새로운 루다를 지탱하는 모델 서빙 아키텍처 — 3편: 안정적인 LLM 서비스를 위한 서빙 최적화 기법
LLM 서빙을 위한 다양한 최적화 기법과 그 효과를 검증하기 위한 부하 테스트 방법론


많은 기업들이 생성AI 시장에 뛰어들기 위해서 각자의 LLM 을 만들기 위해 온 열정을 쏟아붓고 있습니다. 특히 ChatGPT 출시 이후 다양한 종류와 크기의 LLM 들이 만들어 지고 있는데요. 하지만 모든 모델들이 공통적으로 서빙쪽에서 문제를 겪고 있습니다. LLM 을 학습하는 비용 보다, LLM 을 지속적으로 서빙하기 위해서 더 많은 돈(GPU 서버 비용)이 필요로 하기 때문입니다. 역사상 가장 빠르게 성장한 서비스인 ChatGPT 는 하루에 약 $700,000(한화 10억) 이상을 서버 비용으로 사용한다는 예측도 나와있어 얼마나 많은 비용이 필요로 한지 체감할 수 있습니다.
스캐터랩도 더 놀라운 대화형 AI 를 만들기 위해서 저희만의 LLM 을 만들어 오고 있는데요. 저희 역시 더 좋은 성능의 모델을 사용하기 위해 모델크기를 점점 키우면서 LLM 서빙에 필요로 하는 GPU 비용이 기하급수적으로 증가하고 있는 상황이었습니다. 앞으로 모델 크기가 더 커질 일만 남은 상황에서 적정한 가격으로 모델을 서비스하기 위해서는 LLM 비용 최적화가 필수적이라고 판단하였고, 스캐터랩 ML Engineering 팀은 ChatGPT 가 출시되기 이전인 22년 상반기 부터 LLM 서빙 최적화를 연구해 왔습니다. 이번 블로그에서는 LLM 최적화에 대한 배경지식들을 간략하게 소개해 드리고, 저희가 지금까지 진행한 LLM 서빙 최적화 실험 결과들을 공유해 드리려고 합니다.
LLM 서빙 최적화 기법
우선 LLM 서빙을 최적화 할 수 있는 대표적인 최적화 기법들에 대해서 알아보도록 하겠습니다. 참고로 이번 블로그에서는 모델의 성능을 동일하게 유지하면서 적용할 수 있는 서빙 최적화 방법에 대해서만 다룹니다. 따라서 Low Precision Quantization(INT8, INT4, FP8) 이나 Distillation 에 대해서는 다루지 않습니다.
GPU Kernel Fusion
GPU는 Kernel 단위로 연산이 이루어 지게 됩니다. 예를 들어 우리가 두개의 텐서를 서로 MatMul 후에 Add 하는 연산을 수행할 때, Matmul Kernel, Add Kernel 이렇게 두개의 커널을 실행하게 됩니다. 이때 두개의 커널을 실행하는 대신 두개의 커널을 MatmulAdd 라는 하나의 커널로 합쳐 실행하는 것을 Kernel Fusion 이라고 합니다. Matmul Kernel 의 결과를 메모리에 저장하고 Add Kernel 이 다시 메모리에 저장된 결과를 불러와 연산에 사용해야 하는 overhead 가 발생하는데, kernel 내에서 sharedmemory 나 register 를 공유해 이러한 overhead 를 제거할 수 있습니다. Kernel Fusion 은 주어진 연산 그래프가 있을 때 잘 알려진 패턴이 보이면 이를 Fused 된 Kernel 로 교체하여 성능 최적화를 만들어냅니다. 이 기법은 학습/평가시에 모두 적용할 수 있음으로 딥러닝 모델 사용시에 매우 유효한 최적화 전략 중 하나입니다.
Kernel Fusion을 수행하는 방법으로는 직접 Kernel을 CUDA C++ 로 작성하는 방법이 있고, TensorRT 와 같이 자동으로 Kernel Fusion을 지원하는 툴들을 이용하여 학습된 모델을 최적화 하는 방법도 있습니다.
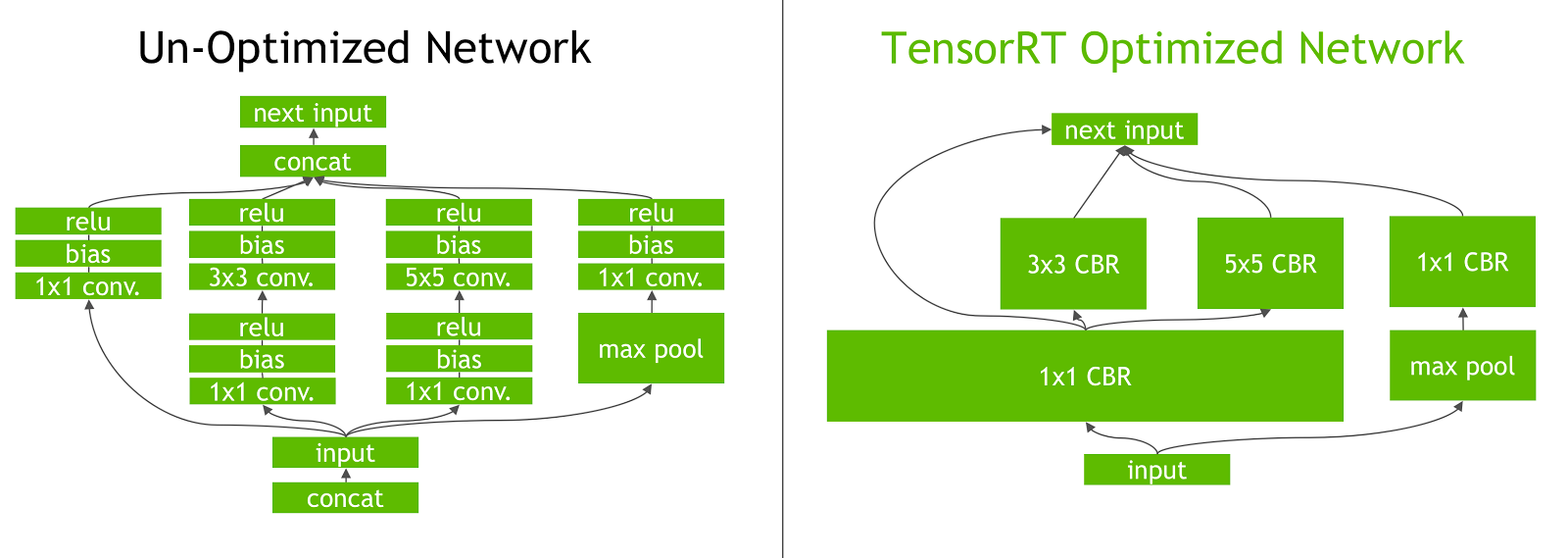
Early Stopping
생성모델을 서빙하는 경우 대부분 max-length / min-length 를 설정하여 원하는 길이 분포로 결과가 생성되는 것을 유도합니다. 하지만 항상 모든 문장이 max-length 길이만으로 이루어지지 않기 때문에 <EOS>와 같은 정지 토큰이 생성되면 생성이 완료되었다고 판단하게 됩니다. Early Stopping 이란 문장 생성 추론시에 <EOS>와 같은 마무리 토큰이 생성되면 더 이상 다음 토큰을 생성을 하지 않도록 하는 기능입니다. 즉 연산의 낭비를 막아주는 최적화 기법 입니다.
