Custom Metric(ex. RPS)으로 HPA 설정하기
쿠버네티스 환경에서 Custom Metric으로 오토스케일링 하는 과정을 설명합니다

쿠버네티스에서 기본으로 제공하는 HPA를 이용하면 pod의 CPU 사용량에 따라 자동으로 스케일 아웃되는 시스템을 쉽게 구축할 수 있습니다. 하지만 서비스의 성격에 따라 CPU 사용량 대신 다른 지표를 이용해 오토스케일링하는 것이 더 적합할 수도 있습니다. 이번 글에서는 custom metric을 정의하고 이를 이용해 HPA가 오토스케일링하도록 설정하는 방법을 공유하겠습니다.
목차
쿠버네티스 오토스케일링
쿠버네티스에서는 다음과 같은 오토스케일러를 사용할 수 있습니다.
- Cluster Autoscaler : 스케줄된 pod을 실행하기 위해 필요한 리소스(CPU, 메모리 등)에 따라 node를 오토스케일링합니다. 핑퐁팀은 CA의 대체제인 Karpenter를 사용하고 있습니다.
- HPA(Horizontal Pod Autoscaler) : 트래픽에 따라 pod의 레플리카 개수를 조절합니다. 각각의 pod이 요구하는 리소스는 동일합니다.
- VPA(Vertical Pod Autoscaler) : 트래픽에 따라 개별 pod의 resource request, limit을 조절합니다.
일반적으로 stateless 서버는 HPA를 사용하는 것이 적합합니다. VPA는 리소스를 변경하는 과정에서 pod의 재시작이 불가피하고, 하나의 node가 가질 수 있는 리소스(CPU, 메모리)에는 한계가 있기 때문입니다. 핑퐁팀에서 운영하는 대부분의 서버 또한 VPA 대신 HPA를 사용하고 있습니다.
HPA의 작동 방식
1. 일정 주기마다 Metric을 가져온다
일정 주기마다 HPA에 정의되어 있는 metric을 metric API를 통해 수집합니다. Metric의 종류는 아래와 같으며 종류에 따라 API도 분리됩니다.
- Resource Metric : CPU, 메모리 사용량 등 pod, node에 미리 정의되어 있는 metric을 의미합니다.
- Custom Metric : 유저가 정의한 metric을 의미하며 절댓값을 이용한 Resource Metric과 유사하게 작동합니다.
- External Metric : 쿠버네티스와 관련 없는 단일 metric이며, 비교가 이루어지기 전에 Pod 개수로 값을 나눌지 여부를 선택할 수 있습니다.
2. 현재 Metric 값, 현재 pod 개수를 바탕으로 원하는 pod 개수를 계산한다
원하는 pod 개수는 아래 수식으로 계산됩니다. 올림을 하게 되면서 스케일링 이후에 현재 metric ≤ 원하는 metric 을 유지하게 됩니다. 더 자세한 내용은 공식 문서에서 확인 가능합니다.
원하는 pod 개수 = ceil[현재 pod 개수 * ( 현재 metric / 원하는 metric )]
3. scale 요청을 보낸다
쿠버네티스 HPA 컨트롤러는 2에서 계산한 값으로 deployment 혹은 statefulset의 pod 개수를 수정하는 요청을 보냅니다.
Metric API Server
HPA에서 Metric API를 통해 값을 수집한다고 했는데, Metric API는 쿠버네티스에서 기본적으로 제공되는 API가 아닙니다. 그래서 HPA를 쓰려면 원하는 Metric API가 작동할 수 있도록 따로 Metric API Server를 설치해야 합니다.
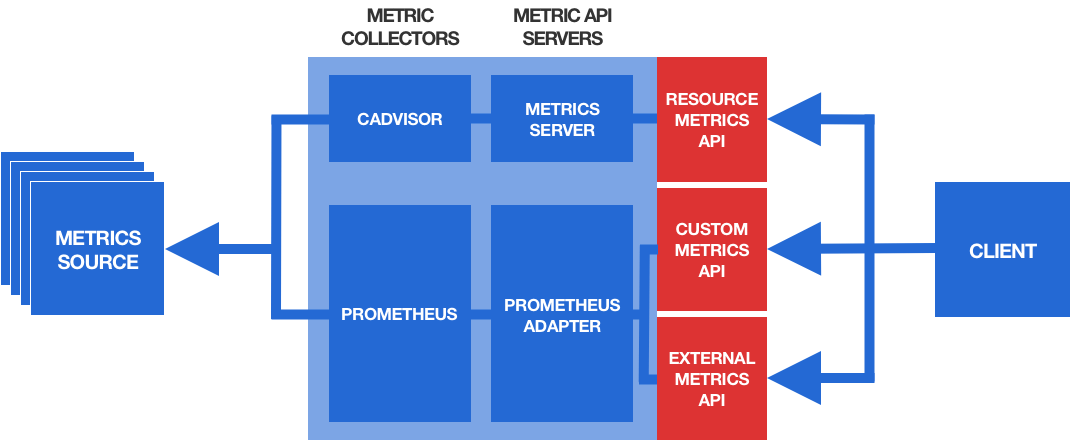
Metric 수집은 위 그림처럼 pipeline이 구성되어 있습니다.
