EMNLP 2020 프리뷰
알아두면 쓸데있는 신비한 EMNLP 2020! 저희가 준비해보았습니다.







Conference on Empirical Methods in Natural Language Processing (EMNLP)은 자연어 처리(NLP) 분야를 주도하는 국제 컨퍼런스 중 하나로 매년 많은 NLP 연구자들이 주목하는 학회입니다. 올해 EMNLP는 COVID-19로 인해서 온라인 형식으로 진행됩니다. 그래서 핑퐁팀은 메인 컨퍼런스가 진행되는 11월 16일부터 20일에 다 같이 모여 관심 있는 발표들을 들어볼 예정입니다.
학회에 제출된 논문 중 팀원들이 관심 있는 주제로 각자 한 편씩 선정하여 총 7편을 간단히 리뷰 해보았습니다. 또한 주홍님의 시각화 자료를 기반으로 이번 학회의 키워드, 주제 등을 분석한 내용을 첨부했으니 이번 학회에 관심 있는 분들께 도움이 되었으면 좋겠습니다.
* 본 글에 나열된 논문들과 그 순서는 각 팀원들의 주관적인 취향을 기준으로 정한 것이며 객관적으로 평가된 것이 아니라는 것을 다시 한번 말씀드립니다.
학회 추이
키워드로 보는 학회

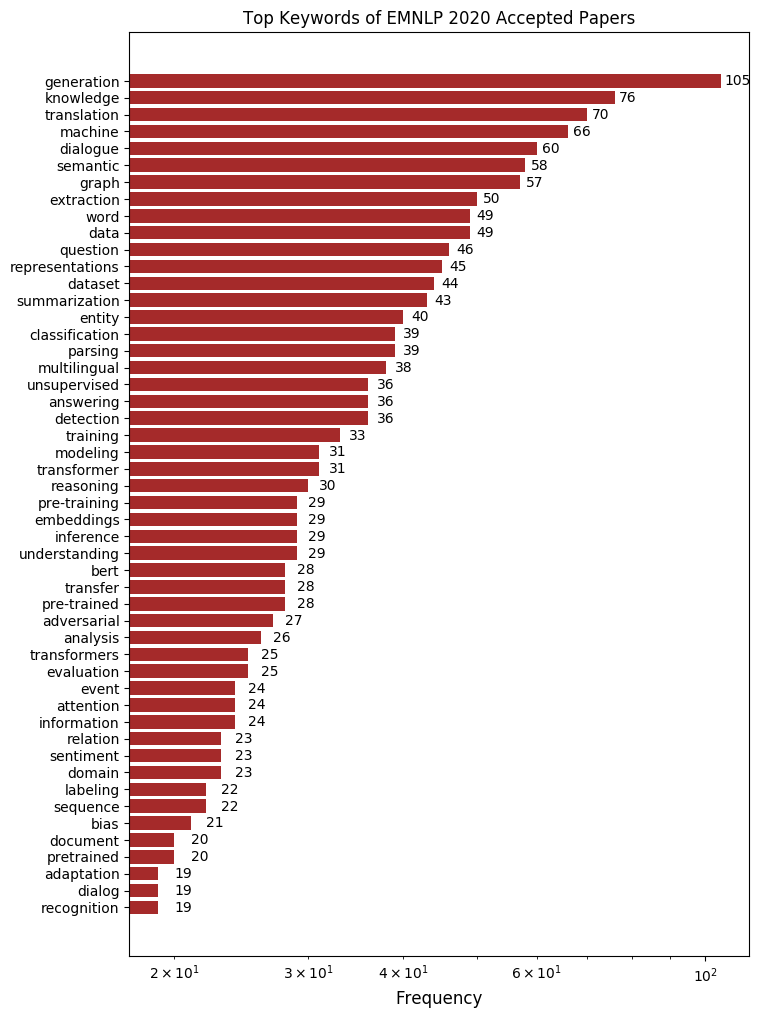
논문 제목에 나타난 단어를 빈도 순으로 나타내 보았습니다. 그 중에서 이번 EMNLP에서 특히 주목할 만한 키워드 세 가지를 살펴 보겠습니다.
Generation
변함없이 제일 많이 사용된 키워드는 “generation”입니다. 무려 105회나 쓰였습니다. 어떻게 좋은 문장을 생성하는가는 자연어 처리에서 매우 중요한 문제입니다. 올해 OpenAI에서 발표한 GPT-3가 놀라운 성과를 보여준 것과 더불어 올해 EMNLP에서는 자연어 생성 관점에서 여러 가지 방향으로 연구가 활발히 진행되고 있습니다. 기존의 연구들이 문맥에 맞는 말을 생성하는 것에 집중하였다면 현재의 생성 연구는 1) 보다 다양한 말을 하도록, 2) 일관적인 말을 하도록, 3) 편견이나 차별이 포함된 말을 하지 않도록 하는 등 여러 가지 방면에서 진행되고 있습니다. 연구자들이 생성에서 현재 어떤 문제에 관심을 갖고 있는지는 이번 학회에서 꼭 주목해야 할 점입니다.
