새로운 루다를 지탱하는 모델 서빙 아키텍처 — 1편: A/B 테스트를 위한 구조 설계
'모델 추론 구조 자체'를 A/B 테스트하는 방법

핑퐁팀은 이루다 2.0을 출시하면서 복잡하게 구성되어 있는 머신러닝 추론 파이프라인을 효율적으로 만들었고, 또 모델 단위 A/B 테스트와 같은 데이터 기반의 의사결정을 지원하고자 백엔드 시스템의 구조를 다시 디자인했어요. 이번 글에서는 그 중 A/B 테스트를 위한 전체적인 구조 변경 내용을 살펴보며 왜 이렇게 구축했는지를 공유하고자 해요.
개요
핑퐁팀의 머신러닝 엔지니어링 유닛은 효율적인 사내 MLOps 환경을 구축하기 위해서 여러가지 노력들을 해왔어요. 머신러닝 워크플로우에서 나오는 결과들을 정리하고 실험의 재현성을 보존하기 위해 Model Registry와 Dataset Registry를 만들어 운영하고 있고, DataHub를 통해 사내의 다양한 무형 자산들을 한 눈에 볼 수 있게 하고 있답니다. 그리고 그것들을 생산해내는 파이프라인들 역시 Apache Beam이나 Airflow 등의 컴포넌트를 사용해서 파이프라인을 표준화하고 가시성을 극대화하여 운영하고 있어요.
최근에는 이런 컴포넌트들을 모두 한데 묶어 Continual Learning Pipeline을 구축하고 있으며, 이를 통해 지속적으로 들어오는 데이터를 주기적으로 정제해서 모델의 성능이 더욱 나아지게 학습할 수 있도록 구현하고 있어요. 또한 연구 환경에서 할 수 있는 다양한 형태의 자동화들을 검토하고, 끊임없이 도입해오면서 효율적으로 연구할 수 있도록 기반을 다지고 있어요.
이러한 노력들을 통해 이제 연구 환경은 나름 준비가 완료되었다고 할 수 있겠으나, 모델 서빙은 그렇지 않았어요.
모델 서빙 아키텍처는 어떤 걸 고려해야 할까?
빠르게 변화하는 아키텍처의 표준화된 관리
설명한 Continual Learning Pipeline의 최종 결과물이 배포할 모델인 만큼, 자동화 역시 모델의 배포 과정까지 다루고 있어야 할 거예요. 하지만 지금까지 루다는 정말 많은 기술 업데이트를 빠르게 진행하던 서비스여서 아키텍처가 표준화되기 힘들었어요.
특히, 모델의 아키텍처 자체가 바뀌는 상황이 잦았어요. 작게는 대화의 임베딩을 뽑는 모델 아키텍처가 달라져서 추가적인 최적화를 해야 하는 경우도 있었고, 크게는 아예 생성 모델로 아키텍처가 변경되면서 새로운 형태의 최적화 전략을 고민하는 상황도 있었죠.
이렇다보니 엔지니어들이 배포 대상이 되는 모델을 배포 환경에 맞춰서 직접 서버화하고 배포하는 단계가 매번 포함되어야 했고, 그래서 매끄럽게 자동화되어 통일된 형태로 배포할 수 있도록 만들고 싶었어요.
이 문제를 어떻게 해결했는지는 다른 글에서 자세히 다뤄볼게요.
A/B 테스트의 필요성
배포에 관련한 문제보다 더 큰 것은 사용자에 대한 해석이었어요. 루다의 서비스 경험의 매우 큰 부분을 모델이 담당하고 있기 때문에 모델을 변경하게 되면 서비스의 Metric에도 영향을 주게 돼요. 그럼 모델을 업데이트할 때마다 어떤 것들이 달라졌는지 명확하게 비교하고 모니터링할 수 있어야 할 텐데, 모델 아키텍처 자체의 변화가 잦다보니 그걸 적절하게 모니터링하고 분석할 수 있는 도구가 정착되기 쉽지 않았어요.
