Transformer - Harder, Better, Faster, Stronger
Transformer 구조체와 이 구조를 향상시키기 위한 기법들을 같이 알아봅시다.

이번 블로그에서는 2017년에 발표되어 자연어처리 분야의 한 획을 그었던 Transformer 구조와 이를 활용한 GPT / BERT 구조에 대해서 다룹니다. 아울러 어떠한 문제들이 있었고 연구자들이 어떻게 그 문제들을 풀려 노력했는지에 대해서 같이 알아보고자 합니다.
Table of Contents
- 들어가며: Transformer 에 대해서
- Transformer의 구현체: GPT와 BERT
- 더 똑똑하게 훈련하기(Harder and Better)
- 빠르고 강하게 줄이기 (Faster and Stronger)
- 이 글을 마치며
- References
들어가며: Transformer 에 대해서
기존 순환 신경망 구조와 그 한계
2010년대는 신경망의 재발견의 시대라고 말해도 과언이 아니라 할 수 있습니다. GPU의 성능이 발전하고 여러 신경망 기법이 재조명되면서 많은 연구자들은 연구하는 분야의 기법들을 신경망의 형태로 구현하기 시작하였습니다. 자연어처리 분야도 예외는 아니었습니다. 기존 방법론에서는 문장을 확률 그래프 모델인 Hidden Markov Model (HMM)과 Conditional Random Field (CRF)으로 나타내었는데, 이 구조 역시 빠르게 신경망 구조로 대체되었습니다. 2016년까지 그 선택지로 제시된 주로 제안된 구조는 순환 신경망 (Recurrent Neural Network, RNN)과 그 파생 구조 (LSTM이나 GRU 등)이었습니다. 순환 신경망은 출력이 입력으로 들어가는 구조를 의미하는데, 일반적으로 문장을 표현할 때의 순환 신경망은 이전 단어에서의 hidden_state가 해당 단어의 hidden_state를 결정하는 것에 사용되면서 단어의 뜻을 순차적으로 반영하는 구조를 말합니다. 이 구조들에서 각 단어를 나타내는 벡터는 그 앞 단어의 벡터에 의해서만 직접적으로 영향받게 됩니다.
이 모델은 문장을 효율적으로 나타낼 수 있었지만, 두드러지는 단점이 있었습니다. 그 단점은 순차적으로 입력이 들어가기 때문에 거리가 먼 단어의 영향력이 줄어든다는 점 (Long Term Dependency Problem)이었습니다. 즉, 바로 앞 문장의 가중치에 의존하는 구조 특성상, 긴 문장이 나왔을 때 앞 쪽에 나온 단어의 영향력을 모델이 잊어버리는 현상 (Vanishing Gradient)이 발생합니다.

Attention에 대해서
일상적인 문장을 분류하는 문제를 다루는 경우는, 예를 들어 문장의 감정값을 추출하거나 의도를 파악하는 경우는, 문장의 길이가 짧기 때문에 이 문제가 크게 심각하지는 않았습니다. 하지만 문장을 새로 생성하는 경우 특히 기계 번역을 하는 경우에는, 새로 만들어 내는 단어들 때문에 문장이 길어지는데다가 언어 특유의 어순에 따라서 멀리 있는 단어를 참조해야하는 경우가 많았기 때문에 성능을 저하시키는 중요한 문제가 되었습니다.
‘먼 거리에 위치한 단어의 영향력을 현재 단어에 효과적으로 반영할 수 있는 방법이 없을까?’ 이 문제에 대한 답으로써 Bahdanau et al.은 Attention 구조를 제안하였습니다. 제안된 Attention 구조는 각 입력 단어가 출력 상태에 연결되는 신경망을 추가로 두어서, 바로 직전 단어 뿐만이 아니라 다른 모든 단어들이 얼마나 현재 결과에 기여하는지 가중치의 형태로 나타낸 것이었습니다. 이 구조는 기존 RNN 구조와 다르게 각 단어가 직접적으로 가중치의 형태로 연결되어 있으므로 그 사이의 상관관계를 직접적으로 나타낼 수 있었습니다. 예를 들어, 훈련 데이터에서 두 단어가 서로 자주 나오게 된다면 가중치가 크게 학습이 되고 모델은 해당 단어쌍이 서로 상관관계가 강하다는 것을 알게 되는 것입니다.
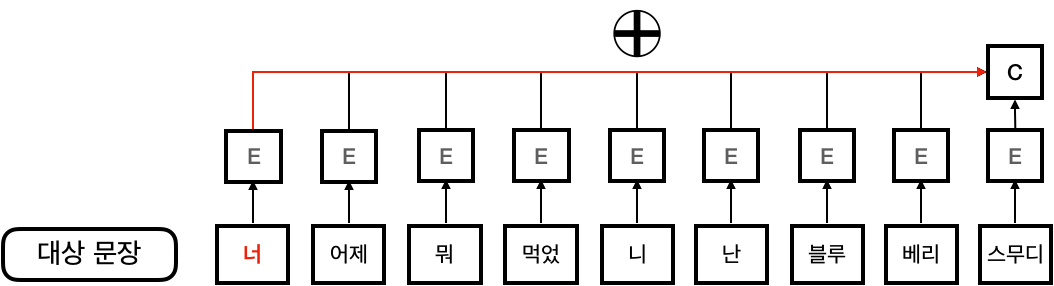
Bahdanau가 제시한 이후로 Luong 등이 추가로 더 효율적인 Attention 구조를 제안하였지만 본질적인 아이디어, 즉 “단어간 상관관계를 가중치의 형태로 모델에 반영한다.” 는 것은 자연어처리 분야에서의 하나의 혁신으로 남았습니다.
Transformer의 구조
기존의 Attention 구조는 RNN Cell에서 보조적으로 활용되었습니다. 2017년 Google의 Vaswani et al. 은 다음과 같은 아이디어를 제안하였습니다.
만약 Attention이 단어간 상관관계를 잘 반영할 수 있다면, Attention만으로도 문장을 모델링 할 수 있지 않을까?
이 발상의 전환에 따라서 제안한 구조는 기존의 언어 모델과 다르게 RNN 없이 언어를 수학적으로 기술할 수 있는 모델이었습니다. 이 구조가 바로 Transformer 구조입니다. 기존 구조에서는 문장을 “단어의 연속적인 배열”로 간주하였습니다. 그러나 Transformer에서 문장은 “단어간의 Attention들의 합”으로 나타납니다. 즉, 문장이라고 하는 구조는 마치 베틀처럼 Attention을 촘촘하게 엮은 형태로 나타낼 수 있는 것입니다.
Transformer 는 크게 두 부분으로 나눌 수 있습니다: 문장을 잠재 표현으로 변환하는 Encoder block과 이를 다시 복원하는 Decoder block 입니다. 각 block은 Attention을 집약적으로 구성한 구조입니다. 이제 어떻게 Transformer에서 Attention이 활용되었는지를 알아보면서 Transformer의 구조를 살펴보도록 합시다.
