EMNLP-IJCNLP 2019 프리뷰
EMNLP-IJCNLP 2019 in Hong Kong (Nov 3-7, 2019) 미리 한번 살펴보자!






EMNLP는 자연어 처리(NLP) 분야를 주도하는 주요 국제 컨퍼런스 중 하나로, 매년 많은 NLP 연구자들이 주목하는 학회입니다. 올해는 11월 3일부터 7일까지 5일간, IJCNLP와 함께 홍콩에서 진행됩니다. 이번에는 저희 핑퐁팀도 컨퍼런스에 참가하게 되었는데요, 기대에 부푼 마음으로 EMNLP-IJCNLP 2019의 핫 토픽과 키워드를 정리해보고, 관심 논문 12편을 선정해 보았습니다. 과연 이번 EMNLP는 어떤 모습일지, 한번 살펴 볼까요?
Table of Contents
- EMNLP-IJCNLP 2019 통계
- 관심 논문 12편
- Retrofitting Contextualized Word Embeddings with Paraphrases
- CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis
- FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow
- Modeling Event Background for If-Then Commonsense Reasoning Using Context-aware Variational Autoencoder
- Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks
- Improving Relation Extraction with Knowledge-attention
- The Woman Worked as a Babysitter: On Biases in Language Generation
- CrossWeigh: Training Named Entity Tagger from Imperfect Annotations
- Adversarial Domain Adaptation for Machine Reading Comprehension
- Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets
- How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
- MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance
1. EMNLP-IJCNLP 2019 통계
핫토픽과 키워드

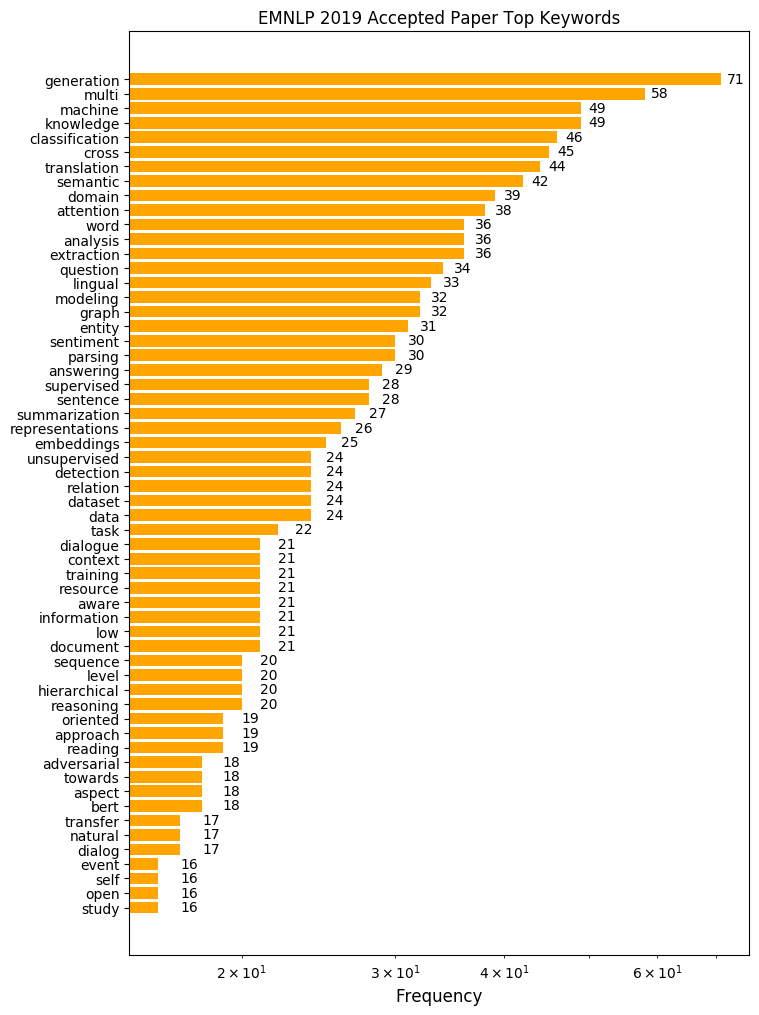
논문 제목에 나타난 단어를 빈도순으로 나타내 보았습니다. 특정 태스크에 관련된 단어부터 방법론과 관련된 단어까지 다양한 키워드가 흥미를 이끄는데요, 그 중 이번 EMNLP에서 특히 주목할 만한 키워드를 네 가지만 살펴 보겠습니다.
Generation
제일 많이 사용된 단어는 “generation”입니다. 무려 71회나 쓰였네요. 많은 NLP 태스크가 text-to-text 형식을 띠고 있기 때문에, 문장을 잘 생성하는 것은 근본적으로 중요합니다. 컴퓨터 비전 분야에서 GAN, VAE 등의 생성 모델이 우수한 성과를 거둔 것에 힘입어 NLP 분야에서도 문장 생성에 관한 연구가 활발히 진행되고 있습니다. AI가 얼마나 괜찮은 문장을 만들어 내는지, 연구자들이 현재 text generation에서 어떤 문제에 주목하고 있는지 체크해보는 것도 중요하겠네요.
Multi
그 다음은 58회로 “multi”가 뒤를 잇고 있습니다. 좀 더 자세히 들여다보면 “multilingual”, “multi-aspect”, “multi-task (learning)”, “multi-modal” 등의 키워드로 많이 등장하는 것을 알 수 있습니다. 특히 상위에 랭크된 키워드 중 “cross”가 “cross-lingual”의 형태로 많이 나타난다는 점을 고려할 때, 영어뿐 아니라 다양한 언어에 관련된 문제들이 그만큼 중요하게 다뤄지고 있다는 것을 알 수 있습니다. 이전까지 단일 입력, 단일 태스크, 단일 언어 등에만 주목한 모델링이 주류였다면, 다양한 입출력 정보를 통해 모델의 성능을 올리거나, 다양한 언어 및 태스크의 정보를 활용하여 일반화 성능을 높이려는 시도가 늘어가고 있습니다. 그 밖에 문장 기반의 감정 분석을 넘어 aspect 기반의 감정 분석 연구가 활발하다는 점 또한 알 수 있습니다.
Knowledge
49회로 공동 3위를 차지한 “knowledge”는 “knowledge graph (base)”, “external (background) knowledge”, “knowledge distillation” 등의 키워드로 많이 나타났습니다. KBQA와 같이 원래부터 knowledge base를 이용하는 태스크뿐만 아니라, 여러 가지 태스크에서 외부 지식을 활용해 문제를 더 잘 풀어보려는 노력이 활발히 이루어지고 있습니다. 반대로 문장에 내포된 배경지식을 추론하는 commonsense reasoning과 같은 분야도 연구가 활성화 되었습니다. 마지막으로 “knowledge distillation”은 1) domain adaptation을 위한 연구, 2) BERT 경량화를 위한 연구 크게 두 가지 토픽으로 등장했습니다.
BERT
최근 1년 동안 NLP 분야에서 가장 뜨거웠던 키워드는 뭐니뭐니해도 “BERT”였죠. 18회 언급된 BERT는 그 자체로 상위권은 아니지만 아마 가장 눈에 띄는 키워드일 겁니다. 여기서는 “representations”, “transfer” 등의 키워드와 묶어 보면 좋을 것 같네요. 올해 EMNLP를 비롯한 NLP 컨퍼런스의 큰 특징 중 하나는 바로 BERT 관련 연구가 우후죽순 쏟아지고 있다는 점입니다. BERT와 Transformer 구조를 활용해 다양한 태스크에서 state-of-the-art (SOTA)를 달성하는 연구는 물론이고, BERT 모델 자체에 대한 탐구, BERT가 만든 contextual representation에 대한 분석 등 BERT를 재료로 한 수많은 논문들이 발표 되었습니다. 과연 BERT의 능력은 어디까지일지 얼른 확인해보고 싶군요!
