EMNLP 2022 Review
핑퐁팀과 함께하는 EMNLP 2022 Review

The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)는 자연어 처리 분야 최고의 국제 컨퍼런스로서 최신 NLP 연구들이 발표되는 행사입니다.
저희 핑퐁팀의 이녕우님이 이번 EMNLP 2022에 Accept된 Pneg: Prompt-based Negative Response Generation for Dialogue Response Selection Task 논문 발표를 위해 행사 장소인 아부다비로 떠나셨고, 나머지 팀원들은 3박4일 동안 별도의 공간을 마련하여 온라인으로 논문 발표를 듣고 함께 토론하는 즐거운 시간을 가졌습니다!
발표된 논문 중 인상 깊었던 논문을 각자 한 편씩 선정하여 총 14편을 간단히 리뷰해보았습니다. 현재 핑퐁팀이 관심있게 보고있는 연구라고 할 수 있을 것 같아요! 재미있게 읽어주세요 😀
- Keep Me Updated! Memory Management in Long-term Conversations
- FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
- Are Large Pre-Trained Language Models Leaking Your Personal Information?
- A Distributional Lens for Multi-Aspect Controllable Text Generation
- Generative Multi-hop Retrieval
- InstructDial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
- Re3: Generating Longer Stories With Recursive Reprompting and Revision
- Fine-tuned Language Models are Continual Learner
- The “Problem” of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation
- PromptBERT: Improving BERT Sentence Embeddings with Prompts
- Towards Tracing Factual Knowledge in Language Models Back to the Training Data
- Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
- Iteratively Prompt Pre-trained Language Models for Chain of Thought
- WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
Keep Me Updated! Memory Management in Long-term Conversations
작성자: 고상민
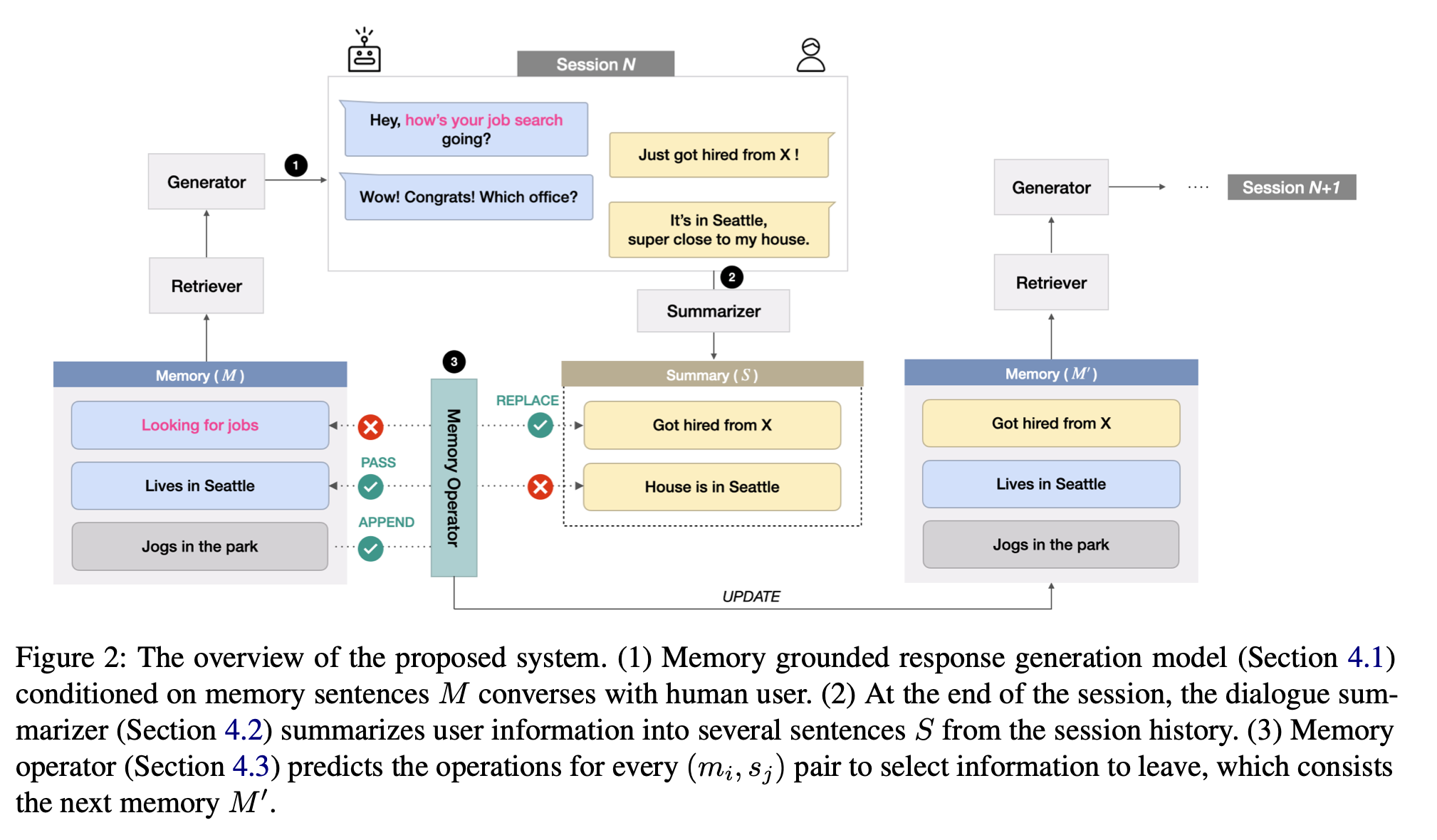
Long-term Conversation에서 중요한 정보를 기억하고 이에 맞게 대화하는 것은 매우 중요합니다. 이전 연구에서는 이전 기억이 업데이트 되지 않고 활용되어 대화 내 모순을 일으킬 수 있습니다. 이를 해결하기 위해 기억 업데이트, 삭제 등이 가능한 시스템을 제안합니다. 또한 케어콜 데이터셋 싱글 세션을 기반으로 레이블링을 통해 멀티 세션 데이터셋, 대화 요약 데이터셋, 기억 활용 대화 데이터셋을 구축하였습니다. 그 결과 저장된 메모리를 그대로 사용하는 Baseline에 비해 유의미한 성능 향상이 있음을 확인하였습니다.
FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
작성자: 류성원
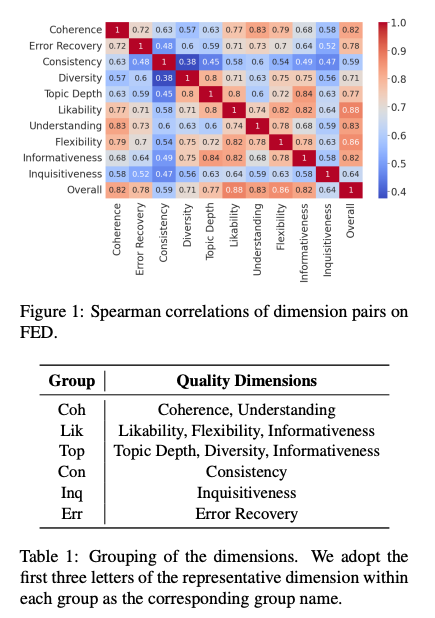
이 논문은 Open-domain Dialogue의 Model-based Reference-free 평가를 위한 메트릭을 제안합니다. Metric 제안을 위하여 이 논문은 FED (Mehri and Eskenazi, 2020a)라는 대화 평가 데이터셋을 사용합니다. 해당 데이터에는 대화마다 5명의 사람이 11개의 기준(Coherence, Understanding, Likability, Flexibility, Informativeness, Topic Depth, Diversity, Informativeness, Consistency, Inquisitiveness, Error Recovery)으로 평가하였습니다. 본 논문에서는 1) Metric 간의 Correlation을 기준으로 11개의 기준을 6가지(Coh, Lik, Top, Con, Inq, Err)로 grouping하고 2) 그 6가지 Metric을 몇 가지 기준으로 Dimension Selection을 하여 최종적으로 Coherence, Likability, Topic depth의 세 가지 차원이 가장 중요하다는 사실을 도출하였습니다. 그리고 이 세 가지 차원의 데이터로 학습하여 사람의 평가와 가장 높은 Correlation을 가진 모델을 만드는 데 성공하였습니다.
Are Large Pre-Trained Language Models Leaking Your Personal Information?
작성자: 강경필