Attention in Transformer
Transformer 에서 Attention 은 Scaled-dot Product attention 을 사용합니다. 앞서서 Attention은 단어와 단어 사이의 상관관계를 나타내는 가중치라고 설명드렸습니다. 단어 A에 대해서 단어 B 가 주는 가중치는 다음과 같은 세 개의 변수로 표현할 수 있습니다.
- Query (Q): 영향을 받는 단어 A를 나타내는 변수입니다.
- Key (K) : 영향을 주는 단어 B를 나타내는 변수입니다.
- Value (V) : 그 영향에 대한 가중치를 나타냅니다.
이 경우, 단어쌍 가중치 Attention(Q,K,V)는 다음과 같이 계산됩니다. Attention을 Q,K의 내적으로 계산한 값을 (Dot-Product), Query와 Key의 Array Dimension으로 그 크기를 조절 (Scaling) 하기 때문에 제안한 Attention을 Scaled-dot Product attention 으로 칭합니다.
\[Attention(Q,K,V) = softmax({\frac{Q{K^{T}}}{\sqrt{d_{k}}}})V\]논문의 저자들은 위의 Attention 구조를 제안한 것에 그치지 않고, 이를 여러 번 반복하는 구조 (Multi-head Attention)를 제안하였습니다. 문장의 상관 관계는 여러 측면에서 바라볼 수 있기 때문이며 따라서 여러 종류의 Q, K, V를 설정함으로써 다양한 측면의 관계를 나타낼 수 있다고 보았기 때문입니다.
Encoder block and Decoder block
Encoder block은 문장을 잠재 표현으로 변환하는 부분입니다. 원 논문에서 저자들은 6개의 동일한 구조를 활용하여 이를 구현하였습니다. 각 구조는 위에서 설명한 Multi-head attention 층과 Fully-connected 층으로 구성되었습니다. 원 논문에서는 각 구조들의 출력값을 합하여 한 단어당 총 512차원의 잠재 표현으로 변환하였습니다.
Decoder block도 Encoder block과 유사하게 형성되었습니다. 단, Encoder의 출력이 잠재표현인 것과 다르게, Decoder의 출력은 단어의 출현 확률이 됩니다. 아울러 Decoder는 실제 단어를 출력하는 부분이기 때문에 해당 단어를 기준으로 뒷 단어들에 의한 Attention을 Masking 처리를 하고 참조하지 않았습니다.
Transformer의 구현체: GPT와 BERT
GPT와 BERT의 성질과 비교
Vaswani et al.에 제안한 Transformer는 효과적인 구조였지만 Encoder와 Decoder가 단순하게 결합된 구조로 더 향상될 여지가 있었습니다. 2018년, OpenAI에서 발표한 Pre-trained Transformer 기반 생성 모듈 (Generative Pre-trained Transformer, 이하 GPT)과 역시 같은 해에 Google에서 발표한 양방향 Transformer Encoder 모델 (Bidirectional Encoder Representations from Transformers, 이하 BERT)은 원래의 Transformer 구조를 층층이 누적시켜서 단어간의 상관관계를 충분히 반영할 수 있도록 조직한 구조이지만, 기능적인 측면에서 차이를 보입니다.
| 항목 | GPT | BERT |
|---|---|---|
| Transformer block | Decoder block | Encoder block |
| Attention 방향 | Uni-directional | Bi-directional |
| 문장 생성 활용 여부 | 문장 생성 가능 | 직접 생성 불가능 |
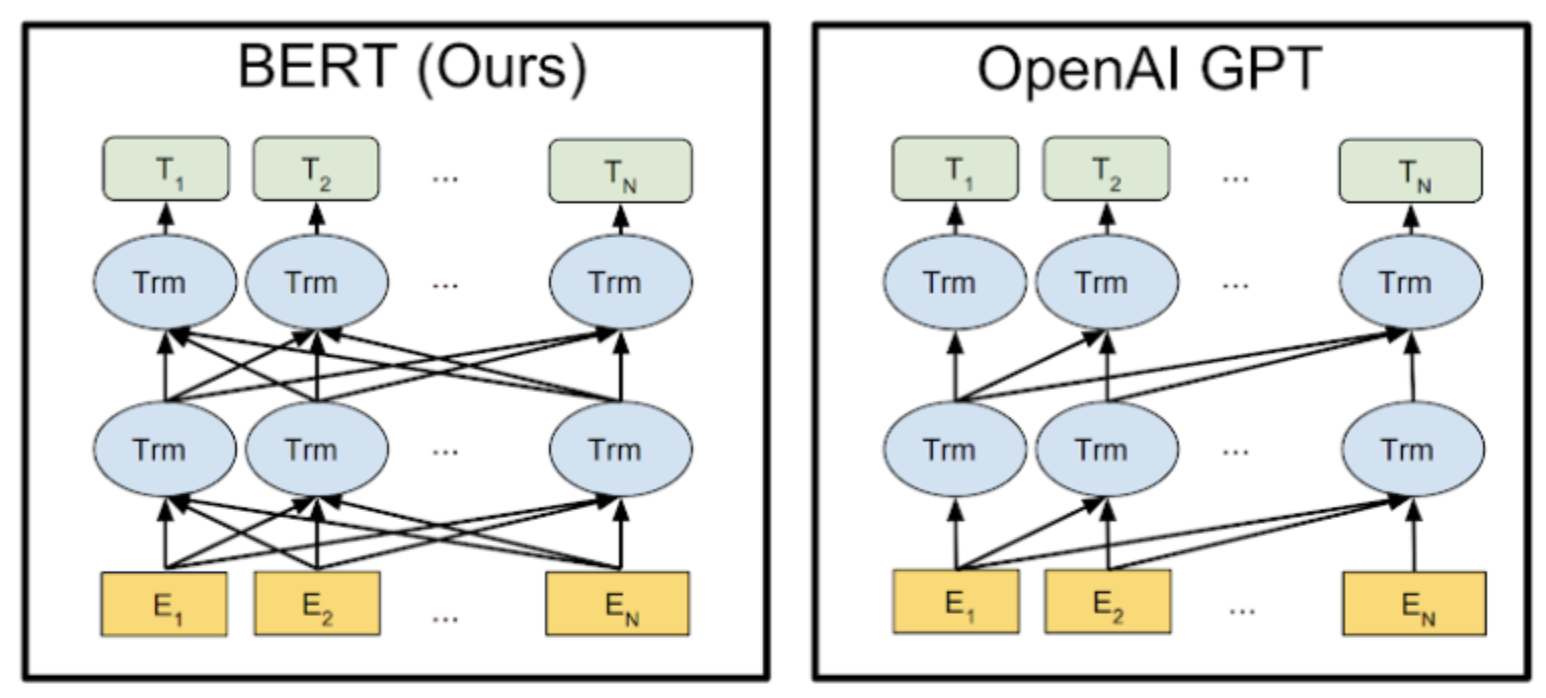
두 구조의 가장 큰 차이점은 Attention의 참조방향이 순방향이냐 양방향이냐는 것입니다. GPT의 경우 Decoder block이 순방향 Attention만을 쓰기 때문에 문장 생성에 직접적으로 이용될 수 있다는 강점을 가집니다. 이에 비해 BERT는 양방향 Attention을 써서 더 많은 정보를 반영하므로 비록 문장 생성에 직접 사용될 수는 없어도 더 우수한 성능을 나타냅니다.