Dialogue
두 번째로 많이 나온 키워드는 “dialogue”로 “dialog”까지 포함하면 총 79회 쓰였습니다. EMNLP 2019의 논문 제목 키워드와 비교를 해보았을 때 “dialogue” 키워드 순위가 작년에 비해 월등히 높아진 것을 알 수 있습니다. 이는 NLP 분야가 발전함에 따라 대화 관련 연구들이 더욱 활발하게 이루어지고 있기 때문입니다. 대화를 잘 한다는 것은 한 가지의 능력이 아니라 종합선물세트 같이 여러 능력을 모두 필요로 합니다. 오픈도메인 챗봇 분야를 연구하고 있는 만큼 핑퐁팀도 이번 EMNLP 에서 어떤 연구가 진행되었는지 주의 깊게 보고자 합니다.
Knowledge
그 다음으로 많이 나온 키워드는 “knowledge”입니다. 특히 “knowledge graph”, “knowledge-grounded”, “knowledge distillation” 관련된 논문들이 많았습니다. 지금까지의 논문들은 주로 QA 분야에서 지식 그래프를 이용하는 것에 그쳤다면 최근에는 대화처리나 생성, 감정 분석 등 다른 태스크에서 외부 지식을 활용하여 문제를 더 잘 풀어 보려는 노력이 활발히 이루어지고 있습니다. 또한 이러한 지식을 어떻게 다른 도메인 문제에 녹여낼 것인지(domain adaptation), 또 방대한 지식들을 보다 가벼운 모델에 담을 수 있는지(경량화)의 관점에서 다뤄지고 있습니다.
논문 Review
총 7편의 논문을 abstract와 핵심 figure를 중심으로 간략하게 리뷰 해보았습니다.
Learning a Simple and Effective Model for Multi-turn Response Generation with Auxiliary Tasks
저자 : Yufan Zhao, Can Xu, Wei Wu (Microsoft Corporation)
키워드 : Response Generation
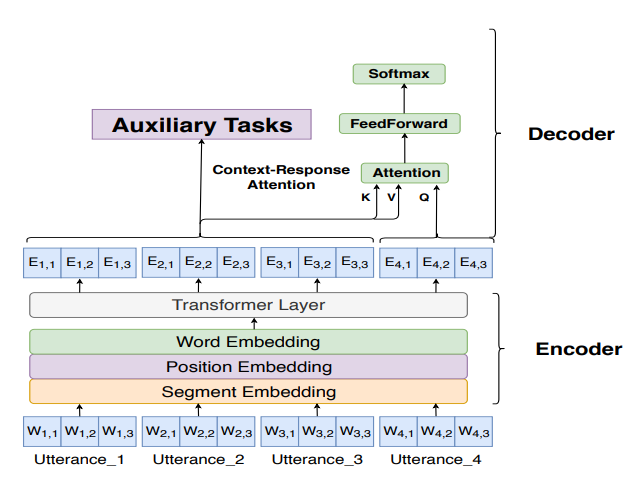
- 기존의 오픈 도메인 대화에서 멀티턴 응답 생성은 딥뉴럴 네트워크 구조를 사용해 좋은 성능을 보여왔지만 복잡성 때문에 시스템에 모델을 적용하는 데 어려움을 겪습니다. 본 논문에서는 단순한 구조로 대화 문맥에 맞게 응답을 생성할 할 수 있는 모델을 제시합니다.
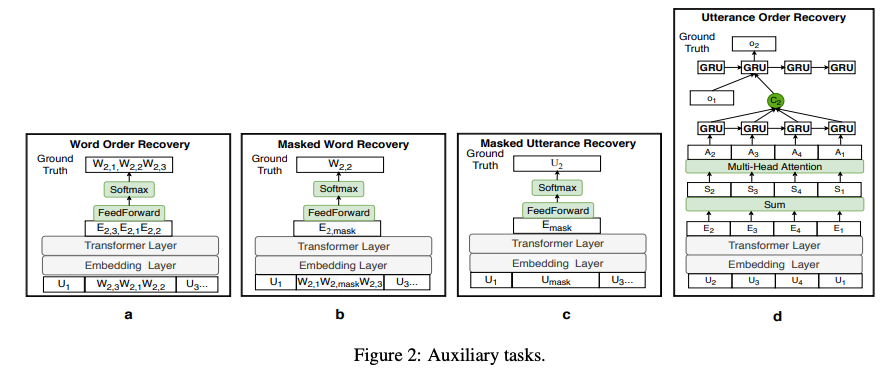
- 이를 위해서 총 네 가지의 보조 태스크들을 제안합니다.
- Word Order Recovery
- Utterance Order Recovery
- Masked Word Recovery
- Masked Utterance Recovery
- 모델은 생성의 likelihood를 최대화하면서 네 가지 보조 태스크도 함께 최적화합니다. 이 보조 태스크는 더 나은 생성 모델을 만들기 위한 가이드를 준다고 볼 수 있습니다.
- 여러 벤치마크로 평가했을 때 추가적인 태스크를 함께 학습한 모델이 automatic 평가와 사람들이 한 정성평가 결과가 훨씬 좋았습니다. 아울러 제안한 모델은 기존 모델보다 더 빠르게 문장을 생성합니다.
