와 같이 입력의 이름을 원하는 대로 지정하고 싶다면, input_signature에서 name을 원하는 입력과 동일하게 지정해준 후, SavedModel 저장 시 signature를 삽입해주면 됩니다.
Inferentia Tensorflow Serving Docker로 실행하기
EKS 등에서 모델 서버를 배포하려면 Docker Image는 필수죠. 하지만 Tensorflow에서는 아직 Inferentia 전용 TFserving docker image를 제공하고 있지 않아요. 대신 AWS Neuron - tensorflow-model-server-neuron Dockerfile에서 예제를 제공하고 있으니 참고해 각자에게 맞는 docker image를 만들어 사용해보세요. 아래 코드는 핑퐁팀 내에서 사용하는 Inferentia 전용 Tensorflow Serving Dockerfile입니다.
FROM ubuntu:20.04
RUN apt-get update -y
RUN apt-get install -y --no-install-recommends gnupg2 wget ca-certificates
RUN echo "deb https://apt.repos.neuron.amazonaws.com bionic main" > /etc/apt/sources.list.d/neuron.list
RUN wget -qO - https://apt.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB | apt-key add -
# Installing Neuron Tools
RUN apt-get update -y
RUN apt-get install -y aws-neuron-tools=2.1.4.0 tensorflow-model-server-neuron=2.8.0.2.3.0.0
# Sets up Path for Neuron tools
ENV PATH="/opt/bin/:/opt/aws/neuron/bin:${PATH}"
# Set where models should be stored in the container
ENV MODEL_BASE_PATH=/models
RUN mkdir -p ${MODEL_BASE_PATH}
ENTRYPOINT ["tensorflow_model_server_neuron"]
이렇게 Build 된 Docker Image를 실행시키기 위해서는 Neuron Device를 실행하기 위한 환경세팅(neuron dkms 와 aws neuron tools가 필요해요)이 필수적입니다. Inferentia를 실행하는 환경에 따라서 환경 설정 방법이 다르므로 AWS Neuron - Docker environment setup와 AWS Neuron - Install Neuron TensorFlow를 참조해 주세요! 환경 설정이 완료되었다면 다음 방법으로 Inferentia 전용 Tensorflow Serving Container를 실행해 봅시다!
# 위에서 제공한 Dockerfile을 이용해서 Tensorflow 이미지를 build 합니다.
docker build -t inferentia-tfserving:latest .
# docker run
docker run -it --rm \
--device=/dev/neuron0 \
-p 8501:8501 \
-v /home/ubuntu/roberta-base-neuron:/roberta-base-neuron \
inferentia-tfserving:latest \
--model_base_path=/roberta-base-neuron \
--rest_api_port=8501
이때, neuron device를 꼭 지정해주어야 해요. --device /dev/neuron0와 같이 device 옵션을 이용하여 host device를 추가해줄 수 있어요. 단, 이 방법으로 device를 지정해주면 모든 디바이스를 일괄적으로 사용하는 것은 불가능하므로 사용하고자 하는 device(Neuron Core)가 여러 개라면 일일이 지정해주어야 해요.
모델 추론하기
간단한 스크립트를 이용해 모델을 추론해봅시다. sequence length를 128로 컴파일한 모델이니 128 길이의 dummy input을 만들고, SavedModel 저장 시 삽입했던 signature의 input name과 동일하게 payload를 생성해줍니다. 추론 요청하면 각 batch 별로 STS 모델의 예측값이 잘 나온 것을 확인할 수 있어요. 😆
import requests
import random
BATCH_SIZE = 4
SEQUENCE_LENGTH = 128
input_ids = [[random.randrange(1, 1000) for _ in range(SEQUENCE_LENGTH)] for _ in range(BATCH_SIZE)]
attention_mask = [[1.0] * SEQUENCE_LENGTH for _ in range(BATCH_SIZE)]
payload = {"inputs": {"input_ids": input_ids, "attention_mask": attention_mask}}
response = requests.post("http://localhost:8501/v1/models/model:predict", json=payload)
# response
# {'outputs': [[0.94488889], [0.826834261], [0.741707742], [0.893877506]]}
EKS 에 Inferentia Tensorflow Serving 배포하기
빌드된 이미지가 잘 작동하는지 확인했다면 실서비스 환경과 동일하게 EKS 위에 배포해 봅시다.