어떻게 보면 당연한 기법처럼 보이지만, Kernel Fusion 과 같이 여러 연산들을 묶는 입장에서는 꽤나 까다로운 기능입니다. 여러 연속된 연산을 합칠수록 성능의 이점이 늘어나기 때문에 최대한 Fixed 된 형태의 추론 그래프를 만들어야 하지만, Early Stopping 이 필요로 하게 된다면 매 토큰 생성시 마다 Early Stopping 조건에 만족했는지 체크하고 이에 따라서 생성을 계속할지 / 중지할지 결정하는 분기 처리가 필요로 하기 때문입니다. 때문에 TensorRT 와 같이 ONNX Graph 를 입력으로 받고, 이를 최적화 된 Graph 로 반환하는 툴에서는 잘 작동하지 않는 기능입니다. 주로 Pytorch / JAX 와 같이 Dynamic Graph 를 지원하거나 아니면 아예 커널 자체를 Custom C++ 로 작성하여 유연한 분기 처리가 가능한 경우에 사용할 수 있습니다.
Key/Value Caching
LLM 은 주어진 Context 뒤에 한토큰 한토큰을 이어서 생성하는 방식으로 추론을 진행합니다. 이때 Auto Regressive 모델에서의 Self-Attention 특성상 앞 부분의 Context 의 Key, Value 값은 토큰이 새로 생성되더라도 변하지 않는데요. 이를 활용하여 앞 부분에 연산해 둔 Key, Value 를 토큰 생성이 끝날때 까지 Caching 하여 중복된 연산을 막는 기법입니다. 새로운 토큰에 대해 생성을 완료하고, 해당 토큰에 대한 Key, Value 값이 계산 되면 기존 Key/Value Cache 에 새로운 Key/Value 값을 concat 하여 다시 저장하게 됩니다. Huggingface 코드에서 .generate(..., use_cache=True) 를 통해 Key/Value Caching을 사용할 수 있습니다.
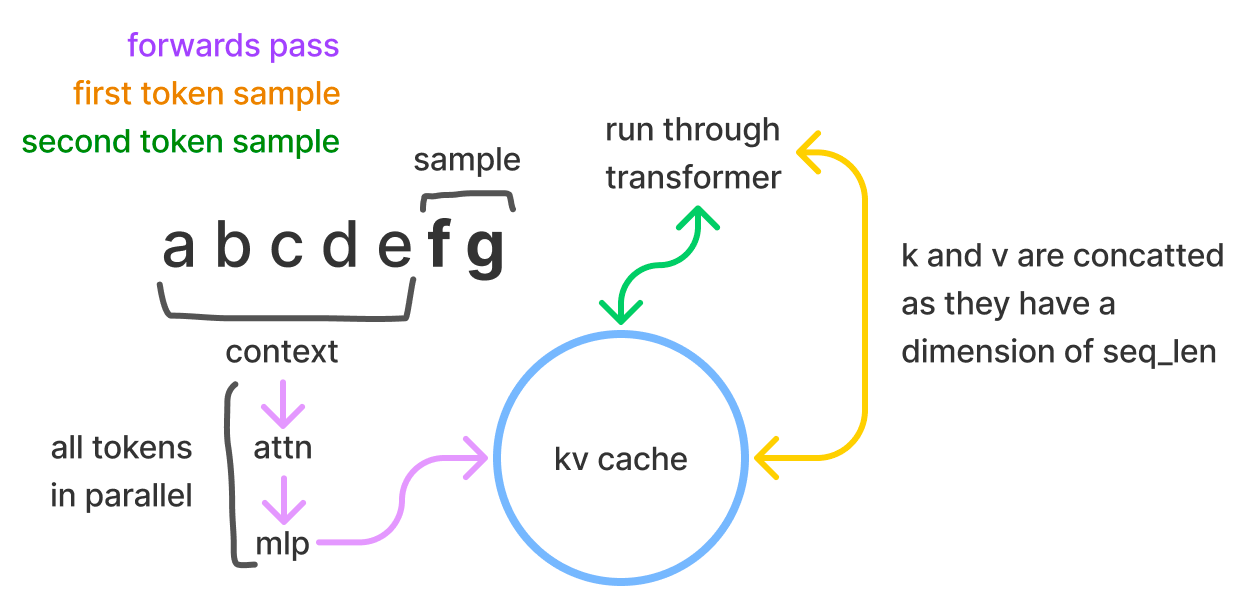
Flash Attention
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness 에서 제안된 GPU 최적화 기법으로 LLM의 Transformer 연산시 발생하는 Memory Throughput Bottleneck 을 해결한 기법입니다. 간략하게 요약하자면, 대형 LLM 모델의 Transformer Self Attention 연산시에 주로 Memory Throughput 이 낮아 Tensor Core 의 연산 효율이 떨어지는 문제가 있음을 확인하였습니다. 저자들은 이를 해결하기 위해서 연산을 중복해서 실행하더라도 최대한 HBM과 SRAM 사이의 IO를 최소화 하여 기존보다 약 2배 이상 Latency 를 줄이는 기법인 FlashAttention 을 발표하였습니다.