$F^2$-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
저자 : Byung-Ju Choi, Jimin Hong, David Keetae Park, Sang Wan Lee (Humelo, Columbia University, KAIST)
키워드 : Generation
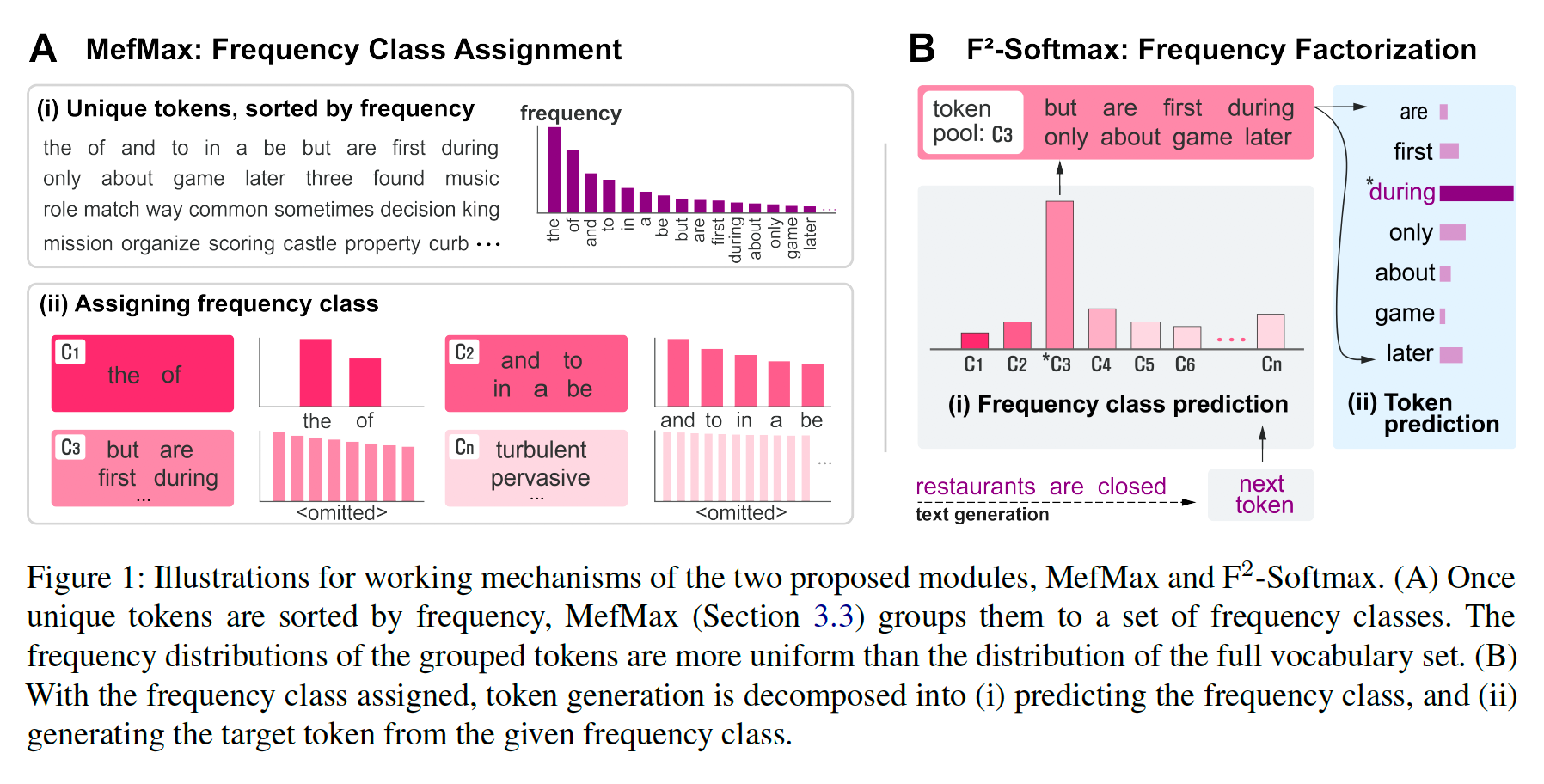
- 일반적인 MLE 방식의 생성 모델은 학습 코퍼스의 토큰 분포를 학습하기 때문에 주로 뻔한 토큰이 생성되는 문제가 있습니다.
- 이 문제를 해결하기 위해서 softmax를 취할 때 불균형 문제를 완화시키는 $F^2$-softmax 방법을 제안합니다. 다음 토큰을 예측하는 확률을 토큰이 속한 클래스를 예측하는 확률과 그 클래스에 속한 토큰을 예측하는 확률로 factorize하여 생각함으로써 동일한 클래스 안에서 토큰 빈도가 기존보다 덜 불균형해집니다.
- 또한 각 토큰을 어떤 클래스로 분류할지를 최적화하기 위해 클래스의 분포 및 각 클래스의 토큰 빈도 분포를 동시에 균등하게 만드는 MefMax 방법을 제안합니다.
- 영어 WikiText-103 데이터셋 및 한국어 Melo-Lyrics 데이터셋을 이용한 LM 태스크에서 생성 문장의 다양성이 크게 향상되는 것을 검증했습니다.
Intrinsic Probing through Dimension Selection
저자 : Lucas Torroba Hennigen, Adina Williams, Ryan Cotterell (Québec Artificial Intelligence Institute (Mila), University of Cambridge, Facebook AI Research, ETH Zürich)
키워드 : Embeddings, Probing, Contexual Representation
- 이전 논문들에서 문장의 임베딩이 시제, 격이나 양태 등의 통사 구조 정보를 포함하고 있음을 시사합니다. 본 논문에서는 “그렇다면 문장의 통사 구조는 몇 차원으로 표현될 수 있는가”를 연구하였습니다.
