TFX 머신러닝 파이프라인 사용하기
팀에서 필요한 학습 파이프라인 구축하기

핑퐁팀에서는 루다의 대화 성능을 지속적으로 발전시키기 위해 Continual Learning을 연구하고 있어요. 이를 위해 새로운 데이터를 받으면 모델을 학습하고, 평가하는 일련의 과정을 수행해야 하는데, 이 모든 과정에 사람이 직접 개입하는 것은 너무 효율적이지 않았어요. 그래서 반복되는 과정을 하나의 파이프라인으로 만들어 관리할 필요성이 생겼고, 이를 TFX로 해결해 보고자 해요.
이번 블로그에서는 핑퐁팀에서 효과적인 머신러닝 파이프라인 구축을 위해 TFX의 어떤 구성 요소들을 적용하는지 알려드릴게요. 이를 위해서 TFX 커스텀 컴포넌트를 다루는데, 어떻게 구현할 수 있는지 공유해 드리고자 합니다. 🙂
TFX가 뭐죠? 🤔
TFX(TensorFlow Extended)는 Tensorflow를 십분 활용하여 데이터 가공부터 학습, 검증까지 일련의 과정을 파이프라인으로 제공하는 프레임워크에요. 그뿐만 아니라 모델을 실제 프로덕션에 서빙하기 전 실 서버와 같은 환경에서 트래픽을 보내보고 검증하거나, 모델 서빙에 필요한 Warmup 데이터가 포함된 모델로 생성하고 서빙까지 모든 과정을 지원해요.
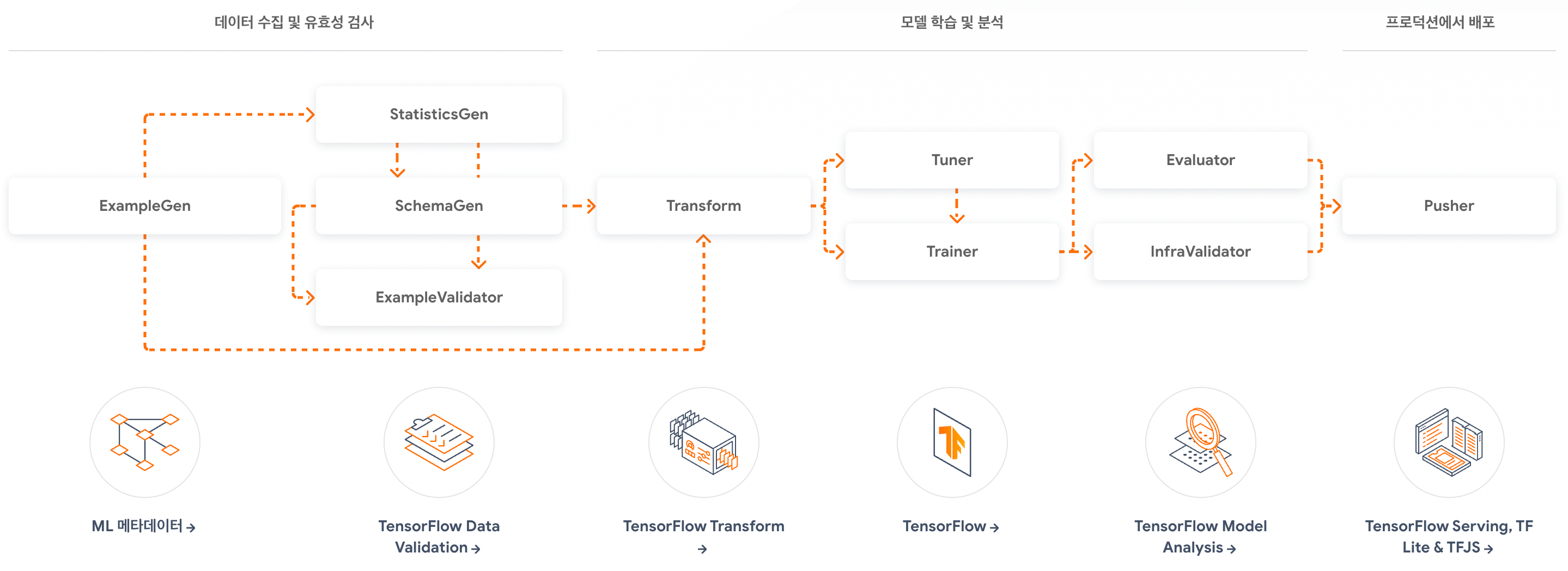
위 그림을 보면 TFX의 개략적인 흐름을 파악할 수 있어요. 파이프라인이기 때문에 모든 과정을 각각의 컴포넌트로 구성할 수 있고, 개별적으로도 분리해서 사용할 수도 있답니다.
