Continual Learning: 꾸준히 성장하는 모델을 만들기 위한 기술
주제별로 알아보는 continual learning


Continual Learning은 지속적으로 들어오는 데이터 스트림을 학습하기 위한 방법입니다. 데이터가 지속적으로 주어짐에 따라 데이터의 분포 혹은 데이터가 다루는 태스크가 변화하고, 모델은 현재 주어진 데이터를 학습할 때 기존에 배운 지식을 일부 잃기 마련입니다. 이러한 현상을 Catastrophic Forgetting이라고 합니다. Continual Learning의 방법론들은 Catastrophic Forgetting 현상을 최소화하면서 변화된 데이터 분포 혹은 새로운 태스크에 효과적으로 적응, 학습하는 것을 목적으로 합니다.
핑퐁팀 또한 지속적으로 모델을 업데이트하고 있기 때문에 Continual Learning 방법론을 지속적으로 팔로업하고 있었는데요. 이번 글에서는 Continual Learning 연구 분야에서 다뤄지는 방법론들의 분류 체계와 각 방법론이 동작하는 방식에 대해 소개드리겠습니다. 각 방법론별 분류 체계는 Continual Lifelong Learning in Natural Language Processing: A Survey (Magdalena Biesialska et al., 2020) 을 따랐습니다.
Regularization Methods
Regularization 방법론은 흔히 Loss 함수에 추가적인 Term을 넣어 정규화하는 방식인데요. 가장 기본적으로는 L2 Regularization을 통해 과거 태스크를 학습한 Weight의 변화량을 최소화 하면서 새로운 Task를 학습하는 방법을 떠올릴 수 있습니다. 하지만 L2 Regularization은 단순히 변화량이 작아지도록 정규화하기 때문에 기존에 학습한 태스크와 새로 학습한 태스크 모두 제대로 수렴하지 못하는 결과를 보이게 됩니다.