여러 논문에서 Pre-trained Language Model (PLM)은 기억(Memorization)을 잘하기 때문에 개인 정보를 유출할 가능성이 높음을 보여 왔습니다. 이 논문에서도 실험을 통해 PLM이 모델의 크기가 커짐에 따라 Memorization을 더 잘하게 되고, 개인 정보가 유출될 수 있음을 보입니다. 다만, 논문에서는 아직까지 PLM은 정보를 잘 연계하지 못하기 때문에 “특정 인물”의 개인 정보를 유출할 위험은 낮은 것을 실험으로 확인하였습니다. 그럼에도 불구하고 저자들은 초대형 생성 모델이나 입력 정보가 구체적인 경우 개인 정보가 유출될 가능성이 높아지기 때문에 개인 정보 유출을 방지해야 할 필요성을 역설하며, 전처리 과정에서 데이터의 중복을 없애는 방법, 개인정보가 포함된 데이터를 제거하거나 가리는 방법, DP-SGD 등 Differential Privacy 기반의 학습 방법, 생성된 문장에 개인정보가 있는지 등을 검사하여 후처리하는 방법 등을 간단하게 소개합니다.
A Distributional Lens for Multi-Aspect Controllable Text Generation
작성자: 장성보
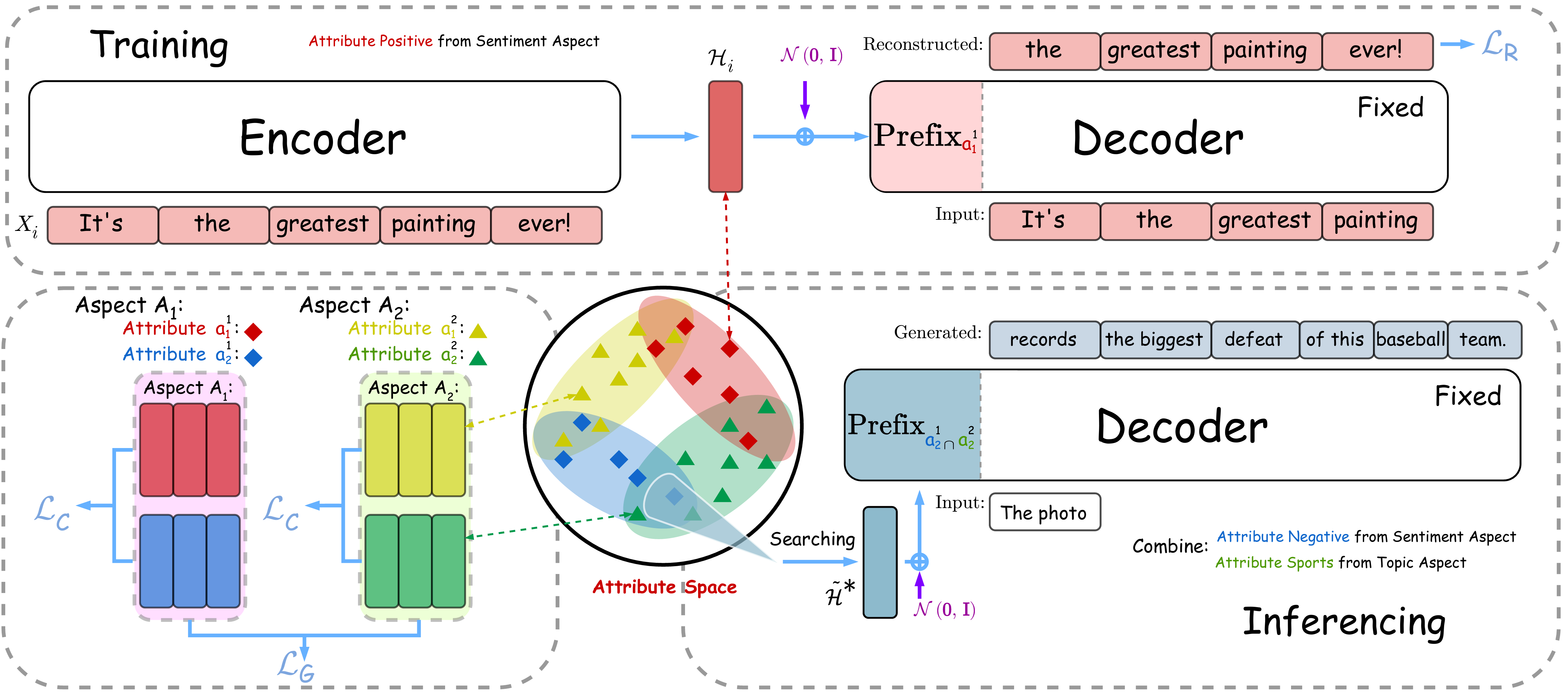
LM이 문장을 생성할 때 여러 Aspect를 동시에 조절하는 것이 어려운데, 기존 연구에서는 보통 각각의 컨트롤러가 Aspect에 해당하는 문장들의 분포를 학습한 뒤 단순하게 Interpolation 하는 방식을 사용했습니다. 이는 분포가 Symmetric하지 않을 때는 Degeneration 문제를 일으킵니다. 논문에서는 Attribute Fusion을 분포의 관점에서 바라보고 여러 분포의 Intersection에서 직접 찾아 생성하는 방법을 제시합니다.
Generative Multi-hop Retrieval
작성자: 이성현
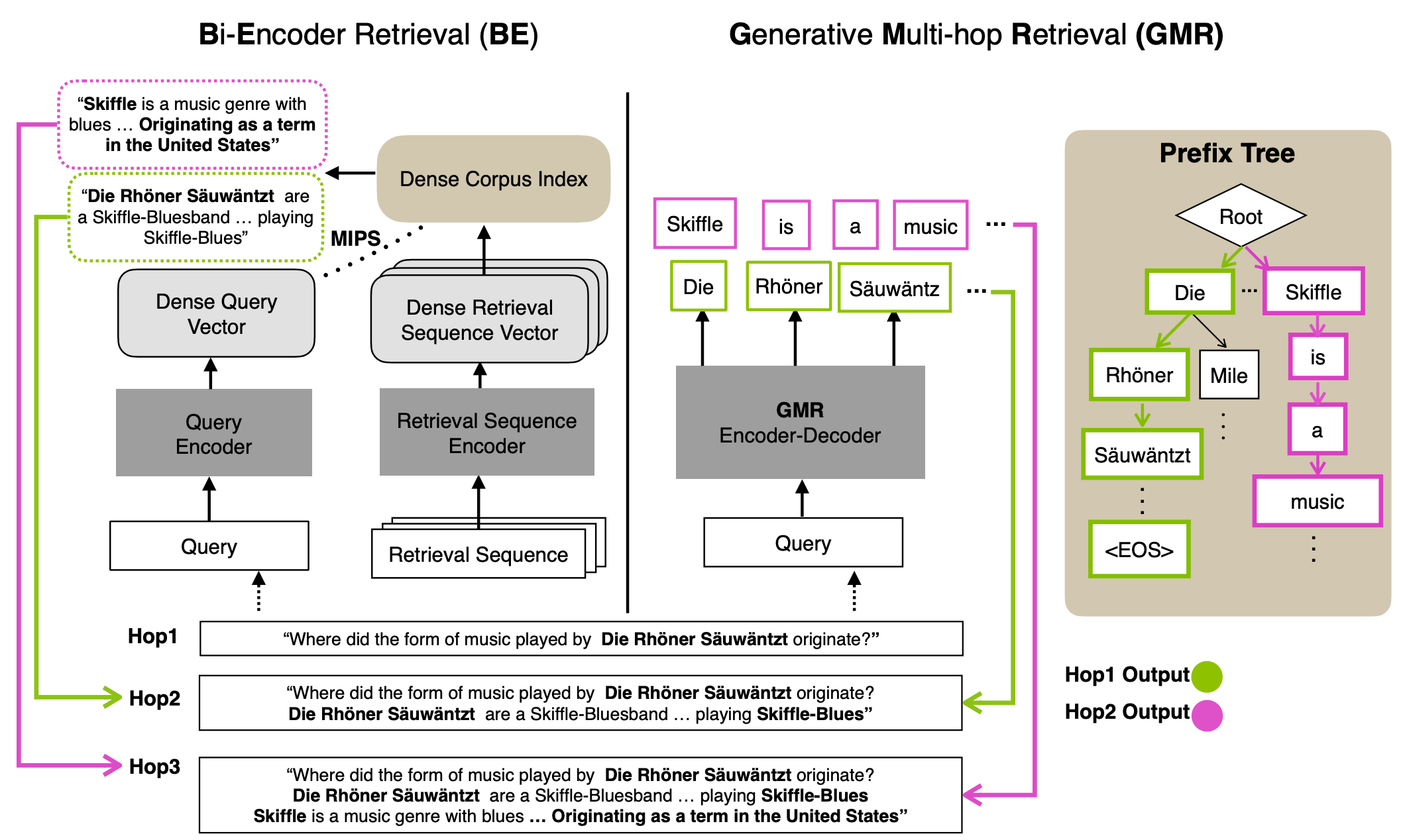