핑퐁팀에서는 TFX에서 제공하는 모든 컴포넌트들을 사용하지는 않고, 일부 컴포넌트들은 내부적으로 개발된 시스템들과 잘 어울리도록 커스터마이징해서 사용하고 있습니다. 대표적으로 지난 블로그에서 소개해 드린 Apache Beam을 활용해 Dataset Registry로부터 데이터를 불러오는 DatasetsExampleGen이 있죠.
이제부터 핑퐁팀에서 TFX를 어떻게 활용하고, 사내 시스템에 맞게 커스텀 컴포넌트를 어떻게 구현했는지 이 두 가지 측면에서 자세히 알아볼게요.
커스텀 컴포넌트를 만들어보자 ⚙️
TFX는 기본으로 제공되는 컴포넌트 외에 별도로 필요한 로직을 담아 새로운 컴포넌트를 만들 수 있도록 가이드를 제공하고 있어요. 먼저 각 컴포넌트의 구조와 동작 방식을 살펴보겠습니다. 그런 다음 커스텀 컴포넌트를 만들기 위한 방법과 구현체를 살펴볼게요!
컴포넌트의 구조와 동작 방식
모든 컴포넌트는 다음과 같이 3가지 요소로 구성되어 있어요.
- Component Specification: 컴포넌트의 입출력 데이터에 대한 스펙을 정의합니다.
- Component’s Executor: 입력으로 받은 데이터들을 처리하여 스펙에 정의된 출력 데이터로 반환해 줍니다.
- Component Interface: 컴포넌트를 사용하기 위해 ComponentSpec과 Executor를 조합하여 인터페이스를 제공합니다.
파이프라인이 실행되면 정의된 순서에 따라 컴포넌트들이 실행될 텐데, 컴포넌트 사이에서 데이터는 아무렇게나 전달받지 않고 채널을 통해 아티팩트로 주고받을 수 있죠.
여기서 채널과 아티팩트가 무엇인지 궁금할 수 있어요. API 문서에 따르면 TFX 채널의 의미는 Producer-Consumer 사이를 잇는 가상의 컨셉이라고 합니다. 즉, 어느 한 컴포넌트로부터 다른 컴포넌트까지 데이터를 흐르게 할 수 있는 통로라고 생각하시면 돼요. 그리고 아티팩트는 구글의 MLMD로 관리되는 데이터이며, 파이프라인의 결과물이 주로 저장됩니다. 아티팩트는 데이터와 데이터의 추가적인 정보들이 담긴 메타데이터로 나누어 저장하는데, 메타데이터는 MLMD 내부 데이터베이스에 기록되고, 실제 데이터는 GCS와 같은 스토리지에 저장됩니다.
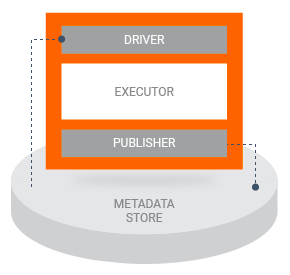
파이프라인 실행 시 데이터(아티팩트)가 어떻게 컴포넌트 입력으로 들어올까요? TFX 내에는 컴포넌트의 실행을 보조하는 Driver와 Publisher라는 요소가 있어요. 파이프라인 실행 시 Driver는 컴포넌트 스펙에 정의된 입력 아티팩트를 파악하여 Metadata Store에서 불러오고 컴포넌트에 넣어줍니다. 그런 뒤에 컴포넌트 실행이 끝나면 Publisher가 출력 아티팩트를 Metadata Store에 기록해요. 보통의 경우 이 두 가지는 커스터마이징 할 일이 없어요. (ExampleGen 같은 경우 데이터 버전에 따라 다르게 불러올 수 있어야 하기 때문에 커스터마이징 하여 사용되고 있습니다.)