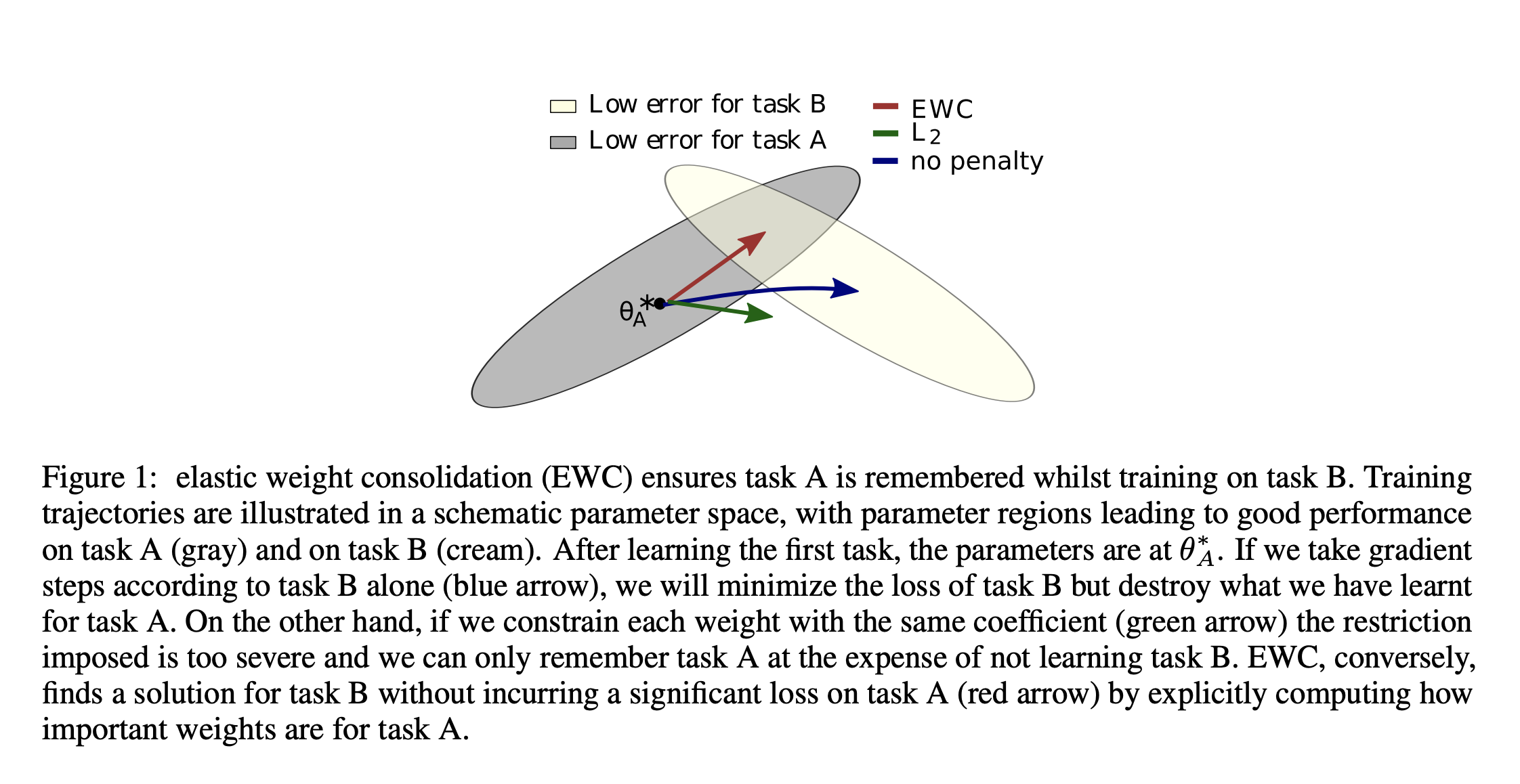
Overcoming catastrophic forgetting in neural networks (James Kirkpatrick et al., 2017) 에서 제안된 Elastic Weight Consolidation (EWC)은 이러한 문제를 해결하기 위해 second order differential equation을 정규화합니다. 위의 그림을 보면 Task A 학습을 마친 후에 Task B를 학습할 때 각 방법 별로 어떻게 수렴하는지를 알 수 있습니다. 위 그림에서 L2 Regularization이 제대로 수렴하지 못하는 것과 달리 EWC는 태스크 A와 B 모두 잘 학습할 수 있는 방향으로 움직이는 것을 볼 수 있습니다. 이는 L2 Regularization과 다르게 EWC는 변화량의 변화율을 정규화하기 때문에 기존에 크게 움직이던 방향으로는 계속 이동하고 움직임이 덜한 방향을 향해서는 덜 이동하도록 모델을 업데이트합니다.
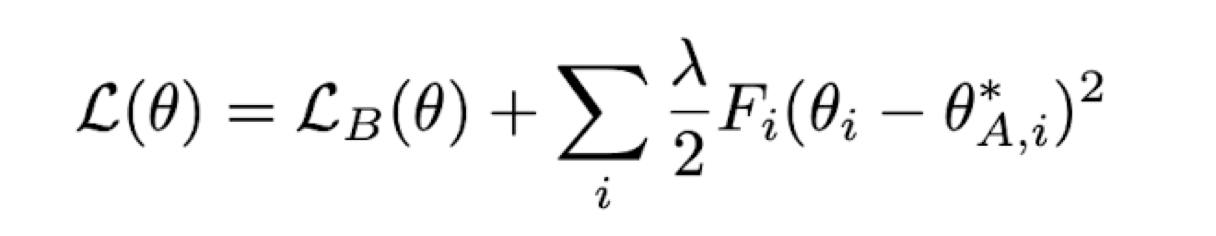
추가로 second order differential equation을 직접 정규화하는 것은 computational cost가 크기 때문에 EWC는 이에 비례하는 fisher information matrix를 활용하여 regularization하게 됩니다.
Rehearsal Methods
Rehearsal Methods는 Memory Bucket 혹은 examplar라는 개념을 활용하여 과거 태스크의 예제를 저장하고 현재 태스크를 학습할 때 추가로 같이 학습하는 방법입니다. 과거 태스크의 일부를 지속적으로 같이 학습함으로써 현재 태스크를 학습하면서 발생하는 Catastrophic Forgetting을 최소화 시킬 수 있습니다.