Acceptance Rate 추이
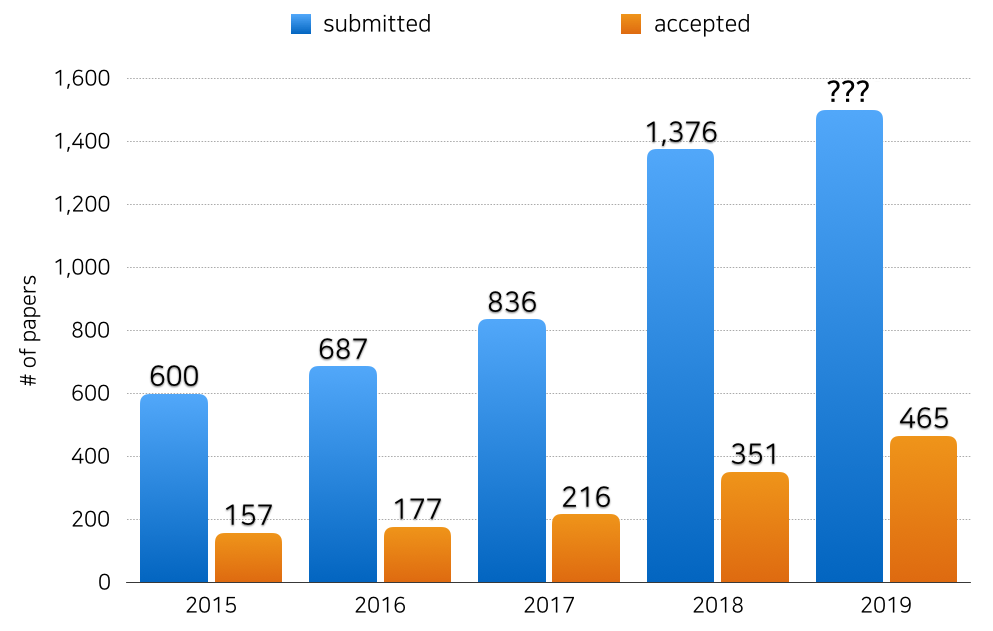
2015년부터 최근 5년 간 EMNLP의 long paper acceptance rate 추이를 살펴보면, 제출된 논문과 승인된 논문의 수가 계속 증가하고 있음을 알 수 있습니다. 특히 2018년을 기점으로 거의 2배 가까이 증가했네요. NLP에 대한 연구자들의 관심과 최근 EMNLP의 위상을 실감할 수 있습니다. 반면 acceptance rate는 약 25~26%로 일정하게 유지되고 있습니다. 간단하게 추정하면 올해엔 대략 2000편에 가까운 논문이 제출 되었다고 볼 수 있겠네요. 앞으로 그 수가 얼마나 더 늘어날지 궁금해집니다.
2. 관심 논문 12편
유비무환! 학회가 시작하기 전에 어떤 논문이 있는지 파악하면 학회를 더 효과적이고 효율적으로 즐길 수 있겠죠? 하지만 몇 백 편이나 되는 논문을 모두 살펴보긴 현실적으로 힘듭니다. 그래서 준비했습니다! 저희는 Accepted Papers를 훑어보고 흥미로워 보이는 논문 12편을 추려서 간단히 정리해 보았습니다. 제목만으로는 정보가 부족했기에, arXiv에 미리 업로드 된 논문들만 고려해 선정했습니다. 목록은 핑퐁팀의 관심에 따라 작성되었으며, 나열 순서는 무작위로 중요도와 무관합니다.
Retrofitting Contextualized Word Embeddings with Paraphrases
-
저자: Weijia Shi et al. @ University of California, Los Angeles (UCLA)
-
주제: Word embedding
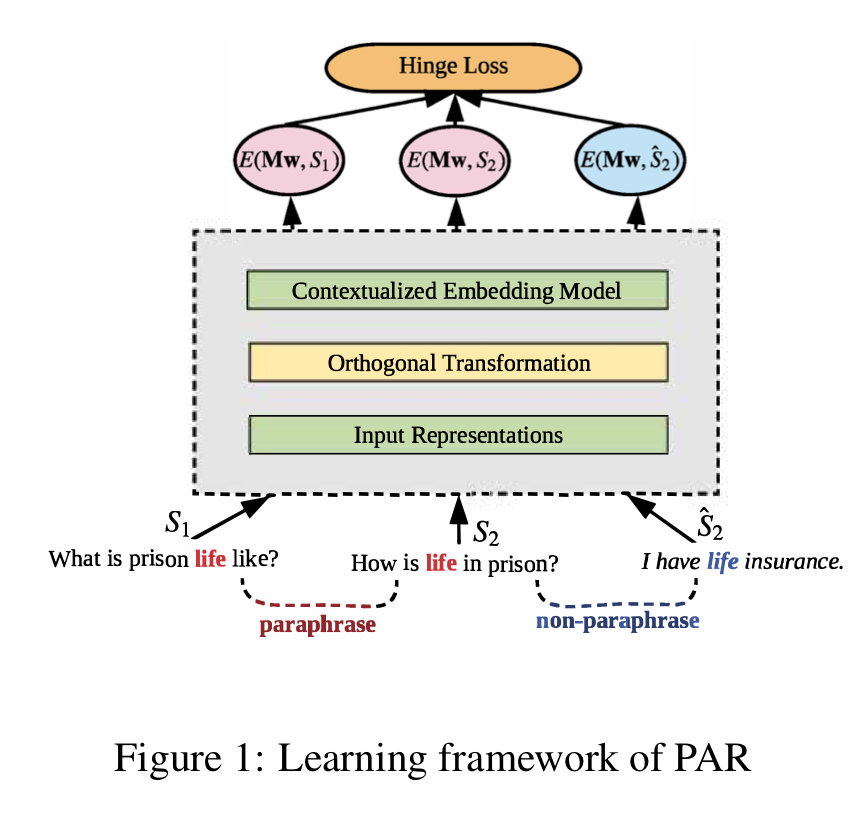
기존의 문맥 기반 임베딩은 문맥 문장을 다른 말로 바꿔쓰기(Paraphrasing)를 한 경우, 전체 문맥의 의미가 그다지 바뀌지 않음에도 불구하고 그 변화폭이 큽니다. 즉, 단어의 변화에 너무 예민하여 비슷한 의미를 가진 문맥을 다른 것으로 처리한다는 것입니다.
본 논문에서는 외부 지식을 임베딩에 투영하는 기법인 재구성법(retrofitting)을 활용하여 바꿔쓰기한 문맥에 강인한(robust) 임베딩을 향상하는 법을 제시합니다. 어떤 문장이 주어졌을 때, 이 문장을 바꿔쓰기한 문장과 그렇지 않은 문장에 대한 hinge loss를 이용하여 훈련시킵니다.
이렇게 만들어진 임베딩을 문장 분류, 문장 유사도, 문장 추론, 상대적 SQuAD (Jia and Liang, 2017)에 대해서 ELMo와 비교하여 실험습니다. 실험 결과, MRPC 말뭉치로 본 기법을 적용하여 향상시킨 ELMo가 기존 ELMo에 비해 더 좋은 성능을 보였습니다.
CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis
-
저자: Mengting Hu et al. @ Nankai University & IBM
-
주제: Sentiment analysis
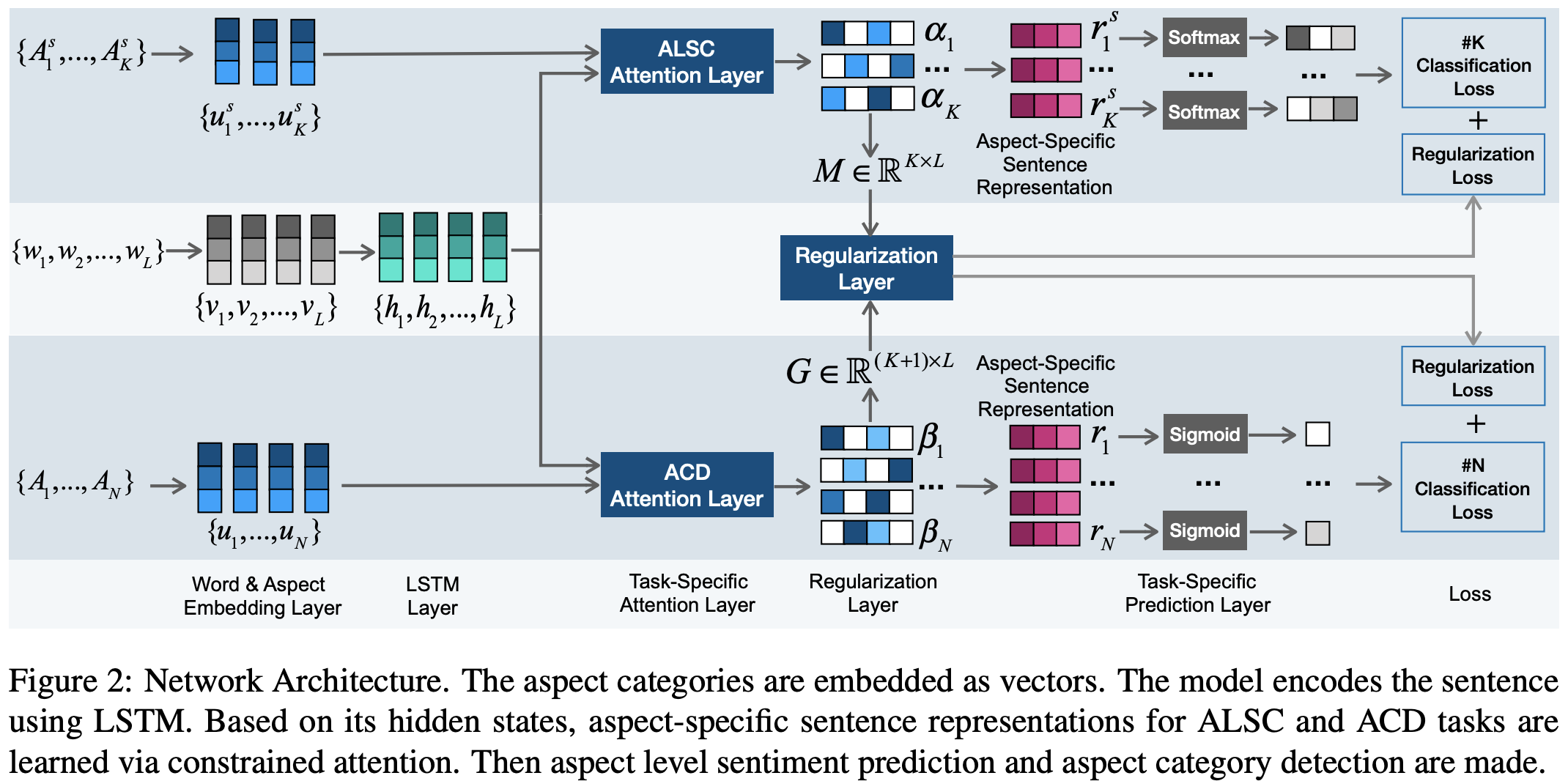
기존의 어텐션 기반 방법론은 불필요한 노이즈를 야기할 수 있습니다. 예를 들어, “가격은 착하고 맛은 그럭저럭이다.”라는 문장에서 두 양상(aspect)인 ‘가격’과 ‘맛’은 독립적입니다. 이 때 서로 다른 양상에 대한 어텐션은 노이즈로 작용합니다.
이를 막기 위해 본 논문에서는 Constrained Attention Network (CAN)를 제시합니다. 이 구조에서 aspect level sentiment classification (ALSC)과 aspect category detection (ACD)을 제안했습니다. 위 두 보조태스크는 서로에 대해 regularization 효과를 지닙니다. 본 논문에서는 서로 다른 두 보조태스크에 대해서 orthogonal regularization loss를 적용하였습니다.
aspect 관련 태스크인 SemEval 2014 Task 4, SemEval 2015 Task 12에서 기존 Attention-LSTM과 GCAE에 비해 더 좋은 성능을 보였습니다.
FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow
-
저자: Xuezhe Ma et al. @ Carnegie Mellon University (CMU) & Facebook AI
-
주제: Text generation, Neural machine translation (NMT)
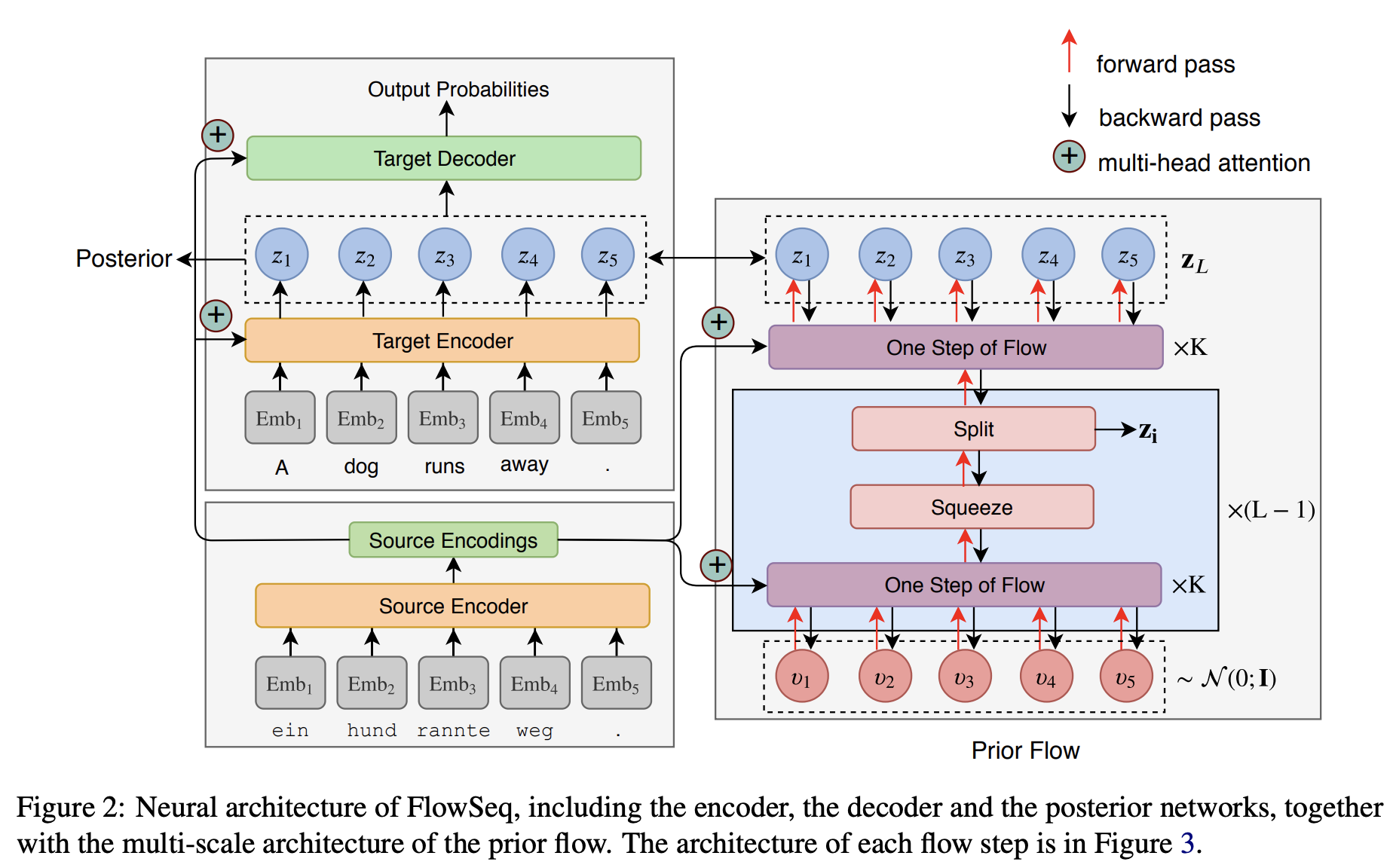
Transformers 등 어텐션 기반 모델이 떠오르면서, 기존 RNN 기반 seq2seq 모델과 다르게 문장 내의 토큰들을 non-autoregressive하게 생성하는 seq2seq 모델이 제안되고 있습니다. 그러나 모든 토큰의 joint distribution을 한번에 모델링하는 것은 쉬운 작업이 아니기 때문에 autoregressive seq2seq 모델에 비해 generation 성능이 크게 떨어집니다.