- Metric Source : CPU, memory, GPU, 요청 수와 같은 Metric을 제공하는 주체이며 일반적으로는 pod, node에서 제공합니다.
- Metric Collector : Metric Source로 부터 Metric을 수집하는 주체입니다. HPA와 관계 없이 모니터링의 목적으로 사용됩니다.
- Metric API Server : Metric Collector의 데이터를 HPA에서 사용할 수 있게 쿠버네티스 API로 노출하는 역할을 합니다.
Resource Metric API Server
Resource Metric의 경우에는 Metric Collector가 기본으로 설치되어 있습니다. 쿠버네티스의 모든 Node에는 kubelet이 설치되어 있고, kubelet에는 cAdvisor가 포함되어 있습니다. cAdvisor가 Metric Collector의 역할을 하며 Pod, Node의 cpu, memory 사용량을 수집하고 kubelet이 이를 노출합니다.
cAdvisor가 쿠버네티스에 기본으로 있기 때문에, Metric API Server의 역할을 할 Metric Server만 설치하면 쉽게 resource metric을 HPA에 제공할 수 있게 됩니다.
설치는 아래와 같이 kubectl apply 명령어로 쉽게 할 수 있고 잘 설치되었는지는 kubectl top 명령어로 확인해 볼 수 있습니다.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
$ kubectl top pod -n <namespace>
NAME CPU(cores) MEMORY(bytes)
XXX-deployment-aaaaaaaa-aaaaa 5m 4203Mi
XXX-deployment-bbbbbbbb-bbbbb 4m 120Mi
Custom Metric API Server
하지만 CPU와 memory가 아닌 다른 지표로 서버의 부하를 측정해야 하는 경우도 있습니다. 이런 경우를 위해 쿠버네티스에서는 custom metric을 통해 HPA를 사용하는 방식도 제공합니다. Resource Metric 과는 달리 cAdvisor가 제공하지 않는 metric을 사용하므로 prometheus와 같은 metric collector도 필요합니다.
핑퐁팀은 RPS(request-per-second)를 기준으로 오토스케일링하는 HPA를 만들기 위해서 prometheus adapter라는 별도의 custom metric API server를 설치했습니다. 구체적인 설치 과정은 다음 챕터에서 설명하겠습니다.
External Metric API Server
External metric API는 custom metric API와 구조가 크게 다르지 않고, 앞서 custom metric API server로 사용한 prometheus-adapter가 external metric 또한 지원하고 있습니다. prometheus-adapter externalRule에 대한 자세한 설명은 공식 문서에서 참고할 수 있고 HPA 설정은 공식 문서에서 참고할 수 있습니다.
RPS로 오토스케일링하기
핑퐁팀은 istio, prometheus(prometheus operator)를 이용해 RPS(request-per-second) 기준으로 오토스케일링하는 HPA를 설정했습니다. RPS를 기준으로 설정한 이유는 I/O 작업이 많아 CPU, memory뿐만 아니라 스레드 개수, network bandwidth와 같은 병목 요소들도 많아서 이를 종합적으로 보고 싶기도 했고, 서버로 들어오는 대부분의 요청이 유저 발화에 답변하는 API 1개이기 때문에 RPS를 유의미한 지표로 삼을 수 있다고 생각했습니다.
물론 custom metric이 반드시 RPS일 필요는 없기에 팀의 상황에 맞는 다른 Metric으로 HPA를 설정해도 되고, prometheus를 사용하지 않고 new relic, datadog 등을 사용하더라도 적절한 Metric API Server를 설치해준다면 적용할 수 있습니다.