주어진 문서 풀에서 필요한 지식을 검색하는 테스크는 다양한 어플리케이션에서 사용되며 지금까지는 문서와 쿼리를 각각 인코딩하여 벡터로 표현한 뒤, 유사도를 측정하여 검색을 수행해왔습니다. 이 논문에서는 (1) 특정한 벡터 공간으로 인코딩하는 방식이 문서와 쿼리를 충분히 표현하지 못하고, 심지어 (2) 여러 번의 문서 검색이 필요한 상황에서는 오류를 전파시키는 문제점이 있다고 지적합니다. 이러한 문제를 해결하기 위해 저자들은 여러 번의 문서 검색이 필요한 테스크에서 모든 과정을 텍스트를 생성하는 형태로 나타내는 방법을 제안합니다. 구체적으로, 최근에 엔티티 탐지 테스크에서 제안된 접두사 트리를 활용한 생성 기반의 검색 방식을 차용하고 언어 모델 목적식을 활용한 중간 테스크를 학습하여 길이가 긴 문서 풀에 대해서도 생성 모델을 통해 검색이 가능하도록 학습합니다. 학습된 모델은 StrategyQA과 같은 여러 번의 검색을 활용한 다양한 질의응답 테스크에서 Recall과 F1 스코어가 기존 방식을 능가하는 성능을 보여주었으며 여러 번의 문서 검색에서 발생할 수 있는 오류 전파가 기존 방식보다 완화되었음을 실험적으로 검증하였습니다.
InstructDial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
작성자: 이주홍
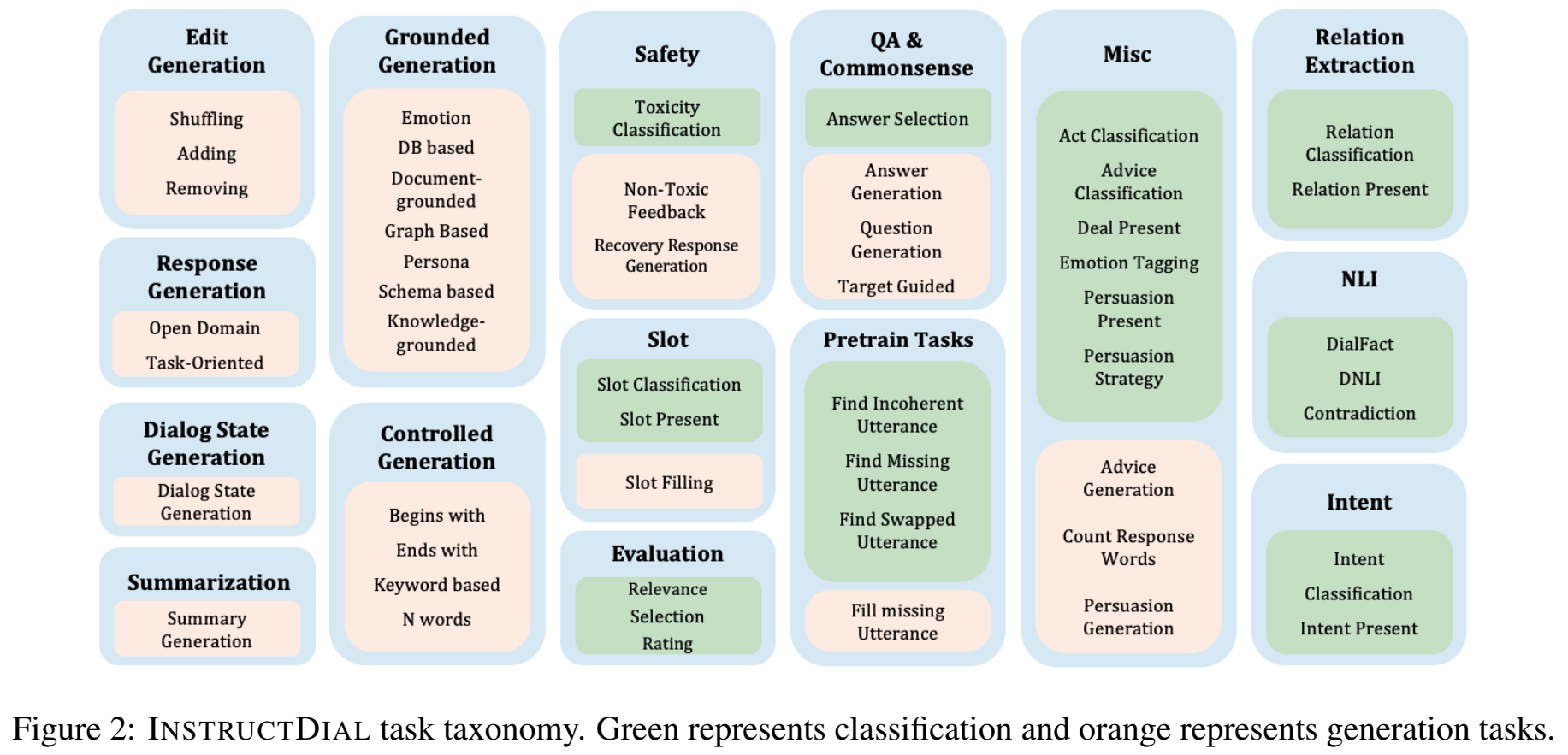
최근에 LLM은 Instruction Tuning을 통해 놀라운 일반화 성능(Zero-shot & Few-shot)을 보이고 있습니다. 하지만 아직 Dialogue 관련 태스크에 대해서는 제대로 다뤄진 적이 없습니다. 본 논문은 InstructDial이라는 Dialogue를 위한 Instruction Tuning 프레임워크를 제안합니다. T0-3B와 BART0 모델을 기반으로 59개의 공개된 대화 데이터셋으로부터 총 48개의 Text-to-Text 형식의 태스크를 만들어서 학습을 시켰습니다. 그 결과 평가를 위한 6개의 대화 관련 Unseen 태스크에서 GPT-3를 비롯한 다른 모델들보다 나은 Zero-shot 성능을 보였습니다.