상술한 BERT와 GPT는 기존 기법들에 비해 아주 뚜렷한 성능 향상이 있었기 때문에, 생성 분야에서는 GPT, 그 외의 분야에서는 BERT가 기존 방법론을 대체하였습니다. 마치 2010년대 초반에 LSTM이나 GRU 기반의 기법들이 CRF나 SVM 기반 처리기법들을 대체해버린 것처럼 말입니다.
Transformer 기반 모델의 문제점
그렇지만 모든 구조는 밝은 면이 있으면 어두운 면이 있는 법입니다. Transformer 기법들이 현업에 적용되면서 연구 단계에서는 크게 부각되지 않은 단점들이 드러나기 시작했습니다. Transformer 구조체의 여러 단점들은 하나의 크고 근원적인 문제점으로 요약됩니다.
모델이 문제를 풀기에는 너무 크다!
배기량이 매우 큰 슈퍼카를 자가용으로 몰게 되는 경우를 비유로 들 수 있겠습니다. 아마 그 슈퍼카는 200km/h는 가볍게 찍을 수 있을 것입니다. 그렇지만 늘 자동차로 붐비는 도심에서 자가용으로 모는 것이 좋은 선택일까요? 제 속력을 발휘할 기회는 거의 찾지 못한채 유지비만 막대하게 소모할 것입니다. 보다 구체적으로 Transformer 구조체의 문제점을 들어보면
- 모델이 훈련하기에 너무 큽니다. 때문에 어느정도 이상의 성능을 내기 위해서는 보다 막대한 양의 훈련 데이터와 시간이 필요합니다. 사실 뒤에서도 설명하겠지만 Wikipedia로 학습되어 현재 배포되고 있는 BERT 모델은 덜 훈련되었(under-fit)다는 증거가 여럿 포착되고 있습니다. 그렇게 막대한 데이터로 그렇게 많은 시간동안 훈련시킨 모델이 훈련이 부족하다는 사실은 새삼 얼마나 모델이 큰지 다시 한 번 절감하게 만듭니다.
- 모델이 실행하기에 너무 큽니다. 유저 인터페이스 형태로 서비스되기 위해서는 통신의 latency를 감안해서라도 모델의 처리 시간이 50-100ms 이하로 떨어져야합니다. 그렇지만 BERT의 경우에는 GPU를 이용하는 경우에도 단일 처리 시간이 200ms 를 넘는 경우가 많습니다. 이러면 아무리 성능이 좋아도 실제 시스템에 탑재되지 못하는 것은 당연합니다. BERT가 나온지 1년이 되어갑니다만, 제품화되는 경우가 손에 꼽을 정도라는 것이 이를 시사합니다.
이러한 문제를 접하게 된 이후의 연구 방향은 크게 2가지 방향으로 진행되었습니다.
- 실험 결과 Transformer 구현체는 훈련이 덜 된 구조인 것이 시사되었다. 그렇다면 어떻게 더 많이, 치밀하게 훈련시켜서 성능을 향상시킬 수 있을까?
- 실제로 Transformer 구현체들을 인터페이스로 구현하려면 어떻게든 구조를 축소시켜야한다. 어떻게 하면 성능의 손실을 최대한 막으면서 구조를 빠르고, 강하게 줄여서 실제로 서비스가 가능한 형태로 바꿀 수 있을까?
더 똑똑하게 훈련하기 (Harder and Better)
다음 구조들은 첫번째 관점에서 진행된 연구들입니다.
| 항목 | BERT | XLNet | RoBERT | MT-DNN | T5 |
|---|---|---|---|---|---|
| Parameter Size | Base:110M Large:340M |
Base:110M Large:340M |
Base:110M Large:340M |
Base:110M Large:340M |
220M |
| Train Data Size | 16GB | Base: 16GB(BERT) Large: 113GB |
Base: 16GB(BERT) Large: 160GB |
16GB(BERT) + GLUE | 750GB (C4) |
| GLUE Score | 80.5 | 88.4 | 88.5 | 85.1 | 89.7 |
XLNet: Transformer-XL based Approach
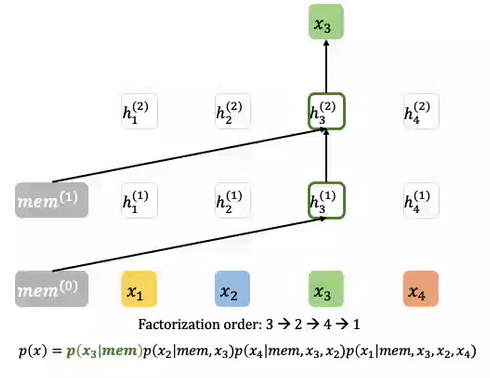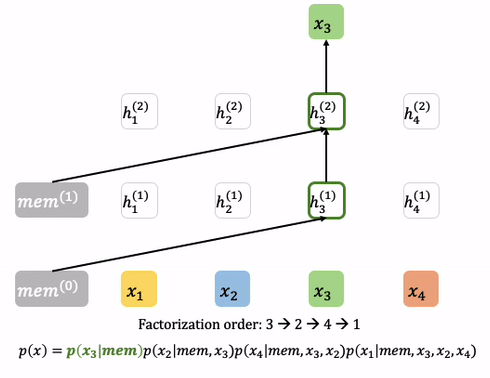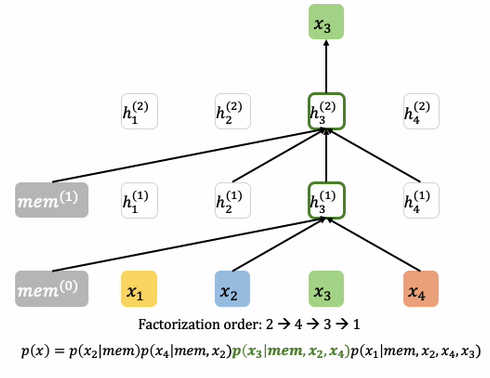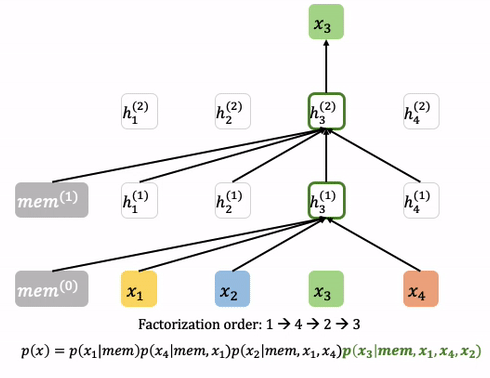
XLNet은 BERT보다 더 많은 상관관계를 고려한 모델입니다. 개략적인 특징은 다음과 같습니다. (보다 더 자세한 설명은 https://tech.scatterlab.co.kr/xlnet-review/ 를 참조해주시기 바랍니다.)