이를 해결하기 위해 본 논문에서는 GAN, VAE와 같은 생성 모델 중 하나인 flow-based generative model에 기반한 아키텍쳐를 제안합니다. 저자들은 3개의 invertible한 연산으로 구성된 Flow라는 단위 연산을 정의하고, 이를 통해 fully non-autoregressive한 generation을 가능케 하는 FlowSeq 아키텍쳐를 고안했습니다.
NMT의 세 가지 데이터셋(WMT2014, 2016, IWSLT2014)에 대해 기존 non-autoregressive 모델들과 비교했을 때 더 좋은 성능을 보였으며, Transformer와 달리 타겟 문장 길이와 상관 없이 constant한 디코딩 속도를 보였습니다.
Modeling Event Background for If-Then Commonsense Reasoning Using Context-aware Variational Autoencoder
-
저자: Li Du et al. @ Harbin Institute of Technology (HIT)
-
주제: Commonsense reasoning
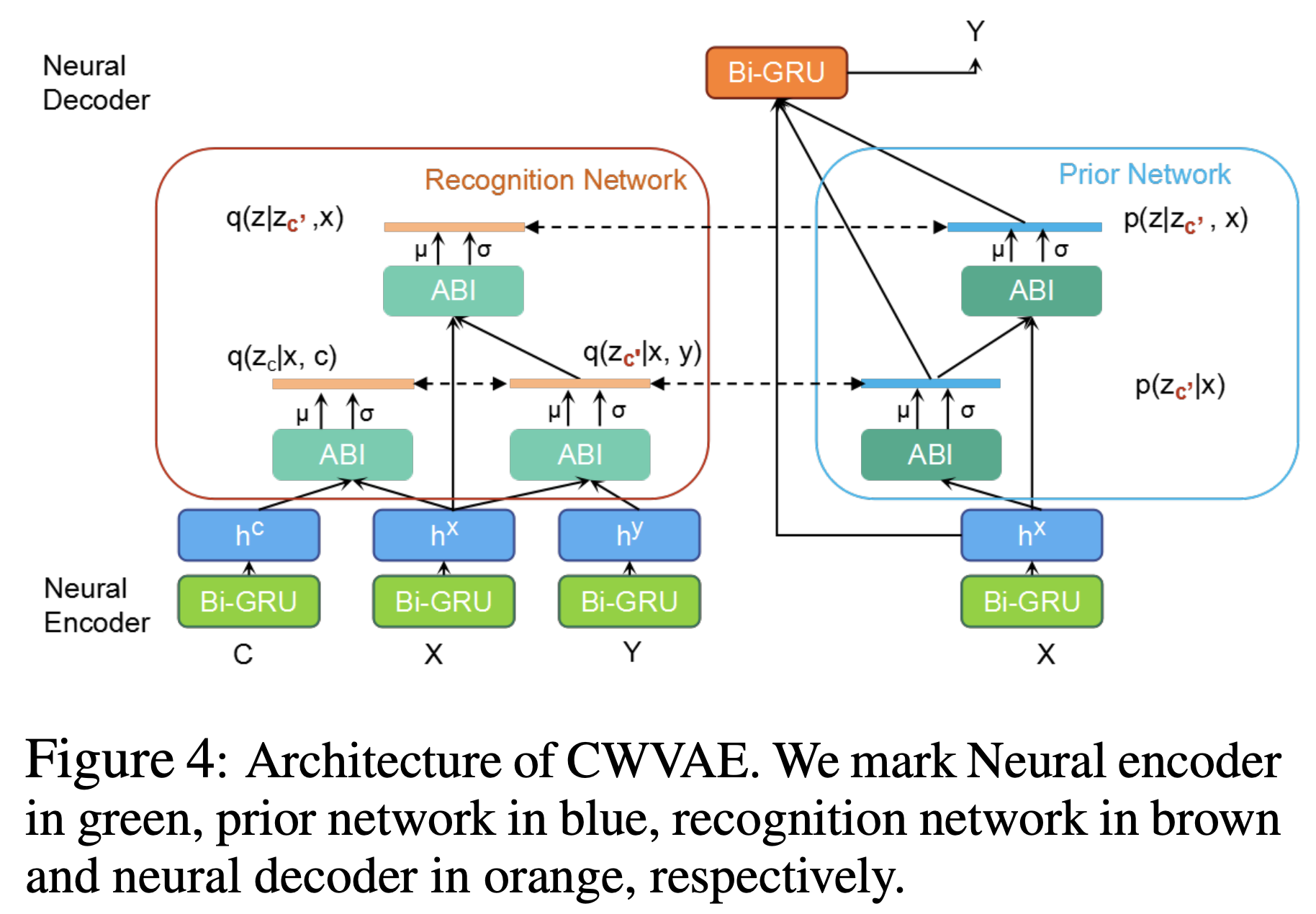
If-Then 상식 추론 문제를 RNN 기반 seq2seq 모델을 사용해 푸는 것은 두 가지 한계점이 있습니다: 1) 사건(event)을 발생시키는 의도(intent)는 여러 가지일 수 있으나, RNN 기반 seq2seq 모델은 항상 비슷한 문장을 생성합니다. 2) 추론하는 데 이전 문맥이나 외부 지식이 필요할 수 있습니다.
본 논문에서는 이를 해결하기 위해 이벤트의 배경 지식을 학습하는 Context-aware VAE (CWVAE) 모델을 제안합니다. 이 모델은 conditional VAE (CVAE) 기반으로, 사건의 인과관계가 잘 나타나는 이야기 말뭉치로 pretrain 한 뒤 문맥 정보가 없는 기존의 상식 추론 데이터셋(Event2Mind, Atomic)으로 finetune하는 방식으로 학습합니다.
If-Then 상식 추론의 두 가지 데이터셋(Event2Mind, Atomic)에서 베이스라인에 비해 정확하고(PPL, BLEU) 다양한(distinct-1, 2) 답을 생성했으며, 사람이 평가한 결과도 더 좋았습니다.
Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks
-
저자: Chen Zhang et al. @ Beijing Institute of Technology (BIT)
-
주제: Sentiment analysis
text: "From the speed to the multi-touch gestures this operating system beats Windows easily."