대표적인 논문으로는 iCaRL: Incremental Classifier and Representation Learning (Sylvestre-Alvise Rebuff et al., 2017) 이 있습니다. 위 논문은 시간이 지날수록 Class가 추가되는 형태의 태스크인 Class Incremental Learning에 Rehearsal Methods를 적용한 논문입니다.
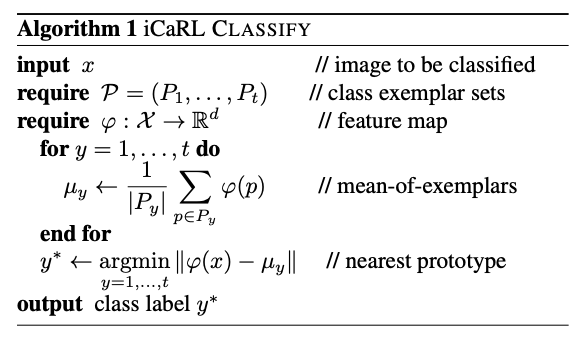
iCaRL에서는 일반적인 Classification을 위한 모델과는 달리 Nearest Mean of Examplar Classification이라는 방법을 사용합니다. 이는 메모리 안의 예제들을 모델을 통과시켜 feature를 생성하고 각 클래스 별로 feature 평균을 구한 뒤 새로운 예제가 나오면 각 클래스의 feature 평균 중에서 가장 가까운 클래스로 분류하는 방식을 사용합니다.
또한 새로운 클래스에 대한 분류를 위한 학습과 함께 examplar에 있는 이전 클래스에 대해서도 distillation 방식으로 학습을 함께 진행하여 catastrophic forgetting을 방지합니다. 이러한 과정에서 examplar는 새로운 클래스에 대해서도 대표적인 예제를 추가해야하는데요. examplar에 좋은 예제를 넣기 위해 feture의 평균에 가장 가까운 M개의 예제를 메모리에 추가하는 방식을 사용합니다.
iCaRL의 방법론 이외에도 간단하게 과거 태스크의 예제를 랜덤하게 메모리에 추가하는 방식 또한 Catastrophic Forgetting을 방지하는데 효율적이라고 합니다. 간단하면서도 좋은 효율을 보이기 때문인지 이후에 나온 다양한 Continual Learning 방법론들에서 Rehearsal Methods가 함께 사용되는 사례를 많이 볼 수 있습니다.
Memory Methods
Memory Methods 또한 Rehearsal Methods와 유사하게 Memory Bucket을 활용하는 방법론입니다. 하지만 과거의 예제를 같이 학습하는 Rehearsal 방법과는 다르게 Memory Methods는 학습 및 추론 시에 제약을 거는 용도로 과거 Example을 활용하죠.
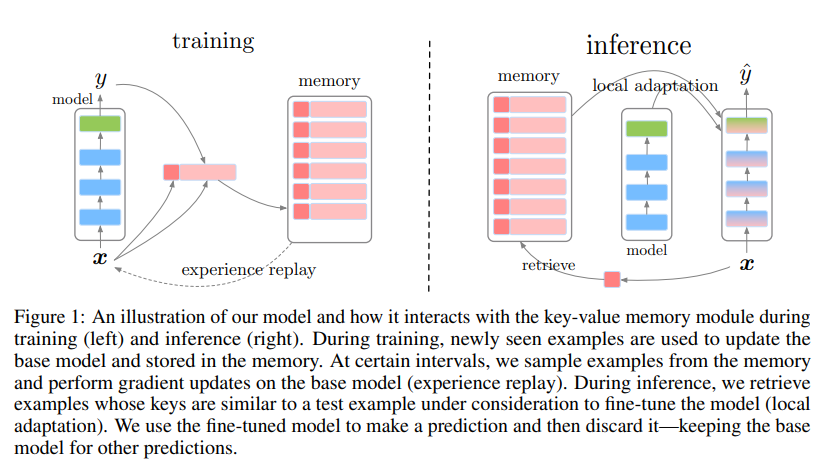
Episodic Memory in Lifelong Language Learning (Cyprien de Masson d’Autume et al., 2019) 에서는 Sparse Experience Replay 및 Local Adaptation 기법을 제안함으로써 Catastrophic Forgetting 문제를 해결합니다. 사전 학습된 BERT(key-network)를 기반으로 입력 샘플에 대한 표현을 키 값으로 얻고, 레이블과 함께 확률적으로 메모리에 저장합니다. 학습 단계에선 1만 개의 새로운 샘플을 학습할 때마다 100개의 샘플을 메모리에서 얻어와 모델을 업데이트(Sparse Experience Replay)합니다. 테스트 시점엔 모델의 성능을 최대로 끌어올리기 위해 메모리에서 테스트를 위한 샘플과 가까운 K개의 이웃을 얻어오고 모델을 일시적으로 K개 샘플에 대해 튜닝한 이후에 주어진 샘플에 대해 추론(Local Adaptation)합니다.
