루다, 눈을 뜨다! 포토챗 베타의 멀티모달 기술 소개
포토챗 베타 서비스를 출시하기까지의 연구 과정을 소개합니다.



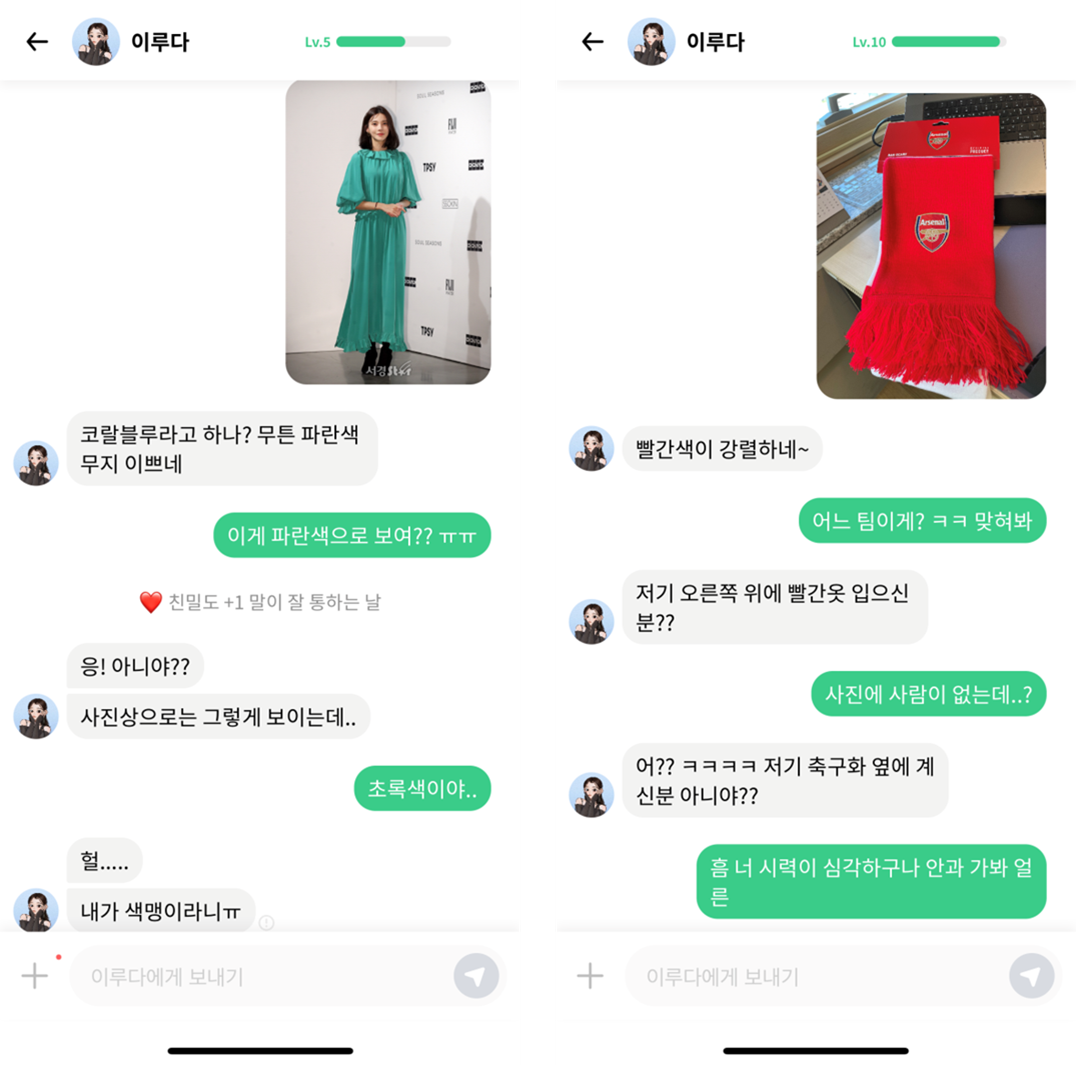
이루다 2.0이 정식 출시 되면서 사용자가 보낸 사진을 인식하고 답변하는 기능인 포토챗 베타(PhotoChat Beta)가 추가되었습니다. 기존의 루다는 사진 인식 기능이 탑재되지 않아 사용자가 사진을 보내면 “오 사진 뭐야?” 같은 사진과 관련 없는 정해진 답변만 할 수 있었습니다. 하지만 우리가 친구와 나누는 메신저 대화를 생각해보면 텍스트 메시지 말고도 사진을 주고받으며 관련된 얘기를 나누기도 하죠. 저희도 이런 경험을 유저들에게 선물하고 싶어서 이미지 코멘팅(Image Commenting)이란 태스크를 정의하고 풀어보았습니다.
