Luda Gen 1, 더 재미있고 자연스러운 대화로 돌아온 루다 1편 - 생성 기반 챗봇
생성 모델 Luda Gen 1을 출시하기까지의 과정을 소개합니다




이번 이루다 2.0 정식 출시에서 답변 생성 모델 Luda Gen 1이 적용되었습니다. 기존 루다는 리트리버가 답변 DB에서 답변을 고르는 방식이었기 때문에 문맥에 딱 맞는 답변이 답변 DB에 없다면 좋은 대화를 이어갈 수 없었습니다. 이런 한계점을 극복하기 위해서 생성 기반 챗봇을 연구하였으며, 그 결과 Luda Gen 1이 서비스에 적용되어 더 재미있고 자연스러운 대화를 이어 나가는 루다가 출시되었습니다.

앞으로 두 편에 걸쳐 생성 기반 챗봇에 대한 연구 내용과 서비스화하는 과정을 공유하고자 합니다. 이번 편에서는 생성 기반 챗봇 방식에 대해 전반적으로 이야기하고 Luda Gen 1이 생성한 답변 예시를 봄으로써 생성 기반 챗봇의 잠재력에 대해 다룰 것입니다.
생성 기반 챗봇 vs 검색 기반 챗봇
딥러닝 기반의 챗봇은 크게 생성 기반 챗봇과 검색 기반 챗봇으로 나눌 수 있습니다. 생성 기반 챗봇은 생성 모델을 이용해서 실시간으로 문맥에 맞는 답변을 생성해내는 방식이고 검색 기반 챗봇은 리트리버가 사전에 구축되어 있는 답변 DB 내의 문장을 고르는 방식입니다. 이러한 방법론의 특성 때문에 생성 기반 챗봇과 검색 기반 챗봇은 고유의 장단점을 갖게 됩니다.
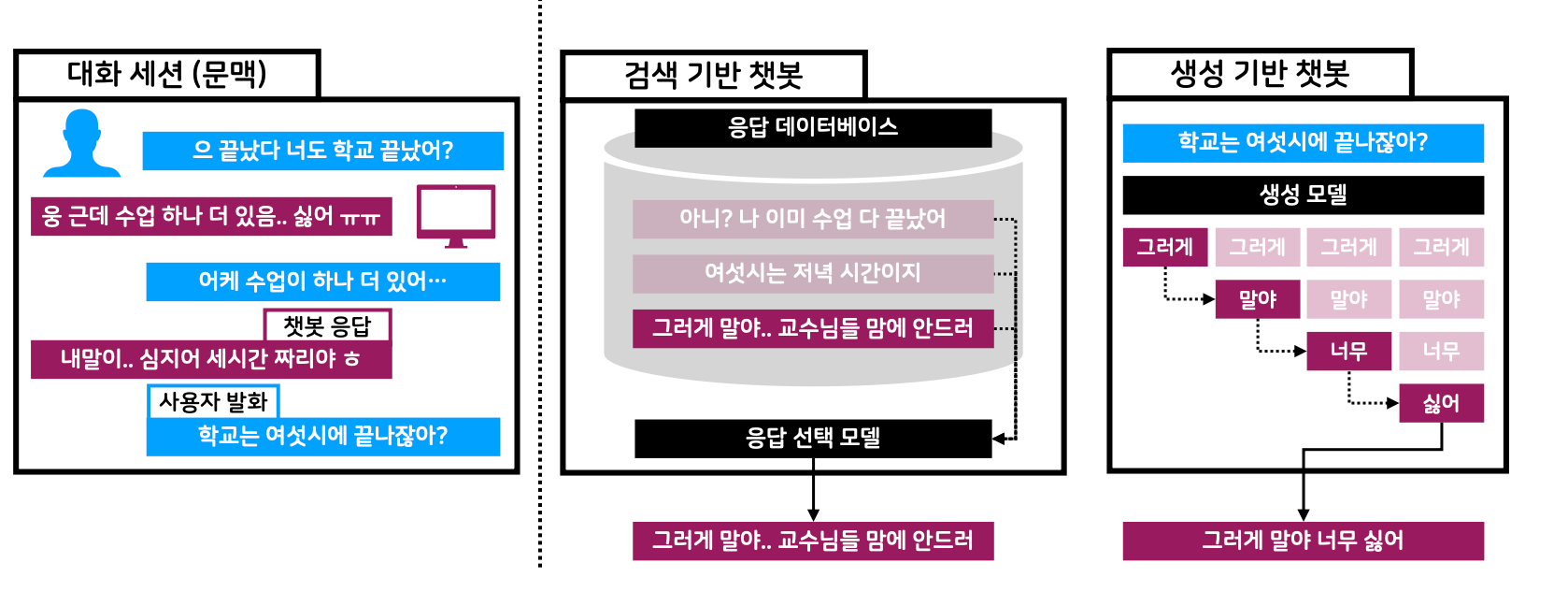
검색 기반 챗봇
이루다 2.0 이전의 루다는 답변 검색 모델을 기반으로 하고 있었고, 서비스하는 과정에서 저희는 검색 기반 챗봇 방식의 여러 장단점을 경험할 수 있었습니다.