Architectural Methods
Architectural 방법론은 모델의 구조를 지속적으로 수정하여 Catastrophic Forgetting 문제를 개선합니다. 일반적으로는 새롭게 배우는 태스크에 대응하는 전용 파라미터를 추가함으로써 모델의 구조를 변경합니다.
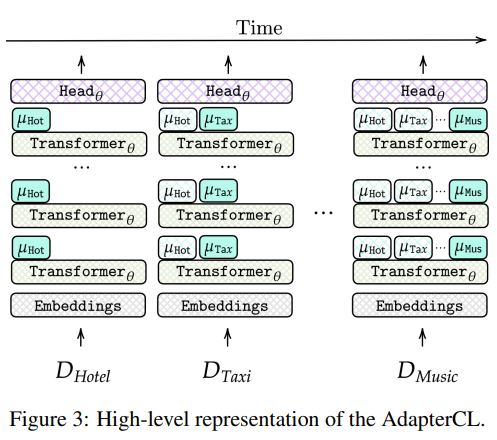
Continual Learning in Task-Oriented Dialogue Systems (Andrea Madotto et al., 2021) 논문에서는 Task-Oriented Dialogue System에 지속적으로 새로운 도메인이 추가될 때마다, 모델의 각 Transformer 레이어 위에 Adapter 레이어를 추가하여 챗봇 모델을 학습합니다. Adapter 레이어는 Residual Connection 기반의 Fully Connected 레이어입니다. 테스트 혹은 추론 시 도메인을 모르는 상황에서 적절한 Adapter를 선택하는 것은 중요합니다. 본 연구에선 PPL 기반의 분류기를 두고 각 Adapter의 PPL을 Uncertainty로 취급하여 선택 대상 Adapter를 결정하였습니다.
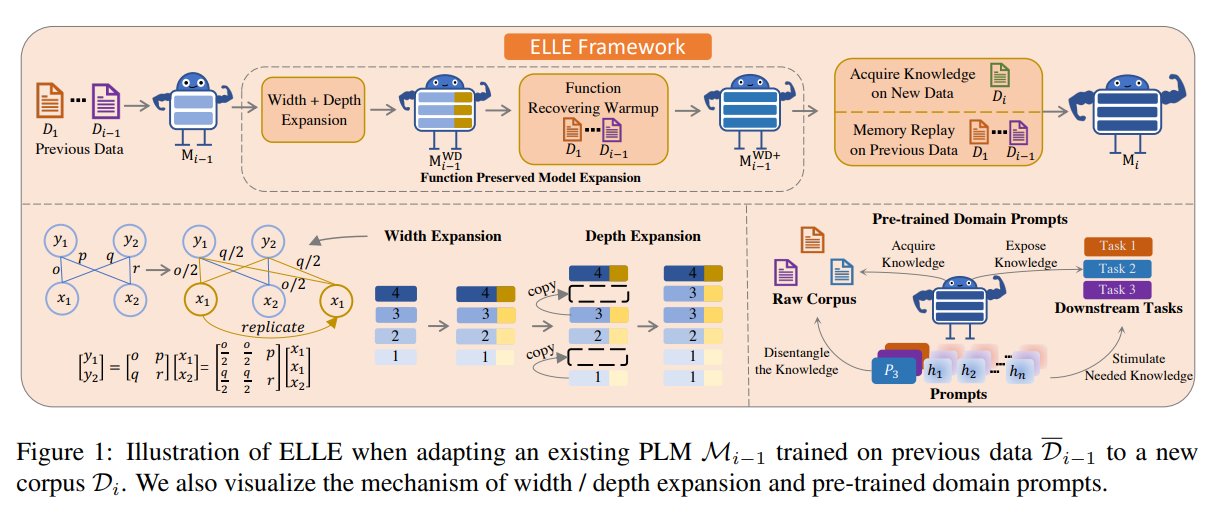
ELLE: Efficient Lifelong Pre-training for Emerging Data (Yujia Qin et al., 2022) 논문에서는 지속적인 Pretrained Language Model (PLM)의 학습을 위해 해결해야 할 두 가지 과제를 지적했습니다. 하나는 효율적인 지식의 확장, 다른 하나는 적절한 지식의 자극입니다. 