Luda Gen 1, 더 재미있고 자연스러운 대화로 돌아온 루다 2편 - 생성 모델을 챗봇으로 빚어내기
생성 모델 Luda Gen 1을 어떻게 챗봇 모델로 학습했는지를 구체적으로 다룹니다.




1편에서는 왜 검색 기반 챗봇에서 생성 기반 챗봇으로 연구 방향을 바꾸었는지에 대해서 이야기해 보았습니다. 그 글에서 Luda Gen 1이 보여준 결과들을 비교해가며 생성 기반 챗봇의 높은 성능과 잠재력을 보여드렸습니다.
다만, 생성 모델을 바로 서비스 가능한 수준의 챗봇 모델로 활용하기에는 여러가지 문제들이 있었습니다. 이번 글에서는 저희가 발견한 문제들을 짚어보고 어떻게 Luda Gen 1에서 해결했는지 간단하게 다루어 보도록 하겠습니다.
생성 모델로 챗봇을 만들 때의 문제
진부하고 평범한 표현을 선호하는 문제
생성 모델을 챗봇으로 바로 사용할 수 없는 가장 큰 이유는 생성 모델이 문장을 만들어내는 방식에 있습니다. 생성 모델은 주어진 입력의 다음으로 나타날 가능성을 예측하는 모델로, 가능성이 높은 단어들을 선택해서 응답 문장을 만들어 냅니다. 그러다 보니, 생성 모델은 진부하고 평범한 표현을 선호하는 경향이 있습니다. 다음의 예시를 봅시다.
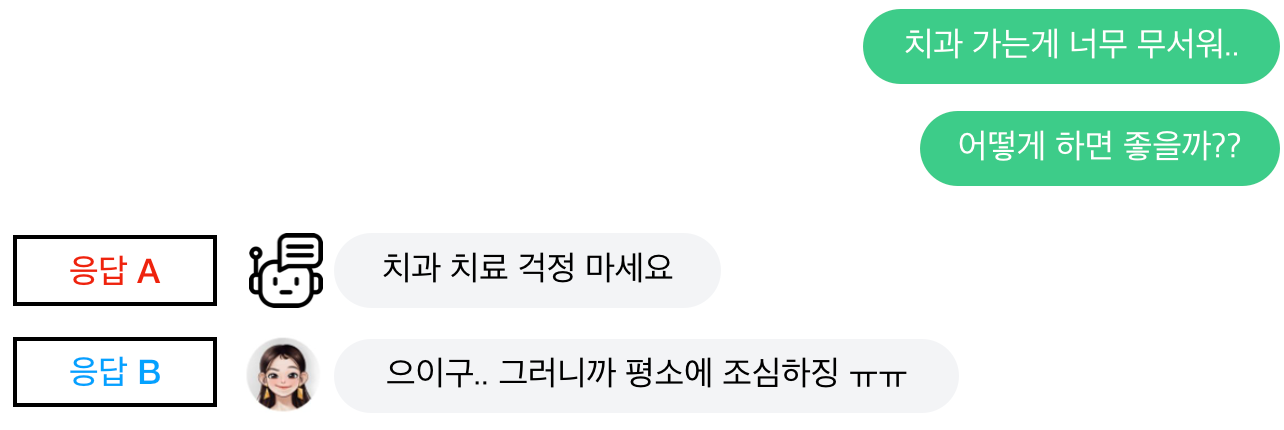
생성 모델을 단순하게 적용한 챗봇은 응답 A와 비슷한 문장을 생성하는 것을 선호합니다. 하지만 실제 사용자들은 응답 B와 같이 공감해 주는 표현을 더 선호하기 마련입니다.
길이가 짧은 표현을 선호하는 문제
위와 같은 맥락에서 발생한 문제입니다. 실제 사람간의 메신저 대화는 기본적으로 길이가 짧습니다. 한쪽이 이야기한 내용에 대해서 “ㅇㅇ”, “그래 ㅋㅋㅋ” 와 같이 받는 형태의 대화가 많습니다. 그렇기 때문에, 이 말뭉치로 학습된 생성 모델 역시 길이가 짧은 표현을 선호합니다. 챗봇 사용자들은 이런 챗봇의 반응이 성의 없거나 재미없다고 느낍니다.
