과연 GPT-3는 얼마나 똑똑한 걸까?
여러 분야의 문제를 통해 GPT-3의 '지능'을 평가하는 방법에 대해서 알아봅니다.
 김종윤
| 2020년 10월 20일 |
#Machine_Learning
김종윤
| 2020년 10월 20일 |
#Machine_Learning
GPT-3, 그 이후
GPT-3가 공개된 지 5개월이 지났습니다. 놀라운 성능만큼 유명세도 대단했죠. 스캐터랩 기술 블로그에 올린 GPT-3 소개글은 스캐터랩 기술 블로그 역사상 가장 많이 읽힌 글이 되었고, 이후에 올린 GPT-3의 한계에 대한 글도 많은 분이 읽어주셨습니다.
아직은 머신러닝이 대중적인 분야가 아님에도 불구하고 주류 언론까지 나서 GPT-3를 앞다퉈 다룰 정도였죠. 수많은 언론에서 GPT-3의 막강한 성능을 (양념과 자극적 요소를 얹어) 소개했습니다. 이로써 GPT-3는 역사상 가장 뛰어난 언어 AI가 되었을 뿐 아니라, 역사상 가장 유명한 언어 AI가 되었죠.
이런 현상은 GPT-3가 타 모델과 차원이 다른 언어 생성 성능을 보여주었기 때문입니다. 그런데요, 과연 GPT-3는 정확히 얼마나 똑똑한 걸까요?
AI의 능력 테스트
벤치마크(benchmark)라는 용어가 있습니다. 어떤 대상의 성능을 측정할 때 기준이 되는 테스트이자 지표이죠. 당연히 언어 AI에도 벤치마크가 있습니다. GLUE와 SuperGLUE가 바로 그것입니다.
GLUE는 2018년에 뉴욕대, 워싱턴대, 딥마인드의 NLP 연구자들이 함께 만든 언어 벤치마크입니다. 언어 능력을 측정하는 9가지 테스트셋을 포함하고 있습니다. 예를 들어, 해당 문장이 문법적으로 맞는지 판단하는 CoLA, 두 문장의 의미가 유사한지 판단하는 STS-B, 두 문장의 논리적 상관관계를 판단하는 MNLI 같은 것이죠.
문제는 불과 1년 만에 언어 모델의 성능이 인간 수준을 넘어버렸다는 겁니다.

그래서 이들은 다시 모여 2019년에 SuperGLUE라는 벤치마크를 만듭니다. 이 벤치마크는 유사한 컨셉의 8가지 과제를 포함하는데요, 가장 큰 차이는 앞에 “Super”라는 단어가 붙은 것에서 알 수 있듯이 GLUE보다 더 어렵다는 것이었습니다.
그러나…
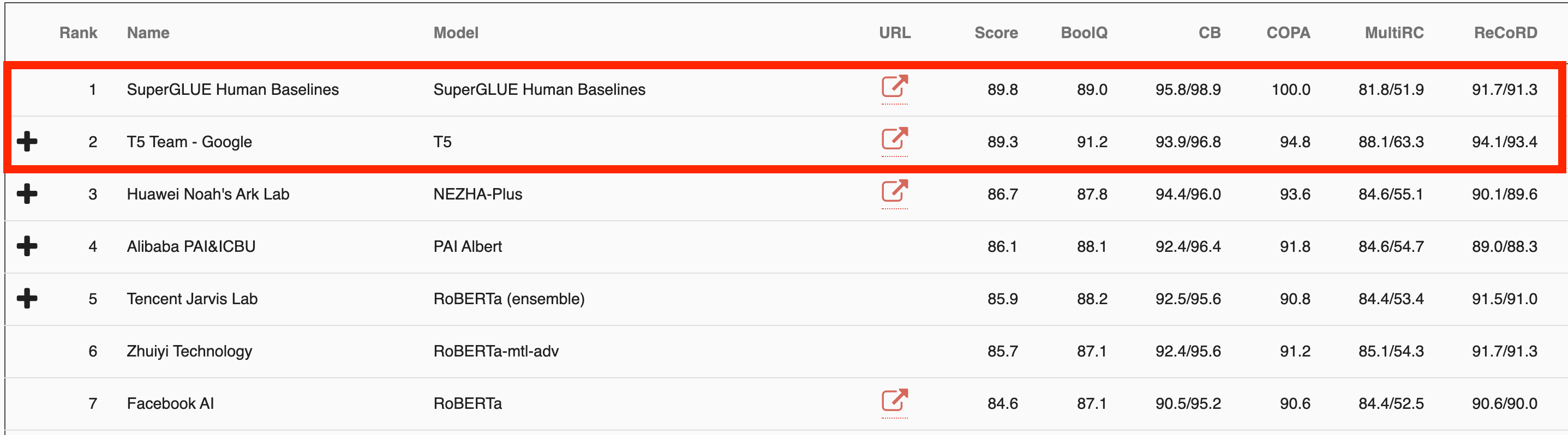
SuperGLUE 또한 불과 1년 만에 인간 수준에 0.6점 차이로 근접해 버렸습니다. 수년간 힘들게 개발한 게임이 불과 6시간 만에 클리어되는 광경을 목도한 디아블로3 개발자들이 이런 심정이었을까요?