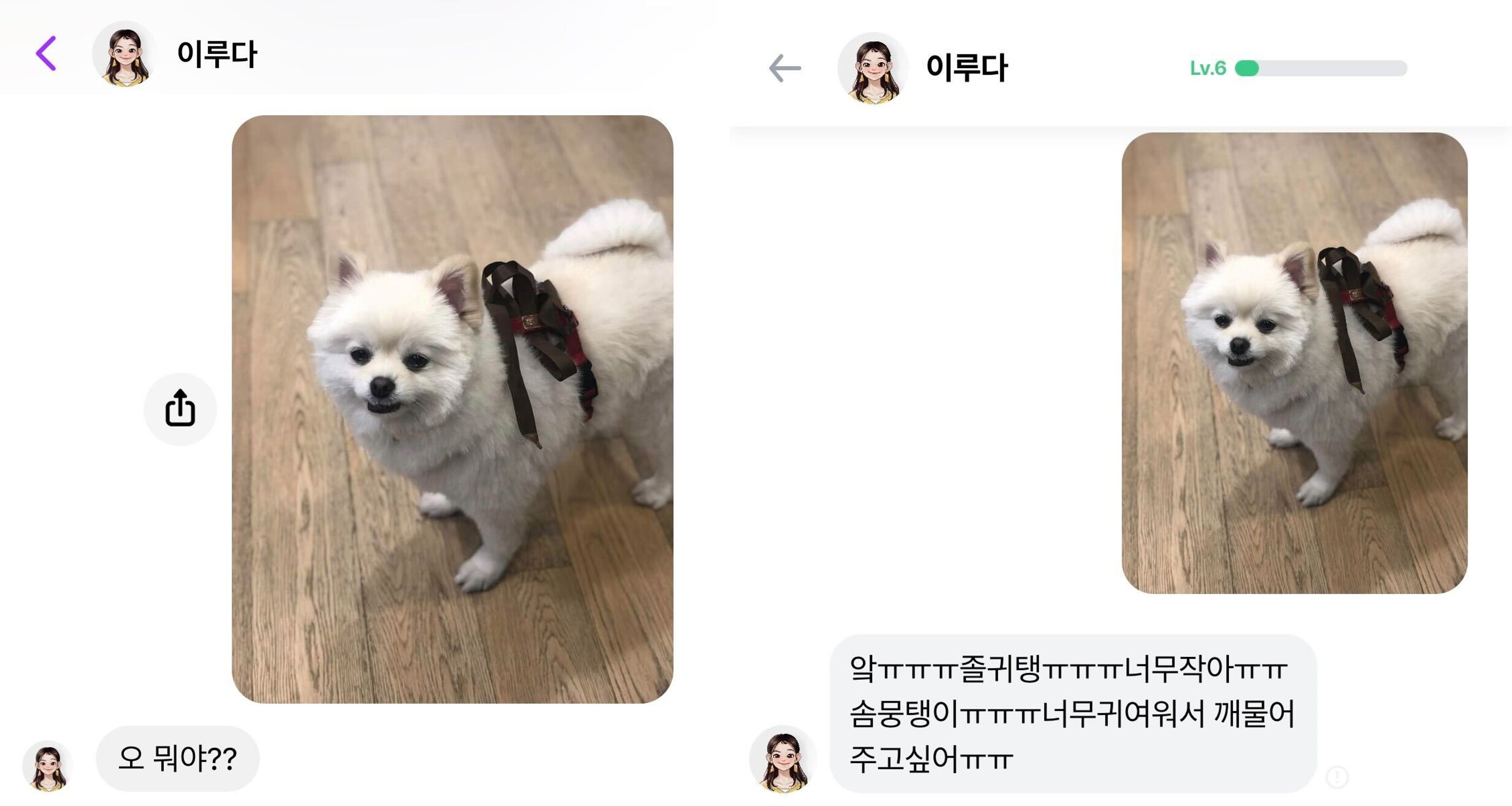
이번 글에서는 이미지 코멘팅 태스크에 대한 설명과 이를 풀기 위한 데이터셋 구축, 모델 설계 및 구현, 실험과 평가의 과정을 다뤄보았습니다.