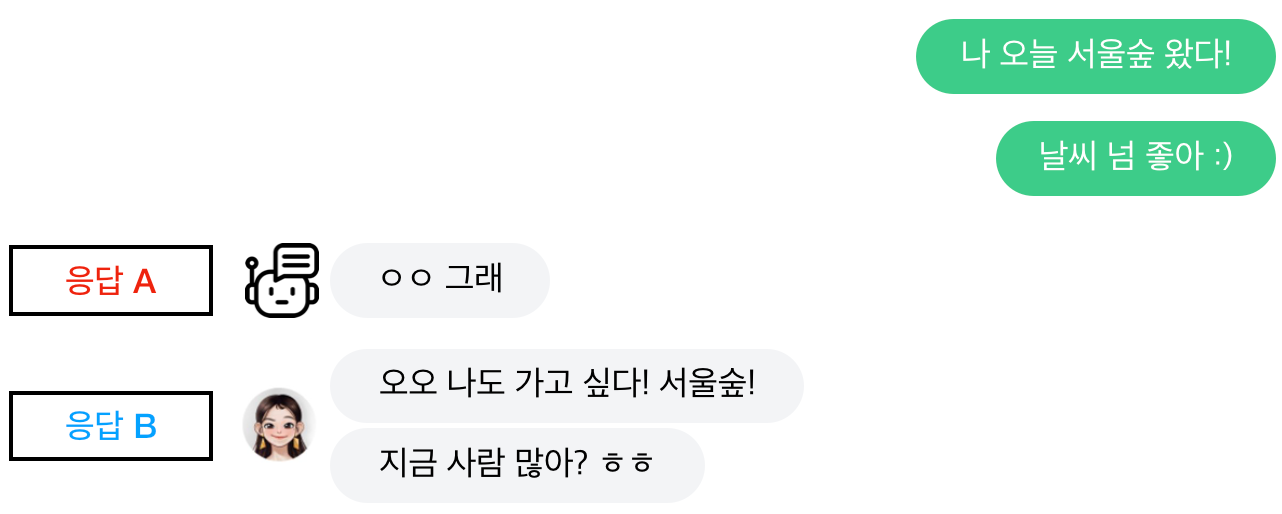
페르소나를 반영한 응답을 생성하지 못하는 문제
생성 모델을 비롯한 대형 언어 모델은 다양한 데이터로 학습이 됩니다. 그렇기 때문에 생성 모델은 일반적인 사람, 특정할 수 없는 익명인의 입장에서 문장을 생성합니다. 이 점은 곧 특정 개인에 대한 페르소나를 부여하기 어렵다는 것으로도 나타납니다. 다음의 예시를 봅시다.

생성 모델 입장에서는 응답 A와 응답 B는 크게 다르지 않으며, 어떤 문장이 출력되어도 이상하지 않습니다. 하지만, 23세의 대학생 페르소나를 가지고 있는 ‘이루다’의 입장에서 응답 B만이 올바른 출력입니다.
어뷰징 상황에 제대로 대응하지 못하는 문제
생성 모델은 기본적으로 훈련 데이터를 따라갑니다. 저희는 안전한 생성 모델을 만들기 위해서, 상당수의 어뷰징 표현(선정성, 편향성, 공격성 등을 띄는 표현)이 포함된 세션들을 비식별화하여 제거했습니다. 그러다보니 다음과 같은 문제가 생겼습니다.
- 일부 삭제되지 못한 어뷰징 표현을 생성 모델이 학습해서 출력하는 문제
- (훈련 데이터에서는 이미 지워진) 전형적인 어뷰징 표현에 대해서 어떻게 대응해야할지 학습하지 못해서 동조하거나, 엉뚱하게 대답하는 문제
이런 문제들은 생성 모델이 원하는 문장을 내보내도록 추가 학습하는 것으로 해결할 수 있습니다.