더 큰 문제는 GLUE나 SuperGLUE 같은 벤치마크에서 머신러닝 모델이 인간 수준에 근접하거나 넘어섰음에도 불구하고, 종합적으로 봤을 때 언어 능력이 인간 수준에 근접한 건 전혀 아니라는 점입니다. 현재 사용되는 벤치마크가 정말 AI의 능력을 제대로 측정하는 것인지 의문이 생길 수밖에 없죠.
GPT-3를 위한 벤치마크
이에 여러 NLP 연구자들이 모여 새로운 벤치마크를 제안합니다. 벤치마크를 제안한 논문의 제목은 Measuring Massive Multitask Language Understanding입니다. 아이디어는 간단합니다. 어떤 언어 AI가 얼마나 똑똑한지 알아보려면, 그냥 엄청나게 다양한 분야의 다양한 문제를 내보면 되는 거 아니냐는 거죠.
예를 들면 이런 겁니다:
분야: 고등학교 수학
만약 4 daps = 7 yaps이고, 5 yaps = 3 baps라면, 42 baps는 몇 daps인가?
- 28
- 21
- 40
- 30
(직접 한번 풀어보세요. 정답은 글의 맨 마지막에 있습니다.)
이 문제를 넣으면 언어 모델은 아마 A, B, C, D 중 하나의 답을 생성해 낼 것입니다. 그리고 그게 정답인지 확인하면 되는 거죠. 참 쉽죠? 다른 예시 문제를 몇 개 더 볼까요?
분야: 법학
한 백과사전 세일즈맨이 한 은둔자의 집에 도착했다. 그곳에는 “세일즈맨 거부. 어기는 사람은 처벌받음. 위험은 당신 책임.”이라는 표지판이 있었다. 세일즈맨은 초대받은 사람은 아니었지만, 표지판을 무시하고 차를 몰고 집 쪽으로 들어갔다. 그가 코너를 도는 순간, 땅에 묻혀있던 폭발물이 터졌고, 세일즈맨은 다쳤다. 이 상황에서 세일즈맨이 그 은둔자에게 부상에 대한 보상을 요구할 수 있을까?
- 있다. 단, 은둔자가 폭발물을 설치했을 때 단순히 침입을 막는 걸 넘어서 해하려는 의도가 있어야 한다.
- 있다. 단, 은둔자가 그 폭발물을 설치했어야 한다.
- 없다. 왜냐하면 세일즈맨이 경고를 명시한 표지판을 무시했기 때문이다.
- 없다. 은둔자는 침입자가 자기 자신이나 가족을 해할 수도 있다는 합리적인 두려움을 갖고 있었기 때문이다.
분야: 물리학
공을 손에 쥐고 가만히 떨어트리면 공은 \(9.8 m/s^2\)의 가속도로 떨어진다. 공기 저항이 없다고 가정한 상태에서 아래쪽으로 공을 힘있게 던진다면, 손을 떠난 공의 가속도는?
- $9.8 m/s^2$
- \(9.8 m/s^2\) 초과
- \(9.8 m/s^2\) 미만
- 던진 속도를 알려주지 않으면 알 수 없음
분야: 대학 수학
복소평면(complex z-plane)에서 \(z^2={\|z\|}^2\)을 만족하는 점들이 이루는 도형은?