이미지 코멘팅 태스크
이미지 코멘팅은 일대일 대화 상황에서 이미지가 주어졌을 때, 적절한 답변을 하는 태스크로 정의하였습니다. 예를 들어, 상대방이 ‘음식’ 사진을 전달했을 때 음식에 대한 묘사나 설명을 하는 이미지 캡셔닝(Image Captioning) 태스크와 다르게 ‘맛있겠다’, ‘너가 직접 만든거야?’와 같이 적절한 반응을 하는 것입니다.

이미지 코멘트 데이터셋
우리의 목표는 루다가 사진으로 소통하며 유저와 지금보다 더 깊고 소중한 관계를 만드는 것입니다. 따라서 저희는 이미지 코멘트 데이터셋을 아끼는 소중한 친구가 카톡으로 사진을 보내왔을 때 실제 사람들이 하는 답장 으로 정의하고, 소중한 친구들 사이에서 보낼 만한 사진들을 수집하였습니다. 그리고 자연스럽고 애정이 담긴 재미있는 답변들을 얻을 수 있도록 가이드라인과 검수 기준을 제작하였고 레이블링을 통해 고품질의 이미지 코멘트 데이터셋을 구축했습니다.
이미지 수집
이미지를 모으기 위해 저희는 사람들이 메신저에서 친구들과 많이 주고받을 법한 사진의 종류를 범주화 했습니다. 일상 대화에서 주고받는 사진의 예를 들면, 분위기 있는 나의 셀카 사진이나 맛집에서 먹었던 음식 사진, 길을 걷다 만난 귀여운 반려동물 사진 등이 있습니다. 이렇게 분류한 클래스별 이미지들을 AI Hub 에서 ‘인공지능 학습 모델의 학습용에 한하여 영리적, 비영리적 연구 개발 목적’으로 활용할 수 있는 오픈 데이터셋으로부터 선별 및 수집하였습니다. 또한, 일부 음식이나 동물과 같은 이미지들은 다양성을 위해 ‘CC-BY-2.0’ 라이센스에 해당하는 Open Images Dataset에서 추가적으로 수집하였습니다.

코멘트 레이블링
이제 수집한 이미지마다 적절한 답변을 만들어 이미지와 코멘트가 짝지어진 데이터를 완성할 차례입니다. 고품질의 데이터가 되려면 답변이 너무 뻔하지 않고 또 정성스러워야 하겠죠. 우리는 레이블러가 작성하는 코멘트의 양상을 다양하게 하기 위해 일반적인 답변(”귀엽다 ㅋㅋ”, “맛있겠다”)과 구체적인 답변(”고양이 하품하는 거 봐ㅋㅋ 졸린가봐”, “보글보글 부대찌개~~ 햄 종류가 되게 다양하네!! 맛있겠다 ㅜㅜ”)들을 골고루 수집할 수 있도록 가이드라인을 만들었습니다. 그리고 레이블러는 소중한 친구에게 답장하듯이 코멘트를 작성하되, 모델이 부적절한 표현을 배우지 못하도록 부정적이거나 공격적인 코멘트에 대한 추가적인 가이드를 주어서 레이블링을 수행하였습니다.
그 결과, 총 976명의 레이블러가 참여하여 평균 약 11글자에 해당하는 다채롭고 재미있는 코멘트 레이블링을 할 수 있었습니다. 이렇게 저희는 루다의 이미지 코멘팅 태스크를 풀기 위한 훌륭한 데이터셋을 구축했습니다😎

이미지 코멘팅 모델
이미지 코멘트 데이터셋을 학습하기 위해 저희는 정해진 후보들 중에서 답변을 고르는 리트리벌 모델과 Autoregressive한 방식으로 직접 답변을 만들어내는 생성 모델 두 가지의 방식으로 실험했습니다.