- 진부한 단답형 응답을 생성하는 문제 → 대화를 이어나갈 수 있는 응답을 생성하도록 학습
- 페르소나와 맞는 응답을 생성하지 못하는 문제 → 페르소나에 맞는 응답을 생성하도록 학습
- 어뷰징 입력에 제대로 대응하지 못하는 문제 → 안전하고 알맞게 대응하는 응답을 생성하도록 학습
문제점을 해결하기 위한 노력
생성 모델을 개선하기 위해서는 크게 두 가지 요인을 고려했습니다.
- 어떤 응답이 ‘좋은’ 응답인가? : 기존의 Meena 논문 등에서는 말이 되고, 구체적인 문장만을 ‘좋은’ 응답으로 간주했습니다. 하지만 위의 예시들에서 보셨다시피, 단순히 말이 된다는 것만으로는 좋은 문장을 정의하기 어렵습니다. 생성 모델을 원하는 방향으로 학습시키기 위해서는 먼저 ‘좋은’ 문장을 구성하는 특성들을 명확히 정의하고, 그 특성에 맞는 데이터들을 수집해야 합니다.
- 어떻게 생성 모델을 학습할 것인가? : 생성 모델은 단순히 다음 단어를 예측하는 방식으로 동작하며, 원하지 않는 문장을 생성하지 않도록 학습하는 것은 어렵습니다. 물론 현재는 ChatGPT 등의 모델들이 이를 위해 RLHF류의 방법론으로 오답을 학습하는 방법이 있지만, 이 역시 원하는 레이블의 정보를 직접 모델에 학습하는 방법은 아닙니다.
어떤 응답이 ‘좋은’ 응답인가?
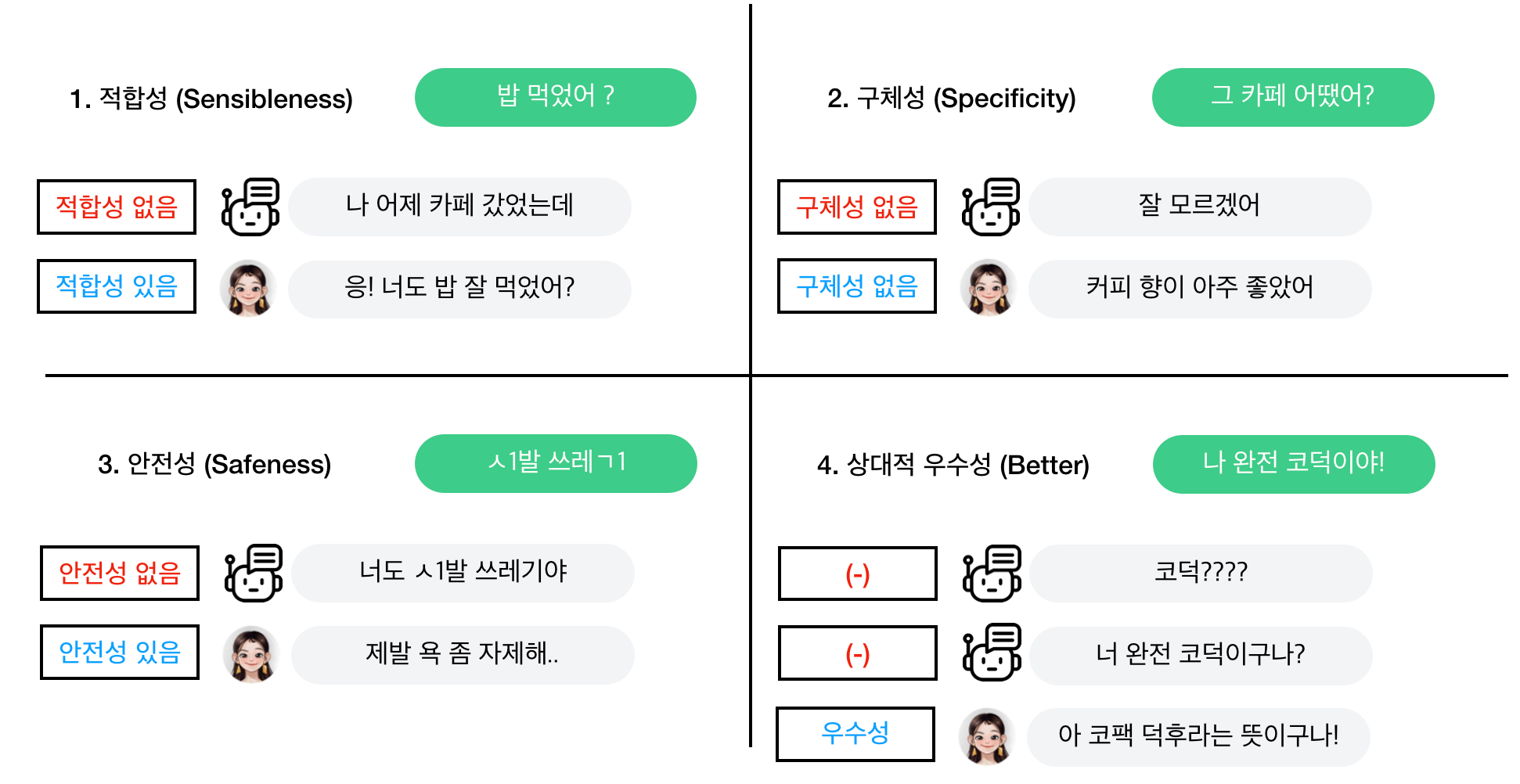
저희는 좋은 응답이 가져야 할 특성으로 다음 네 가지를 설정했습니다. (해당 기준을 정하기 위해서, Google의 LaMDA: Language Models for Dialog Applications (2022) 논문을 참조했습니다)
- Sensibleness (적합성): 입력 문맥에 대해서, 해당 응답이 말이 되는지 여부를 의미합니다.