- GPT는 단방향, BERT는 단순 양방향 상관관계를 보는데 비해, XLNET은 상관관계의 순서를 순열 형태로 샘플링한 다음에 그 앞번 단어들에 대한 상관관계를 봅니다. 예를 들어, (2,4,3,1)이 샘플 되었다면 2번째 단어 → 4번째와 2번째의 상관관계 → 3번째와 4번째, 3번째와 2번째의 상관관계 → … 의 상관관계를 고려합니다. 이 때, 학습은 충분조건으로 주어진 단어들을 제외한 입력을 Masking 함으로써 이루어집니다.
- 아울러 훈련 데이터를 기존 BERT에 10배가량 증가시켰습니다. (물론 공정한 비교를 위해서 RACE에 대해서 실험할 때에는 동일한 데이터로 Pretrain 하였습니다.)
결과적으로 성능이 향상되었으며 동일한 데이터에 대해서도 더 우수한 성능을 보였습니다. 몇몇 시사점들은 다음과 같습니다.
- 다음 문장 예측 작업 (Next Sentence Prediction, 이하 NSP)을 훈련 과정에 포함하면 성능이 떨어지는 모습을 보였습니다. 반대로 위에서 제안한 순열 Masking을 사용하여 훈련한 경우에는 동일한 양의 데이터를 사용한 경우에도 더 우수한 성능을 보이는 것을 확인하였습니다. 즉, 언어의 상관관계는 양방향 상관관계 그 이상이며 이러한 상관관계를 쉬운 과업으로 학습시키는 것은 충분하지 않다는 것입니다.
- XLNet 자체의 구조적 우수성도 있지만 데이터가 많아졌다는 것도 성능 향상에 기여하였습니다.
RoBERTa: Robustly Optimized BERT Pretraining Approach
BERT의 훈련 과정을 다시 조정한 것이 RoBERTa입니다.
RoBERTa와 BERT의 차이점은 다음과 같습니다.
- 더 많은 데이터: 기존의 BERT모델은 16GB 데이터를 활용하여 훈련되었습니다. XLNet에서는 원 BERT 대비 8배에 해당하는 데이터를 활용하였으므로, RoBERTa 역시 데이터를 10배로 늘려서 실험하였습니다. 실험 결과, 데이터를 더 많이 넣어주고 이에 대응하여 더 많이 학습시켰을 때 비약적으로 성능이 향상되었습니다.
- Dynamic Masking : 원래 BERT의 경우 Word Masking을 미리 적용한 데이터로 훈련을 진행하였습니다. 물론 그렇게 되면 Masking에 따라 Bias가 생기게 됩니다. 때문에 훈련 전에 똑같은 데이터에 대해서 Masking을 10번 다르게 적용한 데이터를 만들어 활용하였습니다. 그럼에도 불구하고 Epoch이 늘어나면 똑같은 Masking 데이터를 보는 문제점이 있었으므로 여전히 예상치 못한 Bias가 생기게 됩니다. RoBERTa에서는 모델에 학습 데이터를 입력할 때마다, Masking을 새로 적용하여 훈련에 활용하였습니다.
- 다음 문장 예측 (NSP) 제거: 처음에 BERT가 제시되었을 때 NSP를 훈련 Objective에 포함시키는 편이 전체 훈련을 시키는 것에 도움이 된다고 간주되었습니다. 하지만 XLNet 논문을 비롯한 몇몇 후속 연구들에 따르면 NSP는 오히려 부정적인 효과를 가져오는 것으로 분석되었습니다. 실험 결과, 원 BERT의 구현과 다르게 문단 부분이 아니라 개개 문장쌍만을 넣었을 때, NSP는 오히려 성능에 악영향을 주었습니다. 즉, NSP는 너무 쉬워서 언어를 깊게 이해하는 것에 오히려 방해가 된다는 결론입니다.
- 배치 사이즈 증가: 기존의 언어 모델 학습의 경우는 작은 배치 사이즈 (통상 256)에 대해서 많이 학습을 시키는 전략을 취했습니다. 실험 결과 BERT를 학습시킬 때는 더 큰 배치 사이즈에서 더 잘 훈련이 되는 것으로 확인되었습니다. 즉, 더 큰 배치에 대해서 가중치 경사값을 계산할 때 보다 더 많은 문장을 반영하게 되는 것입니다.
- 1바이트 단위 글자 표현: 기존의 BERT에서는 유니코드 글자 단위의 부분 단어 어휘 사전을 사용했습니다. 그러나 이 경우, 어휘 사전에 없는 글자들을 놓치게 됩니다. 실제로 어휘 사전에 없는 단어(Out-of-Vocabulary, OOV)는 언어 모델의 성능을 저하시키는 요인이 됩니다. 본 논문에서는 바이트 단위의 부분 단어 어휘 사전을 활용하여, 유니코드 상에 있는 글자들을 모두 포착할 수 있도록 하였습니다. 이 방법은 성능 향상에는 직접적으로 기여하지 않았지만 더 많은 글자를 다룰 수 있게 해줍니다.
RoBERTa의 경우는 BERT와 구조적으로 다르지 않지만, 여러 실험들을 통해서 BERT에 대한 이해도를 높여주었다는 의의를 가지는 방법입니다. 특히 더 많은 데이터가 필요하다는 직관은 우리 생각보다 BERT는 더 많은 여력을 가지고 있는 구조라는 것을 시사합니다. 반대로 그렇다면 같은 성능을 위해서는 이렇게 큰 구조가 필요없다는 결론에 도달할 수도 있을 것입니다.