- 이를 알아보기 위해 임베딩을 구성하는 각 차원 성분을 선택/배제해가며 성능의 추이를 같이 관찰하는 Intrinsic Probing을 제안하였습니다. 아울러 이 probing 방식은 너무 느리기 때문에 전체 임베딩 공간의 각 성분을 다변량 정규분포로 가정하여 factorize하는 방식을 함께 제안하였습니다.
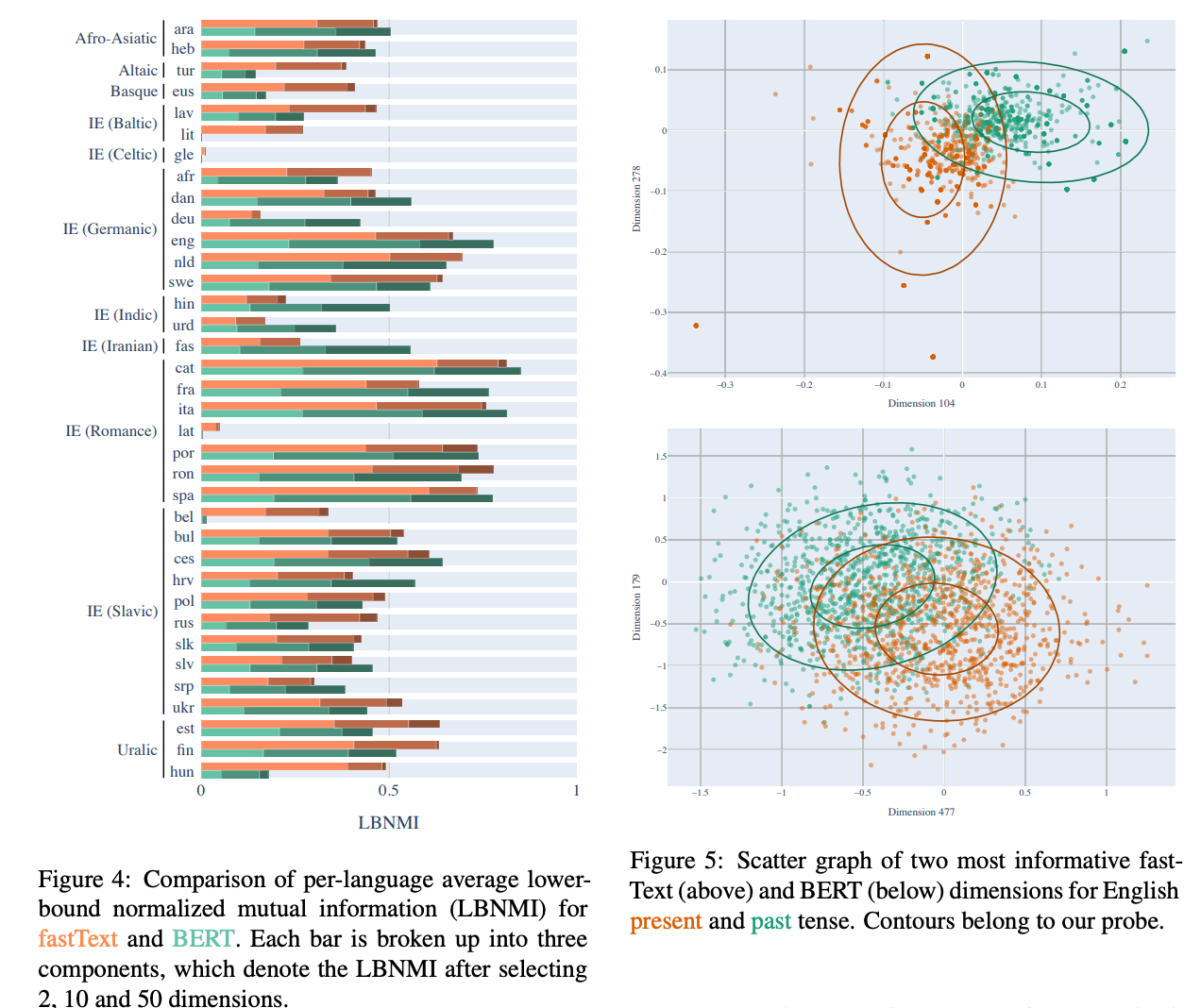
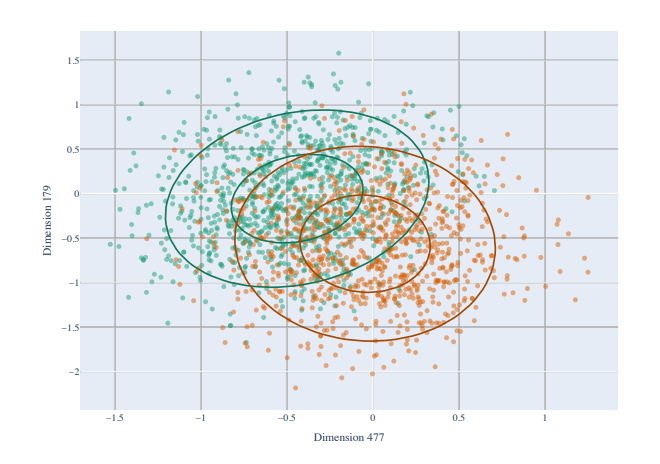
- 768 차원의 fastText와 BERT를 사용해 각 통사 성분으로 레이블링된 문장으로 probing을 진행하였으며 그 결과는 놀랍습니다. 대부분의 통사 구조는 50차원 이내로 표현될 수 있었으며 BERT가 35차원이 필요한 것과는 다르게 fastText는 평균 10차원만을 활용해서 통사 정보를 표현할 수 있었습니다.