이 기법은 모델의 성능에 전혀 영향을 주지 않고 단순 HW Level 의 Bottleneck 을 SW 기법으로 해결한 방법이기 때문에 FasterTransformer, Composer 등 많은 툴에서 이 기법을 활용하고 있습니다. 보다 더 많은 사용 케이스들을 확인해 보고 싶으시면 다음 링크(HazyResearch/flash-attention) 를 참조해 보시면 좋을 것 같습니다!
Dynamic Batching
실제 REST API 를 구성하고 사용자의 입력을 받으면 시간차이를 두고 각각 다른 생성 요청들이 들어오게 됩니다. 이때 각 요청 마다 단일 추론을 하게 된다면 GPU 의 Tensor Core Utilization 을 100% 사용할 수 없습니다. 때문에 여러 개의 입력을 한 개의 Batch 로 묶어 최대한 Tensor Core 의 Utilization 을 높이는 방법이 필요로 하고, 이때 사용하는 기법이 Dynamic Batching 입니다. 다만 Batch 의 크기를 무한이 늘린다고 계속 Utilization 이 늘어나는 것이 아니고, GPU 의 사용률이 이미 충분히 높아진 시점 부터는 Latency 가 증가하게 됩니다. 때문에 서비스의 요구조건에 맞게 최대 batch_size 와 batching 을 하기 위해서 기다리는 최대 시간을 적절하게 설정하는 작업이 필요로 합니다. 이러한 Dynamic Batching 기능은 NVIDIA Triton 이나 Tensorflow Serving 의 가장 대표적인 기능으로 LLM 이 아니더라도 실시간 ML 서비스에서 많이 사용되고 있습니다.
하지만 Dynamic Batching 을 하게 되면 자연스럽게 비효율적인 상황을 마주하게 됩니다. 예를 들어 Context 의 길이가 10인 입력과 길이가 256인 입력이 동시에 하나의 Batch 로 묶이게 되는 상황처럼 Batch 내의 길이가 매우 다양한 경우엔 가장 짧거나 가장 긴 입력 시퀀스에 맞게 padding 또는 attention mask 를 적용해야 하기 때문에 연산의 비효율이 발생하게 됩니다. HyperClova 서빙 최적화 포인트 글을 보면 보다 자세한 이슈들을 확인해 볼 수 있습니다.
또한 LLM 에서는 출력토큰을 한 번에 하나씩 생성해야 하기 때문에, 요청 하나를 처리하는데 드는 Latency 가 초 단위인 것이 일반적입니다. 특정 요청이 batching 을 위해 기다리는 최대 시간 이후에 시스템에 도착해서 Batch 에 함께 묶이지 못한 경우, 해당 요청은 수 초를 기다려서 현재 Batch 가 수행이 모두 끝난 후에야 연산을 시작할 수 있습니다.
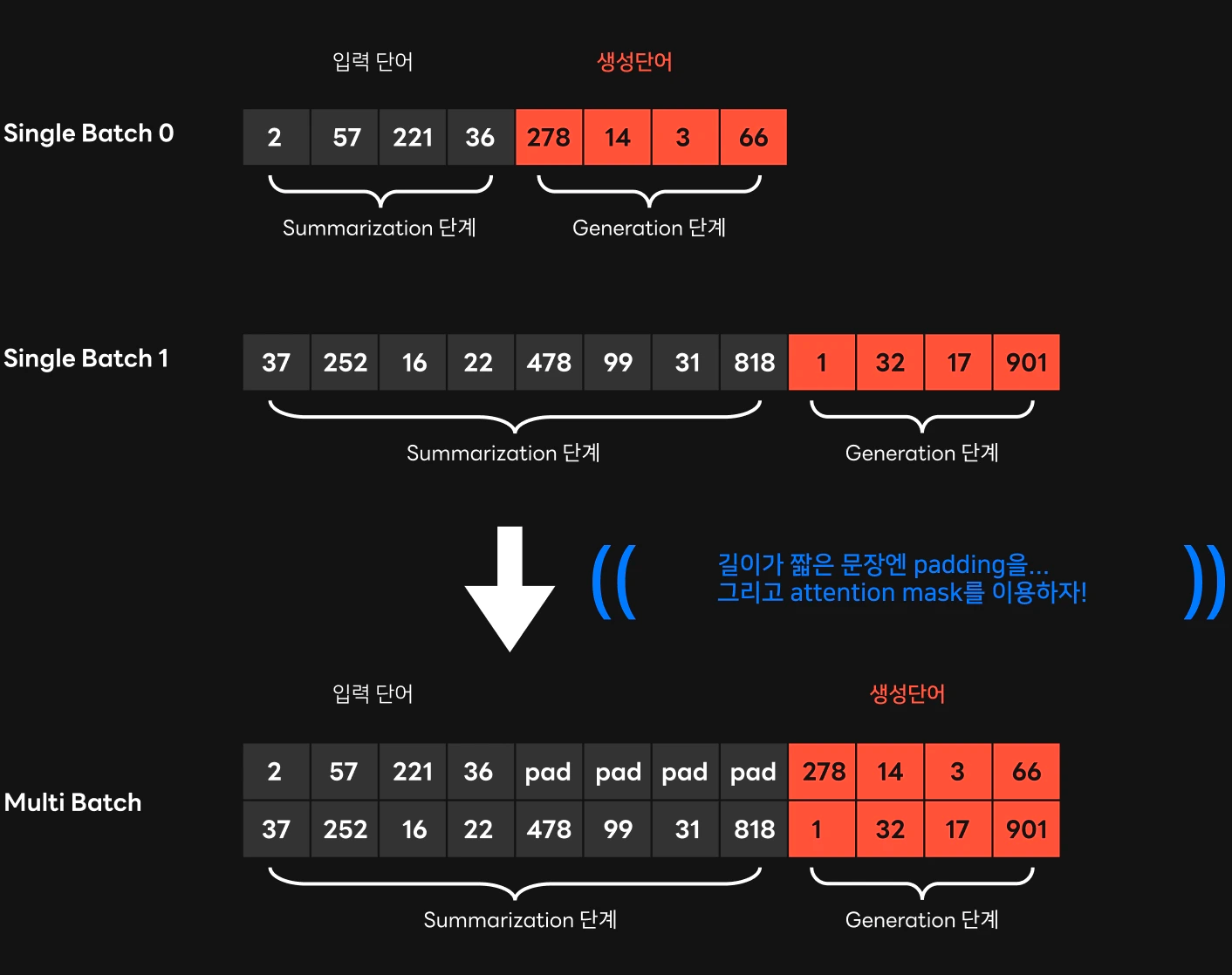
Iteration Batching
위와 같은 Dynamic Batching 의 문제점을 해결하기 위해서 FriendliAI 는 Iteration-level Scheduling 이라는 새로운 기술을 제안하였습니다. Iteration-level Scheduling 은 Batch 로 묶인 요청들에서 출력 토큰이 하나 생성될 때 마다 새로운 수신한 사용자 요청이 있는지 체크하고, 새 요청을 Batch 에 바로 포함시킬 수 있어서 대기 시간이 최소화 됩니다. 또한 Batch 내에서 생성이 끝난 요청이 발생한 경우 해당 요청을 즉시 반환함으로서 최소한의 연산이 이루어질 수 있도록 구현하였습니다. 다만 해당 기술은 특허로 보호되어 있어, 타사에서 직접 구현하여 사용하는 것은 불가하다는 한계점을 지니고 있습니다. 보다 자세한 내용은 FriendliAI 의 Periflow 블로그 글 을 참고하면 좋을 것 같습니다.