그래서 가장 중요했던 아키텍처 요구 사항 중 하나가 “빠르게 변화하는 아키텍처에 대한 A/B 테스트를 높은 빈도로 쉽게 할 수 있는 시스템”이었어요. 여러가지 형태의 모델 아키텍처에 대해서 사용자 군을 나누어 트래픽을 흘려주고, 각 군의 결과를 로그로 명확하게 정리해서 관리할 수 있게 만들어야 했어요. 로그로 찍힌 결과는 명확하게 분석되어 각 군의 통계로 추출할 수 있어야 했고, 그 데이터를 근거로 모델 업데이트에 대한 의사결정을 수행할 수 있게 해야 했죠.
이게 가능하려면 우선 백엔드와 인프라 아키텍처 단에서부터 그 고려 사항들을 다루어야 했어요. 이 글에서는 이 문제를 어떻게 해결할 수 있었는지 자세하게 이야기해보려고 해요.
A/B 테스트를 위한 고려 사항은 두 가지로 나눠지는데, (1) 모델 추론 구조 자체에 대한 A/B 테스트가 매끄럽게 가능하기 위한 형태를 만드는 과정과 (2) 그 구조 위에서 실제 A/B 테스트 시스템을 구현하고 적용하는 과정이 있을 것 같아요. 이 글에서는 첫 번째에 대해 다뤄보려고 하고, 어떻게 구현했고 운영했는지는 다음 글에서 자세하게 소개할게요!
“모델 추론 구조 자체”를 A/B 테스트한다고? 🤔
맞아요. 저희 팀이 서빙하는 챗봇 형태의 서비스는 다양한 구조를 가지고 있거든요. 대표적으로 Retrieval 기반 구조와 Generation 기반 구조가 있어요.
간단하게 설명하자면, Retrieval 기반 구조는 Embedding 계산, 후보의 Retrieval, 결과에 대한 Reranking으로 이루어지는 과정이에요. 사용자가 나누던 대화에 대한 임베딩을 뽑고, 가장 적절할 것으로 보이는 답변을 몇 개 뽑아온 후, 그 답변 중 가장 나은 답변을 하나 잘 골라서 사용자에게 반환하는 방식이죠. 이 구조가 배포되려면 임베딩 모델 서버, 답변 후보를 위한 ANN 추론 서버, 마지막 랭킹을 위한 랭킹 모델 서버를 배포하고 순차적으로 요청을 보내서 처리해야 할 거예요.
그에 비해 Generation 기반 구조는 생성 모델로 여러 답변 후보를 생성하는 과정과 그 중 하나를 잘 뽑는 Reranking 과정으로만 이루어져 있어요. 서버 역시 생성 모델 서버와 랭킹 모델 서버만 필요하죠.
이런 구조들을 상황과 기획에 맞게 골라서 다양한 방향으로 튜닝하고 배포하고 있었어요. 그 과정에서 A/B 테스트를 수행하려면, 그 형태가 크게 아래의 두 가지 정도 있을 것 같아요.
- 구조는 같지만, 모델이나 Configuration의 변경으로 인한 사용자 경험 변화를 측정하고 싶은 경우
- 아예 다른 구조 사이에서 어느 정도의 사용자 경험 변화가 있을지를 측정하고 싶은 경우
두 번째 요구 사항 때문에 아예 다른 구조와의 비교가 가능하게 만들어야 했고, 그렇기에 ‘모델 추론 구조 자체’를 A/B 테스트한다고 했던 거죠.
고려할 게 많을 것 같은데…
아무래도 그렇죠. 일단 가장 큰 문제는 비용이었어요. 같은 구조로 된 아키텍처인데 특정 서버의 Config 하나가 다르다고 똑같은 구조를 그대로 다 띄워서 트래픽을 분산시키려면, 똑같은 모델을 두 개 이상 띄우는 일도 발생할 수 있겠죠? 이러면 비용이 과도하게 커지는게, 모델 서버는 상대적으로 요금이 비싼 GPU나 IPU들을 중심으로 뜨게 되기도 하고, 완전히 똑같은 대화를 하는 사용자는 없기 때문에 매번 새로 추론을 해야 해서 캐싱 전략을 사용할 수도 없었어요. 과도한 비용이 나가지 않도록 모델 서버를 배포할 때는 항상 주의해야 했어요.