전자를 해결하기 위해 새로운 태스크의 정보를 받아들일 때 더 많은 파라미터를 추가하되, 지식을 적절히 보존함과 동시에 새로운 정보에 잘 적응할 수 있도록 Function Preserved Model Expansion 방법을 제안했습니다. 후자를 위해서는 PLM을 다운스트림 태스크에 적용할 때, 사전 학습 단계에서 학습된 다양한 도메인의 지식들 중 주어진 다운스트림 태스크에 적합한 지식을 취사선택 할 수 있도록 Pre-trained Domain Propmts를 제안하였습니다.
Knowledge Distillation Methods
Distillation 방법론은 이전 태스크까지 학습한 모델(Teacher)의 체크포인트를 이용하여, 현재 시점의 태스크를 학습하는 모델(Student)에게 이전 모델이 배운 Dark (Hidden) Knowledge를 주입함과 동시에 새로운 태스크에 대한 지식을 학습시킵니다.
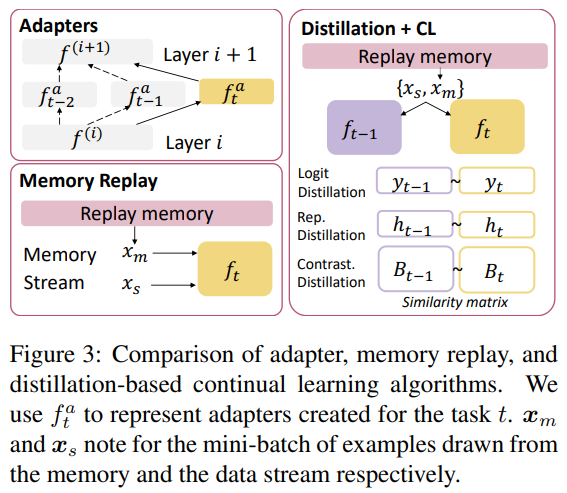
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora (Xisen Jin et al., 2022) 논문에서는 언어 모델이 현실 세계에 배포된 이후 지속적으로 새로운 지식을 학습하면서, 언어 모델이 Out of Distribution (OOD) 데이터에 잘 적응해 나감과 동시에 지식을 더 잘 보존하기 위한 최적의 방법을 찾기 위한 연구를 수행했습니다. Adapter 기반 방법, Memory Replay 기반 방법, 그리고 Distillation 기반 방법을 비교 실험하였고, Replay Memory 방법과 Distillation 방법을 조합 했을 때 가장 효과적으로 동작함을 보였습니다.