커스텀 컴포넌트 구현 방법
가이드에 따르면 커스텀 컴포넌트를 구현하기 위한 방법은 다음과 같이 세 가지가 있어요.
- Python function-based components
- Container-based components
- Fully custom components
상위 두 가지 방법은 나름 직관적이고 쉽게 구현할 수 있어서 이 글에서는 다루지 않을게요. 다만 마지막 방법은 컴포넌트 구조 전체를 커스터마이징 하는 방법이라 이해하기도 어렵고 구현하기도 쉽지 않아요. 그래서 이 부분에 대해 좀 자세히 알아볼까 해요.
컴포넌트 스펙과 인터페이스
컴포넌트를 구현하기 위해서 먼저 ComponentSpec 클래스를 정의하여 입출력 스펙을 정의해야 해요. 이는 Executor에서 실행될 때 스펙에 정의된 키값들로 입력을 받아오게 되고, 파라미터의 경우 값 자체를, 아티팩트의 경우 tfx.types.Artifact 타입의 오브젝트를 받아옵니다. 이때 INPUTS와 OUTPUTS는 ChannelParameter 타입으로 선언해야 하며, 각 파라미터들은 ExecutionParameter로 선언해야 해요.
from tfx.types.component_spec import ChannelParameter, ComponentSpec, ExecutionParameter
from tfx.types import standard_artifacts
class MyComponentSpec(ComponentSpec):
PARAMETERS = {
"num_samples": ExecutionParameter(type=int),
"config": ExecutionParameter(type=str),
}
INPUTS = {
"examples": ChannelParameter(type=standard_artifacts.Examples),
}
OUTPUTS = {
"model": ChannelParameter(type=standard_artifacts.Model),
}
ExecutionParameter에서 받을 수 있는 타입은 bool, int, float, str, bytes의 기본 타입이거나 protobuf 타입이어야 해요. protobuf라 할지라도 내부적으로는 str로 변환되어서 주입되니 Executor에서 한 번 변환하는 작업이 필요합니다. 만약 입력 파라미터를 json 형식으로 받고 싶을 때도 json.dumps 명령어와 같은 JSON Serialization이 필요해요.
컴포넌트 스펙이 정의되면 인터페이스 클래스도 생성하여 파이프라인 코드 작성 시 컴포넌트를 사용할 수 있도록 만들어 주어야 합니다.
from tfx import types
from tfx.dsl.components.base import base_component, executor_spec
from tfx.types import standard_artifacts
from my_component import executor
class MyComponent(base_component.BaseComponent):
SPEC_CLASS = MyComponentSpec
EXECUTOR_SPEC = executor_spec.ExecutorClassSpec(executor.Executor)
def __init__(self,
num_samples: int,
config: Dict[str, str],
examples: types.Channel = None):
output_model = types.Channel(type=standard_artifacts.Model)
spec = MyComponentSpec(num_samples=num_samples,
config=json.dumps(config),
examples=examples,
model=output_model)
super().__init__(spec=spec)
인터페이스 클래스 내의 SPEC_CLASS 변수에 앞서 작성한 ComponentSpec 클래스를 대입하고, EXECUTOR_SPEC 변수에 후술할 Executor를 대입해서 Executor와 ComponentSpec을 연결해 주어야 해요. 이후에 __init__ 함수에서는 인자를 받아 ComponentSpec 객체를 생성하여 super() 함수를 호출해야 합니다. 생성할 때 키워드 인자로 정의한 스펙에 맞도록 각 항목을 입력해 줘요. 이때 출력 아티팩트는 초기화할 때 채널을 생성하여 스펙에 넣어줄 수 있도록 해야 해요.