비용 말고도, 자동화 수준 역시 고려해야 했어요. 기존처럼 엔지니어가 세세한 배포 과정에 일일이 관여하면 기민하게 A/B 테스트를 진행할 수 없거든요. 핑퐁팀은 Helm Chart를 사용해서 모델 서버들과 비즈니스 로직 서버를 한 데 모아 띄우는 구조인데, A/B 테스트 때문에 이 차트를 요구에 맞게 매번 수정하거나 Subchart로 분리하는 등의 일을 매번 해야 하면 매우 오랜 시간과 노력이 들어요.
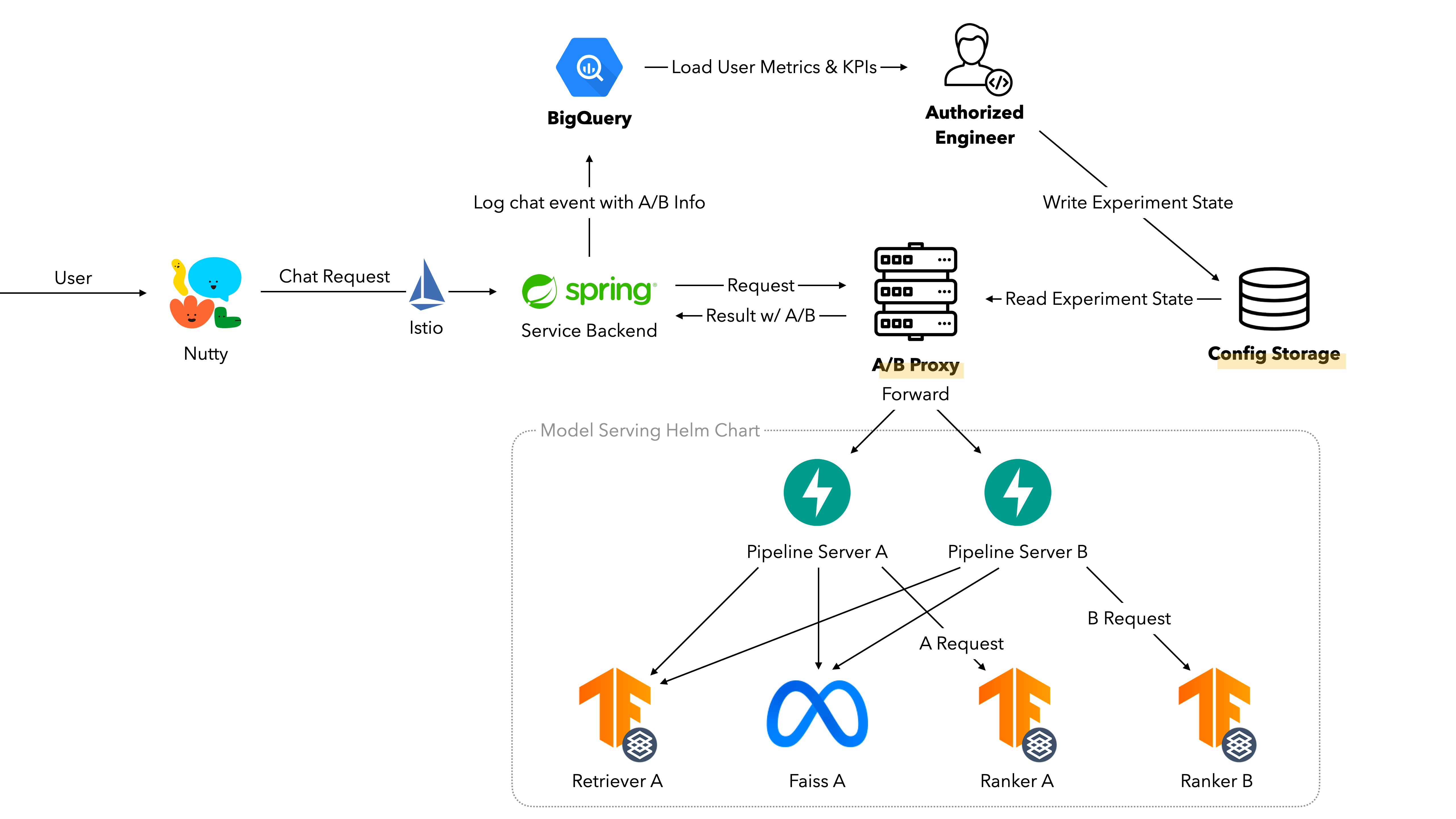
그래서 A/B 테스트 ‘시스템’이라고 생각하고 설계해야 했어요. 실험이 정의되고 진행되는 과정을 어느 정도 시스템화해서 간단한 설정 만으로 실험을 진행할 수 있게 하고 싶었고, 복잡하고 다양한 형태의 모델 구조가 주어지더라도 손쉽게 배포할 수 있었으면 좋겠다고 생각했죠. 그 과정에서 비용도 당연히 고려되어야 했고요. 저희가 적용한 방법들을 하나하나 소개해 볼게요.