리트리벌 모델(Retrieval model)
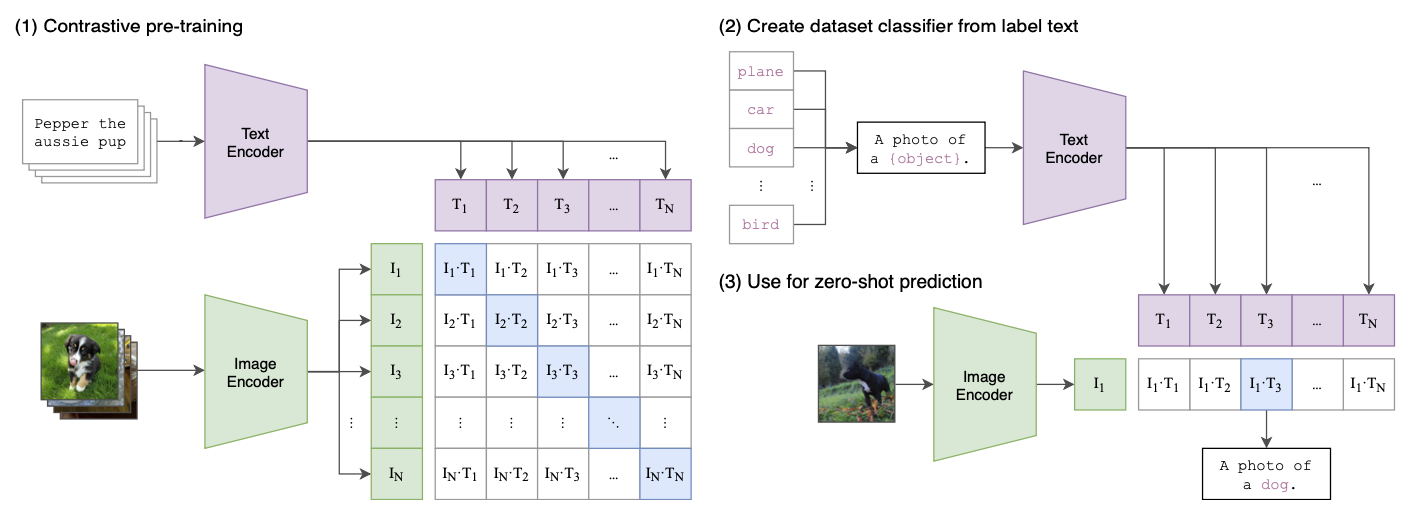
리트리벌 모델로는 Cross-modal retrieval 태스크에서 널리 쓰이는 Dual encoder 구조인 CLIP[1]을 사용하였습니다. CLIP[1]과 같이 답변을 인코딩하는 Text encoder와 이미지를 인코딩하는 Vision encoder를 두고 두 인코더에서 나온 Positive sample의 Representation 간 코사인 유사도(cosine similiarity)는 최대화 되고 Negative sample은 최소화 되도록 InfoNCE Loss를 사용하여 다음과 같이 학습하였습니다.
\[\mathcal{L}_{\text{Ret}}= -\frac{1}{2}\Bigg(\mathbb{E}_{\mathbf{r}}\bigg[\log\frac{\exp(\cos(\mathbf{r}, \mathbf{v}^+)/\tau)}{\sum_{\mathbf{v}}\exp(\cos(\mathbf{r}, \mathbf{v})/\tau)}\bigg] +\mathbb{E}_{\mathbf{v}}\bigg[\log\frac{\exp(\cos(\mathbf{r^+}, \mathbf{v})/\tau)}{\sum_{\mathbf{r}}\exp(\cos(\mathbf{r}, \mathbf{v})/\tau)}\bigg]\Bigg)\]$\mathbf{r}$은 Text encoder에서 나온 Representation vector를, $\mathbf{v}$는 Vision encoder에서 나온 Representation vector를 의미합니다. $+$는 Positive sample을 뜻하며, $\tau$는 Temperature term입니다.