Re3: Generating Longer Stories With Recursive Reprompting and Revision
작성자: 구상준
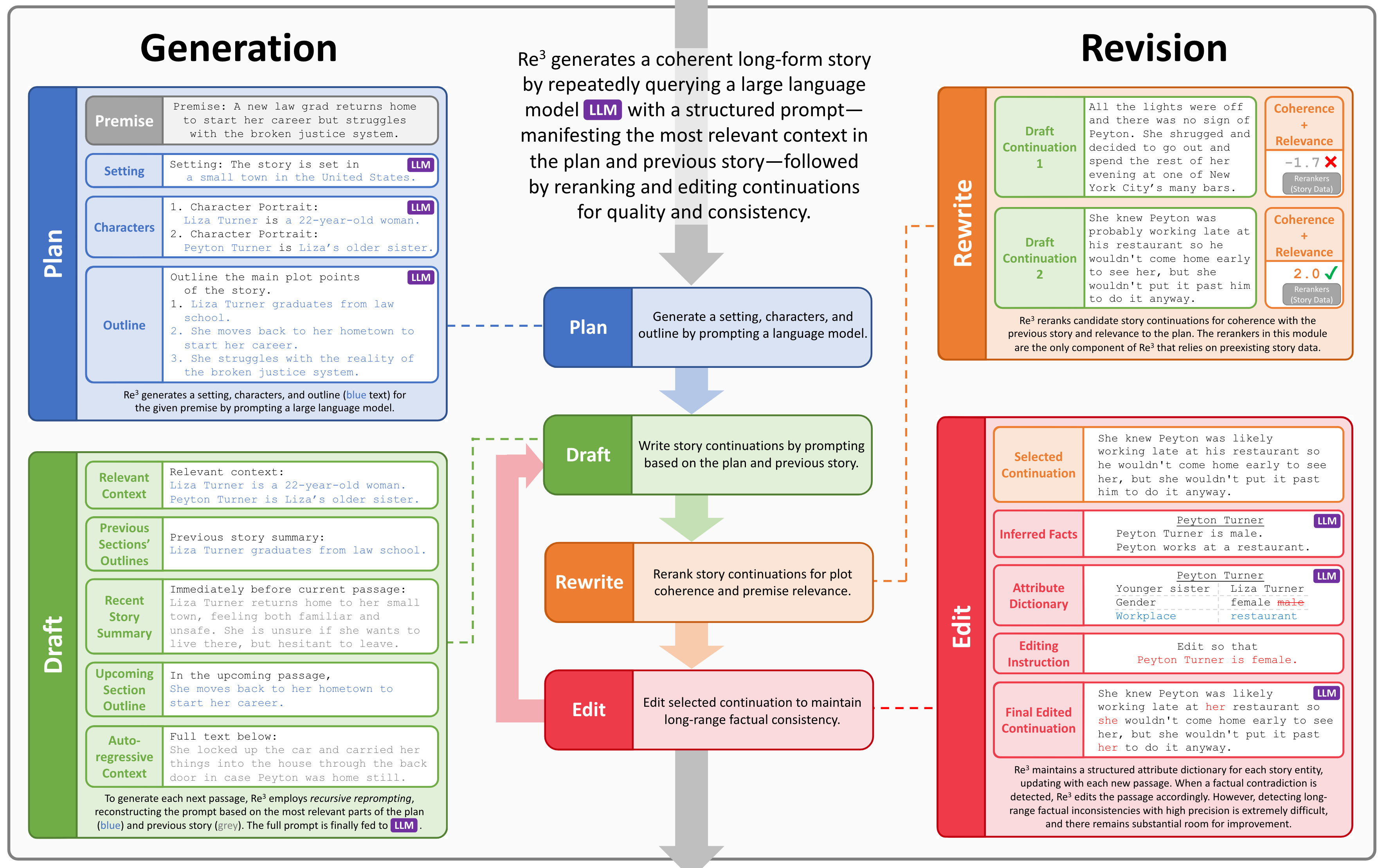
현재 생성 모델은 짤막한 문장이나 이야기는 잘 만들어냅니다. 하지만 그보다 훨씬 긴 이야기를 만들다보면 이야기의 앞쪽과 뒤쪽이 서로 맞지 않는 현상이 발생합니다. 본 논문은 이를 해결하기 위한 Re3 프레임워크를 제안합니다. 이 프레임워크를 통해 저자들은 생성 모델이 만들어낸 이야기의 일관성과 설정과의 연관성을 크게(14% ~ 20%) 개선하였습니다.
- Plan: 이야기를 만들 때부터 해당 이야기에 등장하는 인물이나 설정에 관한 프롬프트를 상세하게 설계합니다.
- Draft: 위의 프롬프트를 같이 넣어주면서 이야기를 순차적으로 만들어냅니다.
- Rewrite: 만들어낸 이야기 후보들이 원래 주어진 설정과 얼마나 부합하는지 확인하여 점수를 메깁니다.
- Edit: 가장 좋은 후보군을 설정과 부합하도록 수정한 뒤에 이전 이야기에 덧붙입니다.