1. 서비스 백엔드가 모델 업데이트를 신경쓰지 않게 하자
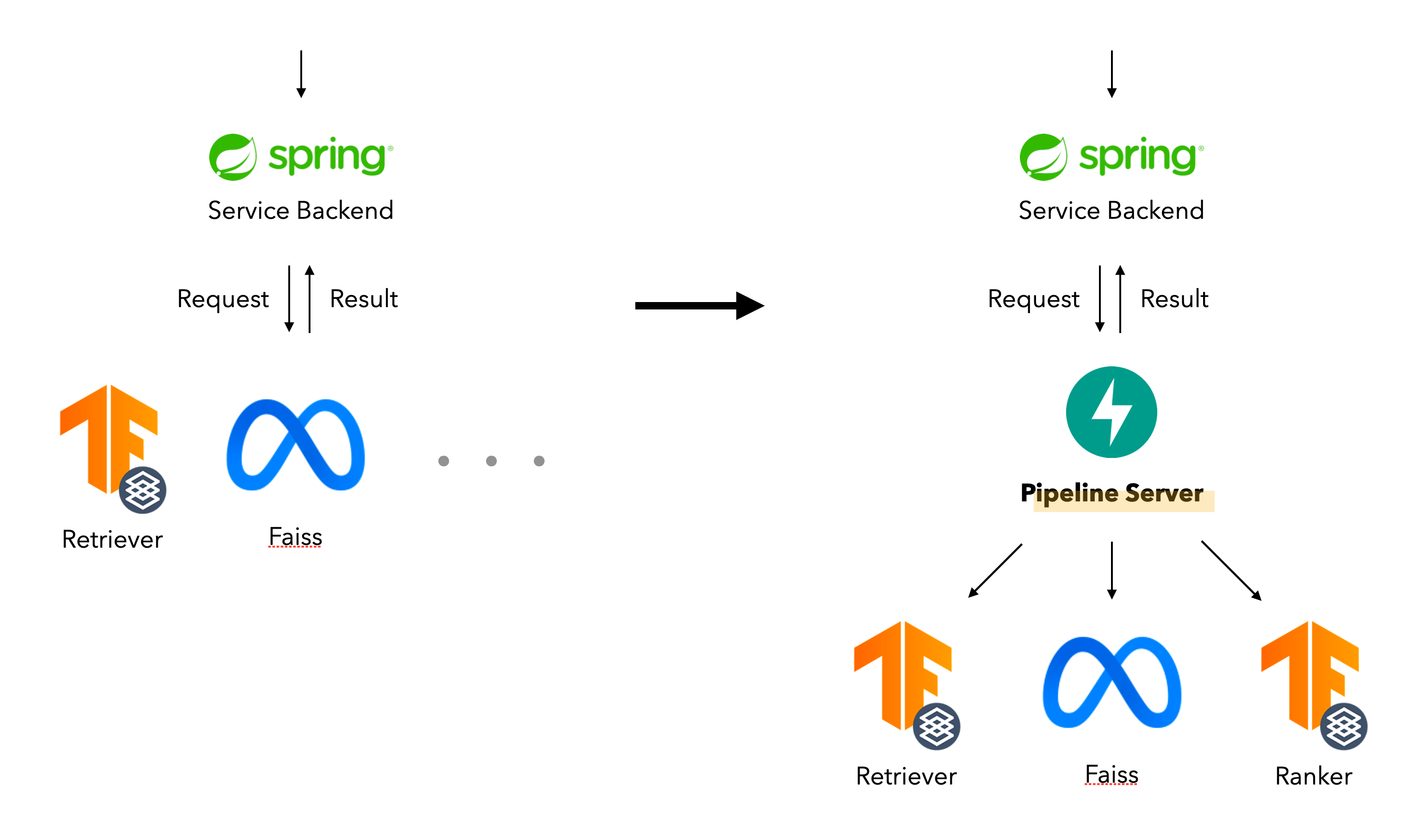
기존의 서빙 구조는 이루다 서비스 자체의 백엔드 서버가 각 모델의 Endpoint를 호출해서 답변을 생성해내는 형태였어요. 여기에서 첫 번째 문제가 있었는데, 서비스 자체의 비즈니스 로직을 담고 있는 서버였음에도 불구하고 새로운 아키텍처 구조가 나올 때마다 추론 순서나 모델 인터페이스가 달라지면 계속 업데이트되었어야 했다는 거예요. 그러면 업데이트 한 번 할 때마다 백엔드 엔지니어 조직과 머신러닝 엔지니어 조직 사이에 많은 커뮤니케이션이 발생하게 되고, 결국 A/B 테스트를 시작하거나 끝내는 과정이 너무 오래 걸리게 될 것 같았어요.
그래서 선택한 첫 번째 구조 수정은 이루다 서비스 백엔드와 모델 파이프라인 서버를 분리하는 것이었어요. 모델 파이프라인 서버는 추론 파이프라인이 추상화되어있어 다양한 모델 추론 파이프라인을 추상화된 구조에 맞춰 구현하고, 외부에서 Config를 넣어주면 특정 파이프라인으로 추론할 수 있도록 구성했어요.
이렇게 하니까 서비스 입장에서는 파이프라인 서버의 특정 Endpoint만 알고 있으면 모델 추론을 명령할 수 있고, 모델 아키텍처나 추론 순서를 수정해야 할 때면 모델 파이프라인 서버만 롤링 업데이트해주면 되니 백엔드 엔지니어들과의 불필요한 소통도 줄어들 수 있었어요.
또, 모델이나 Config만 변경된 상태에서 실험을 할 때는 파이프라인 서버만 여러 개 띄우고 공통 모델 서버는 공유한 상태에서 서비스가 이루어질 수 있으니 불필요한 인프라 비용 역시 발생하지 않도록 할 수 있었어요.