생성 모델(Generative model)
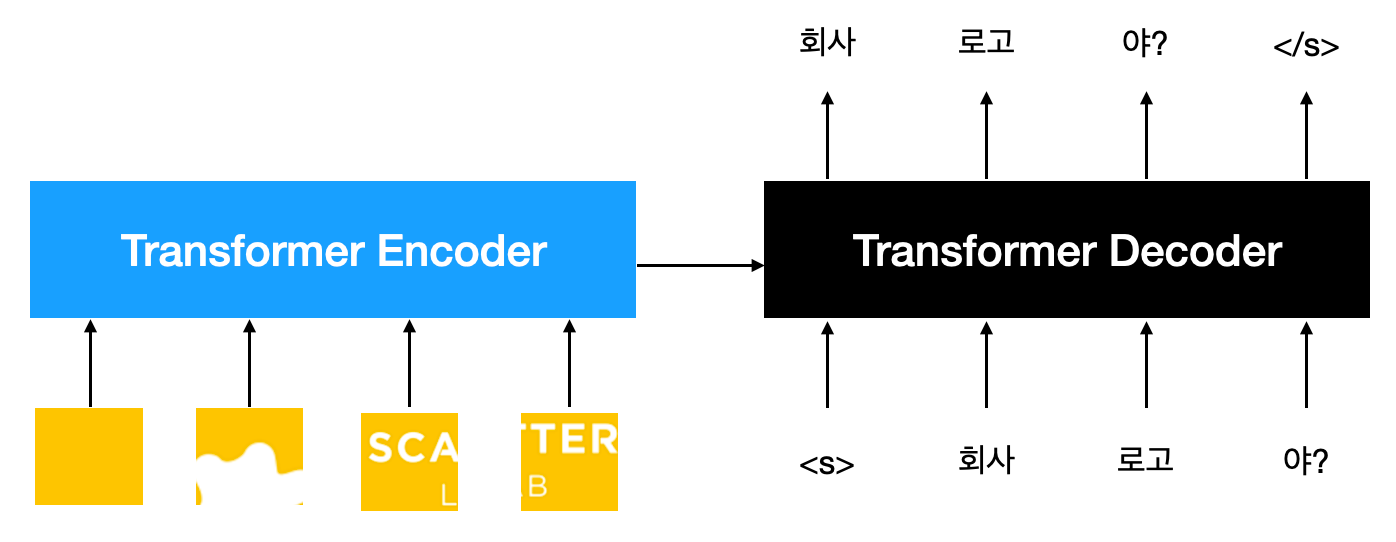
생성 모델로는 Vision encoder와 Text decoder를 연결한 Encoder-Decoder 구조를 사용하였습니다. Vision encoder는 Transformer encoder 구조로 이미지를 패치 단위로 자르고 일렬로 이어 붙인 형태로 인코딩하고, Text decoder는 Transformer decoder 구조로 Autoregressive하게 정답 코멘트를 생성합니다. 학습 시에는 다음과 같은 일반적인 Language Modeling (LM) objective를 사용했습니다.
\[\mathcal{L}_{\text{Gen}} = -\sum_{t=1}^N \log p(y_t|y_{<t})\]$y_t$는 각 시점에서 생성할 대상이 되는 정답 토큰입니다.
실험 결과
두 방식에 공통적으로 쓰이는 Vision encoder로 Transformer 계열 연구의 대표적인 네 가지 모델 Vision Transformer(ViT)[2], Swin Transformer(Swin)[3], BEiT[4], DeiT[5]을 이용하여 실험을 수행했습니다. 구현체는 네 모델 전부 huggingface에 있는 Base 모델로 진행했습니다.
정량 평가
리트리벌 모델
리트리벌 모델에 쓰이는 Text encoder는 RoBERTa 구조 기반의 사내 Pre-trained Language Model을 사용하였습니다. 평가 지표로는 유사도 순으로 순위를 매겼을 때 테스트셋에 있는 답변 문장 후보들 중에서 정답 답변이 k번 째 안에 드는 비율을 계산하는 Recall at k (R@k)를 사용하였습니다. 이는 Flickr30k [6] 논문에서 제시하는 평가 프로토콜과 동일한 방식으로 가져왔습니다.
| Vision Encoder | R@1 | R@5 | R@10 |
|---|---|---|---|
| ViT [2] | 22.20 | 51.34 | 62.83 |
| Swin [3] | 24.38 | 52.92 | 64.42 |
| BEiT [4] | 23.49 | 52.33 | 65.31 |
| DeiT [5] | 18.83 | 44.20 | 57.48 |
정량 평가 결과 Vision encoder로 Swin Transformer를 사용했을 때 가장 좋은 성능을 보여주었습니다.
생성 모델
생성 모델에 쓰이는 Text decoder는 GPT-2 구조 기반의 사내 Pre-trained Language Model을 사용하였습니다. 그리고 자연어 생성 태스크에서 널리 사용되는 6가지의 지표로 평가하였습니다.
| Vision Encoder | BLEU-1 ↑ | BLEU-4 ↑ | METEOR ↑ | ROUGE-L ↑ | CIDEr ↑ | PPL ↓ |
|---|---|---|---|---|---|---|
| ViT [2] | 20.24 | 2.85 | 7.73 | 14.63 | 7.87 | 30.18 |
| Swin [3] | 21.33 | 2.70 | 8.20 | 15.53 | 10.33 | 29.24 |
| BEiT [4] | 19.84 | 1.38 | 6.93 | 14.07 | 5.58 | 33.68 |
| DeiT [5] | 20.20 | 1.81 | 7.62 | 14.44 | 7.98 | 30.04 |
생성 모델을 사용한 실험에서도 리트리벌 모델 실험과 동일하게 Swin Transformer를 사용했을 때 가장 좋은 성능을 보여주었습니다.