Fine-tuned Language Models are Continual Learner
작성자: 이봉석
본 논문은 Instruction Tuning 패러다임으로 파인튜닝된 LLM의 Continual Learning에 관해 탐구하고, 이전에 학습한 태스크에 대한 Catastrophic Forgetting을 피하면서 다양한 태스크에 적응하는 능력을 조사했습니다. 실험 결과, 새로운 태스크를 학습할 때 1%의 Rehearsal만으로도 이전에 배운 태스크에서 충분히 높은 성능을 유지할 수 있다는 것을 발견했습니다. 그리고 이런 적응하는 능력과 지속적인 학습 능력은 모델의 Multi-task Nature, Instruction Tuning 패러다임, 스케일 때문이 아니라 사전 학습에서 나오는 것으로 분석합니다.
The “Problem” of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation
작성자: 김수정
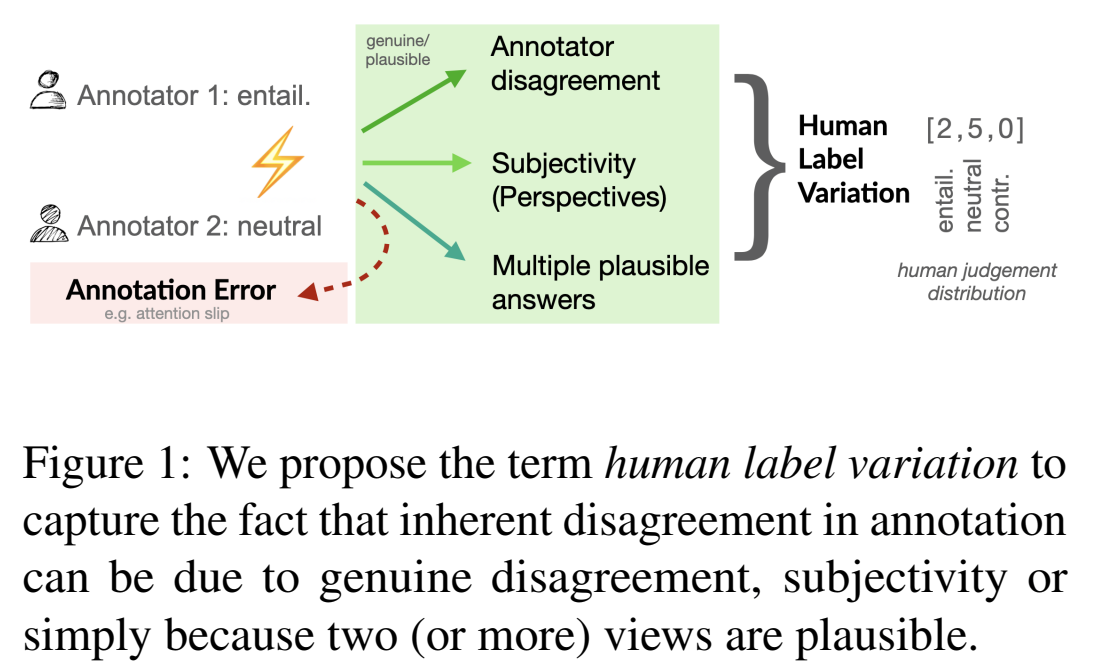
Human Label Variation (HLV)은 보통 노이즈로 인식됩니다. 하지만 주관적이거나 복수 정답이 가능한 어려운 태스크에서는 실재로 Ground Truth가 존재하지 않을 수 있고 오히려 HLV가 올바른 신호일 수 있습니다. 이런 태스크에서는 데이터, 모델링, 평가 등 전반적인 ML 파이프라인에서 HLV를 적절히 고려하는 것이 효과적입니다. 본 논문에서는 1) 데이터에서 Disagreement와 Variation의 정의, 2) 모델링에서 HLV를 고려하는 방법, 3) 평가에서 HLV를 고려하는 다양한 관련 연구를 제안합니다.
PromptBERT: Improving BERT Sentence Embeddings with Prompts
작성자: 서상우
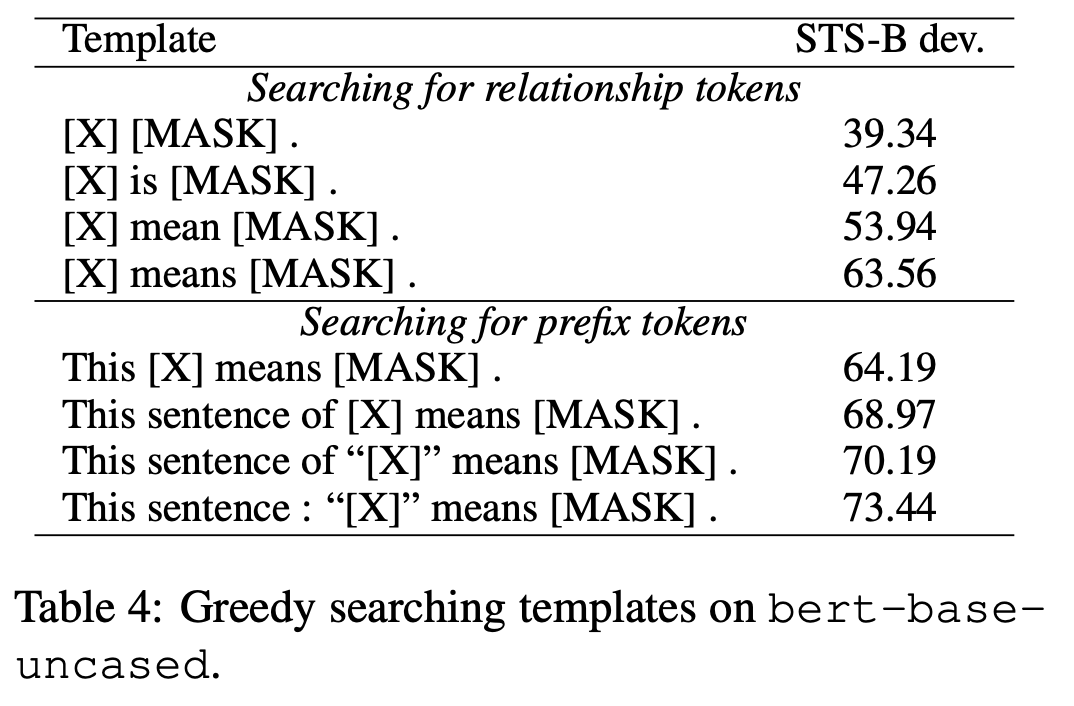
Sentence Representation을 더 잘 구성하기 위해 기존의 Contrastive Learning에 Prompt-based Sentence Embedding 방법을 더합니다.