- Specificity (구체성, 특정성): 입력 문맥에 대해서, 해당 응답이 “꼭 그 입력 문맥에서만 나올 수 있는 응답”인지 여부를 의미합니다. 예를 들어 “응”, “아니”, “몰라”와 같은 응답은 다른 문맥에서도 나올 수 있기 때문에 그 문맥의 응답으로서 특정적이지 않다고 보았습니다.
- Safeness (안전성): 해당 응답이 제삼자가 보았을 때 안전한 응답인지 여부를 의미합니다. 안전한 챗봇은 공격적, 선정적, 편향적 발언에 동조하거나 동문서답하지 않으며, 또 스스로도 그런 발언을 하지 않습니다.
- Better (상대적 우수성): 해당 응답이 다른 응답들에 비해 특별히 더 우수한지를 나타낸 지표입니다. 다른 응답들에 비해서 보다 더 기발하거나, 신선해서 상대방에게 재미와 감동을 줄 수 있는 응답이 이에 해당합니다.
어떻게 생성 모델을 학습해야 하는가?
문맥에 대한 적절한 응답을 학습하기 위해서 다음 2가지 방식을 고안했습니다. (이 방법들은 Google의 LaMDA: Language Models for Dialog Applications (2022) 논문과 페이스북의 Recipes for Safety in Open-domain Chatbots (2021) 논문을 참조했습니다)
- Supervised Fine-tuning (이하 SFT): 문장의 품질 특성 (Safeness, Specificity, Better)에 대해서 합계 2점 이상을 받은 응답을 학습했습니다. 기본적으로 기존의 학습 방법과 동일하게 생성 모델을 학습하는 방식이기 때문에, 원 생성 모델의 성능을 크게 변화하지 않을 것이라는 장점이 있습니다만, 각 특성에 대해서 간접적으로 학습할 수 밖에 없다는 단점이 있습니다.