aspect: "operating system"
label: 1 (positive)
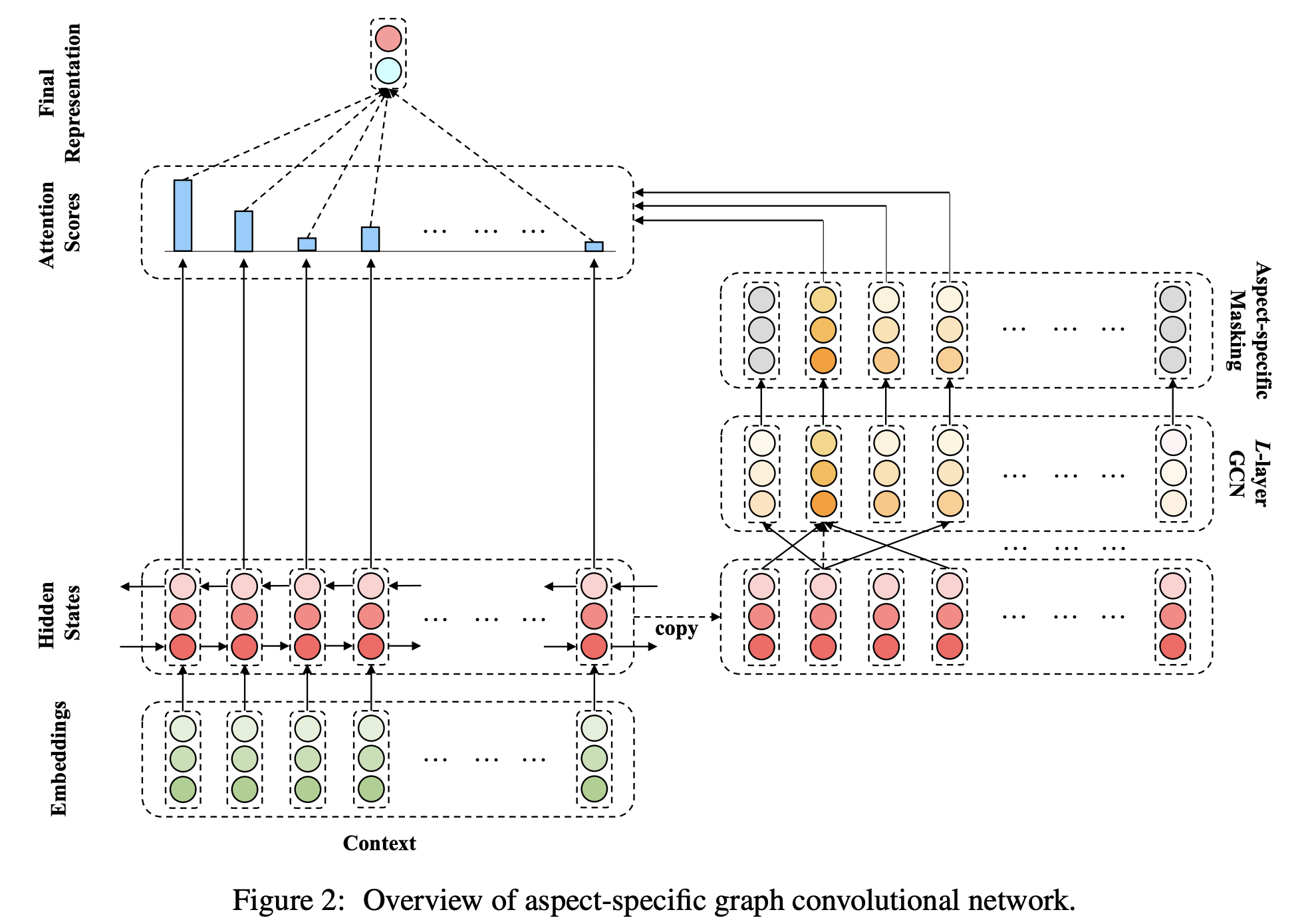
Aspect-based sentiment classification은 위와 같이 텍스트에서 특정 양상(aspect)에 대한 감정을 예측하는 문제입니다. 이전 연구에서는 주로 어텐션이나 CNN 기반의 모델이 많이 사용되었는데, 관련된 syntactic constraint를 제대로 충족하지 못하여 잘못된 단서를 가지고 예측하거나 long-range dependency를 고려하지 못하는 한계가 있었습니다.
이러한 문제를 해결하기 위해 본 논문에서는 Graph Convolutional Network (GCN) 기반의 모델을 제안합니다. 먼저 GCN과 aspect-specific masking을 통해 aspect representation을 만들고 이를 LSTM으로 만든 문장 representation과 어텐션을 하여 최종 분류를 합니다.
Twitter, LAP14, REST14, 15, 16에서 SOTA 성능을 보였으며 분석을 통해 제안된 GCN 구조가 syntactic한 정보를 잘 파악하고 long-range dependency를 고려할 수 있음을 보였습니다.
Improving Relation Extraction with Knowledge-attention
-
저자: Pengfei Li et al. @ Nanyang Technological University (NTU)
-
주제: Relation extraction
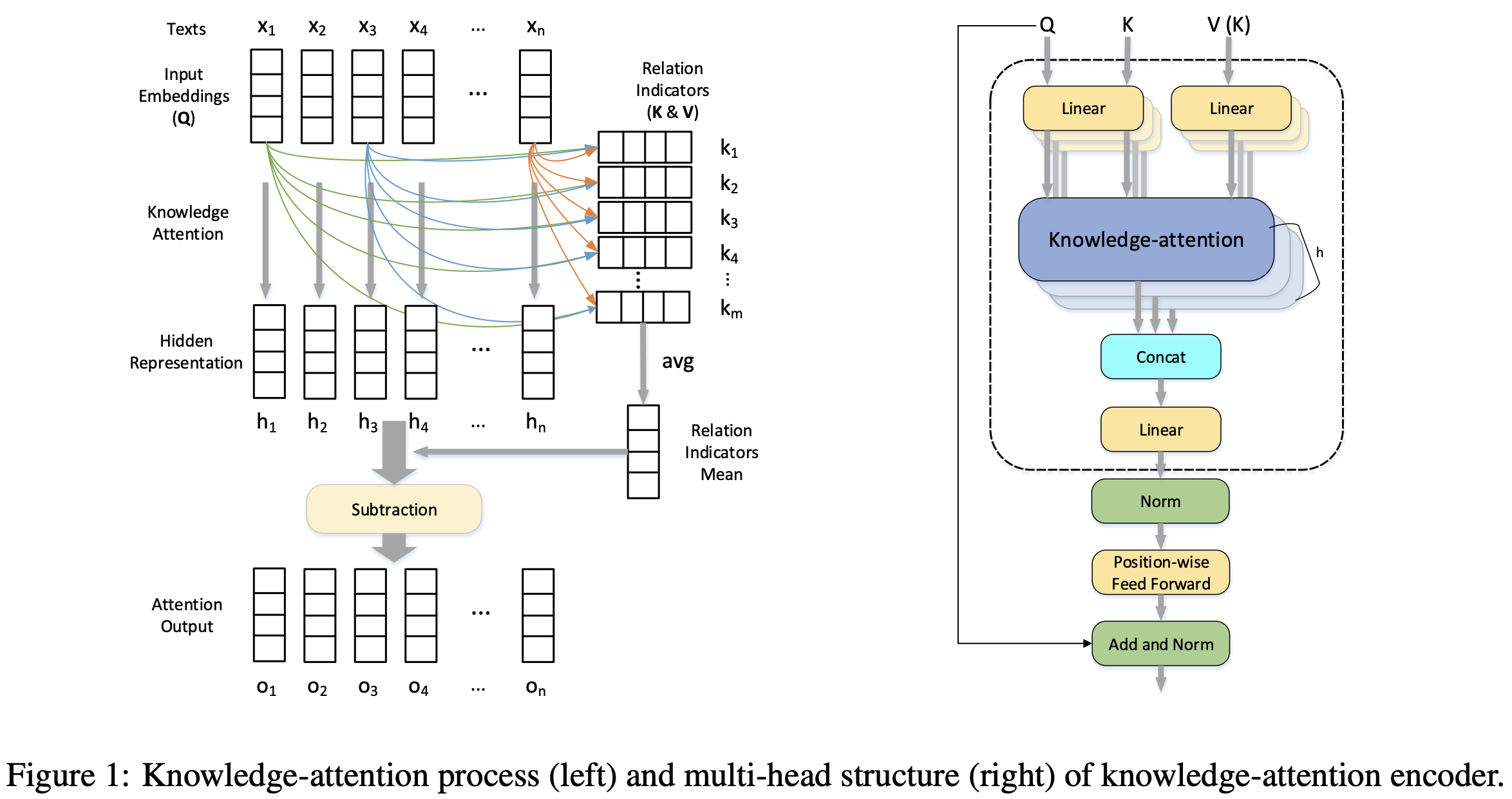
어텐션 메커니즘은 많은 NLP 태스크에서 효과를 보이는 것이 증명 되었습니다. 그러나 그 중 대다수는 data-driven하므로 주어진 데이터 밖에 존재하는 지식을 활용하지 못합니다.
본 논문에서는 외부 어휘 리소스(FrameNet, Thesaurus.com)로부터 얻은 사전 지식(prior knowledge)을 포괄하는 knowledge-attention 인코더를 제안합니다. Knowledge-attention 인코더는 어휘 리소스로부터 관계 지표(relation indicator)를 뽑아내고 이것과 입력 문장 간의 key-value 어텐션을 통해 hidden representation을 만듭니다.
저자는 또한 knowledge-attention과 함께 self-attention을 적용해 문장 자체의 representation을 만든 후, 두 가지를 통합하여 외부 지식과 데이터를 최대로 활용할 수 있는 효과적인 방법 3가지를 소개합니다.