핑퐁팀은 머신러닝 모델을 확장성 있게 배포하기 위해서 Kubernetes를 사용하고 있고, AWS Kubernetes Managed Service인 EKS를 사용하여 Kubernetes를 관리하고 있습니다. EKS Node Group으로 inf1.* 인스턴스 타입을 지원하기 때문에 Inferentia 가속기를 이용해서 모델을 서빙할 수 있습니다. 더 자세한 내용은 공식 문서인 AWS Neuron - Deploy Neuron Container on Elastic Kubernetes Service (EKS) 링크를 참조하시면 좋을 것 같습니다! 저희는 실제 Deployment 코드를 중심으로 설명해 드리겠습니다!
첫 번째 tfserving, tokenizer image를 build하고 EKS에서 사용할 수 있도록 ECR에 push 합니다.
docker build -t ecr.****.tokenizer-server:latest -f Dockerfile.tokenizer .
docker build -t ecr.****.inferentia-tfserving:latest -f Dockerfile.tfserving .
# Prerequisite: ECR 인증이 필요합니다.
docker push ecr.****.tokenizer-server:latest
docker push ecr.****.inferentia-tfserving:latest
두 번째 AWS S3에 Neuron Compiled 된 SavedModel과 Model Config, Batching Config 파일을 작성 후 s3에 저장합니다. Batching Config는 Dynamic Batching 을 통해서 여러 입력을 하나의 Batch 로 묶어 추론할 수 있도록 해줍니다. Batching은 Inferentia 가속기의 Throughput을 높이는데 큰 역할을 하기 때문에 매우 중요합니다. Model Config와 Batching Config에 대한 보다 자세한 설명은 Tensorflow 공식 문서를 참고해 주세요!
#model.config
model_config_list {
config {
name: 'roberta-base'
base_path: 's3://../neuron_saved_model'
model_platform: 'tensorflow'
}
}
# batching.config
max_batch_size { value: 64 }
batch_timeout_micros { value: 1000 }
max_enqueued_batches { value: 1000000 }
num_batch_threads { value: 4 }
세 번째 EKS에서 동작할 Tensorflow Serving Container가 모델을 S3에서 다운로드받을 수 있도록 Kubernetes secret에 S3 경로에 접근 권한을 보유한 AWS access key를 등록해 줍니다.
네 번째 Inferentia Node Group을 생성하고, 1개 이상의 Node를 Running 상태로 만들어야 합니다.
다섯 번째 아래와 같은 deployment.yaml을 정의하고 Kubernetes에 apply합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: inf-models-deployment
namespace: default-namespace
spec:
replicas: 1
selector:
matchLabels:
app: inf-models
template:
metadata:
labels:
app: inf-models
spec:
containers:
- name: models
image: ECR_PATH/inferentia-tfserving:latest
imagePullPolicy: Always
args:
- --model_config_file=s3://../model.config
- --rest_api_port=8501
- --enable_batching
- --batching_parameters_file=s3://../batching.config
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
key: AWS_ACCESS_KEY_ID
name: aws-credential
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
key: AWS_SECRET_ACCESS_KEY
name: aws-credential
- name: AWS_REGION
value: us-east-1
- name: S3_USE_HTTPS
value: "true"
- name: S3_VERIFY_SSL
value: "true"
resources:
limits:
aws.amazon.com/neuron: 1
readinessProbe:
httpGet:
path: /v1/models/roberta-base
port: 8501
failureThreshold: 30
initialDelaySeconds: 120
periodSeconds: 10
livenessProbe:
httpGet:
path: /v1/models/roberta-base
port: 8501
failureThreshold: 3
initialDelaySeconds: 420
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
- name: tokenizer
image: ECR_PATH/tokenizer-server:latest
imagePullPolicy: Always
resources:
limits:
memory: 4Gi
nodeSelector:
type: inferentia-workers
아래와 같이 정상적으로 배포가 잘 된 것을 확인할 수 있어요.
# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/default-models-deployment-******* 2/2 Running 0 1h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/default-models-deployment 1/1 1 1 1h
여섯 번째 모델 서버에 접근할 수 있는 Service를 정의하고 auto scaling이 필요하다면 HPA도 설정합니다. 자세한 내용은 Amazon EKS 클러스터에서 실행 중인 Kubernetes 서비스를 공개하려면 어떻게 해야 합니까?와 같은 문서를 참고해 주세요!
부하 테스트 진행하기
모델을 EKS 위에 성공적으로 배포했다면 실서비스와 동일한 환경에서 부하 테스트를 진행해봅시다.
서비스 출시 전 트래픽을 어느 정도까지 감당할 수 있는지 한계치를 탐색하는 일은 필수적인 만큼 JMeter, LoadRunner 등 많은 부하 발생 도구들이 존재해요. 저희는 Python으로 성능 스크립트를 작성해 빠르게 테스트 환경을 구축할 수 있고 간단한 옵션만으로 분산 부하 테스트를 해 볼 수 있는 Locust를 사용하기로 했습니다.