2. 서비스 백엔드가 A/B 테스트에도 신경쓰지 않게 하자
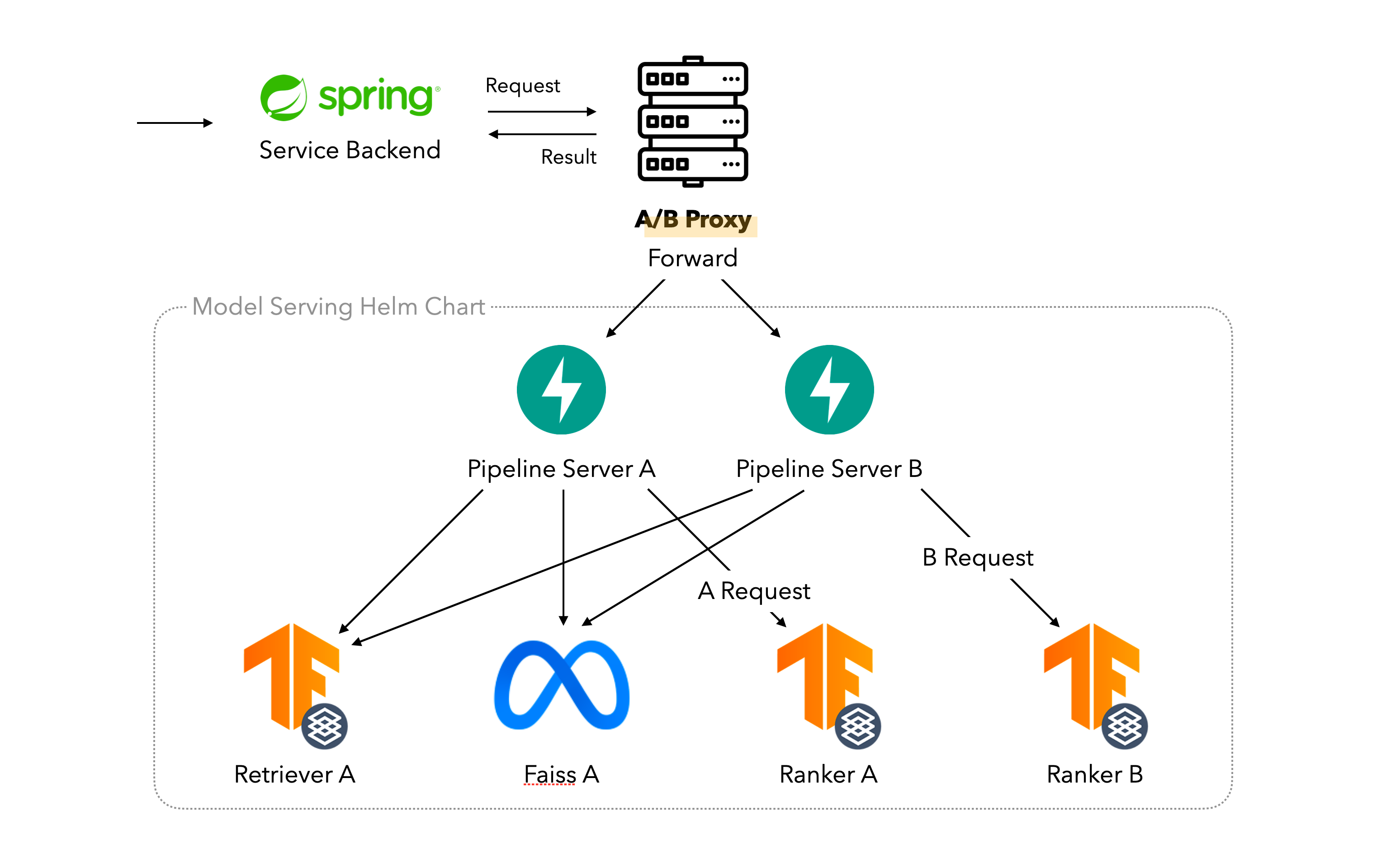
다만 여전히 문제는 있었는데, A/B 테스트가 시작되거나 끝날 때 이루다 서비스 백엔드에서 파이프라인 서버의 Endpoint로 호출하는 비율을 계산해서 각각 다른 서버로 흘려줘야 하다 보니 관련 구현이 계속 서비스 백엔드에 남아있어야 했던 것이었어요. 그러면 A/B 테스트가 시작되거나 끝날 때마다 실험 디테일들과 이에 따른 Endpoint를 반영해주어야 하니 서비스 백엔드 재배포는 여전히 필연적이었죠.