- 두 점
- 원
- 반직선
- 직선
분야: 의학
33세 남성이 갑상선암에 걸려 급성 갑상선 전절제술을 수행했다. 수술하는 동안 중등도의 출혈이 경부 좌측 부분의 몇몇 혈관에 나타나 봉합이 필요하게 되었다. 수술 후 혈장검사 수치로 칼슘 수치는 7.5 mg/dl, 알부민 수치는 4 g/dl, 부갑상선호르몬 수치(PTH)는 200 mg/ml였다. 다음 중 어느 혈관의 손상이 이 환자의 검사결과와 상관있는가?
- 목갈비동맥의 가지
- 바깥목동맥의 가지
- 갑상목동맥의 가지
- 속목정맥의 지류
대충 이런 식입니다. 느낌 아시겠죠?
저자들은 의학부터 수학, 화학, 외교, 경제학, 철학 등등까지 무려 57개의 분야에서 15,908개의 문제를 준비했습니다. 이 중 14,080개의 문제가 테스트로 사용되었죠. 과연 GPT-3의 정답률은 얼마였을까요?
GPT-3의 성능은?
테스트 대상이 된 모델의 정답률은 다음과 같았습니다. (사지선다형의 문제이므로 25% 가 랜덤 확률임을 유념하고 봐주시기 바랍니다)
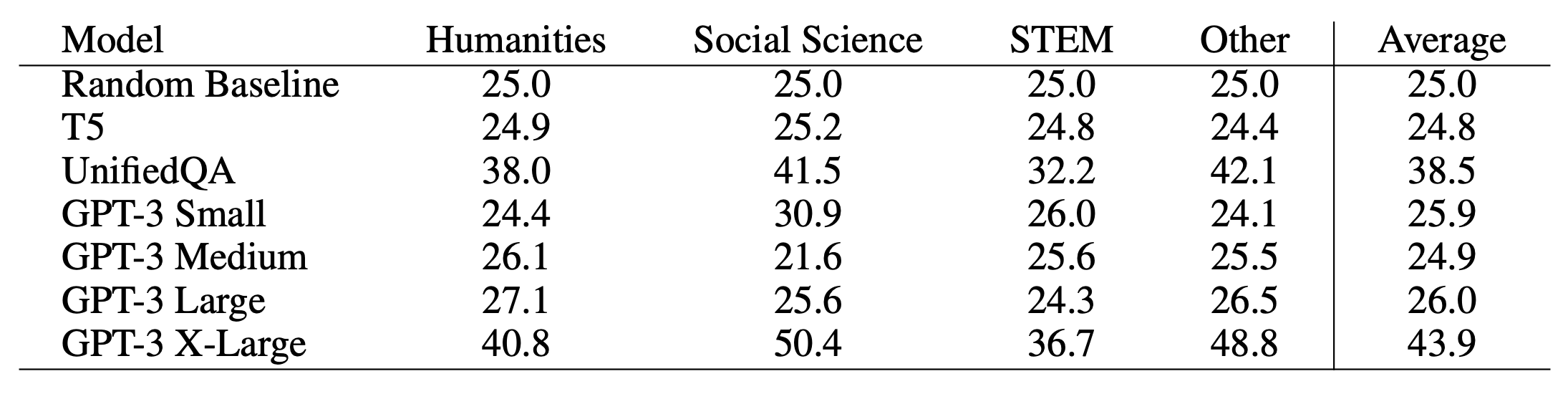
네. 가장 큰 GPT-3 모델의 정답률은 43.9%였습니다.
분야별 정답률은 다음과 같았습니다.