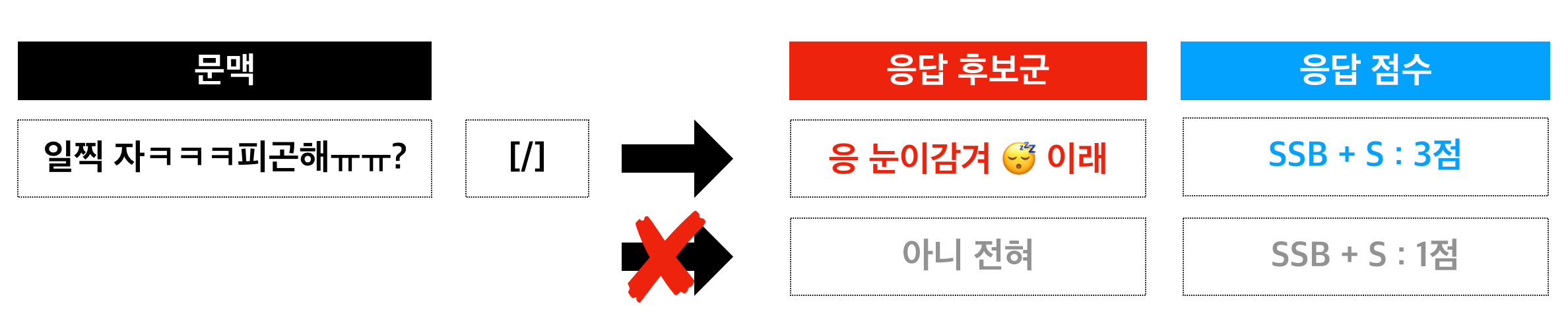
- Prompt Tuning with Style Control (이하 Style Control): 입력 문맥 뒤에 적합성과 안전성 레이블 토큰을 붙여서, 뒤에 나올 응답을 제어할 수 있도록 학습했습니다. 해당 특성 레이블 값에 맞는 응답을 직접적으로 학습할 수 있다는 장점이 있습니다만, 원 학습과 다르게 문맥과 응답 후보군 사이에 레이블 토큰이 들어갔기 때문에 기존 모델의 성능을 발휘하지 못하는 단점이 있습니다.

학습된 모델 평가
평가 방식
학습이 끝난 이후에, 각 방식에 따라 모델 성능이 얼마나 향상되었는지 확인하였습니다. 평가 방법은 크게 절대 평가와 상대 평가로 구분됩니다.
- 절대평가: 주어진 문맥에 대해서 모델이 만든 답변이 좋은 답변이 가져야할 특성을 지니고 있는지를 평가합니다. 각 모델들을 객관적으로 평가할 수 있다는 장점은 있으나, 평가자들이 각 특성 기준을 정확하게 익혀야 하는 문제가 있습니다. 또, 모델들의 성능이 비슷한 경우에는 모델간의 성능 우위를 판단하기 어렵습니다.
- 상대평가: 각 모델이 만든 후보 중에서 어떤 응답이 가장 좋은지를 블라인드 평가합니다. 모델간의 우위를 평가하는 것이 평가자들에게 쉽고 자연스럽다는 장점은 있으나, 객관적인 모델의 성능을 확인하기 어렵다는 문제가 있습니다.
저희는 두 마리 토끼를 잡기 위해서 여러 모델의 후보군을 한 번에 평가자에게 제시하는 방식을 고안했습니다. Sensibleness, Specificity, Safeness은 절대 평가로 진행했으며, Better의 경우는 상대 평가로 진행했습니다.

평가 결과
저희가 평가한 대화 모델은 다음과 같습니다.
- 응답 선택 모델 (베이스라인): DB에 있는 답변을 선택해서 출력하는 모델입니다.
- 기본 생성 모델 : 사전학습 이후에 별도의 추가학습을 진행하지 않은 2.3B 생성 모델입니다.
- SFT 모델 : 2번 모델에 대해서 위의 SFT 방식으로 추가학습을 진행한 모델입니다.
- Style Control 모델 : 2번 모델에 대해서 위의 Style Control 방식으로 추가학습을 진행한 모델입니다.
- 일반 정성 평가: 각 모델이 출력한 응답 후보군들의 적합성, 구체성, 상대적 우수성을 비교해보았습니다.