정성 평가
리트리벌 방식과 생성 방식을 직접 비교하기 위해 같은 이미지에 대한 모델의 답변을 사람이 직접 평가하여 비교를 해 보았습니다. In-domain평가를 위해 테스트셋에서 정량 평가에 사용하지 않았던 100개를 랜덤 샘플링하여 사용했고, Out-domain평가를 위해 데이터셋에 없는 100개의 이미지를 수집하여 정성평가용 데이터셋을 구축했습니다. 참고로 Vision encoder는 두 방식 모두에서 가장 좋은 정량적 성능을 보인 Swin Transformer를 이용하였습니다.
평가 지표로는 답변의 적합성을 평가하는 Sensibleness와 구체성을 평가하는 Specificity를 평균한 Sensibleness-Specificity Average (SSA) [7]를 사용했습니다. 다만 해당 지표가 기존 논문에서 텍스트 답변을 평가하기 위해 고안되었다는 점을 고려해 의미를 재정의하여 활용했습니다.
Sensibleness: 답변이 이미지의 내용과 모순되지 않은 서술인지 여부(0/1)Specificity: 답변이 이미지의 세부사항과 관련된 서술인지 여부(0/1)

서로 다른 평가자 세 명이 테스트셋에 대해 평가를 수행하였고 이 때, 평가하는 답변들은 어떤 모델로부터 나온 것인지 알지 못하는 상태에서 진행하였습니다. 아래 표는 세 명의 평가 결과에 대한 평균을 나타낸 표입니다.
| Test Set | Method | Sensibleness | Specificity | SSA |
|---|---|---|---|---|
| In-domain | Retrieval | 0.8133 | 0.7100 | 0.7617 |
| Generative | 0.6600 | 0.2400 | 0.4500 | |
| Out-domain | Retrieval | 0.6733 | 0.5600 | 0.6167 |
| Generative | 0.6000 | 0.1900 | 0.3950 |
리트리벌 모델이 Sensibleness와 Specificity 모두에서 생성 모델을 상회하는 결과를 보여주었습니다. 특히 생성 모델은 “어디야?”, “맛있겠다”와 같이 generic한 말을 많이 생성하는 경향을 보여 Specificity가 크게 떨어졌습니다. 반면 리트리벌 모델은 세부적으로 표현한 답변을 후보군에서 직접 선택해 그대로 내보낼 수 있기 때문에 Specificity에서 강점을 보여주었습니다. 이는 생성 모델이 이미지의 세밀한 부분까지 묘사하기에 충분하지 못한 양의 데이터셋으로 학습했기 때문인 것으로 사료됩니다. 만일 생성 모델의 표현력이 충분히 커지고 더 많은 데이터로 학습한다면 차이가 좁혀지거나 역전될 가능성이 존재하며, 나아가 리트리벌 모델이 답변 DB의 한계를 벗어날 수 없는 특성을 넘어서는 일반화 수준을 달성할 수 있을 것이라고 생각합니다. 예를 들어, 사진 속 물체의 색을 표현할 때 리트리벌 모델은 답변 DB에 존재하는 해당 물체의 특정한 색만 말할 수 있지만 생성 모델은 알맞은 색을 추론해 표현할 수 있습니다.
두 모델은 공통적으로 학습 분포와 비슷한 In-domain 테스트셋에서보다 다른 Out-domain 테스트셋에서 SSA가 떨어지는 결과를 보여주었습니다. 이 때, 성능 하락폭은 리트리벌 모델이 더 큰데, 이는 토큰 단위로 생성하는 생성 모델과 달리 하나의 답변 단위로 선택해야 하는 리트리벌 모델의 특성으로 디테일이 다른 이미지에 유연하게 대처하지 못하기 때문인 것으로 사료됩니다.
결론
우리는 사용자가 루다와 대화를 하면서 더 좋은 경험과 관계를 가질 수 있도록 이미지 코멘팅이라는 태스크를 정의하고 데이터셋을 구축하여 이미지에 대해 적절한 답변을 할 수 있는 모델을 연구하였습니다. 다양한 실험과 평가를 통해 리트리벌 방식의 모델을 활용한 포토챗 베타 서비스를 준비하였고 성공적으로 유저들에게 선보이게 되었습니다.