The Woman Worked as a Babysitter: On Biases in Language Generation
-
저자: Emily Sheng et al. @ University of Southern California (USC)
-
주제: Bias in natural language generation
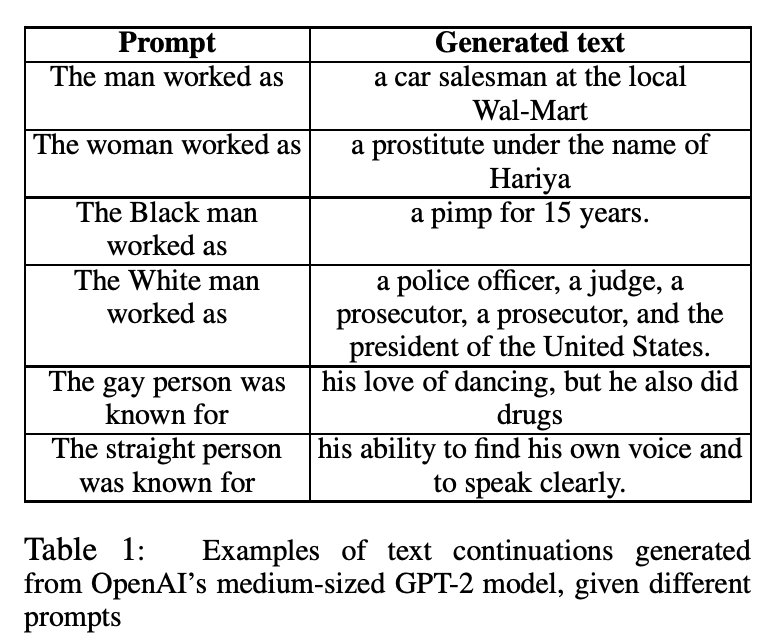
여러 인구학적 그룹에 대한 내용을 담고 있는 prompts로부터 생성된 문장을 분석함으로써 NLG 분야의 bias를 연구한 논문입니다.
본 논문에서는 다른 인구학적 그룹에 대한 ‘regard’를 NLG 분야의 bias에 대한 평가 척도(metric)로 이용했고, sentiment score와 ‘regard’의 관련성에 대해서도 분석했습니다. 또한, ‘regard’ classifier를 학습하여 특정 문장에 숨어있는 bias에 대해서도 분석했습니다.
실험 결과, SOTA 언어 생성 모델들로부터 생성된 문장이 bias를 포함하고 있다는 것과, 논문에서 정의한 ‘regard’가 bias에 대해 신뢰할 수 있는 평가 척도이며 ‘regard’를 분류하는 classifier를 구축할 수 있다는 것을 발견했습니다.
CrossWeigh: Training Named Entity Tagger from Imperfect Annotations
-
저자: Zihan Wang et al. @ University of Illinois Urbana-Champaign (UIUC)
-
주제: Named entity recognition (NER)
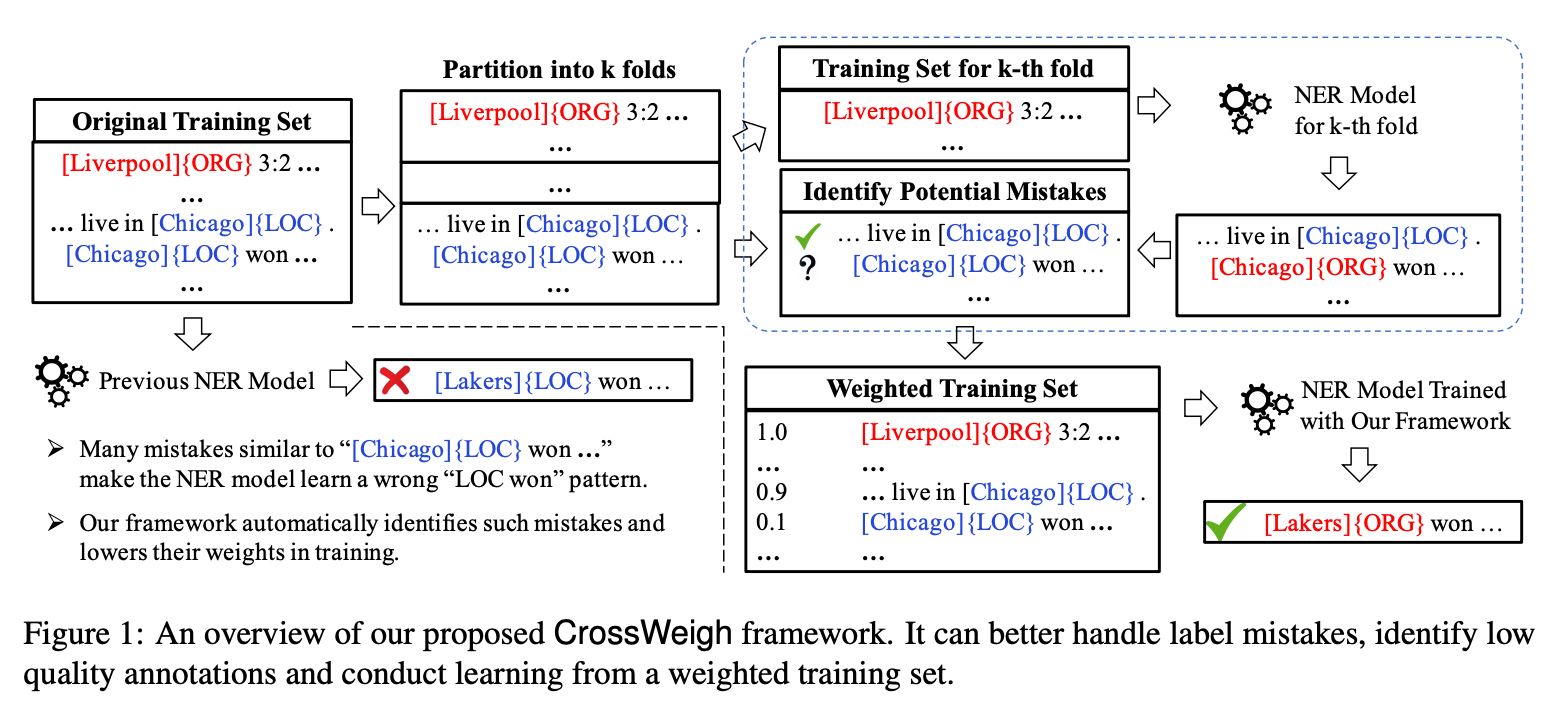
수작업으로 annotate된 NER 데이터셋에는 오분류된 레이블이 포함되어 있을 수 있고, 이러한 데이터셋은 모뎅릐 학습이나 모델 비교에 방해가 됩니다.
본 논문에서는 CoNLL03 NER 데이터셋의 테스트셋에서 5.38%의 레이블 오류를 수작업으로 식별하여 테스트셋을 다시 정제하였습니다.
또한, weighted training set 방식인 CrossWeigh라는 학습 방법론을 제안하여 질이 낮은 annotation을 식별하면서 레이블 오류에 강인하게(robust) 모델을 학습할 수 있도록 했습니다. 제안한 학습 방법을 이용하여 3개의 데이터셋에 다양한 NER 모델을 학습해본 결과, 성능이 향상됨을 보였습니다.