MT-DNN: Multi-Task Deep Neural Network
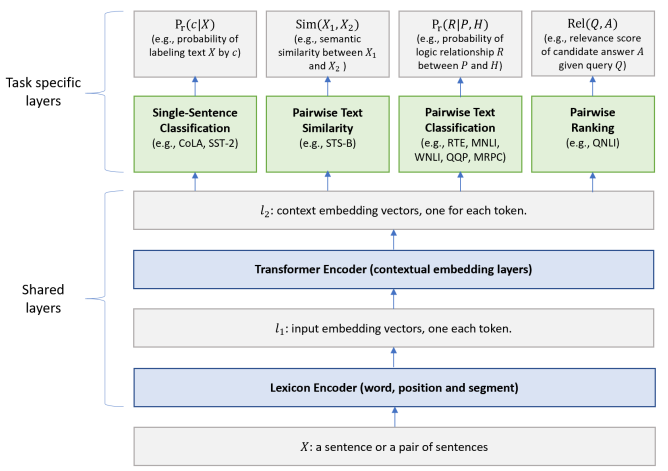
위에서 계속해서 시사되고 있는 바는 “BERT는 매우 강력한 모델이며, 이를 이끌어내기 위해서는 더 어려운 문제가 필요하다.” 라는 것입니다. 이에 대해서 자연스럽게 내릴 수 있는 가설은 “다양한 작업으로 학습시키면 언어를 잘 이해할 수 있지 않을까?” 입니다. MT-DNN은 이 가설을 실제로 시험해본 모델이라 할 수 있습니다.
기존의 BERT의 경우, Transformer를 Masked LM과 다음 문장 예측 작업으로만 훈련시켰습니다. MT-DNN은 여기에 그치지 않고 GLUE에 포함되는 서로 다른 네 가지 작업 (문장 분류, 문장쌍 유사도, 문장쌍 분류, 문장쌍 순위 메기기) 으로 Transformer를 Fine-tuning 시켰습니다. Fine-tuning을 위해서 Task당 별도의 신경망 층 (Task-specific Layer)를 두었습니다. 전체 작업들은 임의의 순서에 의해, 미니배치 단위로 학습에 사용되었습니다. 즉, 실제로 훈련시에는 한 미니배치당 한 작업만이 배당되며, 그 작업 하나에 의해서만 Loss가 계산되며 이 Loss에 따라서 전체 모델이 학습되었습니다.
검증을 위해서 원 작업인 GLUE와 새 작업인 문장 추론 (SNLI) 에 대해서 성능을 측정하였습니다. 실험 결과, MT-DNN 모델은 원 BERT에 비해 GLUE에 대해서 더 높은 성능을 보였으며 (이것은 사실 Fine-tuning을 거쳤기 때문에 당연합니다.) 각 GLUE 작업 단위로 추가적인 Fine-tuning을 했을 때 단순 BERT를 Fine-tuning했을 때보다 더 높은 성능을 보였습니다. 아울러 새 작업을 Fine-tuning할 때도 훨씬 작은 데이터를 사용해도 좋은 성능을 발휘하는 것을 볼 수 있었습니다.
MT-DNN이 시사하는 바는 다음과 같습니다.
- RoBERTa와 XLNet에서 시사되었다시피, BERT가 배울 수 있는 여력은 생각보다 큽니다. 본 방법론이 우수한 성능을 보여주었다는 것은, 한 작업에서 두드러지지 않은 언어 관계를 다른 작업을 통해 반영할 수 있게 되었다는 사실을 의미합니다.
- 또한 새 작업에서의 높은 성능은 언어의 각 작업들이 서로 어느 정도는 상관관계가 있다는 사실을 시사합니다. 마치 축구를 잘하는 친구가 농구나 배구도 잘하는 것과 유사합니다. 따라서 서로 유사한 작업들은 Fine-tuning할 때 보다 서로의 성능 향상에 기여할 것으로 예상됩니다. 물론 그렇지만 개개의 작업을 집중적으로 Fine-tuning 할 때에 비해 성능은 떨어질 것으로 예상되며 개별 성능과 종합 성능 사이의 균형점을 찾는 것이 필요하다 하겠습니다.
T5: Text-To-Text Transfer Transformer
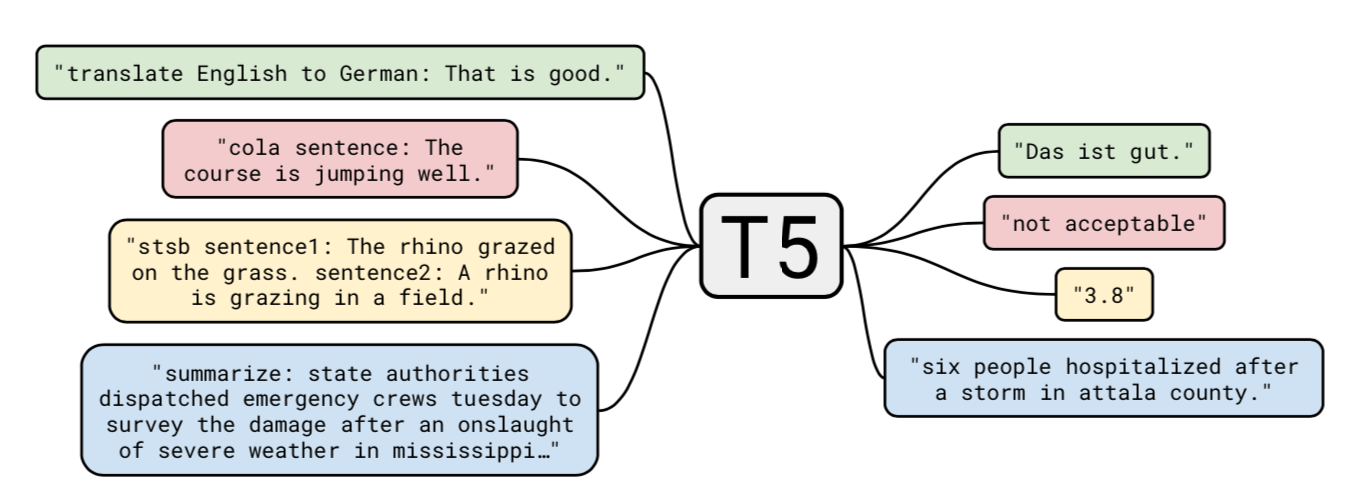
구글에서 제안한 T5 구조는 상당히 특이한 형태로 문제들을 기술합니다. 기존의 MT-DNN 등의 모델들이 배치 단위에서 실 훈련 데이터를 변경하며 다양한 문제를 모델에 투입하였다면, T5는 모든 문제를 문장 형태로 추상화 한 다음에, 그 추상화된 문장을 푸는 것을 훈련시킨 구조입니다.
T5의 문제 기술 형태에 대해서 조금 더 살펴보도록 하겠습니다. 기존의 Transformer 구조들은 다른 작업을 풀 때에는 각기 다른 레이어를 사용하도록 되어있었습니다. T5는 모든 문제를 “문제 문장” 형태로 기술될 수 있다고 가정합니다. 이 구조에서 문제를 푸는 것은 “문장 형태로 제공된 문제의 답을 찾기”로 변환됩니다. 어떤 관점에서는 문제를 일반화된 문장으로 번역한다고 할 수 있습니다. 예를 들어, “That is good.”을 독일어로 번역하는 문제를 생각해봅시다. 이 문제는 문제 문장 “translate English to German: That is good. target: Das is gut“로 변환됩니다. 본 문장에서 translate ~ target: 까지는 문제를 풀기 위해 주어진 정보이며, 반대로 Das is gut 부분은 실제 정답에 해당하는 부분으로 알지 못하는 부분입니다. T5에서는 주어진 정보 부분에 대해서는 양방향 Attention을, 정답을 생성하는 부분에서는 단방향 Attention을 이용하는 Prefix LM구조를 사용하였습니다.