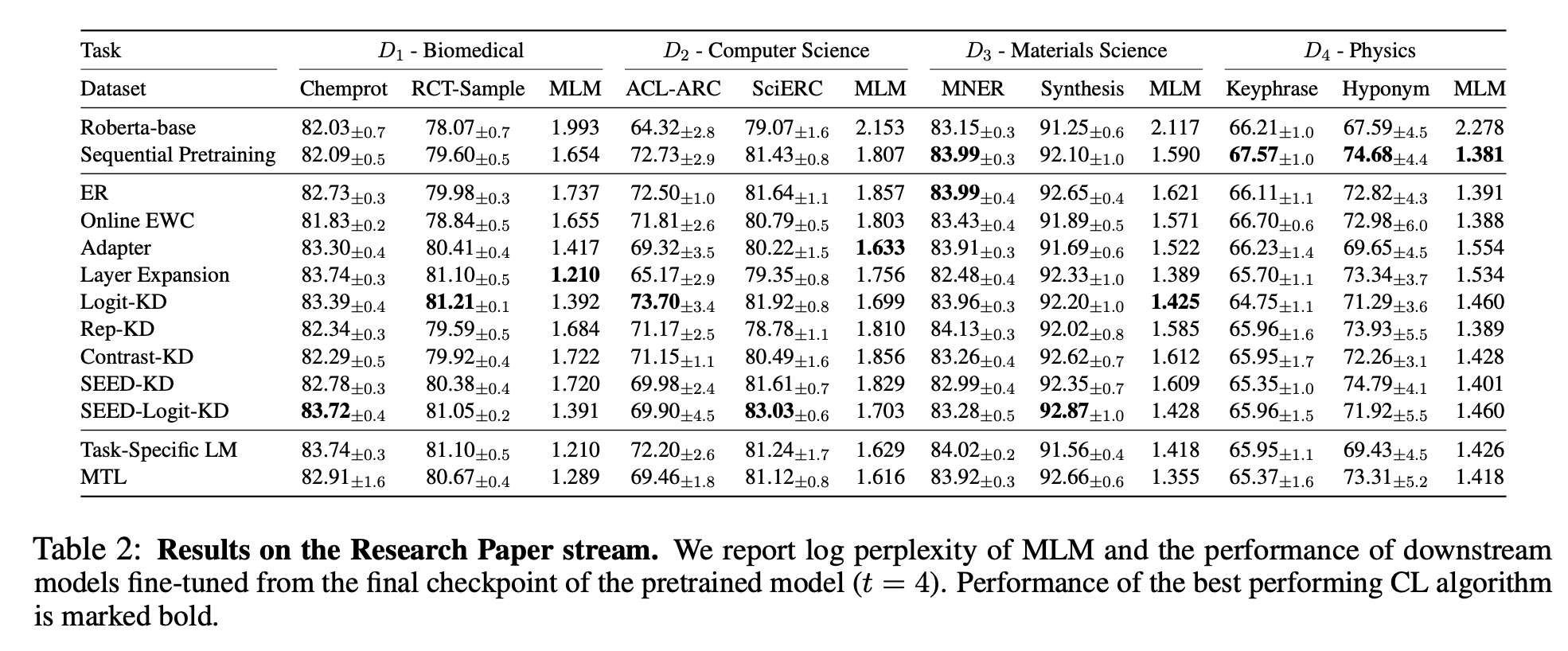
마치며
이번 글에서는 Catastrophic Forgetting 현상을 최소화하면서 지속적으로 분포가 바뀌는 데이터를 효과적으로 학습하는 Continual Learning 방법론을 살펴보았습니다. Regularization, Rehearsal, Architectural, Knowledge Distillation 방법론 등 다양한 방향으로 연구가 진행되고 있으며, 각 방법의 조합을 통해 더 나은 성능을 이끌어내는 방향으로의 연구 또한 이뤄지고 있습니다. 핑퐁팀에서도 이를 활용하여 루다가 지속적으로 대화 성능을 개선할 수 있도록 Continual Learning을 위한 시스템(파이프라인, A/B테스팅 등), 데이터 샘플링 방법, 모델 학습 방법에 관한 연구를 진행하고 있습니다. 더 나은 루다로 찾아 뵐게요! 🤗
참고문헌
- Continual Lifelong Learning in Natural Language Processing: A Survey (Magdalena Biesialska et al., 2020)
- Overcoming catastrophic forgetting in neural networks (James Kirkpatrick et al., 2017)
- iCaRL: Incremental Classifier and Representation Learning (Sylvestre-Alvise Rebuff et al., 2017)
- Gradient Episodic Memory for Continual Learning (David Lopez-Paz et al., 2017)
- Episodic Memory in Lifelong Language Learning (Cyprien de Masson d’Autume et al., 2019)
- Continual Learning in Task-Oriented Dialogue Systems (Andrea Madotto et al., 2021)
- ELLE: Efficient Lifelong Pre-training for Emerging Data (Yujia Qin et al., 2022)
- Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora (Xisen Jin et al., 2022)