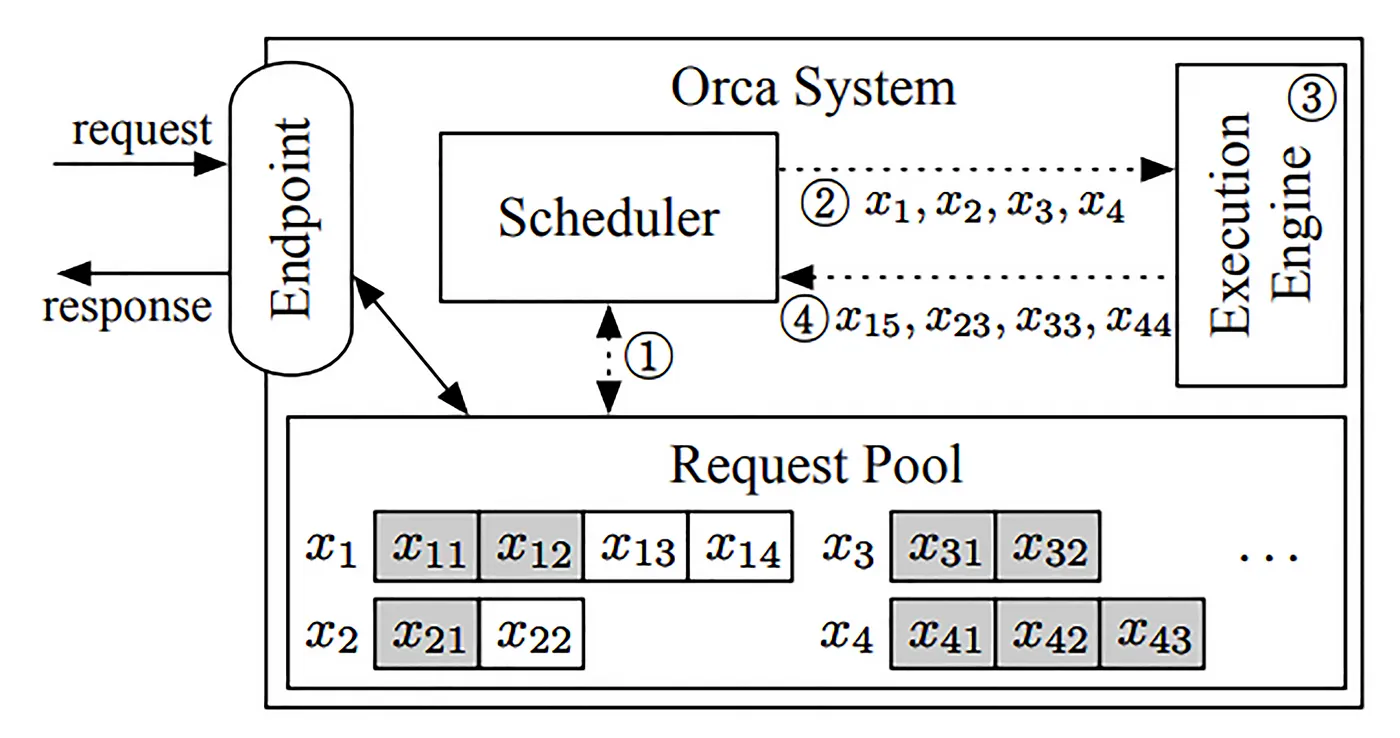
LLM 서빙 방법론
LLM을 학습할때에는 어떻게 해야 더 커다란 모델을, 더 많은 데이터를 GPU에 올려서 빠르게 학습할 수 있을까에 대해서 고민했다면, LLM을 서빙할때는 1)적은 비용으로 2)많은 사용자의 요청을 3)빠르게 서빙할 수 있는 방법들에 대해서 고민하게 됩니다. 그렇기에 앞선 LLM 성능 최적화 기법 소개절에서는 LLM 모델을 어떻게 해야 빠르게 추론할 수 있도록 아키텍처를 최적화할 수 있을지에 대해 소개드렸습니다.
앞서 소개드린 방법들과 같이 모델 아키텍처를 최적화하는 방법들도 있겠지만, 하드웨어 가속기를 활용하여 모델 추론 자체를 빠르게 하는 방법들도 있습니다. 이번 절에서는 실제로 LLM 모델을 Production 환경에 배포하기 위해 어떤 하드웨어 가속기들을 활용할 수 있는지에 대해서 알아보고, 해당 하드웨어 가속기 위에서 가장 최적화되어서 서빙할 수 있는 프레임워크들을 알아보려 합니다.
CPU Serving
특별한 하드웨어 가속기를 사용하지 않고 CPU에서 바로 서빙하는 방법이 있습니다. 주로 현재 조직에서 GPU를 수급하기 어렵거나, 모델의 Latency/Throughput이 별로 중요하지 않을 때 CPU를 사용하는 것도 옵션이 될 수 있습니다. 간단하게 CPU 모델을 서빙하기 위해서는 FastAPI와 같은 Web Framework를 통해 LLM 모델을 REST API로 노출시킬 수 있습니다.