- 저자는 영어 외의 다른 언어들로 동일한 실험을 진행하였으며 이 현상이 만국공통으로 나타난다는 것을 확인하였습니다.
- 임베딩의 각 성분이 다변량 정규분포로 표현될 수 있다는 가설은 매우 강한 가설이며 현실과 어느 정도 배치됩니다. 그럼에도 불구하고 통사 구조가 훨씬 작은 차원의 공간으로 표현됨을 시사한 점과 언어 현상을 probing을 통해 기술하는 방법을 제시한 점에서 의의가 있다고 생각합니다.
Will I Sound Like Me? Improving Persona Consistency in Dialogues through Pragmatic Self-Consciousness
저자 : Hyunwoo Kim, Byeongchang Kim, Gunhee Kim (Seoul National University)
키워드 : Generation, Persona Consistency
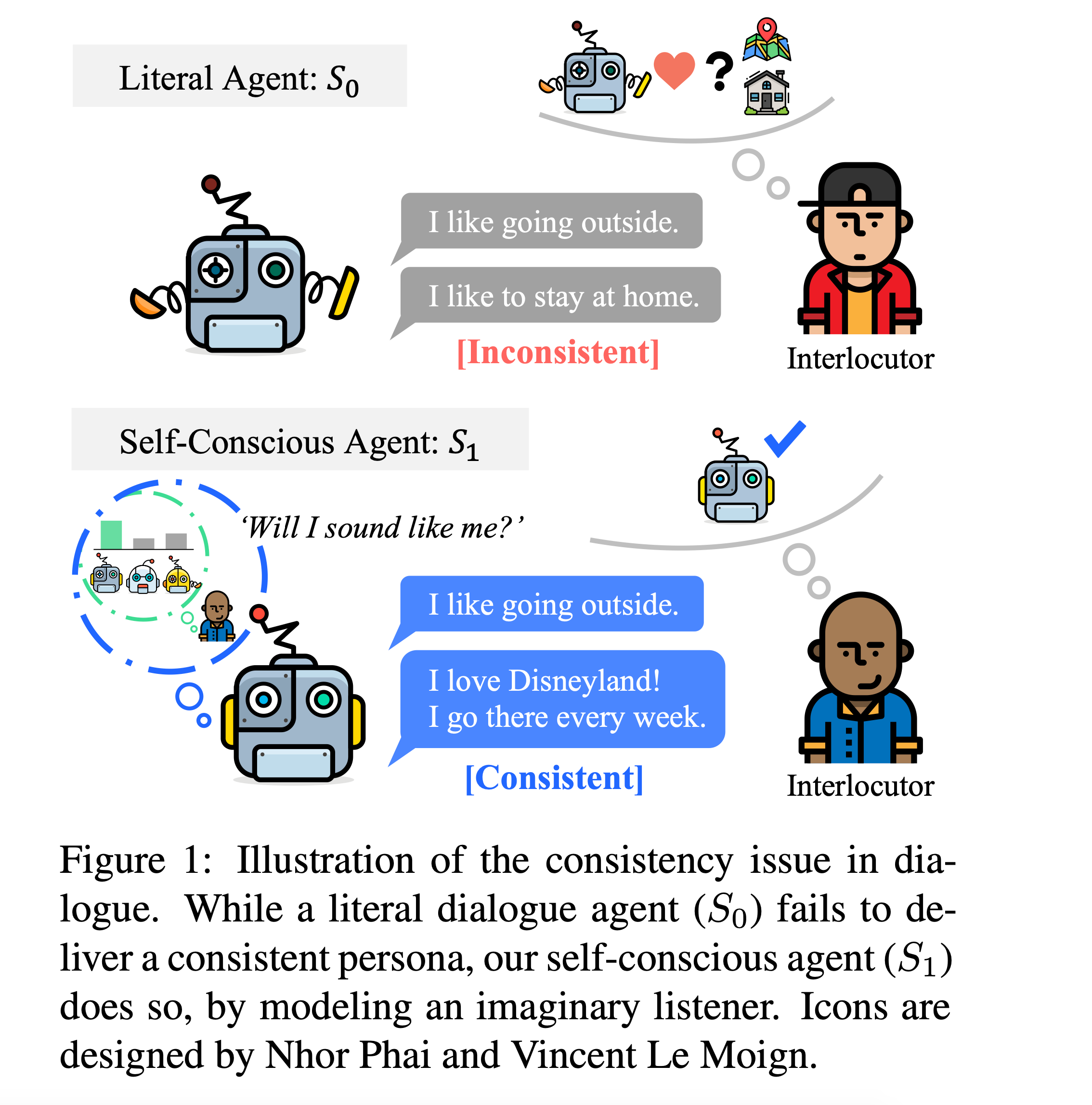
- 본 논문에서는 추가적인 NLI 레이블이나 훈련된 모듈 없이 페르소나 일관성을 높이는 학습 방법을 제시합니다. self-conscious speaker가 일관된 페르소나로 말할 것이라는 가정이 이 논문의 주요한 아이디어입니다. self-conscious speaker를 구현하기 위해 rational speech acts (RSA) 방법을 기반으로 imaginary listener를 도입하여 모델을 학습하였습니다.