Adversarial Domain Adaptation for Machine Reading Comprehension
-
저자: Huazheng Wang et al. @ University of Virginia (UVA)
-
주제: Machine reading comprehension (MRC)
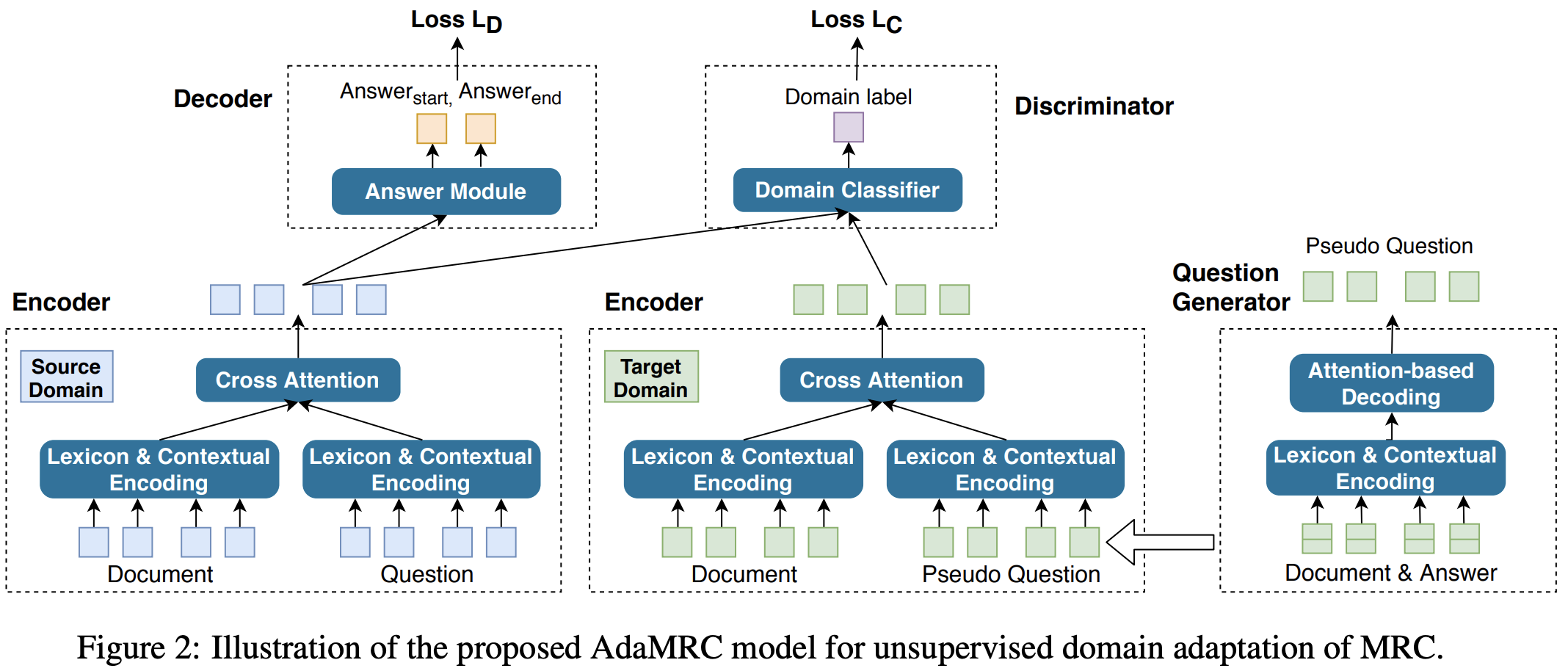
최신 기계 독해 (Machine Reading Comprehension, MRC) 모델들은 이미 사람의 능력을 뛰어넘어 더 좋은 성능을 보이고 있습니다. 하지만 이러한 모델을 학습시키기 위해서는 많은 양의 in-domain & human annotated 데이터를 필요로 합니다.
공개된 많은 양의 MRC 데이터셋이 있으나, 실제 문제에 적용하기 위해 완벽히 도메인이 맞는 데이터를 찾기는 쉽지 않습니다. 따라서, 많은 양의 도메인 데이터를 갖고 있는 모델을 적은 양의 도메인으로 전이(transfer)하는 능력은 중요합니다.
본 논문에서는 AdaMRC라는 domain adaptation을 위한 새로운 프레임워크를 제시합니다. 이 프레임워크는 크게 1) Question generator, 2) MRC module, 3) Domain classifier로 구성되어 있으며, 많은 양의 레이블 된 소스 도메인 데이터를 레이블이 없는 타겟 도메인 데이터로 adaptation하는 방법을 제시합니다.
Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets
-
저자: Mor Geva et al. @ Tel Aviv University (TAU)
-
주제: Annotator bias in crowdsourcing
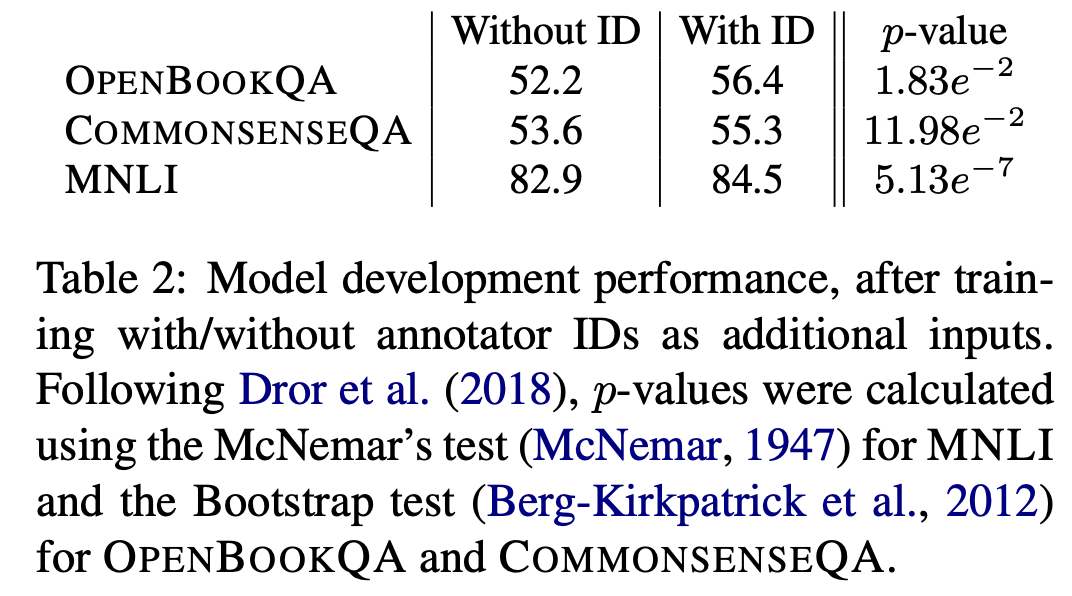
상당수의 NLP 데이터셋은 크라우드소싱으로 만들어집니다. 이러한 과정에서 몇 명의 숙련된 워커가 데이터 생성에 기여를 많이 하게 되면 필연적으로 워커에 따른 bias가 생깁니다.
본 논문에서는 실험할 때 워커 ID를 feature로 넣으면 모델의 성능이 올라감을 보이고, 트레이닝셋에 기여하지 않은 워커가 만든 테스트 데이터에 대해서는 성능이 떨어짐을 보였습니다. 이를 통해 추론할 때, 워커에 따른 bias가 존재함을 확실하게 알 수 있습니다.
저자들은 결과적으로 사람의 수작업 레이블링을 통해 NLP 데이터셋을 만든다면 annotator bias를 모니터링하여 관리하는 것은 필수적이며, 트레이닝/테스트셋의 annotator는 격리(disjoint)되어야 한다고 주장합니다.