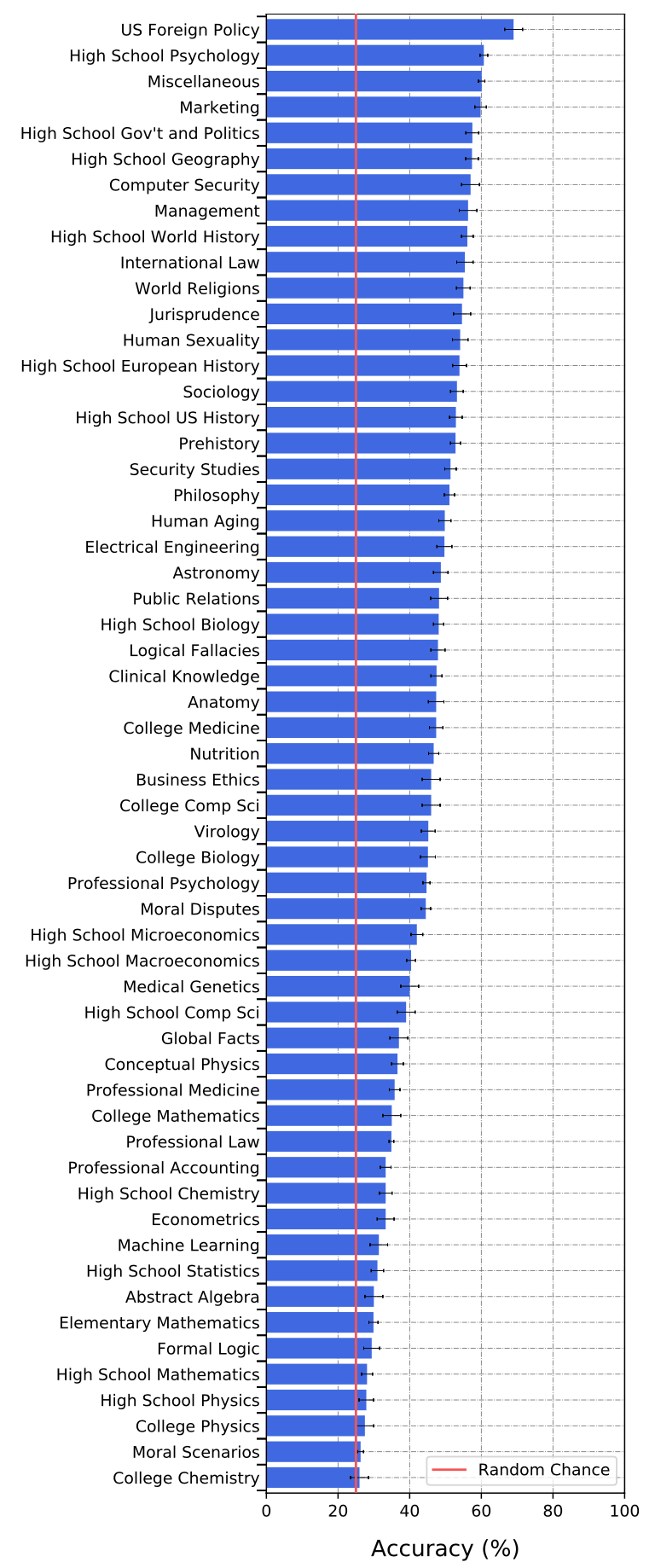
이 결과는 무엇을 말해주는 걸까요?
테스트의 교훈
1. GPT-3는 (당연히) 완벽하지 않다
테스트 결과를 보시면 아시겠지만, GPT-3는 이 벤치마크에서 44점을 기록했습니다. 모두 무작위로 찍었을 때 받는 점수인 25점보다는 훨씬 높은 점수이고 절대 만만치 않은 문제임을 고려할 때 꽤 인상적인 점수이기는 하지만, 동시에 엄청나게 높은 점수는 아닙니다.
이 벤치마크에 대한 인간의 점수가 몇 점인지는 알 수 없습니다. 아마 사람마다 편차가 크겠죠. 하지만 각 분야의 전문가들이 문제를 푼다면 아마 90점 이상은 기록할 것입니다. GPT-3는 아직 그에 한참 못 미치는 수준입니다.
2. GPT-3는 공학/자연과학 분야에 약하다
위의 분야별 테스트 결과를 보면 알겠지만, GPT-3는 상대적으로 인문/사회과학 분야에서 높은 점수를 기록한 반면 공학/자연과학 분야에서는 약한 모습을 보입니다. 이런 현상에는 여러 이유가 있을 것 같아요. GPT-3 학습에 사용된 데이터가 인문/사회과학적인 데이터에 쏠려있어서 그럴 수도 있고, 객관식 테스트의 특성상 인문/사회과학 분야는 암기식 테스트가 많고 공학/자연과학 분야는 추론 능력을 확인하는 테스트가 많아서 그럴 수도 있어요. 현재의 GPT-3는 사고력보다는 지식의 양에서 강점이 있다고 볼 수 있습니다.
3. 그래도 GPT-3는 놀랍다
GPT-3 소개글에서도 말했듯이, GPT-3는 대량의 텍스트 데이터를 대상으로 다음 단어 예측 문제를 수행한 모델입니다. 그런데 어떻게 이 벤치마크에서 랜덤 이상의 점수를 기록할 정도의 지식과 사고력을 갖게 된 걸까요? 저는 점수를 떠나서 GPT-3가 랜덤이 아닌 점수를 기록했다는 사실 자체가 놀랍습니다.