주의할 점은 __init__ 함수에서는 주어진 Spec에 맞도록 컴포넌트를 생성만 해주는 역할이라 실제 데이터를 읽어오진 못해요. 따라서 이 함수에서는 데이터 전처리를 할 수 없어요!
Executor
이제 컴포넌트가 어떻게 데이터를 다루어야 하는지 구현해야 해요. 함수 인자는 컴포넌트 스펙에 정의된 것들이 주입되게 됩니다.
input_dict: 컴포넌트 스펙의INPUTS과 매핑되는 아티팩트output_dict: 컴포넌트 스펙의OUTPUTS와 매핑되는 아티팩트exec_properties: 컴포넌트 스펙의PARAMETERS와 매핑되는 파라미터
from tfx.dsl.components.base import base_executor
from tfx.types import artifact_utils
class Executor(base_executor.Executor):
def Do(
self,
input_dict: Dict[str, List[Artifact]],
output_dict: Dict[str, List[Artifact]],
exec_properties: Dict[str, Any],
):
num_samples = exec_properties.get("num_samples")
config = json.loads(exec_properties.get("config"))
examples_artifact = artifact_utils.get_single_instance(input_dict["examples"])
model_artifact = artifact_utils.get_single_instance(output_dict["model"])
# 아래처럼 경로에서 데이터를 불러와야 합니다.
# load_examples() 는 가상의 함수로, 아티팩트 경로에서 데이터를 불러옵니다.
examples = load_examples(examples_artifact.uri)
# 로직을 작성합니다.
# 아티팩트는 uri 속성에 자신이 바라보는 경로가 지정되어 있습니다.
# write_model()는 가상의 함수로, examples를 입력으로 받아 model을 학습하고나서
# 최상의 checkpoint를 model_artifact에 기록합니다.
write_model(model_artifact.uri, examples)
컴포넌트 간 아티팩트를 사용하는 방법은 일반적인 파일 시스템을 사용하는 방법과 비슷해요. artifact.uri에 아티팩트가 담고 있는 데이터 위치가 있고, 여기서 데이터를 불러와 처리한 후 다시 출력 아티팩트에 담는 방식이죠. 단, 주의할 점은 이 경로는 로컬 경로에 한정되어 있는 것이 아니라, 클라우드에서 실행할 경우 GCS 경로가 담기게 될 수 있어요. 따라서 파이썬 기본 함수인 open과 같은 함수를 사용해서 불러오는 것이 아닌 GFile 또는 TFX에서 구현된 io_utils를 사용하는 방법으로 불러와야 합니다.
Apache Beam과 함께라면
핑퐁팀에서는 Apache Beam으로 대규모 데이터를 처리하고 있고, 사내 라이브러리들도 Apache Beam을 사용한 경우가 많아요. TFX에서는 Apache Beam으로 작성된 데이터 파이프라인을 별다른 처리를 하지 않아도 쉽게 적용할 수 있어요.
앞서 설명드린 방법과 바뀌는 점은 딱 두 가지, 컴포넌트 인터페이스 클래스와 Executor 클래스에요. 이를 각각 base_beam_component.BaseBeamComponent와 base_beam_executor.BaseBeamExecutor를 상속받도록 바꿔주어야 해요.
# Component Interface
from tfx.dsl.components.base import base_beam_component
class MyBeamComponent(base_beam_component.BaseBeamComponent):
pass
# Executor
from tfx.dsl.components.base import base_beam_executor
class Executor(base_beam_executor.BaseBeamExecutor):
def Do(
self,
input_dict: Dict[str, List[Artifact]],
output_dict: Dict[str, List[Artifact]],
exec_properties: Dict[str, Any],
):
with self._make_beam_pipeline() as pipeline:
# Pipeline 작성
Executor 내에서 self._make_beam_pipeline() 함수로 Beam 파이프라인을 생성하여 작성하면 돼요. Apache Beam 컴포넌트를 작성하면 파이프라인 코드 작성 시 MyBeamComponent().with_beam_pipeline_args(["--some-options"])처럼 컴포넌트 별로 Beam의 실행 인자를 넘겨줄 수 있답니다.