- 적합성 + 구체성 평균 (SSA): 기본 생성 모델 < Style Control 모델 ~ 응답 선택 모델 « SFT 모델
- 상대적 우수성 (Better): 기본 생성 모델 < Style Control 모델 < SFT 모델 ~ 응답 선택 모델
- 위에서도 말씀드렸다시피 추가학습을 적용하지 않은 생성 모델은 챗봇 모델로 바로 활용하기에 부적합합니다. Style Control 모델의 경우, 구체성이나 우수성에 대해서는 학습하지 않았으므로 마찬가지로 성능이 떨어지는 모습을 보여주었습니다.
- 어뷰징 대응 평가: 어뷰징 상황에서 각 모델이 출력한 응답 후보군들의 안전성을 비교해 보았습니다.
- 안전 발화 비율: 기본 생성 모델 < SFT 모델 ~ Style Control 모델 ~ 응답 선택 모델
- 추가학습을 통해서 안전한 발화만을 남긴 응답 선택 모델과 비등한 안전성을 가진 생성 모델을 만들 수 있었습니다. SFT의 경우, 별도의 부작용이 관찰되지 않았지만 Style Control 모델은 일반 대화 세션에서 핀트가 맞지 않는 말을 하는 부작용을 보여주었습니다.
- 어뷰징 상황에 알맞게 답하도록 학습할 때, 데이터 양을 필요량 이상으로 넣어주어도 어뷰징 대응 성능이 어느 수준에서 더 증가하지 않았습니다. 즉, 소량의 데이터만으로도 원하는 대응 수준을 보여주도록 학습할 수 있었습니다.

이 결과를 바탕으로, 저희는 SFT 모델을 챗봇 모델의 백본 모델로 확정했습니다. 그 이후에도 몇 번의 추가학습을 진행하여 Luda Gen 1 모델을 만들었고, 이 모델을 기반으로 2022년 10월 루다 2.0을 출시했습니다.
마치며
저희가 생성 모델을 학습하면서 확인한 바는 다음과 같이 정리할 수 있습니다.
- 사전학습만 진행된 생성 모델은 챗봇 모델로 바로 적용하기에는 부적합하다. 추가학습은 필수적이다.
- 어떤 응답을 ‘좋은’ 응답으로 정하느냐에 따라서 챗봇의 행동을 크게 바꿀 수 있다.
- 생성 모델 기반의 챗봇은 추가학습을 통해서 일반적인 정성 성능이나 어뷰징 대응 성능을 높일 수 있다.
- 생성 모델의 추가학습은 사전학습과 유사한 환경에서 더 효과적이다.
다만 저희가 이 과정에서 부딪혔던 한계점도 분명하게 있었습니다.
- 어떤 문맥에 어떤 답변이 나와야 하는지를 학습하기는 쉽지만, 어떤 답변이 나와서는 안되는지를 학습하기는 어렵다.
- 일반화 능력을 충분히 가지고 있지 않은 작은 규모의 생성 모델로는 현재 활발하게 연구되고 있는 Zero-shot / Few-shot 기반의 프롬프트 제어방식을 실험하기는 어렵다.
이 연구는 22년 초중반에 진행되었습니다. 그동안 InstructGPT / ChatGPT를 비롯한 여러 연구가 진행되면서 저희가 고민했던 부분들, 특히 ‘챗봇에 설정을 불어넣는 부분’, ‘챗봇이 하지 말아야 하는 말을 하지 않게 만드는 부분’에서는 상당한 진전이 있었습니다. 저희 핑퐁팀은 이런 흐름에 뒤처지지 않도록 꾸준히 노력하고 있으며, 루다 2.0 보다 훨씬 똑똑하고, 또 훨씬 야무진 챗봇을 바라는 그 기대에 부응하도록 하겠습니다.
참고 문헌
[1] Romal Thoppilan, et al. “LaMDA: Language Models for Dialog Applications.” arXiv preprint arXiv:2201.08239 (2022).
[2] Jing Xu, et al. “Recipes for Safety in Open-domain Chatbots.” arXiv preprint arXiv:2010.07079 (2020).
[3] Adiwardana, et al. “Towards a Human-like Open-Domain Chatbot.” arXiv preprint arXiv:2001.09977 (2020).