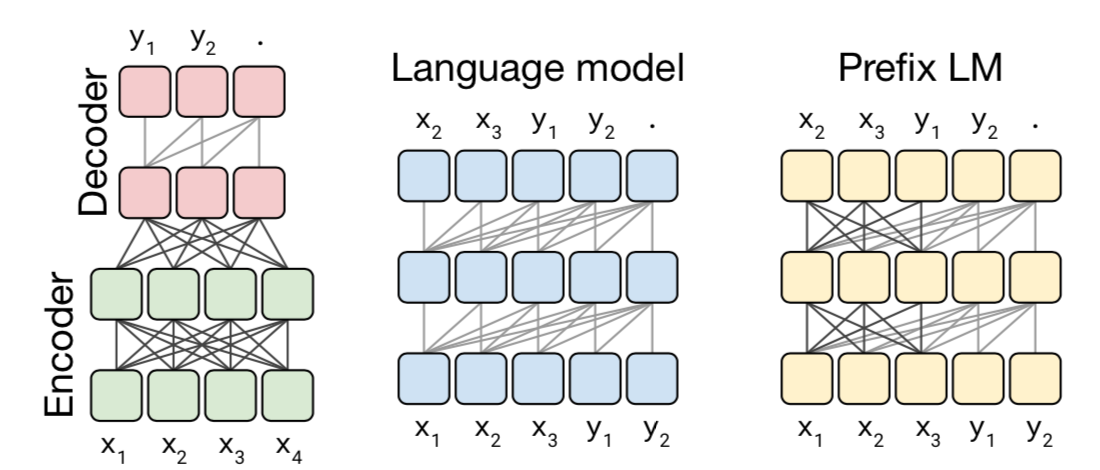
T5의 특징은 다음과 같습니다.
- 문장 자체의 표현을 더 효율적으로 배우기 위해서 Corruption을 도입하였습니다. 이것은 BERT의 Masking과 동일한 역할을 합니다만 조금 더 다양한 방법을 사용합니다.
- Masking: BERT의 Masking과 동일합니다. 문장 내 단어를 Mask 토큰 [MASK]로 가리게 됩니다.
- Replacing span: 문장 내의 구간(span)을 하나의 센티넬 토큰으로 치환합니다. 모든 단어에 대해서 별도의 [MASK] 토큰으로 가리는 Masking과 다르게, 구간 전체를 한 토큰으로 치환하는 것이 다르며, 아울러 그 구간에 대해서 고유한 토큰 [X], [Y] 등으로 치환합니다.
- Dropping: 문장내 토큰들을 누락시킵니다.
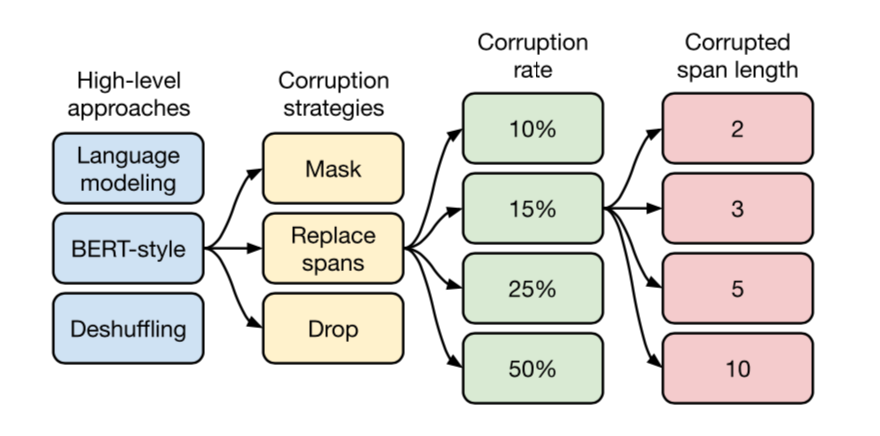
- 이를 해결하기 위해서는 강한 표현력을 가진 모델이 필요했습니다. T5는 BERT를 1층 더 누적시킨 구조로 구성이 되어있습니다. 따라서 BERT에 비해 파라미터의 수가 2배 더 많습니다.
- 추상화된 문제 문장을 만드는 작업이 추가적으로 요구되기 때문에, 모델의 충분한 훈련을 위해서 더 많은 훈련 데이터가 필요하였습니다. 이 학습에 사용된 말뭉치인 C4(Colossal Clean Crawled Corpus)는 인터넷 문서에서 정제루틴을 거쳐서 만든 것으로 약 750GB에 달하는 양입니다. 이는 XLNet이나 RoBERTa에서 사용한 양의 6배에 해당합니다. (다만 Pre-training 중에는 이의 일부분만 사용하며 기존의 방법들과 다르게 한 번 본 데이터는 다시 보지 않습니다.)
T5는 분명 참신한 구조였습니다. 비록 파라미터의 크기가 커졌지만 750GB가 되는 데이터를 소화할 수 있다는 것을 보였기 때문입니다. 다만, 한편으로는 문제를 추상화하는 방법이 Naive하지 않았나는 생각이 듭니다. 문제 문장은 한정된 형태로만 기술되었으며 모델은 그 한정된 형태에 대해서만 답을 생성할 수 있었습니다. 그렇기 때문에 단순히 문제 문장으로 추상화하는 것은 언어를 깊게 이해시키는 소기의 목적을 달성하기에는 피상적이라 판단합니다.
빠르고 강하게 줄이기 (Faster and Stronger)
위의 Transformer를 더 많이 학습시키는 관점으로 바라보는 연구들을 다룰 때에는 해당 연구에서 제안된 구조와 그 구조들이 요구하는 데이터의 양을 기준으로 설명하였습니다. 원 BERT나 GPT에 비해 더 많은 데이터와 더 복잡한 구조가 요구되었기 때문입니다. 즉, 위의 연구들은 “Transformer에 원하는 바를 더하는” 것들이었습니다. 이에 비해 Transformer를 가볍고 빠르게 만드는 연구들은 “Transformer에서 덜어내는” 관점으로 진행되었기 때문에, 그 연구들에서 사용한 기법 위주로 설명하도록 하겠습니다.