새로운 데이터로부터 모델까지 🚀
핑퐁팀에서는 모델 학습에 사용되는 데이터들을 내부적으로 개발된 Dataset Registry에 올려놓고 사용하고 있어요. Dataset Registry에는 csv, jsonl 등 어느 타입이든 상관없이 업로드할 수 있어요. Apache Beam에서 Dataset Registry로부터 데이터를 저장하거나 불러오는 경우가 많은데, 이 과정을 TFX 컴포넌트로 변환하는 작업 역시 어렵지 않아요! 핑퐁팀에서는 위에서 설명한 BaseBeamComponent를 사용하여 Dataset Registry와 연동되는 컴포넌트를 구현했어요.
class _DatasetsExampleGenSpec(ComponentSpec):
PARAMETERS = {
"transform_fn": ExecutionParameter(type=str, optional=True),
"module_file": ExecutionParameter(type=str, optional=True),
"input_config": ExecutionParameter(type=example_gen_pb2.Input),
"output_config": ExecutionParameter(type=example_gen_pb2.Output),
"custom_config": ExecutionParameter(type=str, optional=True),
"range_config": ExecutionParameter(type=range_config_pb2.RangeConfig, optional=True),
"builder_config": ExecutionParameter(type=str, optional=True),
}
INPUTS = {}
OUTPUTS = {
"examples": ChannelParameter(type=standard_artifacts.Examples),
}
TYPE_ANNOTATION = Process
class DatasetsExampleGen(base_beam_component.BaseBeamComponent):
"""Dataset Registry 로부터 데이터를 불러와 Example을 생성합니다."""
SPEC_CLASS = _DatasetsExampleGenSpec
EXECUTOR_SPEC = executor_spec.BeamExecutorSpec(executor.Executor)
DRIVER_CLASS = driver.DatasetsDriver
def __init__(
self,
name: Optional[str] = None,
transform_fn: Optional[Union[str, data_types.RuntimeParameter]] = None,
module_file: Optional[Union[str, data_types.RuntimeParameter]] = None,
input_config: Optional[Union[example_gen_pb2.Input, data_types.RuntimeParameter]] = None,
output_config: Optional[Union[example_gen_pb2.Output, data_types.RuntimeParameter]] = None,
custom_config: Optional[Union[Dict[str, Any], data_types.RuntimeParameter]] = None,
range_config: Optional[Union[range_config_pb2.RangeConfig, data_types.RuntimeParameter]] = None,
builder_config: Optional[Union[Dict[str, Any], data_types.RuntimeParameter]] = None,
):
if name and input_config:
raise RuntimeError("Exactly one of name and input_config should be set.")
input_config = input_config or utils.make_default_input_config(name)
output_config = output_config or utils.make_default_output_config(input_config)
example_artifacts = types.Channel(type=standard_artifacts.Examples)
spec = _DatasetsExampleGenSpec(
transform_fn=transform_fn,
module_file=module_file,
input_config=input_config,
output_config=output_config,
range_config=range_config,
custom_config=json.dumps(custom_config),
examples=example_artifacts,
builder_config=json.dumps(builder_config),
)
super().__init__(spec=spec)
if udf_utils.should_package_user_modules():
udf_utils.add_user_module_dependency(
self,
standard_component_specs.MODULE_FILE_KEY,
standard_component_specs.MODULE_PATH_KEY,
)
TFX의 학습 데이터들은 기본적으로 TFRecord 기반으로 저장하고 사용되고 있어요. Dataset Registry는 다양한 형식의 데이터를 지원하다 보니 단 하나의 코드로 모든 데이터를 TFRecord로 변환하기에는 아직 무리가 있어서, 별도로 가이드를 제공해 주고 transform_fn 함수를 인자로 받아 변환하도록 되어있어요. 여기서 transform_fn과 같은 사용자 정의 함수(User Defined Function, UDF)를 인자로 받아 실행할 수 있도록 유틸을 TFX에서 udf_utils라는 이름으로 제공하여 적용할 수 있도록 해줍니다.