@app.post("/inference")
def inference_with_cpu(request: GenerationRequest):
"""
Huggingface GPT2를 Inference하는 예시 API
"""
with torch.inference_mode():
generate_params = request.dict()
input_ids = torch.tensor([request.tokens], dtype=torch.long)
generate_params["input_ids"] = input_ids
if "top_p" in generate_params:
generate_params["do_sample"] = True
# Inference
outputs = model.generate(**generate_params)
# Context 뒤의 Reply부분만 반환하도록 Slicing
outputs = outputs[:, context_token_length:]
outputs = outputs.reshape(request.num_return_sequences, -1)
outputs = outputs.tolist()
choices = [{"tokens": token} for token in outputs]
return {"choices": choices}
CPU에서 서빙 시, 사용할 수 있는 다양한 최적화 프레임워크들도 존재합니다. PyTorch의 JIT-mode를 활용하거나, HuggingFace의 Optimum에서 제공하는 BetterTransformer를 활용하여서 성능을 끌어올릴 수 있습니다. 위 방법들은 앞절에서 설명한 “Kernel Fusion”기법을 적극적으로 활용하여서 모델 자체의 성능을 떨어뜨리지 않으면서도 빠른 추론 속도를 얻어낼 수 있습니다. 이외에도 Intel®️ Extension for PyTorch를 활용한다면 Intel의 SIMD instruction인 AVX512를 적극적으로 활용하도록 최적화할 수 있습니다. 더 자세한 내용은 Hugging Face에서 작성한 블로그를 참고해주세요.
GPU Serving
충분한 GPU 인스턴스를 확보할 여력이 된다면 GPU를 추론에 활용할 수 있습니다. On-premise로 GPU 머신을 직접 구입하여 라이브 서비스에 활용할 방법도 있겠지만, 높은 확장성과 GPU 아키텍처의 변동에 따른 기민한 움직임을 위해 많은 기업들이 클라우드를 라이브 서비스에 활용하고 있습니다. 서빙에 활용할 수 있는 GPU는 대표적으로 Amphere 아키텍처 기반의 A100, A10, A40 등의 GPU가 있고, NVIDIA의 최신 아키텍처인 Ada Lovelace 아키텍처 기반의 L4, L40 등의 GPU가 있습니다. 높은 메모리가 필요하다면, Turing 아키텍처 기반의 RTX A6000 GPU도 서빙에 활용할 수 있습니다. 이전에 많이 사용되던 T4 또는 그 이하 세대의 GPU 들은 메모리가 부족하거나 Tensor Core 의 연산 성능이 충분하지 않아 LLM World 에서는 주로 사용되지 않습니다.
다양한 클라우드 밴더사에서 위 GPU들을 제공하고 있는데 글을 작성하는 시점에는 GCP에선 A100 40GB 머신인 a2-highgpu-1g, L4 24GB 머신인 g2-standard-4 타입을 제공하고 있고, AWS에선 A10G 24GB 머신인 g5-xlarge 타입을 제공하고 있습니다. 그 외의 GPU들은 대표적으로 CoreWeave에서 A40, A6000, 그리고 L40머신을 제공하고 있습니다. GPU 선택에는 정답은 없고, 조직 내에서 사용할 모델의 아키텍처와 크기가 정해지고 나면 필요한 GPU 메모리의 크기와 서빙 환경의 클라우드 종류, 그리고 조직 내에서 필요로 하는 추론 성능의 요구사항에 따라 적절한 실험을 통해 결정하여야 합니다.
GPU 역시 추론 최적화를 도와주는 여러 오픈소스 프레임워크들이 존재합니다. 대표적으로 NVIDIA의 FasterTransformer가 있는데, 앞서 언급한 Kernel Fusion과 같은 최적화 방법론들을 활용하며 PyTorch가 아닌 Native CUDA C++ 코드로 작성돼 빠른 성능을 제공합니다. Production상에서 FasterTransformer 를 사용하기 위해서 NVIDIA의 Triton을 활용할 수 있습니다. Triton은 FasterTransformer Backend를 지원하기 때문에, 직접 FastAPI로 API 서버를 구현하지 않아도 FasterTransformer의 성능적 이점을 가져오면서 손쉽게 배포를 진행할 수 있습니다. 또한 Dynamic Batching 및 Scheduling, 또는 모델의 병렬화 등의 기능을 지원함으로서 최적화된 API 를 손쉽게 만들수 있습니다. HyperCLOVA 서빙 프레임워크 선정 블로그 글을 보면 네이버 역시 FasterTransformer 를 기반으로 서빙 엔진을 구축한 것을 확인할 수 있습니다.
오픈소스 이외에도 GPU 위에서 LLM 서빙을 최적화하도록 도와주는 유료 솔루션들이 존재합니다. FriendliAI 사의 Periflow는 독자 개발한 배칭 전략과 여러 최적화를 통해 FasterTransformer 대비 5-6배 높은 시간당 처리량(Throughput)을 보여줍니다. 때문에 FasterTransformer 로 5개의 GPU 인스턴스를 띄워 처리할 수 있는 처리량을 한개의 GPU 인스턴스만으로도 처리가 가능하게 됩니다. 다만 해당 엔진을 사용하기 위해서는 FriendliAI 측과 계약을 맺고 라이센스 비용을 지불해야 하기 때문에 인스턴스 비용 외에도 추가적인 비용을 고려해야 합니다.
IPU Serving
최근에는 GPU가 아닌 IPU(Intelligence Processing Unit) 또는 NPU(Neural Processing Unit)을 활용하여 LLM을 서빙하려는 시도들도 이루어지고 있습니다. 대표적으로는 AWS가 자체 개발한 ML 추론 전용 칩인 Inferentia가 있습니다. AWS Inferentia 는 Pytorch / Tensorflow 로 만들어진 모델을 Neuron Architecture 에 맞게 컴파일해주는 SDK 를 지원합니다. 그 이후 Tensorflow Serving 등과 같은 방법을 이용해서 모델을 서빙할 수 있도록 합니다. Inferentia 는 GPU 대비 FLOPs 당 가격이 약 1/3 정도로 저렴하고, GPU 보다 수요가 적어 어느정도 충분한 량의 availability 를 챙길 수 있다는 점이 큰 장점입니다. 실제로 스캐터랩에서도 이전에 RoBERTa를 라이브 서비스에 활용하기 위해 AWS Inference를 활용하여 최적화한 경험이 있습니다. 보다 자세한 내용은 AWS Inferentia 를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 1탄 링크를 참고해 주시면 좋을 것 같습니다.