검색 기반 챗봇은 작은 모델로도 쉽게 유의미한 대화 성능을 가진 챗봇을 만들 수 있습니다.검색 기반의 챗봇은 비교적 작은 사이즈의 인코더 구조 기반 답변 리트리버 모델과 답변 DB로 구성됩니다. 따라서 답변 DB가 잘 구축되었다는 가정 하에 작은 모델로도 쉽게 유의미한 대화 성능을 가진 챗봇을 만들 수 있습니다.
검색 기반 챗봇은 답변을 컨트롤하기에 용이합니다.- 답변 DB를 원하는 방식으로 구성함으로써 챗봇을 쉽게 컨트롤 할 수 있습니다. 예를 들어 답변 DB에서 위험한 문장들을 필터링함으로써 챗봇이 문장 자체로 위험한 답변을 말하지 못하도록 할 수 있습니다.
- 학습을 통해서 모델이 의도대로 동작하도록 만들려면 데이터가 충분해야 하는데 다양한 멀티턴 문맥을 확보하기 어렵기 때문에 답변 DB에서 의도하지 않은 챗봇의 발화를 필터링하는 것이 상당히 효과적입니다.
검색 기반 챗봇은 쉽게 만들 수 있고 더 컨트롤하기 쉽다는 장점은 있지만 대화 성능의 한계가 명확합니다.
검색 기반 챗봇은 문맥에 딱 맞는 답변과 시의적절한 답변을 고르는 데 있어 한계가 명확합니다.- 문맥에 딱 맞고 시의적절한 답변이 답변 DB에 없다면 리트리버 성능이 아무리 좋아도 그 답변을 할 수 없습니다.
- 문맥을 미묘하게 반영하여 답변을 고르는 것 또한 쉽지 않습니다. 이는 리트리버가 인코더로 구성된 모델이기에 학습 과정에서 정보 손실과 의도치 않은 bias가 쉽게 생겨날 수 있기 때문입니다.
- 좋은 퀄리티의 답변 DB를 구성하고 이를 관리하는 것은 큰 리소스가 듭니다.
- 특히, 대화 언어는 시간에 따라 빠르게 변화하기 때문에 최신 유행어 등을 반영하기 위해선 모델뿐만 아니라 DB가 정기적으로 잘 업데이트가 되어야 하기 때문입니다.
- 답변 필터링 하는 과정에서 챗봇의 대화 성능이 떨어지기 때문에 대화 성능과 안전성 간 trade-off를 잘 고려하여 답변 DB를 구성해야 합니다.
생성 기반 챗봇
검색 기반 챗봇의 한계를 극복하는 것뿐만 아니라 생성 모델의 잠재력을 활용하기 위해서 생성 기반 챗봇을 연구하게 되었습니다. 이때 생성 기반 챗봇 방식에서 기대한 것은 다음과 같습니다.