아래 코드는 위 정합성 검증에서 사용했던 모델에 대해 부하 테스트를 진행하는 locustfile 코드에요. HTTPUser를 상속받아 부하 테스트 대상에 요청을 생성할 클라이언트 클래스를 정의해요. 클래스 내에는 task 데코레이터를 사용하여 부하 작업을 정의하는 메소드를 생성해줍니다. 하나의 클라이언트에 여러 태스크를 정의할 수도 있고, task 간의 실행 비율, 즉 요청 비율도 조정할 수 있어요. Locust 에 대한 보다 자세한 내용은 공식문서를 참고하시면 좋을 것 같아요!
# locustfile.py
from locust import HttpUser, task
class ModelsPredictionUser(HttpUser):
@task
def predict(self):
payload = {"input_text": "테스트 문장"}
self.client.post("/inference", json=payload)
스크립트를 다 작성했다면 locust 파일을 실행시키고 Locust Web에 들어가 봅시다. 따로 설정하지 않았다면 http://localhost:8089 일거에요. 화면의 Number of user는 클라이언트의 수를, Spawn rate는 초당 증가시킬 클라이언트 수, Host는 부하를 줄 대상 서버의 주소를 의미해요.
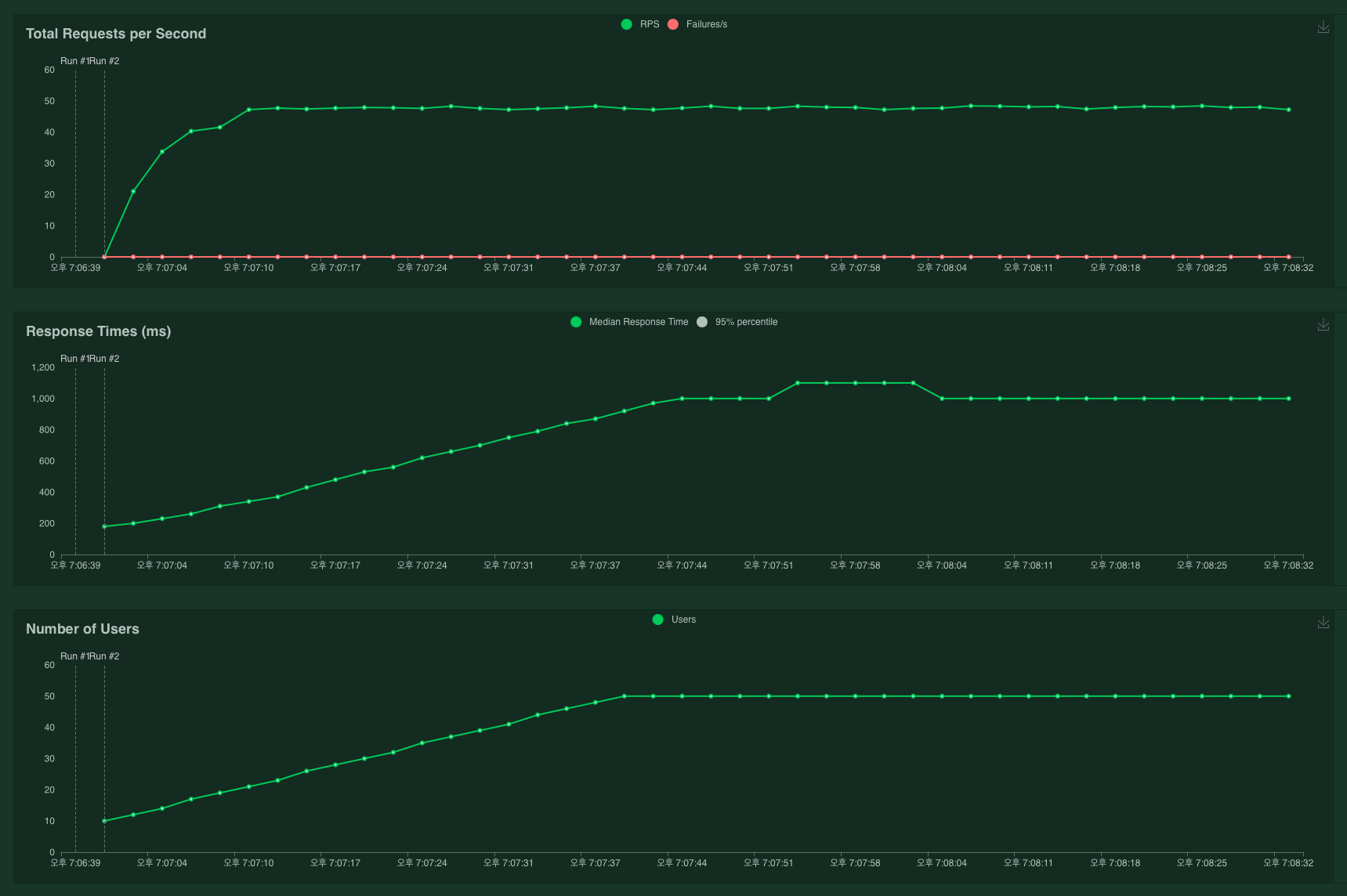
부하를 실행시키면 locust에서는 통계 등과 함께 RPS, Response Time 등을 그래프로 시각화해서 보여줘요. Inferentia 위 roberta-base 모델에 대해서 Number of user = 50, Spawn rate = 1로 실험했을 때의 결과입니다. 최대 48 RPS 정도가 나오는 것을 확인할 수 있어요.