최근에는 Inferentia1 대비 더 높은 성능의 Inferentia2 가 정식 릴리즈 되었습니다. 특히 Inferentia2 의 경우에는 LLM 의 수요에 맞추어서 Dynamic Graph 지원, 175B 정도 크기의 모델도 분산 추론할 수 있는 성능을 제공하기 때문에 또다른 LLM 서빙 옵션 중 하나로 자리매김 하려 하고 있습니다. 하지만 내부적인 실험 결과 아직까지 3B 이상 크기의 모델에서 충분한 성능을 발휘하고 있지 못하고, 다양한 generation 옵션(top-p, repeatation penalty) 등을 좋은 성능으로 지원하고 있지 않아 실제 서비스에 적용되기 까지는 시간이 더 필요로 해 보입니다.
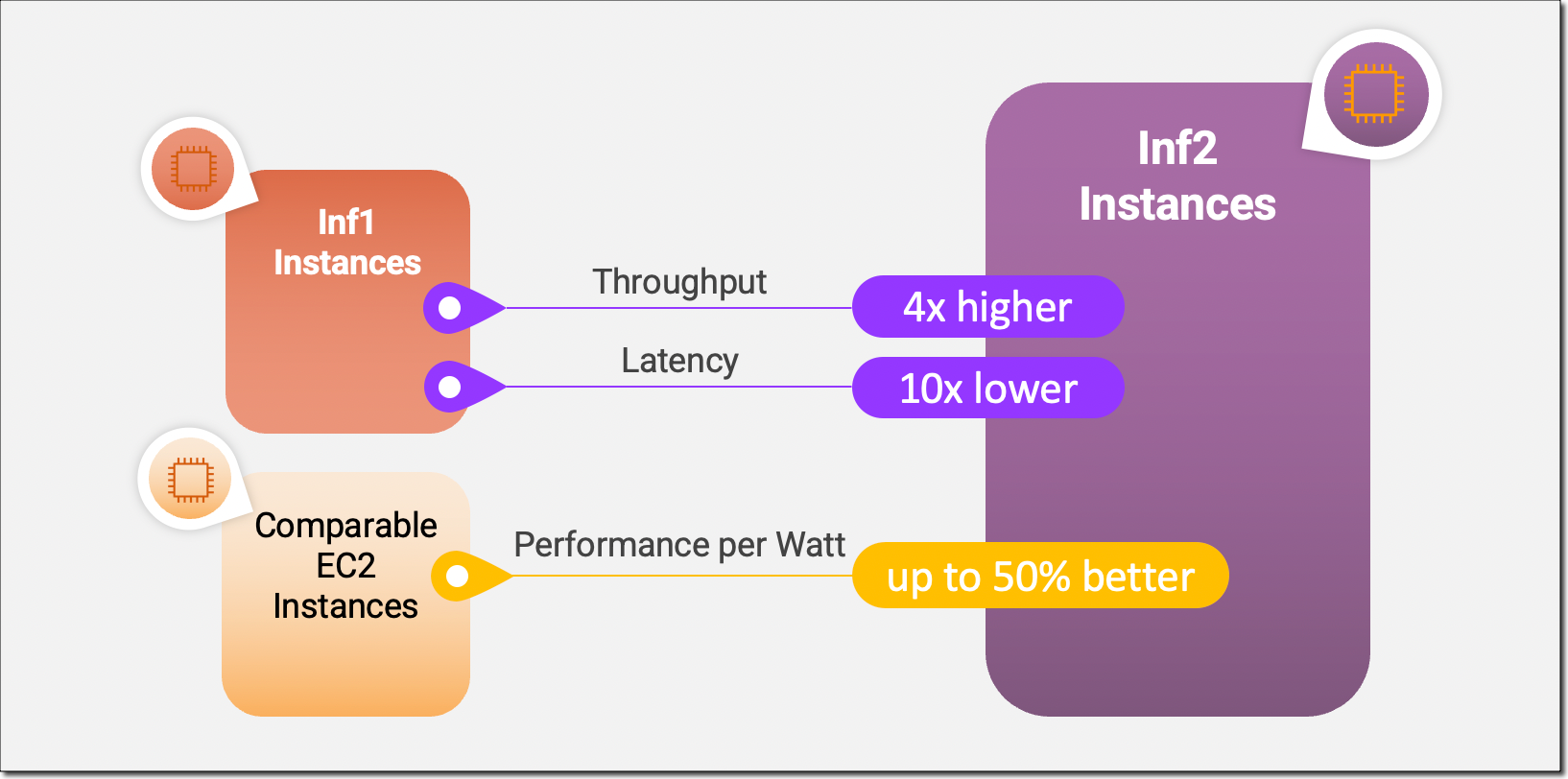
Inferentia 외의 대안으로는 구글의 TPU(Tensor Processing Unit)가 있습니다. 구글에서 제공하는 ML 모델 전용 칩이고 Inferentia 처럼 XLA 기반의 Compiler 를 이용해서 모델의 학습/추론 그래프를 최적화해 TPU 를 사용할 수 있도록 합니다. GCP Kubernetes 에 GA 되어 있기 때문에 JAX 를 기반으로 추론 코드를 작성한다면 서빙용으로도 사용할 수 있는 가능성이 있습니다. 하지만 TPU 기반의 추론시스템에 대해서는 공개적으로 많이 알려진 바가 없습니다. 하지만 종종 발표되는 TPU 관련 블로그 글 을 살펴보면, 내부적으로 TPU 를 학습 외에 추론용으로도 사용하고 있다는 사실을 짐작할 수 있습니다. 아무래도 내부 TPU 리소스 사용량이 많아 TPU 를 추론용으로 GA 하지 않고 있다고 보여지는데, 앞으로 GPU 부족 사태가 가속화 된다면 TPU 도 좋은 대안 중 하나가 될 수 있다고 생각합니다.
그 외에도 국내의 리벨리온, 하이퍼엑셀 등이 있고, 해외에는 Cerebras, GraphCore 등의 스타트업들이 생성AI 를 위한 여러 반도체들을 만들고 있기 때문에 조만간 GPU 외에도 다양한 대안들이 나올 것이라 기대하고 있습니다.