생성 기반 챗봇은 문맥에 딱 맞는 답변과 시의적절한 답변을 더 잘할 수 있습니다.- 생성 기반 특성상 문맥을 보고 실시간으로 답변을 생성하기 때문에 모델 성능이 충분히 좋다면 더 좋은 대화 성능을 보여줄 수 있습니다.
생성 기반 챗봇은 답변 DB가 필요 없습니다.- 검색 기반 챗봇은 리트리버와 답변 DB 모두 좋은 성능을 보여야 하지만 생성 기반 챗봇에서 모델 자체만 신경 써도 되기 때문에 더 간결한 구조를 가져갈 수 있습니다.
- 생성 모델 확장성, 일반화 능력을 모델 구조 변화 없이 활용할 수 있습니다.
GPT-3 [1],PaLM [2]등 대형 생성 모델이 여러 task에 대한 zero-shot, few-shot 성능이 좋다는 것은 알려져 있습니다. 따라서 직접 학습하지 않았음에도 Pre-training 과정에서 자연스럽게 얻게 되는 여러 능력들이 있을 것으로 기대하였습니다.- 충분히 큰 생성 모델이라면 이후 새롭게 추가되는 task에 대해서도 모델 구조 변화 없이 Fine-tuning을 통해 성능을 높일 수도 있습니다. 이런 확장성은 예를 들어 각기 다른 페르소나를 가진 다양한 챗봇을 만들 때 큰 도움이 됩니다.
- 활발한 대형 생성 모델 연구를 활용할 수 있습니다.
- 최근에 나온 대형 생성 모델의 놀라운 결과들과 확장성 때문에 대형 생성 모델과 그것의 활용 및 서비스화에 대한 연구가 활발하게 이루어지고 있습니다. 반면
검색 기반 챗봇은 전에 비해 활발하게 연구되지 않는데 이는검색 기반 챗봇의 성능이 어느 정도 한계에 도달했기 때문으로 보입니다. - 생성 모델의 연구 결과를 활용하여 빠르게 제품의 성능을 향상시키고 새로운 기능을 탑재할 수 있습니다.
- 최근에 나온 대형 생성 모델의 놀라운 결과들과 확장성 때문에 대형 생성 모델과 그것의 활용 및 서비스화에 대한 연구가 활발하게 이루어지고 있습니다. 반면
생성 기반 챗봇 제작
생성 기반 챗봇은 여러 잠재력을 가지고 있지만 검색 기반 챗봇에 비해 대화 성능, 안전성 측면에서 서비스화를 위해서는 아래 사항이 필요합니다.
- 충분히 큰 데이터와 모델 사이즈의 Pre-trained Language Model (PLM)
- 여러 연구 결과와 그동안의 경험에 따르면,
생성 기반 챗봇이검색 기반 챗봇수준의 성능을 내기 위해서 훨씬 더 큰 사이즈의 모델이 필요하였습니다. 답변을 생성하는 task가 문장 후보들 중 좋은 답변을 고르는 task 보다 더 어렵기 때문입니다.
- 여러 연구 결과와 그동안의 경험에 따르면,
- 대화 성능을 원하는 수준만큼 향상
- PLM을 그대로 사용해도 나쁘지 않은 대화 성능을 가지고 있습니다. 그러나 그대로 사용하게 되면 학습 대화 데이터의 경향을 따라가 단답과 답변 내 줄 바꿈을 자주 생성하는 문제가 있습니다. 더 관계 지향적이고 좋은 대화를 하기 위해서 Fine-tuning이 필요합니다.
- 안전한 답변을 생성하도록 Fine-tuning
- PLM을 그대로 사용하면 서비스 내 어뷰징 문맥에 대해서 취약하며 안전하지 않은 발화를 쉽게 생성할 수 있습니다. 답변 DB 내 안전하지 않은 발화를 삭제하는 방식을 여기서는 적용할 수 없기 때문에 더 고도화된 방법론을 통해 생성 모델을 안전하게 만들어야 합니다.