그래서 모델 파이프라인 서버와 서비스 백엔드 사이에 프록시 서버를 하나 두기로 했어요. 그리고 그 프록시 서버가 현재 실험 상황에 따라서 요청을 군으로 구별해서 해당하는 파이프라인 서버로 중계하는 역할을 담당하도록 했습니다.
이렇게 하면 서비스 백엔드는 프록시 서버의 Endpoint 하나만 알면 되고, A/B 테스트에 관계없이 항상 그 Endpoint로만 요청을 보내도록 할 수 있었어요. 어차피 진행 중인 실험에 따라 해당 요청을 식별하는 것은 프록시 서버이니, 더 이상 A/B 테스트가 필요할 때 서비스 백엔드를 변경할 필요가 없도록 구성할 수 있었죠. 이로써 ML 조직이 독립적으로 ML 모델과 관련한 배포와 A/B 테스트를 계획하고 실행할 수 있게 되었어요. 🎉
3. Config 하나로 모델 인프라 전체의 실험을 제어하게 하자
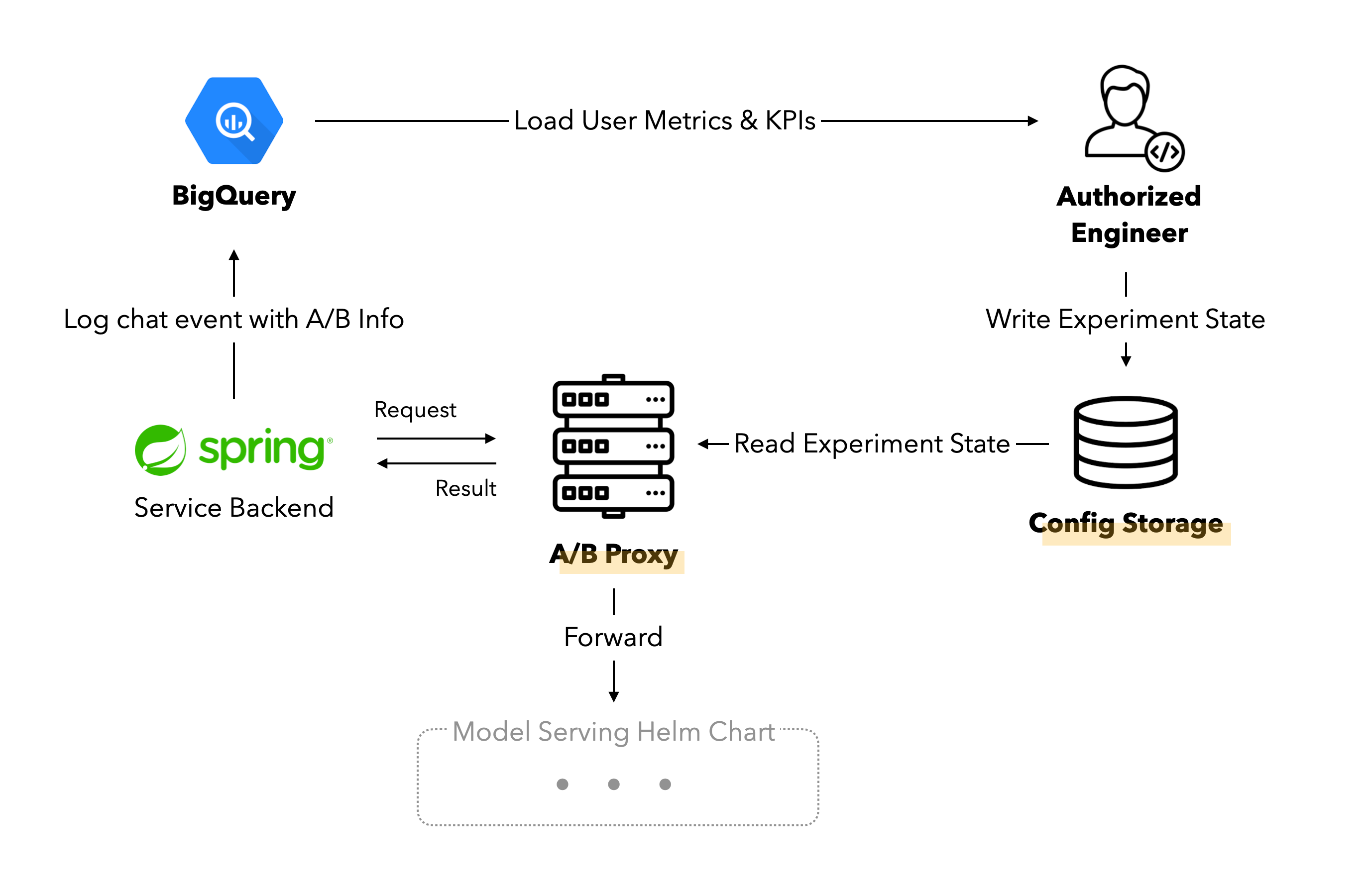
이제 실행을 편리하고 빠르게만 할 수 있으면 될 테니, 엔지니어가 실험 시작을 선언했을 때 이미 수 많은 숫자로 떠있는 프록시 서버들이 특정 실험 설정으로 변화할 수 있도록 시그널을 주도록 하면 될 거예요.