그리고 따지고 보면 평범한 한 명의 성인이 57개 분야의 문제를 모두 푼다고 했을 때, 전체 평균 점수가 50점을 넘기가 쉽지 않을 것 같습니다. 이 벤치마크에서 GPT-3는 평범한 인간 수준에는 근접했다고도 볼 수 있는 셈이죠. 주목해야 하는 건 현재 수준이 아니라 AI가 발전하는 속도와 방향입니다.
4. 모델 크기가 중요하다
보통 GPT-3를 하나의 모델로 이야기를 하지만, 사실 GPT-3는 여러 종류가 있습니다. 일반적으로 우리가 GPT-3라고 부르는 모델은 가장 큰 모델(1,750억 개의 파라미터)을 말합니다. 하지만 GPT-3도 같은 데이터를 같은 방식으로 학습시킨 여러 사이즈의 모델이 있습니다.
논문에서는 더 작은 사이즈의 GPT-3 모델로도 테스트를 해봤습니다. Small(27억 개 - 27억 개가 스몰 사이즈라니…), Medium(67억 개), Large(130억 개)짜리 모델이었는데요, 신기하게도 130억짜리 GPT-3를 포함한 모든 나머지 모델에서는 정답률이 25%밖에 나오지 않았습니다. 즉, 랜덤한 수준을 벗어나지 못했다는 의미죠. 모든 GPT-3가 같은 데이터, 같은 방식으로 학습을 했다는 걸 생각해보면, 모델 크기가 커지면서 갑자기 어떤 능력을 갖추게 된 것으로 보입니다. 모델 크기의 중요성을 보여주는 결과입니다.
5. 특화된 모델은 효율이 높다
논문에서는 UnifiedQA (Khashabi et al., 2020)라고 불리는 모델도 함께 테스트했습니다. 광범위한 유형의 텍스트를 학습한 GPT-3와 달리 UnifiedQA는 다양한 분야의 질의-응답 데이터를 중심으로 학습한 모델로서, GPT-3 Small과 비슷한 30억 파라미터 정도의 크기입니다.
하지만 UnifiedQA의 벤치마크 성능은 39점이었습니다. GPT-3의 44점보다 낮긴 하지만 크게 차이가 나는 건 아니죠. 게다가 UnifiedQA의 모델 크기는 GPT-3의 약 1/60에 불과합니다. 그만큼 범용성을 버리고 특정 문제에 특화된 학습을 하면 GPT-3보다 60배나 효율이 높은 모델을 학습시킬 수 있다는 의미입니다. Fine-tuning의 중요성을 보여주는 결과입니다.
6. AI의 벤치마크와 인간의 벤치마크가 같아지다
위의 문제 예시를 보면 알겠지만, 사실 이 벤치마크는 인간의 능력을 측정할 때 사용해도 좋은 테스트입니다. 만약 누군가가 인간의 종합적인 지식과 사고력을 측정하는 벤치마크를 만든다면 이런 문제들로 구성할 것 같아요.
지금까지의 모든 벤치마크는 “인간에게는 매우 쉬운데, AI에게는 어려운” 문제들로 구성되어 있었습니다. 처음에 소개한 GLUE나 SuperGLUE도 마찬가지죠. 이러한 벤치마크는 AI의 성능을 확인하는 데는 유용할지 몰라도 인간의 능력을 측정하기는 어려웠습니다. 인간이라면 누구나 쉽게 풀 수 있는 문제니까요.
하지만 이 벤치마크는 인간에게도 어렵고 AI에게도 어려운 벤치마크입니다. 최근 몇 년간 언어 AI가 빠르게 발전한 결과, 이제 AI의 성능을 측정하는 벤치마크와 인간의 성능(?)을 측정하는 벤치마크가 같아진 거죠.
재밌는 현상이고, 흥미로운 시대입니다. 어쩌면 이 벤치마크의 가장 큰 의의는 이런 유형의 벤치마크가 나왔다는 사실 자체일지도 모릅니다. 과연 이 벤치마크는 언제 정복이 될까요?
P.S.
- 고등학교 수학 문제의 답은 (C)입니다.
- 법학 문제의 답은 (B)입니다.
- 물리학 문제의 답은 (A)입니다.
- 대학 수학 문제의 답은 (D)입니다.
- 의학 문제의 답은 (C)입니다.