Transformer.zip: Quantization and Pruning
양자화(Quantization)라고 불리는 기법은 원래 연속된 아날로그값을 불연속적인 디지털값으로 변환하는 것을 말하며, 정해진 단위값으로 근사시켜서 통일시키는 것을 일컫습니다. 양자화를 하게 되면 (얼마나 정밀하게 하느냐에 따라 다르겠지만) 필연적으로 정보가 손실됩니다. 즉, 데이터의 정밀도가 떨어지게 됩니다. 하지만 반대로 압축률이 올라갑니다. 즉, 더 적은 용량으로도 데이터를 나타낼 수 있게 됩니다. 대부분의 경우 신호의 정밀도는 큰 문제가 되지 않습니다. 왜냐하면 통상 데이터는 주요 대표값에 의해서 기술되기 때문입니다. 밑의 과자 사진에서 왼쪽은 24bit (1677만 색) 이미지이고 오른쪽은 불과 4bit (16색)이미지입니다. 수치적인 정밀도는 비교할 수 없이 줄었지만, 사진의 이미지가 꽤 잘 보존된 것을 확인할 수 있습니다.

신경망의 가중치도 마찬가지입니다. 만약 임의의 가중치 값을 K 개의 가중치 값으로 축소시킬 수 있다면, 모델의 크기를 대폭 줄일 수 있게 됩니다. 자연어처리에서의 신경망 가중치의 값은 대개 그 값 자체보다는 대략적인 크기나 경향성이 훨씬 중요하기 때문에 이러한 손실은 감수할 수 있는 것이라 하겠습니다.
가지치기(Pruning)는 신경망 내의 일부 가중치를 삭제하고 사용하지 않는 것입니다. 핵심은 성능에 영향을 많이 주는 가중치는 보존하면서 그렇지 않은 가중치들을 삭제하는 것입니다. 이 기법은 이미지 처리 분야에서 많이 연구가 된 부분으로, Song Han et. al이 원 VGGNet의 1/10 크기의 모델로도 동일한 성능을 나타내는 것을 보여주었습니다. 만약에 BERT가 더 많은 데이터를 소화할 수 있을 정도로 큰 모델이라면 이 모델에 대해서 ‘가지를 칠 수 있는’ 여지가 많다고 판단이 됩니다.
스탠포드의 Robin Cheong과 Robel Daniel은 Transformer 구조에 대해서 간단한 K-means Quantization과 Threshold 미만 가중치 쳐내기를 적용했을 때, 성능이 어떻게 변하는지 확인하였습니다. 실험은 WMT 2017 데이터셋에 대해 진행되었고, BLEU를 측정하였습니다. 양자화 방법의 경우, K-means (데이터 클러스터링 시에 상위 K개의 피벗값으로 대표화하는 방법), Binary Masking (Threshold 미만의 데이터값을 0으로 치환하는 방법으로 Threshold 고정(BS-Fixed) 과 변동(BS-Flexible)이 있음)을 적용하였습니다.
실험 결과를 분석해보면
- 데이터를 양자화 하는 경우 2배 이상의 압축을 했을 때도 성능의 하락이 적었으며 4 비트로 양자화하는 경우 오히려 8 비트 양자화에 비해서 더 높은 성능을 보여주었습니다.
- Attention 가중치를 1-bit로 양자화하는 경우도 성능의 큰 손실 없이 10배 정도의 압축률을 보여주었습니다. 아울러, Binary Masking으로 간단하게 구현한 1-bit 양자화는 K-means 방법보다 몇 배 빠르면서 더 높은 성능을 보여주었습니다.
- Pruning의 경우 80%까지 쳐냈을 때는 성능의 하락이 크지 않았지만 90%까지 쳐낸 경우 성능의 하락이 상당하였습니다. 저자들은 90%까지의 Pruning 될 수 있다는 것을 보인 다른 논문들의 결과를 재현하지 못하였으나 이는 Hyperparameter의 설정 등의 부수적인 조절이 부족하였기 때문으로 분석하였습니다.
많은 가중치를 삭제한 이후에도 BERT가 성능을 어느 정도 잘 보존한다는 것은 실제로 성능에 기여하는 가중치는 그렇게 많지 않다는 것을 시사합니다. Mitchell et al. 은 NeurIPS에서 발표한 Are Sixteen Heads Really Better than One? 에서 각 Attention block의 head가 얼마나 실제 성능에 기여하는지를 분석하였습니다. 분석한 결과에 따르면 실제로 작업에 기여하는 Attention Head는 전체 Head에 비해 일부분이며 이는 위의 실험에서 나타난 바와 같습니다.
DistilBERT: Knowledge Distillation
예를 들어 분류 문제를 푸는 상황을 가정해봅시다. 원래 데이터는 그 이미지가 어떤 물체에 해당하는지에 대한 정답 라벨(Hard Label)이 달려있을 것입니다. 이 이미지를 잘 훈련시킨 모델(선생 모델)에 전달하게 되면, 대부분 결과도 그 정답과 일치할 것입니다. 한 가지 놀라운 사실은, 모델이 만들어낸 결과 분포가 실제 이미지를 더 풍부하게 표현한다는 것입니다. 즉, 원래 정답 관점에서는 정답 이외에 대한 정보가 없지만, 한번 모델에서 풀어나온 결과는 정답 외에도 다른 물체에 대한 정보를 담고 있게 됩니다. 이렇게 정보가 묻어 나오는 것이 마치 석유의 부산물들이 증류탑에서 나오는 양상과 같기 때문에 이를 지식 증류라고 일컫습니다.

원래 모델이 생각하는 데이터의 정보가 풀어나온 데이터로 새로 학습시키게 되면 간접적으로 선생 모델이 학습한 바를 반영하게 되므로 더 효율적으로 모델을 학습시킬 수 있으며, 새로 배우는 모델(학생 모델)은 상대적으로 더 적은 규모로 구성될 수 있습니다. 이것이 Hinton et al. 이 제시한 지식 증류의 핵심입니다.
BERT에 대해서도 똑같은 방법을 사용할 수 있습니다. Huggingface의 Sanh et al. 은 원 BERT 모델에 대해서 훈련시킨 다음, 원 모델이 예측한 Masked LM 분포를 이용하여, 레이어 수가 절반인 새 모델을 학습시켰습니다.

실험 결과, 파라미터 수가 절반임에도 불구하고 원 BERT의 성능과 대등한 성능을 보였으며, 심지어 CoLA, SST-2 등 몇몇 작업에 대해서는 더 우수한 성능을 보였습니다. 즉, Pretrain 단계에서 BERT 모델의 출력은 해당 단어에 대한 언어 모델 그 이상의 정보를 가지고 있다는 것을 시사합니다.
ALBERT: A Lite Bert
ALBERT는 구글과 토요타 연구소에서 새로 제시된 모델입니다. 기존의 BERT와 BERT x-large 모델은 성능은 좋았지만 너무 모델 크기가 크다는 문제가 있었습니다. 실험 결과, BERT x-large (모델 사이즈: 1270M)의 경우 RACE 데이터에 대해서 더 작은 모델인 BERT보다 더 낮은 성능을 보였습니다. 따라서 본 논문의 저자들은 모델 가중치의 효율적인 재활용과 더 어려운 문제를 도입함으로써 조금 더 충실한 구조를 만들고자 하였습니다.