저자들은 BERT가 Semantic Similarity 태스크에서 만족스러운 성능을 보여주지 못하는 이유가 기존에 알려진 Anisotropy뿐만 아니라 Embedding Bias의 문제임을 증명합니다.
또한 이를 해결하기 위해 Prompt-based Sentence Embedding을 제안합니다.
이는 Table 4처럼 [X]에 문장을 주고서 prompt를 구성한 뒤에 [MASK]에 해당하는 부분을 Sentence Representation을 사용하는 방식입니다.
이렇게 얻은 Prompt-based Sentence Embedding을 직접적으로 활용하거나 Contrastive Learning의 Positive Instance로 사용하면 Unsupervised 및 Fine-tuned Setting에서 SimCSE를 넘는 성능을 보입니다.
Towards Tracing Factual Knowledge in Language Models Back to the Training Data
작성자: 송제인
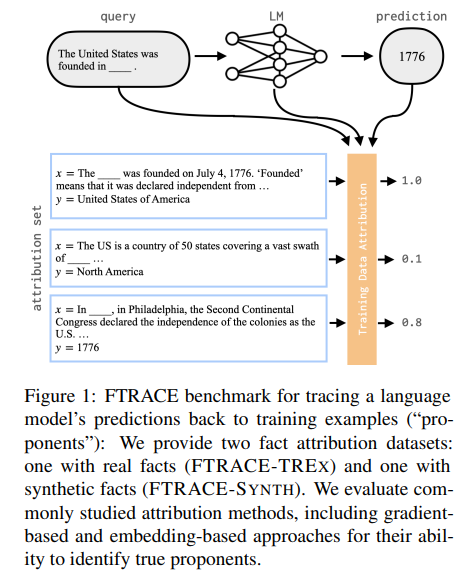
본 연구에선 LM이 특정 사실을 학습하고 생성하도록 영향을 끼친 Training Example를 규명하는 Fact Tracing 문제를 제안합니다. 나아가, Fact Tracing과 밀접하게 관련된 Training Data Attribution (TDA) 기법을 정량적으로 평가하기 위한 두 가지(FTRACE-TREx, FTRACE-SYNTH) Benchmark 데이터셋 및 평가 방법을 제안합니다. 이를 이용해 TDA 연구에서 제안되는 대표적인 두 가지 기법(Gradient-based, Embedding-based)을 BM25 베이스라인과 함게 비교 및 평가하였습니다. 그 결과 TDA에 유리한 실험 환경에서도 Information Retrieval의 전통적인 기법인 BM25가 기존 TDA 기법들보다 더 나음을 보였고, Ablation Study를 통해 기존 TDA 기법들의 문제점을 분석하며 아직 개선 여지가 많음을 보였습니다.
Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
작성자: 정다운
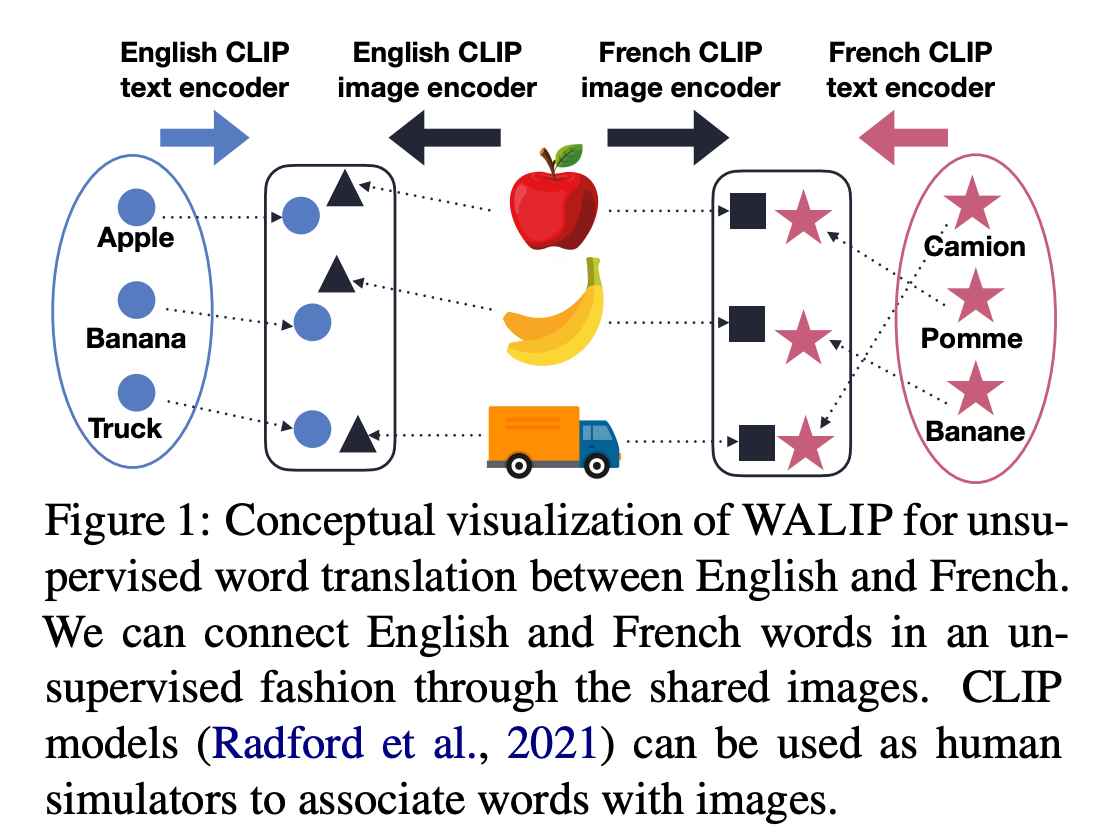
본 논문은 시각 정보를 활용하여 CLIP 모델의 Shared Image-Text Embedding Space를 활용한 새로운 Unsupervised Word Translation 기법(WALIP)을 제안합니다. 다양한 이미지와 단어의 유사도를 해당 단어의 Word Representation으로 활용하고, 이를 이용하여 초기 단어 페어셋을 구축합니다. 그 후, 시각 정보로는 묘사하기 어려운 Abstract Nouns 등의 페어를 구축하기 위해 초기 단어 페어셋을 이용하여 선형 매핑을 학습합니다. 실험 결과 논문에서 제안한 WALIP은 다양한 언어 쌍에 대해 SOTA Alignment 성능을 기록하였고, 특히 크게 다른 언어 쌍에 대해 더 강건한 성능을 보여주었습니다.