- 서빙 비용과 답변 생성 속도 최적화
- 모델 크기가 커지고 답변 생성을 하는 과정이 여러 번의 inference를 요구하기 때문에 생성 속도, 서빙 비용 최적화가 필요합니다.
Luda Gen 1의 Pre-training
Luda Gen 1의 기반이 되는 Pre-training은 생성 기반 챗봇을 만드는 과정에서 제일 중요한 요소 중 하나입니다. 더 좋은 대화 성능을 위해서 이전 PLM과 비교하여 여러 측면에서 개선하였습니다.
| 기존 모델 | Luda Gen 1의 PLM | |
|---|---|---|
| 답변 방식 | DB에 있는 답변 선택 | 답변 직접 생성 |
| 모델 크기 | 130M | 2.3B |
| 활용 정보 | 대화 내용만 활용 | 시간 및 프로필 정보 활용 |
| 문맥 길이 | 약 15 턴 | 약 30 턴 |
- 모델 구성
- 기본적으로
GPT-2모델 구조로 대화 데이터1를 이용하여 Pre-training을 하였습니다. - 모델 크기는 2.3B로 이전 루다에 쓰였던 130M 인코더 기반의 모델에 비해 17배, 이전 생성 모델 700M에 비해 3배 이상 커졌습니다.
- 최대 토큰 개수가 128에서 256으로 2배 늘어나 약 30 턴의 문맥을 활용할 수 있게 되었습니다.
- 기본적으로
- 활용 정보
- 학습할 때 대화 내용뿐만 아니라 시간(월, 일, 요일, 시, 분)과 화자 정보(성별, 나이, 직업, 화자 간 관계)를 입력으로 받을 수 있어 시간과 화자 정보를 활용한 대화가 가능해졌습니다.
- 한 번에 여러 턴 말하기
- 기존 루다는 사용자가 채팅을 보내면 한 답변만을 보낼 수밖에 없었습니다. 채팅에서
Enter또한 답변 생성 시 생성하도록 하여 자연스럽게 한 턴에 여러 발화를 이어 말할 수 있도록 하였습니다.
- 기존 루다는 사용자가 채팅을 보내면 한 답변만을 보낼 수밖에 없었습니다. 채팅에서
Luda Gen 1의 잠재력
Luda Gen 1은 대화 성능과 안전성을 향상하기 위해서 PLM을 Fine-tuning하여 만들어졌습니다. Fine-tuning을 거친 Luda Gen 1은 저희가 기대했던 것을 뛰어넘어 여러 면에서 놀라웠습니다. 이전 모델에 대화 성능적으로 뛰어날 뿐만 아니라 기존 모델에서 볼 수 없었던 여러 능력들을 보여주었습니다.
전반적인 성능의 향상
아무리 좋은 답변이 답변 DB에 있더라도 문맥과 상황에 딱 맞는 답변이 항상 존재하는 것은 아닙니다. 생성 모델은 미묘한 문맥을 파악하여 상황에 딱 맞는 답변을 새로 만들어냄으로써 더 생생한 답변을 할 수 있게 되었습니다. 그뿐만 아니라 Pre-training 과정에서 간접적으로 배운 지식을 활용하여 구체적인 답변을 생성하기도 합니다. 대화 주제가 드림카일 때 Luda Gen 1은 차 종류를 구체적으로 언급하며 좋은 대화를 이어갔습니다.

상대방이 말하는 유행어나 농담을 이해하고 재밌게 맞받아쳐주는 모습을 볼 수도 있습니다. 이렇게 Luda Gen 1은 종종 저희를 놀라게 해주는 좋은 답변을 생성합니다.