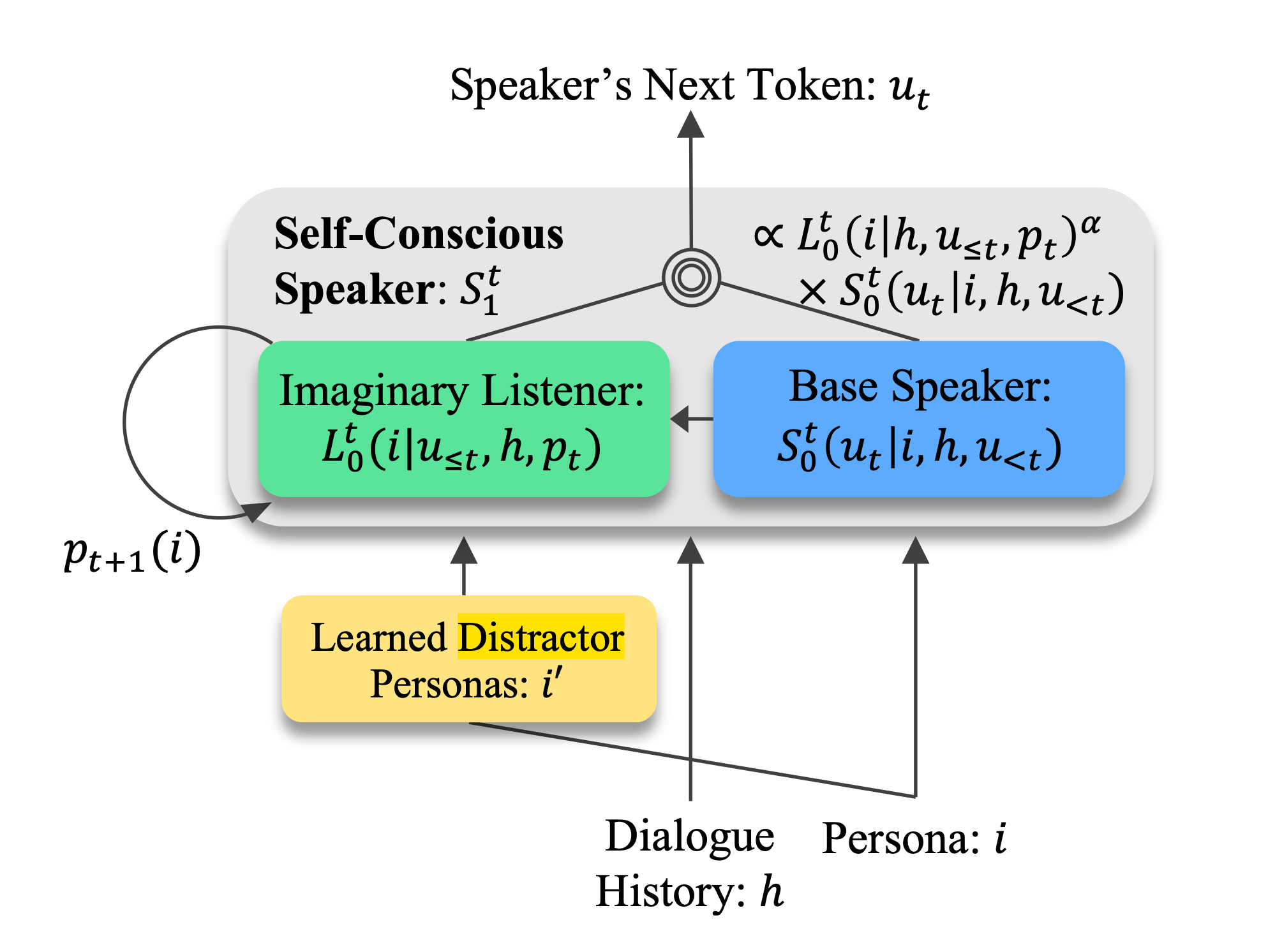
- 학습 시 어떤 persona distractor를 고르는 지가 성능에 큰 영향을 미칩니다. 본 논문에서는 distractor selection task의 방법론으로 memory network를 기반으로 Distractor Memory Network를 제안 하였으며 random이나 BERT 기반 모델 보다 더 높은 성능을 보였습니다.
- Dialogue NLI Evaluation set, PersonaChat dialogue에서 더 좋은 성능을 보였고 human evaluation 지표도 모두 개선되었습니다. 특히 이 방법론은 기존의 dialogue system의 구조 변경 없이 생성모델 기반 챗봇에 범용적으로 적용할 수 있다는 점에서 큰 장점이 있습니다.
Experience Grounds Language
저자 : Yonatan Bisk, Ari Holtzman, Jesse Thomason et al.
키워드 : Language Grounding

- 본 논문에서는 현 시점에서 NLP 연구가 부딪힌 문제와 지닌 한계를 지적하면서 NLP 모델(또는 에이전트)이 발전한 정도를 가늠할 수 있는 다섯 단계 척도인 World Scope(WS)를 제안합니다. 단계별 수준과 한계를 명확히 정의하기 위해 인용한 과거 논의부터 그 한계를 극복하기 위해 이어져온 최근 연구에 이르기까지 방대한 레퍼런ㄴ스를 통해 NLP 커뮤니티의 현재와 나아가야 할 방향을 제시하는 논문입니다.
- 논문에서 제시한 척도는 다음과 같습니다.