LLM 서빙 방법론의 결정을 위한 부하테스트
앞서 소개드린 여러 최적화 방법론들의 최종적인 목표는 “1)더 많은 요청을 2)저지연 3)저비용으로 처리”라고 설명할 수 있습니다. 이를 평가할 수 있는 지표는 Latency와 Throughput이 있습니다. Latency는 하나의 요청이 발생했을 때 응답이 오기까지의 시간을, Throughput은 단위시간 내에 처리할 수 있는 요청의 수를 의미합니다. 즉 1)더 많은 요청을 처리하기 위해선 시스템의 Throughput이 높아야 하며, 이를 2)저지연으로 처리하기 위해선 Latency가 낮아야 합니다. 이를 통틀어서 3)저비용으로 처리한다는 것은 적은 인스턴스수로 요구된 Latency와 Throughput을 충족시킨다는 것이며, 단일 서버가 처리할 수 있는 Throughput이 높을 경우 적은 인스턴스를 사용하게 되여 최종적으로 비용을 낮출 수 있습니다.
Offline으로 ML 모델을 서빙하는 서비스에서는 추론 시스템의 Throughput만 고려해도 되겠지만, 스캐터랩에서 서비스하고 있는 너티와 같은 챗봇의 경우 대화를 걸었을 때 답변이 바로 와야하는 서비스 특성상 낮은 Latency를 가지는 것 역시 중요하기에 Latency는 시스템의 제약사항이 됩니다. 이 때 서빙에 필요한 비용은 아래와 같은 Step으로 구해낼 수 있습니다.
- 단일 서버에서 부하테스트를 통해 Latency-Throughput 그래프를 그립니다.
- Latency-Throughput 그래프를 통해 제품에서 요구하는 Latency에서의 Throughput을 측정하고, 목표로 하는 Throughput에서 서버 하나의 Throughput값을 나누어 인스턴스의 개수를 구합니다.
- 해당 인스턴스의 개수에 시간당 인스턴스 가격을 곱합니다.
Latency-RPS 그래프 그리기
Latency-RPS 그래프를 그리기 위해서는 RPS를 고정한 다음, 해당 RPS에서의 Latency를 측정하는 방식으로 부하테스트를 진행할 수 있습니다. 이를 엄밀하게 측정하기 위해서 확률분포중 하나인 지수분포를 통해 고정된 RPS에서의 요청을 시뮬레이션할 수 있습니다. 지수분포는 독립적인 사건 사이의 대기시간을 나타내는 확률분포이며, $\lambda$만큼의 빈도를 가질 때 평균 $1/\lambda$의 대기시간을 가집니다. 이 $\lambda$값을 초당 요청 처리량(RPS), 즉 Throughput으로 생각할 수 있으며, $\lambda$값을 고정하고, 충분한 Duration동안 Load Test를 진행한다면 실제 RPS가 $\lambda$일 때 유저의 요청 사이의 대기시간을 $\text{Exp}(1/\lambda)$로 둘 수 있고, 이는 현실세계에서 고정된 RPS에서의 유저 요청을 수학적으로 시뮬레이션할 수 있습니다. 아래 코드를 통해 주어진 Throughput에서의 Latency값을 추출해낼 수 있습니다.
def write_result(result_path, results):
first_trace_start_time = results[0]["start_time"]
with open(result_path, "w") as f_result:
f_result.write("start_time(ms),end_time(ms),latency(ms)\n")
for result in results:
start_time = (result["start_time"] - first_trace_start_time) * 1000
end_time = (result["end_time"] - first_trace_start_time) * 1000
latency = end_time - start_time
f_result.write(f"{start_time},") # start_time
f_result.write(f"{end_time},") # end_time
f_result.write(f"{latency}\n") # latency
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=1000)) as session:
result_tasks = []
num_total_request = int(args.lambd * args.duration)
for _ in range(num_total_request):
await asyncio.sleep(random.expovariate(args.lambd))
result_tasks.append(
asyncio.create_task(request(session, master_uri, total_request))
)
results = await asyncio.gather(*result_tasks)
write_result(args.result_path, results)
더 간단하게는 Python에서 부하테스트를 손쉽게 수행하도록 도와주는 툴인 Locust를 활용할 수 있습니다. 유저수를 천천히 늘려가면서 순간 RPS마다의 Latency를 기록하여서 위 결과를 근사할 수 있습니다. 이 때 한번에 유저의 요청이 몰리는 것을 방지하기 위해 between()을 사용하여 하나의 유저에 대해 요청과 요청 사이의 간격을 랜덤하게 합니다. Locust를 활용한 예시 코드는 아래와 같습니다.
from locust import HttpUser, task, constant_pacing, between
import random
...
class LLMUser(HttpUser):
wait_time = between(0, 5)
@task
def generate(self):
input_len = random.randint(200, 236)
input_payload = {
"tokens": [random.randint(1, 1000)] * input_len,
"max_tokens": 20,
"min_tokens": 20,
"n": 8,
"top_p": 0.8,
"top_k": 32,
"seed": [42],
}
self.client.post("/inference", json=input_payload)
def stats_history(runner: Runner) -> None:
"""Save current stats info to history for charts of report."""
while True:
stats = runner.stats
if not stats.total.use_response_times_cache:
break
if runner.state != "stopped":
r = {
"time": datetime.datetime.utcnow().strftime("%H:%M:%S"),
"current_rps": stats.total.current_rps or 0,
"current_fail_per_sec": stats.total.current_fail_per_sec or 0,
"response_time_percentile_95": stats.total.get_current_response_time_percentile(
0.95
),
"response_time_percentile_90": stats.total.get_current_response_time_percentile(
0.90
),
"avg_response_time": stats.total.avg_response_time,
"user_count": runner.user_count or 0,
}
stats.history.append(r)
gevent.sleep(0.5)
def main(args: argparse.Namespace):
env = Environment(user_classes=[LLMUser], host=args.host)
env.create_local_runner()
gevent.spawn(stats_printer(env.stats))
gevent.spawn(stats_history, env.runner)
env.runner.start(args.max_user, spawn_rate=args.spawn_rate)
gevent.spawn_later(args.duration, lambda: env.runner.quit())
env.runner.greenlet.join()
df = pd.DataFrame(env.stats.history)
plt.figure(figsize=(20, 10), dpi=100)
plt.plot(
df["current_rps"], df["response_time_percentile_90"], ".-", label="P90 Latency"
)
plt.plot(
df["current_rps"], df["response_time_percentile_95"], ".-", label="P95 Latency"
)
plt.legend(loc="upper left")
plt.title("Latency/Throuput")
plt.xlabel("Request/sec")
plt.ylabel("Latency")
plt.grid(True)
plt.savefig(args.figure_path)
if __name__ == "__main__":
main(parser.parse_args())
아래는 예시로 DeepSpeed와 FriendliAI의 Orca(Periflow Serving)의 Latency-RPS 그래프를 그려본 결과입니다. 1000ms의 Latency를 Constraint로 주었을 때 DeepSpeed 대비 Orca가 25배 이상의 RPS를 가지는 것을 확인할 수 있습니다.