마치며
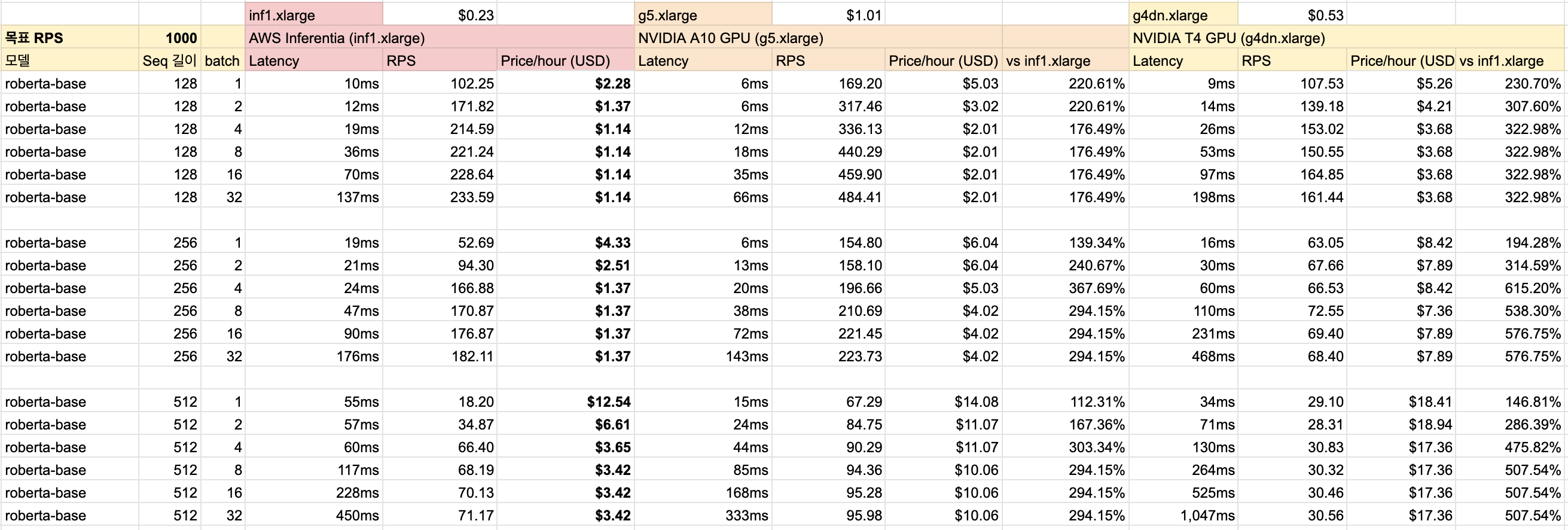
지난 1탄에 이어 이번 2탄에서는 Inferentia를 실서비스에서 배포하기 위한 과정들을 알아보았습니다. Inferentia를 사용한다면 roberta-base 크기의 모델 추론 서버를 배포할 경우 g4dn.xlarge 대비 처리량은 최대 2.6배 높으면서 비용은 최대 5.7배 절감할 수 있어요. AWS Neuron SDK를 사용해 적은 코드 수정으로도 기존 모델을 컴파일하고 Inferentia 위에서 추론할 수 있어요. 모델을 만들었는데 서비스에 배포는 어떻게 할까 고민하시는 분들께 AWS Inferentia 칩 및 Amazon EC2 Inf1 인스턴스 를 참고해 고려하시는 걸 추천해 드려요 :)
{kind=link}
핑퐁팀에서는 Inferentia 외에도 루다에게 들어오는 많은 양의 트래픽을 보다 빠르고 적은 비용으로 최적화하는 방법을 발전해 나가고 있습니다! 저희와 이런 재미있는 문제를 풀고 싶으시다면 언제든 채용 공고를 참고해 주세요! 🚀