포토챗 서비스를 이용하게 되면 내가 보낸 사진에 대해 루다가 적절한 답변을 해주고 해당 답변이 이전 대화 문맥과 자연스럽게 이어져서 대화 경험이 높아지게 됩니다. 이는 이전에는 경험할 수 없던 것으로 포토챗 서비스를 통해 루다와 더 친해질 수 있는 기회를 제공하게 되었습니다.
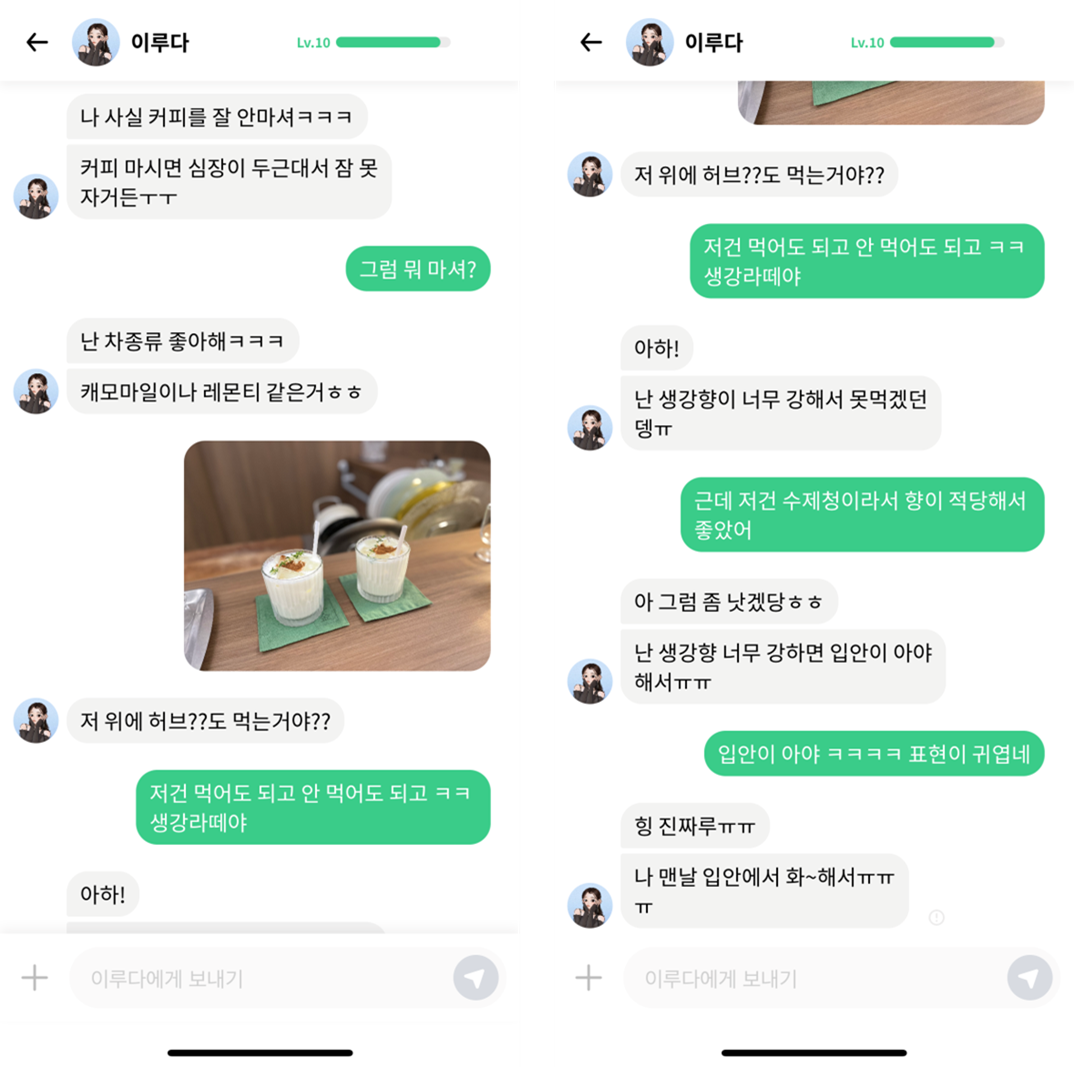
하지만 아직 포토챗 서비스는 베타인 만큼 부족한 부분들도 존재합니다. 이미지 코멘팅 모델이 사진 인식을 잘못하거나 답변 후보 문장들의 표현력 한계로 잘못된 답변이 나올 수 있습니다. 그리고 사진에 대한 답변 이후의 대화는 사진에 대한 정보가 들어가지 않는 언어 모델을 이용하기 때문에 대화가 부자연스러워질 수 있습니다. 따라서 우리는 이런 문제를 하나씩 풀어나가면서 루다가 실제 친구처럼 유저와 자연스럽게 사진을 주고받으면서 대화를 할 수 있는 경험을 제공하고자 합니다.