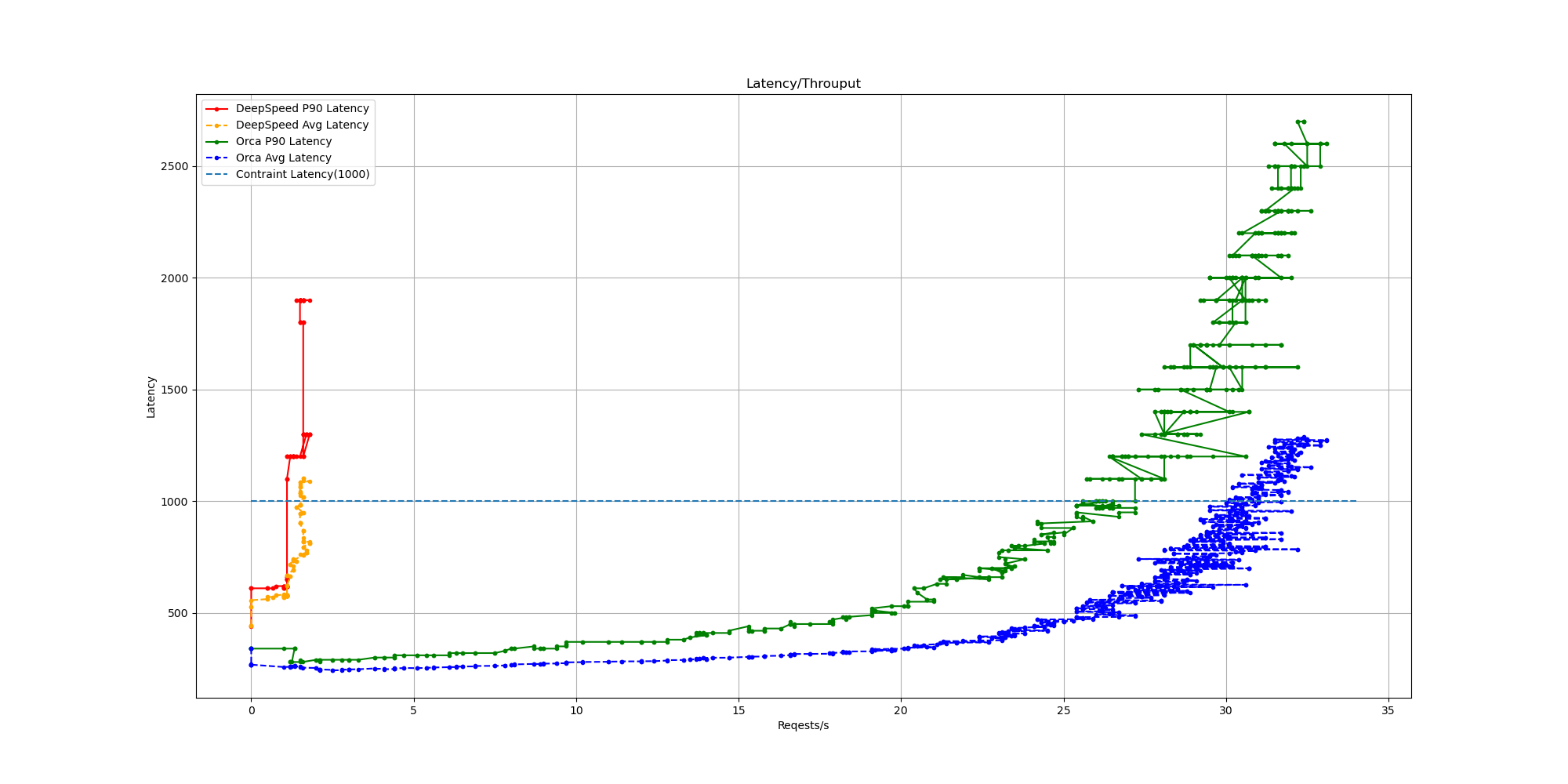
마치며
이번 글을 통해서 생성모델 서빙 최적화에 필요로 하는 기본적인 개념과 현재 사용할 수 있는 기술들에 대해서 간략하게 알아보았습니다. 생성AI 의 가장 큰 Pain Point 가 비용인 만큼, 앞으로도 커뮤니티에서는 생성모델 서빙 최적화 관련된 여러 연구들이 이루어질 것이라고 생각됩니다. 위 블로그에 담지 못한 vLLM 이나 Smooth Quantization 등 여러 기법들이 속속 등장하고 있고, 저희도 내부적으로 적용을 위해서 PoC 를 진행하고 있습니다.
스캐터랩에서는 하루 아침에 바뀌는 서빙 기술들의 Follow-Up을 위해 내부적으로 생성모델 서빙 최적화 스터디를 매주 진행하고 있고, 다음 블로그에서는 그 내용 중 하나로 방금 언급드린 vLLM에 대해 다루어보려 합니다. vLLM은 PagedAttention이라는 새로운 기법을 이용해서 HuggingFace 대비 24배의 성능향상을 이루어냈다고 합니다. 서빙 기술에 관심이 있으신 분들께는 매우 유익한 내용이 될 것이므로, 다음 블로그 포스팅을 기대해주세요!
이러한 생성모델 최적화 기법을 연구하고 실제로 제품에 적용하는 저희 스캐터랩 MLE (Machine Learning Engineer)팀에 관심이 있으시다면 아래 채용공고를 확인해 주시고, 편하게 채용팀(recruit@scatterlab.co.kr)으로 티타임 요청해 주세요 🤗