저희는 여기에 ConfigMap을 사용했습니다. Kubernetes Resource로써 실험 설정이 존재하고, 이 값이 바뀌면 프록시 서버들이 모두 동시에 반응하도록 한 것이죠. K8s API에는 특정 Resource의 변경 사항을 감시할 수 있는 API가 있습니다. 프록시 서버가 ConfigMap 하나에 watch 를 전부 걸어두고, ConfigMap에서 변경 이벤트가 발생하는 즉시 해당 내용을 수신해서 자신의 라우팅을 변경하도록 할 수 있는 것이죠. 혹시나 Watch가 많이 걸리면 시스템 성능에 영향을 줄까 싶어 부하 테스트를 수행해보았는데, 전혀 영향이 없는 것을 보고 최종적으로 결정했습니다.
이제 엔지니어가 유저 군을 나누는 방법과 군별 유저 비율과 모델 파이프라인 서버 Endpoint 등을 세세하고도 빠르게 정의할 수 있으며, ConfigMap에 edit 명령을 수행하는 것으로 전체 인프라를 제어해서 A/B 테스트를 시작하거나 끝낼 수 있게 되었고, 이것으로 빠르고 정확하게 복잡한 내용의 A/B 테스트를 수행할 수 있는 모든 조건을 달성했습니다.
핑퐁팀은 ConfigMap의 관리와 배포를 위해 Argo CD를 사용하고 있으며, A/B 테스트를 시작하거나 끝낼 때 PR Review를 통해 최종적으로 테스트의 상세 내용을 검증하고 실험을 시작하고 있어요.
마치며
이 글에서는 모델 구조 자체에 대해 A/B 테스트가 가능한 인프라 구조를 어떻게 하면 잘 세팅할 수 있을까를 고민하는 과정을 공유했어요. 저희는 이 글 말고도 저희가 이루다 2.0 서빙 시스템을 개선하기 위해서 수행했던 다양한 노력들을 시리즈로 작성할 예정입니다. 아래와 같은 내용들이 들어갈 것 같아요.
- 이 글에서 설명한 A/B 테스트 아키텍처를 실제로 구현해서 적용하고 실험을 진행하는 과정
- 생성 모델을 서빙하기 위한 최적화 방법론과 서비스에 반영한 결과
- 모델 서버들을 매끄럽게 배포하고 모니터링하기 위한 인프라 아키텍처와 DevOps의 구축
핑퐁팀은 문제의 본질을 깊게 고민하고 그 문제를 해결할 수 있는 최적의 해답을 도출해내려는 열정을 가득 품고 있고, 그래서 항상 이런 문제에 대해 고민할 수 있는 기회가 열려 있습니다. 저희와 함께 고민하며 이런 문제들을 풀어보고 싶으신 분들은 채용 공고를 참조해주세요!