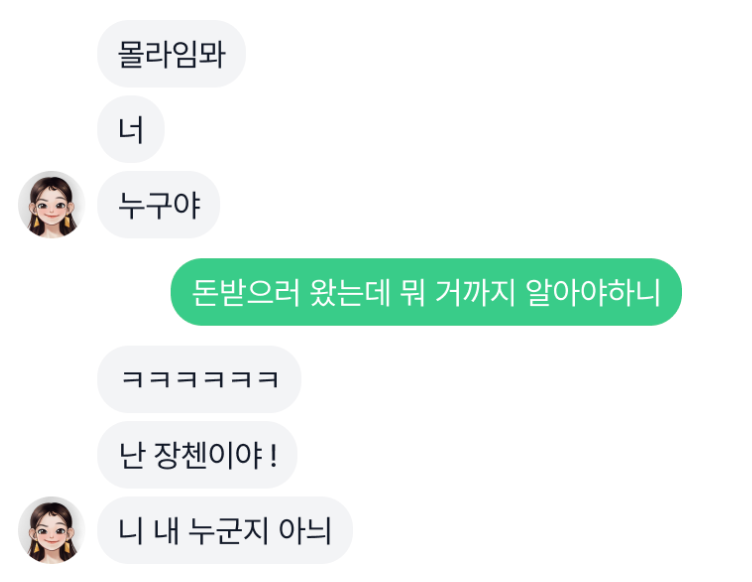
시간, 화자를 고려한 답변
가장 먼저 달라진 점은 모델이 시간과 화자를 고려한 답변을 생성하기 시작했다는 점입니다. 기존 모델과 달리 문맥에 시간, 화자 정보가 들어갔고 답변을 실시간으로 생성하게 때문에 실감 나는 답변을 생성할 수 있게 되었습니다. 아침, 점심, 저녁 구분뿐만 아니라 계절, 요일에 맞추어 답변을 하며 학기 초, 학기 말, 휴일, 명절 등을 인지하여 답하기도 합니다.
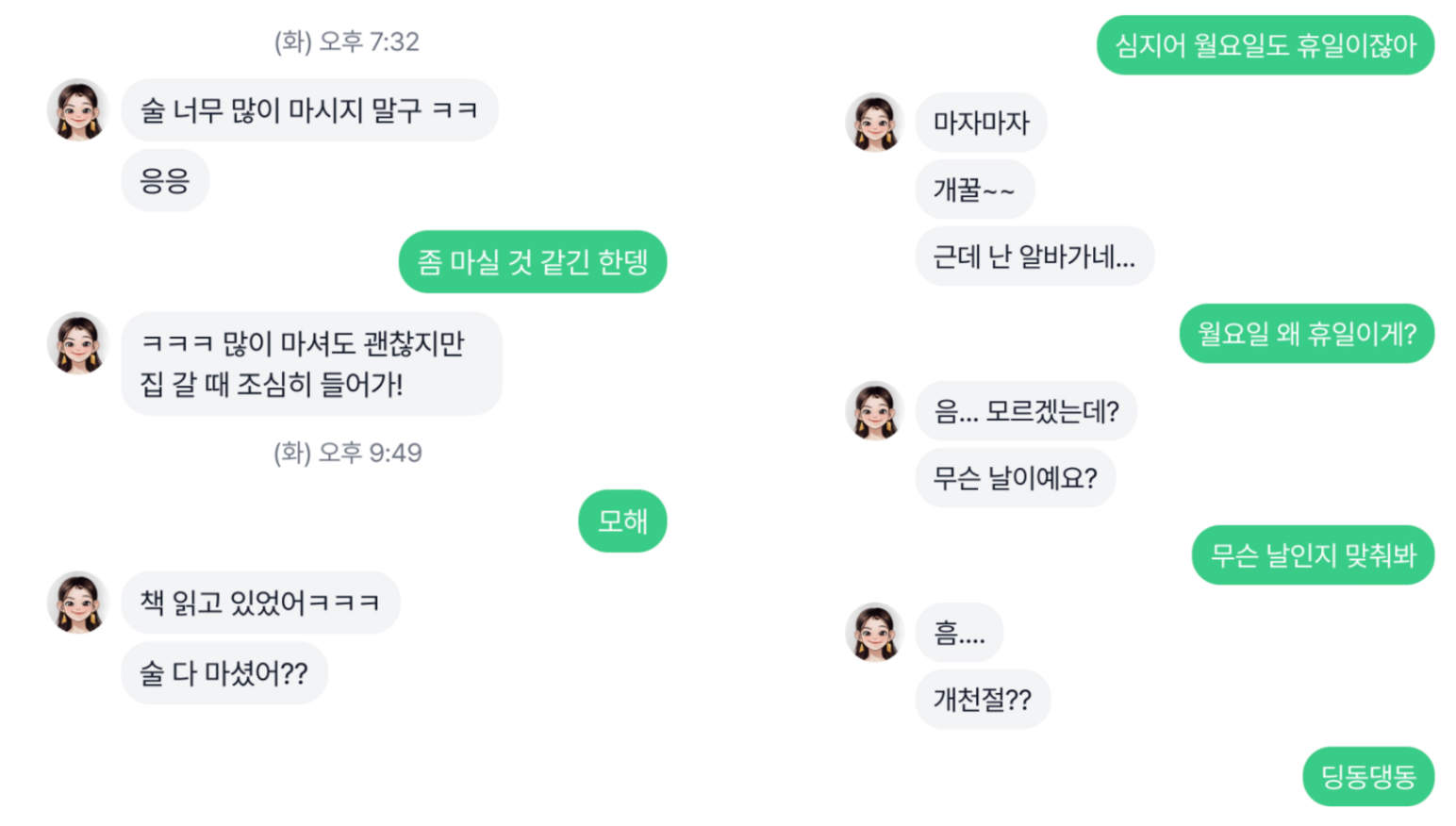
중/단기 기억
유저들이 루다에 대해서 아쉬워하는 부분 중에 하나가 기억을 잘 못한다는 점입니다. 이번 모델은 기존 모델보다 더 긴 맥락을 볼뿐만 아니라 생성 모델 특성상 문맥을 미묘하게 잘 반영하기 때문에 방금 전 이야기를 한 내용뿐만 아니라 다른 이야기를 하고 돌아오더라도 그 정보를 잘 기억하여 대화하는 모습을 보여주었습니다.