Iteratively Prompt Pre-trained Language Models for Chain of Thought
작성자: 이재훈
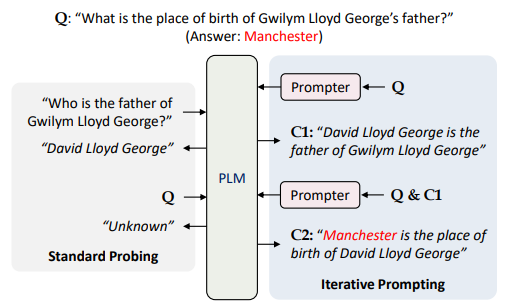
질문에 대답을 하기 위해서는 연속적인 사고를 통해 정답을 도출해야 하는 상황이 존재하며 이를 Chain-of-thought라고 합니다. 본 논문에서는 Chain-of-thought 문제를 풀기 위해 Soft Prompt 방식의 연구를 수행하였습니다. 실험에서는 Prompt로 RoBERTa-Base를 사용하였고 최종 결과를 추론할 때까지 연속적으로 추론하도록 하였습니다. 그 결과 다단계 추론이 필요한 WikiMultiHopQA, R4C, LoT와 같은 데이터셋에서 좋은 성능을 내는 것을 확인하였습니다. 하지만 추론이 계속될 때마다 Input Sequence가 길어지는 점과 Computational Cost 때문에 BART-Large 모델로만 실험을 한 점이 해당 논문의 한계입니다.
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
작성자: 고유미
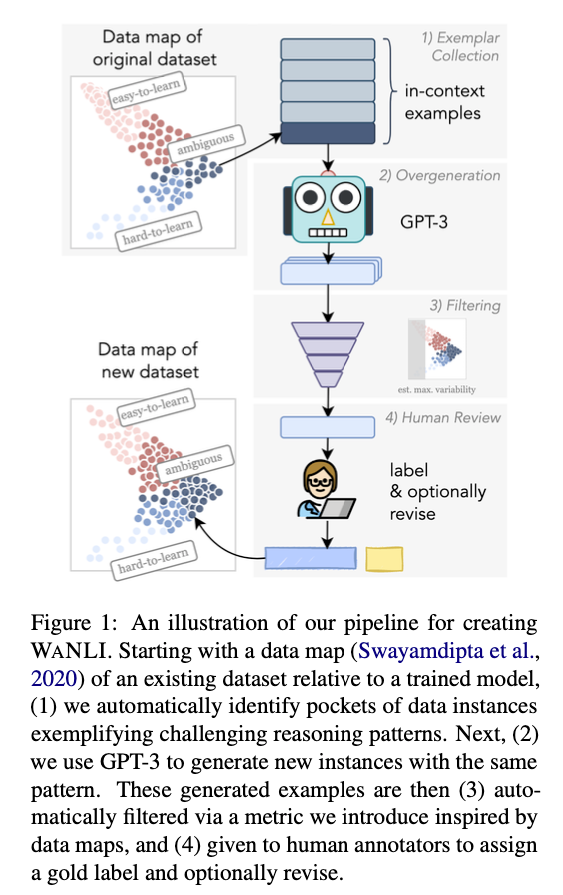
크라우드소싱으로 대규모의 NLP 데이터셋을 만드는 데에는 여러 문제가 있고, 이를 보완 또는 해결하기 위한 방법으로 AI와 협업하는 방식이 제안되고 있습니다. 핑퐁팀에서도 효율적인 데이터셋을 만들기 위해 AI를 활용하는 방안을 다양한 측면에서 고민하는데요. 저자는 데이터를 작성하는 레이블러가 반복적인 패턴에 의존하기 때문에 데이터의 다양성이 부족한 것이 문제라고 생각했습니다. 데이터맵(Swayamdipta et al., 2020)을 사용하여 모호한(어려운) 패턴을 자동으로 식별하고 GPT-3가 유사한 패턴으로 과다생성하도록 한 뒤, 필터링을 거쳐 다시 모호한 예시만 남도록 합니다. 마지막으로 사람이 수정하고 레이블링합니다. 이렇게 완성된 WANLI 데이터셋은 4배 더 큰 MultiNLI에 비해서 성능이 더 좋다는 것을 보여줍니다. 데이터셋의 양보다 질이 더 중요하다는 것을 보여주는 좋은 예이기도 합니다.