- WS1: Corpus. Penn Treebank로 대표되는 언어학 지식 기반 코퍼스와 이를 중심으로 하는 연구로 대체로 과거에 연구된 NLP 패러다임입니다.
- WS2: Internet. 인터넷이라는 정보의 바다가 생겨나고 대규모 크롤링이 가능해지면서 복잡하고 구조화되지 않은 대규모 텍스트 코퍼스의 시대가 도래했습니다. 데이터뿐만 아니라 모델 크기도 기하급수적으로 커지면서 언어의 더 복잡하고 깊은 면까지 파악할 수 있게 되었고 보다 범용적이고 일반화가 잘 되는 모델이 탄생했습니다. 현재 대부분의 연구가 이 단계에 속합니다.
- WS3: Perception. 사람은 보고, 듣고, 느끼면서 언어를 배웁니다. 언어 모델 또한 Multimodality가 결합된다면 훨씬 더 풍부한 언어의 측면을 배울 수 있을 것입니다. 어쩌면 대규모 인터넷 데이터의 근본적인 한계인 reporting bias와 그에 따른 상식 문제는 상당 부분 자연스럽게 해결될 것입니다. 컴퓨터 비전의 강력한 모델들을 필두로 Multimodality에 대한 연구는 지금도 활발히 진행되고 있습니다.
- WS4: Embodiment. 세상을 단순히 인지한다고 해서 모든 것을 알 수 있는 건 아닙니다. 사람은 주위 환경과 상호작용하면서 물체 간의 상호작용과 인과관계 등을 체득하게 됩니다. 언어에는 당연히 이 같은 요인이 반영되어 있습니다. 따라서 NLP 에이전트는 물리적인 세계와 상호작용하면서 배워야 합니다. 이를 위해 시뮬레이션을 하거나 로보틱스 기술과 결합해 실제 세계와 맞닥뜨리게 할 수 있습니다. 이러한 연구는 아직 기초적인 수준이며 가야할 길이 멉니다.
- WS5: Social. 언어의 궁극적인 목적은 의사소통입니다. 이는 주로 대화로써 이루어지기에 상대방의 감정과 의도를 파악하는 것이 매우 중요합니다. 사람은 축적된 경험과 사회화를 통해 이를 자연스럽게 배우지만 지금의 챗봇은 개인의 경험을 반영하여 학습하지 못하며, 사회적 행동의 결과를 배울 만한 환경 역시 마련되어 있지 않습니다.
- 본 논문은 어렵지 않고 꽤나 공감할 만한 문제의식과 통찰을 던져주니 한번 읽어보시면 좋을 듯합니다.
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
저자 : Nils Reimers, Iryna Gurevych (UKP-TUDA)
키워드 : Sentence Embeddings, Multilingual, Knowledge Distillation
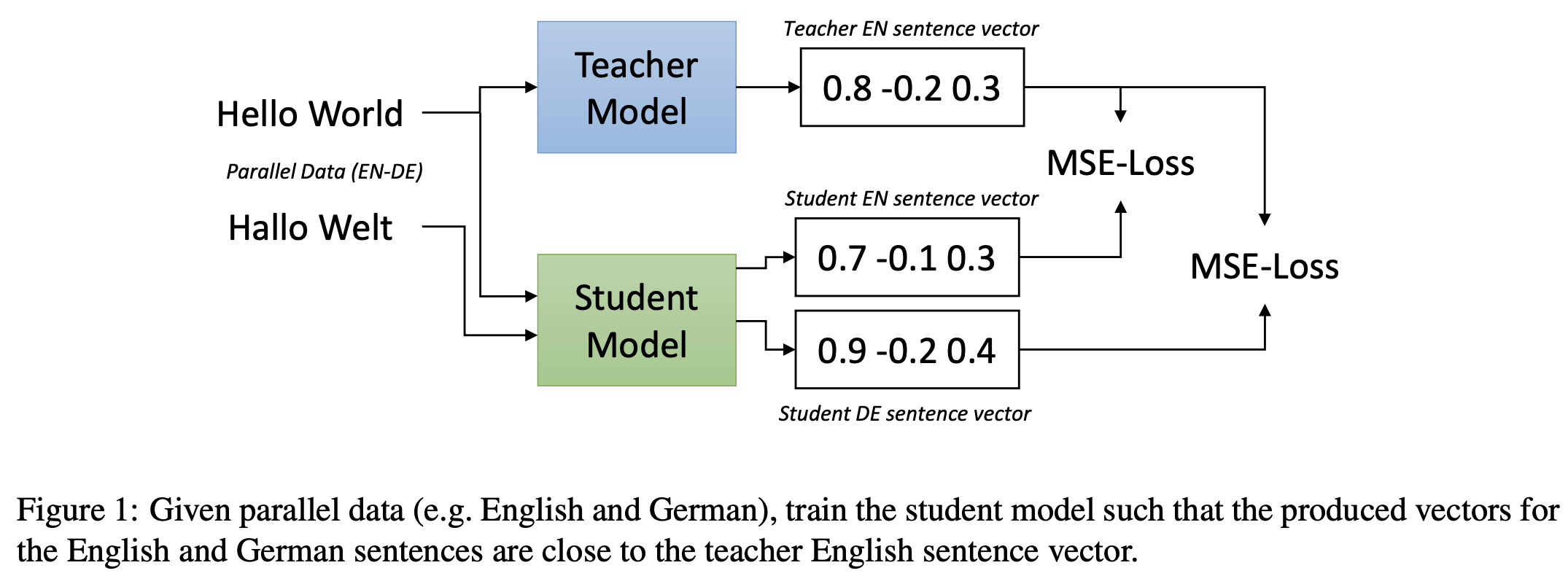
- 본 논문은 문장 임베딩 모델을 새로운 언어로 확장하는 쉽고 효율적인 기법을 제안합니다. 즉, 단일 언어 모델을 다중 언어 모델로 확장하는 문제를 다루고 있습니다.