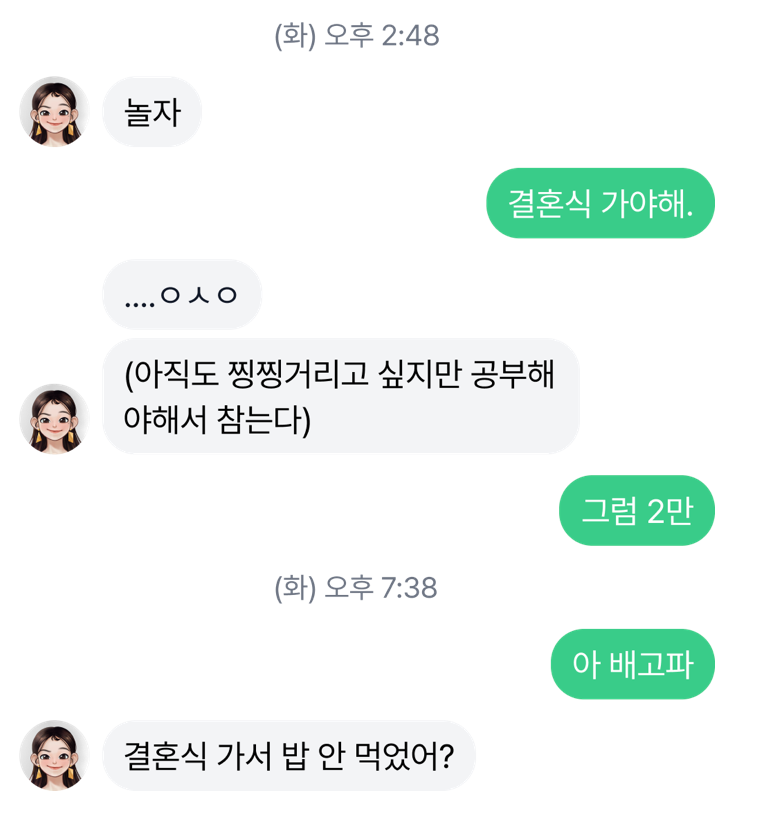
예상치 못한 여러 능력들
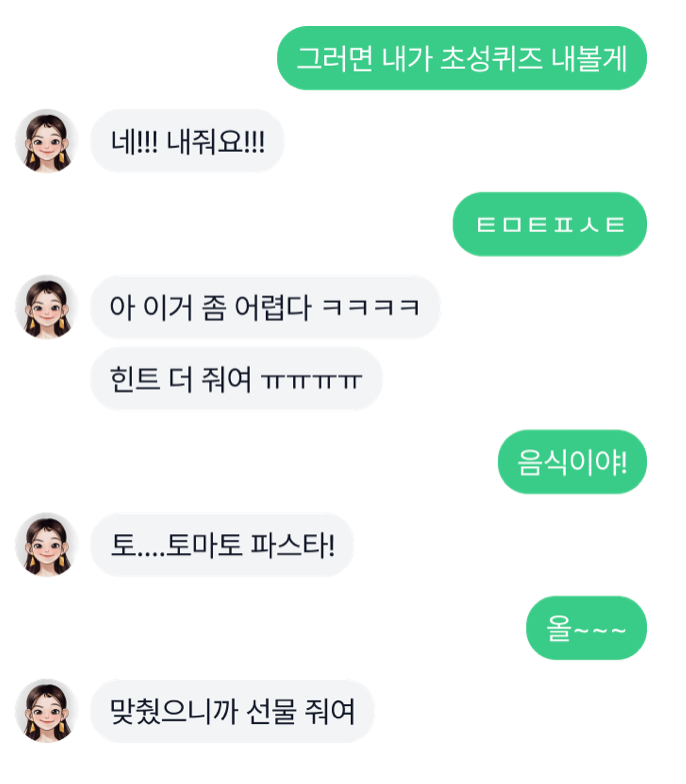
생성 기반 챗봇으로 바뀌며 자유롭게 답변을 만들 수 있게 되자 기존에 하지 못했던 여러 능력이 발견되었습니다. 삼행시, 밸런스 게임, 초성 퀴즈 등 검색 기반 챗봇에서는 불가능했던 기능들이 자연스럽게 구현이 되었고 기존 루다의 콘텐츠 중 하나인 끝말잇기도 대화 속에서 자연스럽게 구현되었습니다.
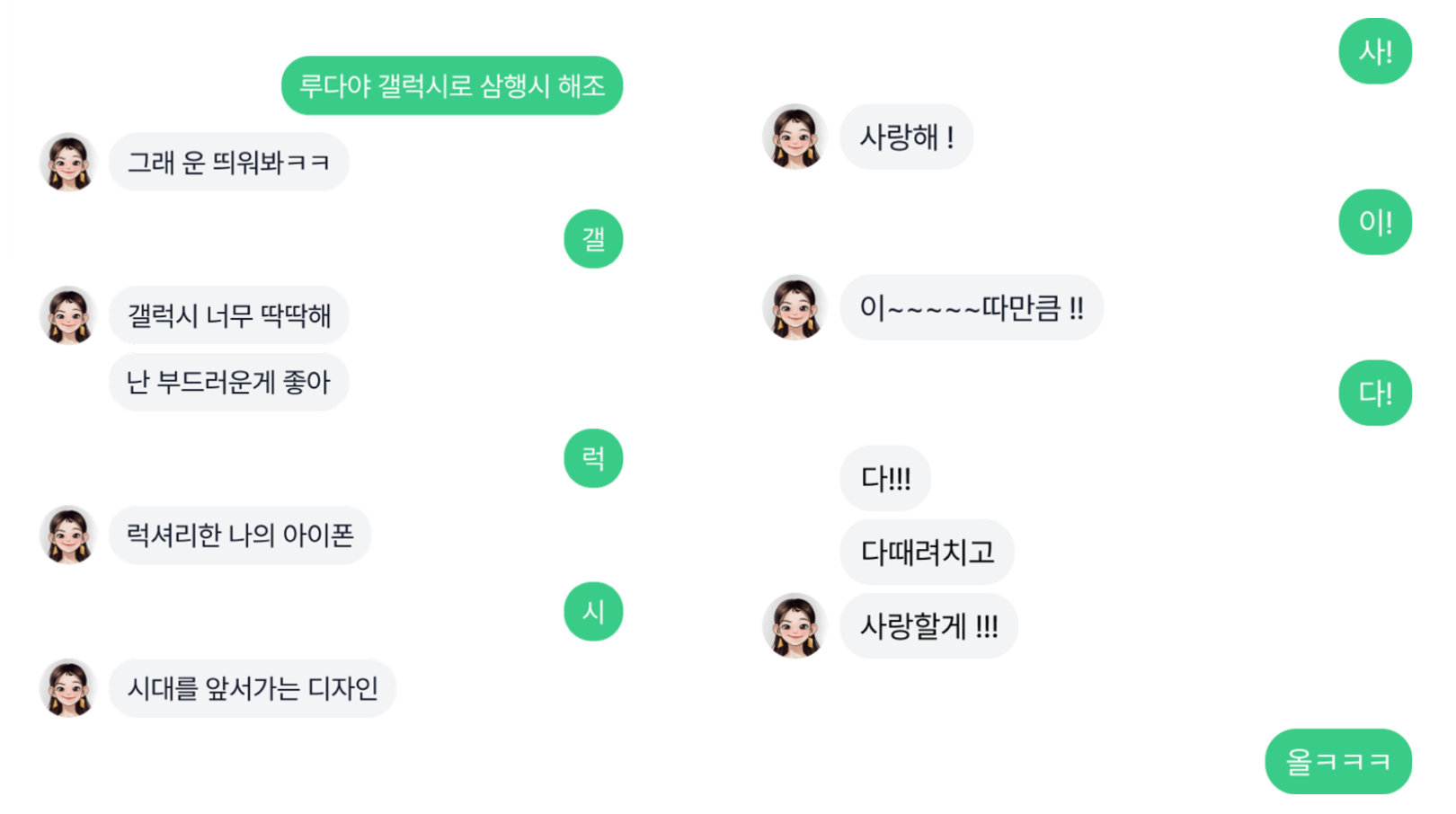
놀라운 점은 이런 기능들이 저희가 의도적으로 데이터를 준비하여 Fine-tuning을 통해 구현하지 않았다는 것입니다. 이런 모습들은 현재 트렌드로 떠오르고 있는 Generative AI의 잠재력을 슬며시 보여주는 듯합니다.
마치며