class _TransformToSerialized(beam.DoFn):
def process(self, example: Any):
yield from self.transform_fn(example)
class _DatasetsToExample(beam.PTransform):
def expand(self, pipeline: beam.Pipeline) -> beam.PCollection[tf.train.Example]:
return (
pipeline
| "ReadFromDatasets" >> datasets.ReadFromDatasets(self.name, self.version)
| "ParseExample" >> beam.ParDo(_TransformToSerialized(self.name, self.transform_fn))
| "ToTFExample" >> beam.Map(tf.train.Example.FromString)
)
class Executor(BaseExampleGenExecutor):
def GetInputSourceToExamplePTransform(self) -> beam.PTransform:
return functools.partial(_DatasetsToExample, transform_fn=self.transform_fn)
실제 Executor 로직에서 일부만 가져와 보았어요. BaseExampleGenExecutor을 상속받으면 입력되는 데이터를 TFRecord 형식으로 변환시키는 Beam Pipeline을 반환하는 GetInputSourceToExamplePTransform 함수를 구현하여 Custom ExampleGen을 완성할 수 있어요.
새로운 데이터가 들어온다면?
TFX는 새로운 데이터가 준비되면 코드 변경 없이 추가된 데이터로만 파이프라인을 구동시킬 수 있어요. TFX 문서의 Span, Version and Split 항목을 참조하시면 좋아요.
핑퐁팀에서 커스텀하여 사용하는 DatasetsExampleGen 컴포넌트는 Driver 또한 커스텀하여 사용하고 있어요. 이는 Span, Split 등과 같은 개념들을 핑퐁팀에서 사용하는 Dataset Registry에 적용하기 위해서예요. 기본 DRIVER_CLASS는 파일 시스템에서 불러올 때와 쿼리로 불러올 때에 대한 로직만 구현되어 있어서, 파일 시스템이 아닌 Dataset Registry는 Driver를 커스텀하여 사용해야 해요. 이때 Driver에 Span, Split을 직접 구현하지 않고, ExampleGen 컴포넌트에서 사용되는 InputProcessor를 별도로 구현하면 쉽게 구현할 수 있어요.
class DatasetsDriver(driver.Driver):
def get_input_processor(
self,
splits: Iterable[example_gen_pb2.Input.Split],
range_config: Optional[range_config_pb2.RangeConfig] = None,
input_base_uri: Optional[str] = None,
) -> input_processor.InputProcessor:
return DatasetsInputProcessor(splits, range_config)
class DatasetsInputProcessor(input_processor.InputProcessor):
def get_latest_span(self) -> int:
versions = datasets.ls(pattern)
# 불러온 데이터셋 목록에서 가장 최신의 버전을 찾습니다.
return datasets_utils.get_lastest_span(versions)
def get_latest_version(self, span: int) -> Optional[int]:
versions = datasets.ls(pattern)
# 불러온 데이터셋 목록에서 가장 최신의 버전을 찾습니다.
return datasets_utils.get_latest_version(versions, span)
DatasetsExampleGen 입력 인자로 아래처럼 선언하면 데이터셋이 추가 될 때 자동으로 감지하여 실행할 수 있어요.
input_config = example_gen_pb2.Input(
example_gen_pb2.Input.Split(name="train", pattern="klue_sts/v{SPAN}_{VERSION}-train"),
example_gen_pb2.Input.Split(name="eval", pattern="klue_sts/v{SPAN}_{VERSION}-test"),
)
example_gen = DatasetsExampleGen(input_config=input_config)
모델 학습까지
Datasets Registry로부터 불러온 데이터는 TFX 기본 컴포넌트로 학습까지 이어져요. ExampleGen에서 생성된 데이터가 TFRecord로 변환되기 때문에 별도의 스키마는 존재하지 않죠. 따라서 StatisticsGen과 SchemaGen을 통해 TFRecord가 어떤 스키마를 가지고 있는지 알아서 분석할 수 있도록 생성해요. 이때 데이터가 조금 복잡해서 자동으로 추론된 스키마가 맞지 않으면 직접 스키마를 작성해야 하고 ImportSchemaGen을 사용해서 스키마를 직접 넣어줄 수도 있죠.