ALBERT의 특징은 다음과 같습니다.
- 임베딩 파라미터 재구성하기: 기존의 BERT와 RoBERTa나 XLNET등의 구조에서 단어 임베딩의 크기 (E) 는 그 내부의 은닉 레이어(Hidden Layer)의 크기 (H) 와 동일하였습니다 (E=H). 그렇지만 이 방법은 효율적이지 못합니다. 단어 임베딩은 “문맥과 상관 없는 단어의 표현”이고, 은닉 레이어는 “문맥이 반영된 단어의 표현”이기 때문입니다. 당연하게 후자가 전자보다 더 복잡한 정보를 가지고 있고 따라서 그 크기도 더 커야합니다 (E<H). 본 논문에서는 임베딩과 은닉층을 분리하였습니다. 이에 따라 어휘 수 V에 대해서 파라미터 크기는 O(VxH) 에서 O(VxE) + O(ExH) 로 크게 감소하였습니다. 표는 ALBERT의 파라미터를 나타낸 것입니다.
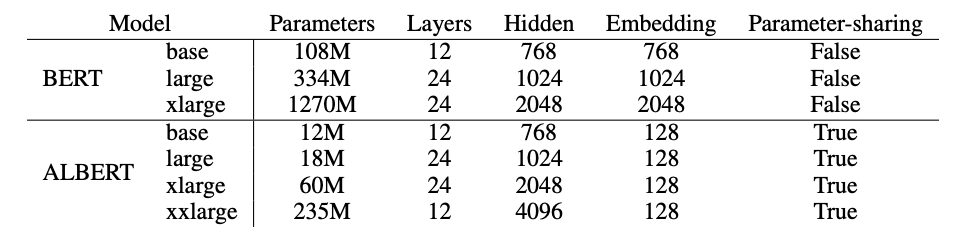
-
파라미터 공유하기: ALBERT에서는 파라미터의 효율성을 위해서 각 레이어에 대한 파라미터를 공유하였습니다. 원래 표준 Transformer보다 공유된 형태의 구조가 더 나은 성능을 보인다는 것은 Universal Transformer (Dehghani et al, 2019)에서 제안되었습니다. 이에 저자들은 파라미터를 공유한 구조에 대해서 실험하였고, 파라미터 학습을 안정화하는 효과를 얻었습니다.
- 문장간 순서 맞히기 (Sentence Ordering Prediction): 위에서도 계속 이야기하였지만, 다음 문장 맞히기 작업은 상대적으로 쉬워서 모델 성능 향상에 기여하지 못하는 것으로 나타났습니다. 저자들은 이 대신 두 문장간의 순서를 맞히는 작업을 도입하였습니다. 즉, 서로 연속된 두 문장에 대해서 문서 내 등장한 올바른 순서와 두 문장 간의 자리를 바뀐 순서를 데이터로 넣어서 모델로 하여금 올바른 순서를 판정하도록 하였습니다. 이 작업은 단순히 비슷한 단어에 대해서 알고 있는 것만으로는 맞히기 어렵기 때문에 더 강력하게 모델을 학습시킬 수 있었습니다.
- 아울러 단어 하나의 Masking 대신 N-gram Masking을 사용하였고, 항상 데이터 세그먼트의 크기를 512로 맞춰주되 10%확률로 더 작은 세그먼트를 입력받도록 하였습니다.
실험 결과를 살펴보면 다음과 같습니다.
- ALBERT는 더 적은 수의 파라미터를 사용하는 경우에도 빠르고 우수한 성능을 보여줍니다. 특히 기존의 BERT가 단순히 XLarge 형태로 파라미터를 늘렸을 때 성능이 하락한 것과 다르게 ALBERT의 XLarge 모델은 파라미터 크기에 따라 성능이 상승하는 것을 볼 수 있었습니다. 이는 ALBERT가 잉여 파라미터가 BERT에 비해 더 적고 전체 모델이 훨씬 효율적으로 훈련됨을 의미합니다.
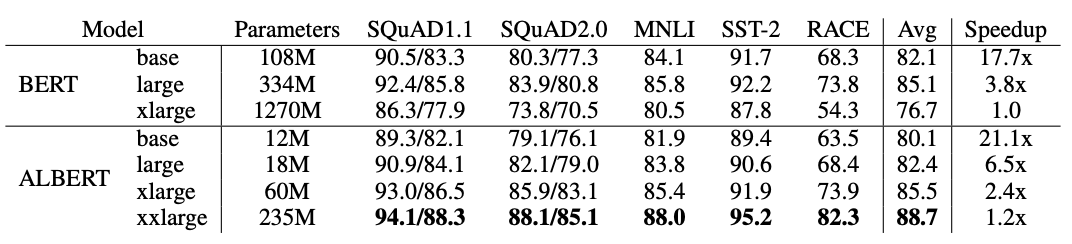
- 아울러 문장간 순서 맞히기 (SOP)가 다음 문장 맞히기 (NSP)에 비해 더 우수한 성능을 나타내는 것으로 보였습니다. 상술한 논문들에서 시사되었던 바와 같이 NSP는 (1) 언어의 미묘한 특성을 잘 반영하지 못하고 유사한 단어에 편향되어 있고 (2) 단어에 대한 정보는 이미 LM에서 잘 학습되었기 때문으로 보입니다.

이 글을 마치며
현재도 많은 연구자들이 한편으로는 언어 모델의 성능을 향상시키기 위해, 다른 한편으로는 언어 모델을 실제 제품에서 사용할 수 있도록 연구에 힘을 쓰고 있습니다. 그리고 저희는 이러한 연구들이 머지 않아 그 결실을 맺으리라고 믿습니다. LSTM이 그러했고, Transformer가 그러했고, BERT가 그러했기 때문입니다. 스캐터랩의 엔지니어들은 다가올 그 날을 깨어 기다리며, 더 사람다운 대화 인공지능을 만들기 위해 노력하겠습니다.
References
-
Papers
- Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014)
- Attention is All you Need (Vaswani et al., 2017)
- Language Models are Unsupervised Multitask Learners (Radford et al., 2019)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2019)
- XLNet: Generalized Autoregressive Pretraining for Language Understanding (Yang et al., 2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (Liu et al., 2019)
- Multi-Task Deep Neural Networks for Natural Language Understanding (Liu et al., 2019)
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
- transformers.zip: Compressing Transformers with Pruning and Quantization (Robin Cheong and Robel Daniel, 2019)
- Are Sixteen Heads Really Better than One? (Michel et al., 2019)
- Distilling the Knowledge in a Neural Network (Hinton et al., 2015)
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (Sanh et al., 2019)
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, (Lan et al., 2020)
- Universal Transformers (Dehgani et al., 2019)
-
Articles