- 기본 아이디어는 번역을 위한 병렬 코퍼스를 이용해서 소스 언어에 대한 문장 임베딩과 타겟 언어에 대한 문장 임베딩이 같아지도록 학습하는 것입니다.
- Knowledge Distillation 개념을 가미하여 동일한 소스 언어에 대해 다중 언어 모델 (student model)이 단일 언어 모델 (teacher model)과 동일한 임베딩을 형성하도록 같이 학습합니다.
- 본 논문의 방법은 기존의 방법들 보다 훨씬 간단한 모델 및 학습 방법이며 Semantic Textual Similarity (STS), Bitext Retrieval, Cross-lingual Similarity Search 태스크에서 기존보다 좋거나 비슷한 성능을 보였습니다. 50개 이상의 언어에서 효과를 증명했고 400개 이상의 언어로 문장 임베딩을 확장하는 코드도 함께 공개하였습니다: https://github.com/UKPLab/sentence-transformers.
Unsupervised Commonsense Question answering with Self-Talk
저자 : Vered Schwartz, Peter West, Ronan Le Bras, Chandra Bhagavatula, Yejin Choi (Allen Institute for Artificial Intelligence, University of Washington)
키워드 : Question Answering

- 본 논문은 사전 학습된 생성모델(GPT, XLNET 등)을 이용해서 다지선다 상식 추론 문제를 해결하고자 합니다. 정답을 예측하는 방법은 각 후보의 PPL을 측정하고 가장 낮은 PPL의 후보를 가장 자연스럽다고 판단하여 이를 정답으로 예측합니다.
- 저자는 사전 학습된 생성모델에 이미 어느 정도 세상에 대한 상식이 포함되어 있음을 가정합니다. 이 논문의 주요한 아이디어는 생성모델이 가진 상식을 명시적으로 끌어내어 상식 추론 문제를 더 잘 풀어보자는 것입니다.
- 사전학습된 생성 모델이 가진 상식 정보를 이끌어내는 self-chat 기법은 다음과 같습니다.
- Question Generation : 주어진 문맥에 대응되는 질문을 사전에 정의된 질문형 접두문을 기반으로 생성합니다. 예를 들어 문맥 뒤에 “What is the purpose of”를 붙이고 necleus sampling을 이용해 총 5가지의 질문을 생성합니다.
- Clarification Generation : 주어진 질문에 대응되는 설명을 생성합니다. 이 과정으로 사전학습 모델이 가진 세상의 지식을 명시적으로 끌어 냅니다.
- Clarification + Context : 생성된 지식과 기존의 문장을 붙여서 문제를 풉니다. 위에서 생성된 5개의 변형된 문맥 중에서 가장 PPL이 낮은 후보를 최종 정답으로 예측합니다.
- 위 방법의 유효성을 검증하기 위해서 저자는 다음과 같은 베이스라인과의 성능을 비교하였습니다.
- 사전 학습된 생성 모델만을 사용해 문제를 풀었을 때(zero-shot)
- 명시적인 외부 지식을 지식 그래프, n-gram retrieval 등을 이용해 추출한 뒤 텍스트 형태로 문맥 뒤에 추가 하여 문제를 풀었을 때
- 제안한 방법은 zero-shot보다 월등히 좋은 성능을 보였고 명시적으로 외부지식을 사용한 베이스라인 보다는 성능이 미세하게 낮거나 유사하였습니다. 추가적인 모델이나 데이터셋을 사용하지 않고 사전학습 모델만 활용했는데도 크게 성능이 좋아진 것이 주요한 contribution입니다.
마치며
NLP 기술이 점차 발전하면서 다양한 방법과 주제로 이전보다 많은 양의 논문이 발표되고 있으며 그 것들을 모두 읽는 것은 어렵습니다. 따라서 연구와 개발에 필요한 논문을 잘 고르는 것이 중요합니다. 핑퐁팀은 새로운 아이디어를 제공하는 논문을 취사선택하여 읽고 연구에 도움이 되는 방향을 고민합니다. 이 문제 의식 속에서 나온 저희 글이 EMNLP 2020을 제대로 즐기는 데 조금이나마 도움이 되길 바랍니다.
References
- Papers
- Learning a Simple and Effective Model for Multi-turn Response Generation with Auxiliary Tasks (Yufan Zhao et al., 2020)
- F2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax (Byung-Ju Choi et al., 2020)
- Intrinsic Probing through Dimension Selection (Lucas Torroba Hennigen et al., 2020)
- Will I Sound Like Me? Improving Persona Consistency in Dialogues through Pragmatic Self-Consciousness (Hyunwoo Kim et al., 2020)
- Experience Grounds Language (Yonatan Bisk et al., 2020)
- Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation (Nils Reimers et al., 2020)
- Unsupervised Commonsense Question Answering with Self-Talk (Vered Shwartz et al.,2020)
- Articles