Transform
데이터를 변환하는 Transform 컴포넌트도 사용하는데요, TFX는 이 컴포넌트를 가지고 대규모 데이터를 Dataflow 등의 Beam Runner로 사용하여 빠르게 처리할 수 있지만 핑퐁팀에서는 잘 활용하지는 않아요. 이미 별도로 데이터를 처리하고 있기 때문에 무거운 로직은 들어가 있지는 않고, 여기서는 문자열들을 토크나이징 하는데 사용하고 있습니다. 이때 TF의 Dataset이나 모델을 사용할 경우, 단순히 생성하는 것이 아니라 tft.make_and_track_object()를 사용해서 인스턴스를 생성해야 한다는 점은 주의해야 해요!
def preprocessing_fn(inputs: Dict[str, Any], custom_config: Dict[str, Any]) -> Dict[str, Any]:
tokenizer = tft.make_and_track_object(lambda: Tokenizer(...)
Trainer
Trainer 역시 TFX 기본 컴포넌트를 사용해요. 다만 로컬과 클라우드 환경을 구분하여 tfx.components.Trainer와 tfx.extensions.google_cloud_ai_platform.Trainer를 분기하여 사용하고 있어요. Transform으로부터 생성된 토크나이징 된 데이터를 입력받고, 최종적으로 서빙에 필요한 Signature 함수들을 담아 SavedModel 형식으로 내보냅니다. 이 Signature 함수는 모델 평가 시에도 사용되고, 사내에서는 평가할 때 입력 Signature가 조금 다르기 때문에 서빙용과 평가용 Signature 함수가 분리되어 있어요.
모델 준비 끝! 이제 서빙으로 📦
이제 학습까지 끝냈으니 서빙을 해야겠죠? 🙂 사내에는 데이터셋 말고도 모델을 위한 Model Registry가 있어요. 핑퐁팀에서는 TFX가 아닌 별도의 루트를 통해 서빙하고 있는데, 그 시작이 바로 Model Registry에 모델을 업로드 하는 거에요.
학습이 모두 끝나면 Model Registry로 업로드를 해야만 하는데, 이 또한 TFX 커스텀 컴포넌트로 별도로 구현해 사용하고 있어요. 학습된 모델을 Model Registry에 등록할 수 있도록 도와줘요. 필요에 따라 지난 블로그에서 설명한 Inferentia Neuron Compile도 가능하게 구현되어 있어 쉽게 사용할 수 있죠.
class Executor(base_executor.BaseExecutor):
def Do(
self,
input_dict: Dict[str, List[Artifact]],
output_dict: Dict[str, List[Artifact]],
exec_properties: Dict[str, Any],
):
model = artifact_utils.get_single_instance(input_dict.get("model"))
model_name = exec_properties.get("model_name")
model_version = exec_properties.get("model_version")
uploaded_model = artifact_utils.get_single_instance(output_dict.get("uploaded_model"))
# 모델을 불러와 Neuron Compile 진행
base_model = tf.keras.models.load_model(model.uri, compile=False)
neuron_model = tfn.trace(base_model, _generate_inputs(model.uri))
tf.saved_model.save(neuron_model, uploaded_model.uri, signatures=_signature_fn(model.uri))
# Model Registry에 등록
models.register(uploaded_model.uri, model_name, model_version)
마치며
TFX의 커스텀 컴포넌트에 관한 문서가 많이 없어요. 공식 문서에는 예시 코드를 보여주면서 이렇게 저렇게 작성하면 된다고 나와있지만, 복잡한 로직을 구현하기에는 예시 코드만으로는 버거웠죠. TFX 라이브러리를 하나씩 파헤쳐 보고 내부 컴포넌트들이 이렇게 작성되어 있구나, 이렇게 동작하고 있구나 이해를 해보고 글을 작성해 보았어요! 글에서 알아본 것보다 TFX 활용 방법에 대해 더 많은 것이 있으니 한 번 찾아보시는 것을 추천드려요! 🙂
MLOps의 여러 복잡한 문제를 같이 해결해 보고 싶은 분들이 있으시다면 언제든지 채용 공고를 참고해 주세요!