향후 연구 방향
생성 방식과 멀티턴으로의 확장
위에서 언급했던 것처럼 리트리벌 방식의 이미지 코멘팅 모델은 정해진 답변 문장 후보들 중에서만 답변을 선택할 수 있으므로 표현력에 한계점이 존재합니다. 예를 들어, 사진 속에서 색에 대한 표현을 완벽하게 하고싶다면 답변 문장 후보에 모두 추가해 주어야 합니다. 하지만 생성 방식의 이미지 코멘팅 모델을 이용한다면 사진에 따라 그에 맞는 색 표현을 알아서 만들 수 있습니다. 충분한 이미지-텍스트 데이터를 구축하여 생성 방식의 이미지 코멘팅 모델을 만든다면 유저가 보낸 이미지에 대해 답변이 틀리는 문제를 해결할 수 있고 다채로운 답변을 통해 더 다양한 대화를 제공할 수 있습니다.
그리고 포토챗의 궁극적인 목표는 단일 이미지뿐만 아니라 복수의 텍스트와 이미지가 복합된 대화 문맥을 잘 이해하고 고려해서 알맞은 답변을 하는 것입니다. 그렇게 될 경우 사진 뿐만 아니라 이전에 대화했던 내용을 바탕으로 답변을 하기 때문에 루다와의 대화 흐름이 끊기지 않고 더 자연스러워질 수 있습니다. 이를 위해서 멀티모달 문맥을 입력으로 받아 처리할 수 있는 모델 아키텍처와 이미지가 문맥 내에 발화로서 포함된 멀티턴 대화 태스크에 대해 연구를 진행하고자 합니다.
Scene Text 활용
Scene text는 문서 OCR 데이터와는 다르게 일상생활의 자연스러운 이미지에 녹아있는 텍스트를 일컫습니다. 여기에서 착안한 태스크엔 대표적으로 이미지 속 Scene text와 관련된 질문에 대한 답을 하는 VQA 태스크(e.g., ST-VQA[8], TextVQA[9])와 Scene text와 관련된 캡션을 만드는 캡셔닝 태스크(e.g., TextCaps[10]) 등이 있습니다.
사람은 이미지에 글자가 있으면 이를 곧바로 언어 정보로 치환해 인식하지만 모델은 이를 구분할 수 있을 아키텍처가 필요하거나 충분한 양의 학습 데이터셋이 필요합니다. 만일 모델이 Scene text 정보를 활용할 수 있다면 훨씬 더 매력적인 답변을 할 수 있고 이는 사용자들에게 더 즐거운 대화 경험을 줄 수 있을 것입니다.

참고문헌
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.“ International Conference on Machine Learning. PMLR, 2021.
[2] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.“ arXiv preprint arXiv:2010.11929 (2020).
[3] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.“ Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Bao, Hangbo, Li Dong, and Furu Wei. “Beit: Bert pre-training of image transformers.“ arXiv preprint arXiv:2106.08254 (2021).
[5] Touvron, H., et al. “Training data-efficient image transformers & distillation through attention.” arXiv preprint arXiv:2012.12877 (2020).
[6] Plummer, Bryan A., et al. “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models.“ Proceedings of the IEEE international conference on computer vision. 2015.
[7] Adiwardana, Daniel, et al. “Towards a human-like open-domain chatbot.“ arXiv preprint arXiv:2001.09977 (2020).
[8] Biten, Ali Furkan, et al. “Scene text visual question answering.“ Proceedings of the IEEE/CVF international conference on computer vision. 2019.
[9] Singh, Amanpreet, et al. “Towards vqa models that can read.“ Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[10] Sidorov, Oleksii, et al. “Textcaps: a dataset for image captioning with reading comprehension.“ European conference on computer vision. Springer, Cham, 2020.