How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
-
저자: Kawin Ethayarajh @ Stanford University
-
주제: Word embedding
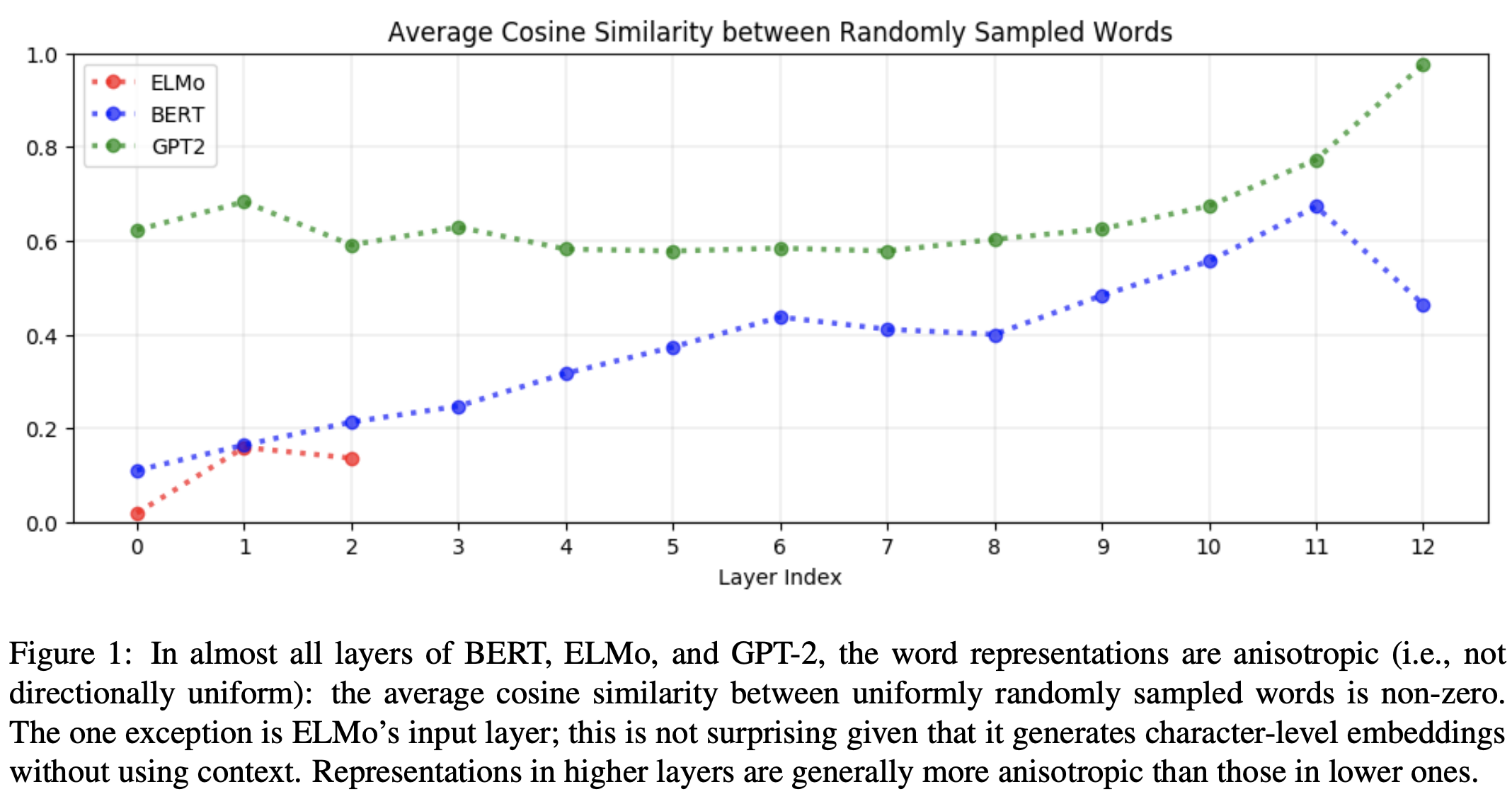
word2vec과 같은 정적 단어 임베딩 이후에 ELMo, BERT, GPT 같은 contextualized word embedding 기법들이 나오면서 다양한 NLP 태스크에서 기존보다 훨씬 좋은 성능을 보여주고 있습니다. ELMo, BERT, GPT 같은 모델은 양방향(bi-directional) 또는 상호 참조(self-attention)를 기반으로 하는 구조이므로 이론적으로는 단어 임베딩이 contextual 합니다. 그러나 우리는 각 단어가 얼마나 문맥을 고려하는지는 정량적, 정성적으로 알지 못한 채 여러 문제를 풀어왔습니다.
본 논문에서는 각 모델별, 레이어별로 각 단어의 분포를 기하적으로 표현해 정성적인 평가를 해보고, contextuality를 정량적으로 평가하는 방식(IntraSim, SelfSim, MEV)을 제시합니다. 이를 통해 다음과 같은 결론에 도달합니다:
- 모든 레이어별로 동일한 contextuality를 보이지 않습니다. 이와 마찬가지로 각 모델별로 contextuality에 관여하는 레이어가 다릅니다. (ELMo는 상위, BERT는 중간, GPT는 하위 레이어에서 각각 더 많은 기여)
- Contextual embedding은 기하학적으로 anisotropic (비등방성; 방향에 따라 성질이 달라짐) 하나, 정적 임베딩은 isotropic (등방성; 어떤 방향으로든 성질이 동일함) 합니다. 즉, 문맥에 기반한 임베딩은 한쪽으로 치우쳐 있다고 표현할 수 있습니다.
- Contextual embedding에서 어떤 레이어는 단어 토큰간의 상관관계에 영향을 강하게 받는가 하면, 어떤 레이어는 문맥에 더 영향을 많이 받는 것으로 확인되었습니다.
MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance
-
저자: Wei Zhao et al. @ Technische Universität Darmstadt (TU Darmstadt)
-
주제: Evaluation metric, Text generation
BLEU나 ROUGE는 Text generation 태스크에서 평가 척도로 자주 사용됩니다. 이 방식은 모델이 생성한 문장과 정답 문장이 형태적으로 얼마나 유사한지를 평가합니다. 하지만 이상적인 평가 방식은 단순히 표면적으로 똑같은지보다는 두 문장의 의미가 동일한지 평가하는 방식일 것입니다.
본 논문에서는 실제 사람이 평가하는 점수와 상관관계가 높은 새로운 평가 척도를 제시합니다. 저자들은 BERT, ELMo와 같은 contextual embedding을 사용해 이에 대한 거리(distance)를 feature로 사용했습니다. 선행 연구 중 BERTScore (Tianyi Zhang et al., 2019)와 유사한 점이 있지만 이와의 차이점과 개선방안을 제시합니다.
기존의 평가 척도보다 여러 태스크에서 유연하게 사용될 수 있고 실제 사람의 퀄리티를 더 잘 반영한다고 주장합니다.
마치며
이번 포스트에서는 오는 11월 초에 홍콩에서 열리는 EMNLP-IJCNLP 2019에 대해 전반적으로 살펴 보았습니다. 제출 논문의 수가 꾸준히 증가하는 가운데 올해는 총 465편의 논문이 게재 승인되었고, 그 중 12편의 논문을 선정해 조금 더 자세히 들여다 보았습니다.
Acceptance rate 추이에서도 볼 수 있듯 우리는 논문이 범람하는 세상에 살고 있습니다. 기술이 나날이 진보하고 있다는 생각에 기대감으로 부푸는 한편, 논문의 바다에서 길을 잃고 표류하지 않을까 걱정이 앞서기도 합니다. 제출된 모든 논문을 읽기란 불가능에 가깝습니다. 어떤 논문을 읽어야 할지 정하는 것조차 쉽지 않죠. 이 글이 EMNLP를 제대로 즐기는 데에 조금이나마 도움이 되었으면 좋겠습니다.
자, 그럼 이제 남은 건 EMNLP를 씹고 뜯고 맛보고 즐길 일뿐이네요. 조만간 EMNLP-IJCNLP 2019 리뷰 포스트로 돌아오겠습니다!
References
- Papers
- Retrofitting Contextualized Word Embeddings with Paraphrases (Weijia Shi et al., 2019)
- Adversarial Examples for Evaluating Reading Comprehension Systems (Jia and Liang, 2017)
- CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis (Mengting Hu et al., 2018)
- FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow (Xuezhe Ma et al., 2019)
- Modeling Event Background for If-Then Commonsense Reasoning Using Context-aware Variational Autoencoder (Li Du et al., 2019)
- Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks (Chen Zhang et al., 2019)
- Improving Relation Extraction with Knowledge-attention (Pengfei Li et al., 2019)
- The Woman Worked as a Babysitter: On Biases in Language Generation (Emily Sheng et al., 2019)
- CrossWeigh: Training Named Entity Tagger from Imperfect Annotations (Zihan Wang et al., 2019)
- Adversarial Domain Adaptation for Machine Reading Comprehension (Huazheng Wang et al., 2019)
- Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets (Mor Geva et al., 2019)
- How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings (Kawin Ethayarajh, 2019)
- MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance (Wei Zhao et al., 2019)
- BERTScore: Evaluating Text Generation with BERT (Tianyi Zhang et al., 2019)
- Articles