RPS 측정
우선 첫번째로 metric이 될 RPS 값이 측정되어야 합니다. 각 서버마다 받은 요청수를 알려주는 API를 프로메테우스에게 노출시키는 방법도 있지만, 이 경우 Spring의 spring-boot-actuator나 python의 starlatte_prometheus 등 서버 프레임워크에 맞는 라이브러리를 연동하는 절차가 추가로 필요합니다. 그런 불편함을 줄이기 위해 istio metric을 사용했습니다. 쿠버네티스 클러스터에 prometheus와 istio가 잘 설치되어 있다면 istio_request_total metric을 통해 서버 간 요청 횟수를 계산할 수 있습니다.
RPS를 측정하고자 하는 서버에 대해 아래와 같이 PrometheusRule을 설정하고 배포하면 RPS 메트릭이 test_requests_per_second 라는 이름의 메트릭으로 수집이 됩니다.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: test-prometheus-rule
namespace: test
spec:
groups:
- name: requests-per-second
rules:
- record: test_requests_per_second
expr: >-
sum(rate(istio_requests_total{reporter="destination", destination_app="test"}[2m]))
/ sum(kube_deployment_status_replicas_available{deployment="test-deployment"})
labels:
namespace: test
service: test
metric을 계산하는 위의 PromQL(spec.groups[0].rules[0].expr)에 대해 설명해보겠습니다. istio_requests_total{…}은 test 서버에 요청이 들어온 전체 횟수입니다. reporter="destination"을 설정한 이유는 istio에서 해당 metric을 source, destination 양쪽에서 측정하고 있기 때문에 중복을 없애기 위함입니다. 그리고 rate() 함수로 초당 평균 증가값을 구하고, 해당 metric이 다양한 column별로 나눠져 있어 하나의 값으로 쓰기 위해 sum()을 해줍니다. 여기에 실제로 스케일링 할 때는 metric을 pod별 평균 값으로 생각하게 되므로 실제로 ready가 되어있는 pod의 개수로 나눠줍니다.
prometheus-adapter 설치
이렇게 RPS metric이 측정이 됐다면, 쿠버네티스에서 해당 metric을 HPA에서 사용할 수 있게 해줄 Metric API 서버가 필요합니다. prometheus metric을 수집하는 경우에는 prometheus-adapter를 Metric API 서버로 이용하면 됩니다.
핑퐁팀은 prometheus-operator를 helm을 통해 배포하고 있어, values.yaml 파일에 prometheus-adapter 설정을 추가하고 배포하는 방식으로 설치했습니다.
# prometheus-operator helm
# values.yaml
...
prometheus-adapter:
enabled: true
prometheus:
url: http://prometheus-operator-kube-p-prometheus
port: 9090
잘 설치되었는지 확인은 kubectl 명령어로 확인 가능합니다.
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
...
{
"name": "services/test_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
HPA 정의
이제 Metric API 설정도 다 되었으니 HPA만 배포하면 정상적으로 오토스케일링이 됩니다. Resource Metric의 경우에는 spec.metrics[].type 을 “Resource”로, Custom Metric의 경우에는 spec.metrics[].type 을 “Object”로 설정하면 됩니다.
추가로 HPA에서는 CPU, RPS와 같은 metric 기준을 동시에 여러 개 정의할 수 있습니다. 이렇게 설정하면 각 메트릭별로 스케일링하고자 하는 pod 개수 중 가장 큰 값으로 스케일링 됩니다.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: test
name: test-hpa
namespace: test
spec:
maxReplicas: 10
metrics:
- object:
describedObject:
apiVersion: v1
kind: Service
name: test
metric:
name: test_requests_per_second
target:
type: Value
value: 30
type: Object
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test-deployment
마무리
지금까지 쿠버네티스 환경에서 HPA를 통해 Custom Metric으로 오토스케일링 하는 법을 알아보았습니다. CPU, memory, RPS 기준으로만 설명하긴 했지만, 비슷한 방법으로 다른 custom metric 또한 설정할 수 있으니 GPU 사용량, 반응 속도 등 각자 필요한 metric을 사용해 오토스케일링 설정을 해봐도 좋을 것 같습니다.
추가로 HPA는 pod 단위의 스케일링이지만 pod을 실행할 수 있는 Node가 없으면 pod이 스케일링이 제대로 될 수 없기 때문에 관심 있으신 분들은 Node 스케일링에 대해서도 찾아보는 것도 추천드립니다.
참고 자료
- https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
- https://itnext.io/autoscaling-apps-on-kubernetes-with-the-horizontal-pod-autoscaler-798750ab7847