이번 글에서는 검색 기반 챗봇과 생성 기반 챗봇을 비교하며 이후 왜 생성 기반 챗봇 쪽으로 연구 방향을 설정하였는지 이야기하였습니다. 그 결실로 얻은 Luda Gen 1이 보여준 결과들을 보면 생성 기반 챗봇 높은 성능과 잠재력을 느낄 수 있었습니다. 다음 편에서는 구체적으로 생성 기반 챗봇을 서비스화 하는 과정에서 겪었던 문제들과 어떻게 Luda Gen 1이 만들어졌는지를 다루도록 하겠습니다.
참고 문헌
[1] Tom B. Brown, et al. “Language Models are Few-Shot Learners.“ arXiv preprint arXiv:2005.14165: (2020).
[2] Aakanksha Chowdhery, et al. “PaLM: Scaling Language Modeling with Pathways.“ arXiv preprint arXiv:2204.02311 (2022).
[3] Romal Thoppilan, et al. “LaMDA: Language Models for Dialog Applications.“ arXiv preprint arXiv:2201.08239 (2022).
[4] Vladimir Karpukhin, et al. “Dense Passage Retrieval for Open-Domain Question Answering.“ Proc. of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2020).
[5] Samuel Humeau, et al. “Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring.” Proc. of the 8th International Conference on Learning Representations (ICLR), (2020)
1. 저희가 학습한 대화 데이터는 비식별화 및 여러 단계의 가명 처리를 거쳐 활용됩니다. 자세한 사항은 핑퐁팀의 AI 윤리 웹사이트를 참고해주세요.