VPT: 다이아몬드 곡괭이를 만들기 위한 여정
OpenAI에서 어떻게 다이아몬드 곡괭이를 만들었는지 알아봅니다. (VPT)

들어가며
지난 6월 22일, OpenAI와 브리티시컬럼비아대학의 연구진은 “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”라는 논문을 발표했습니다. 논문의 요지는 요약하자면 다음과 같습니다.
“우리는 마인크래프트에서 다이아몬드 곡괭이를 만드는 모델을 학습시키는 것에 성공했습니다.”
언뜻 보면 그다지 특별하지 않아보입니다만, 강화 학습을 연구하는 입장에서 바라봤을 때 상당히 인상적인 연구였습니다. 왜냐하면 이전까지는 그 누구도 마인크래프트에서 다이아몬드 곡괭이를 만드는 모델을 학습시키지 못했기 때문입니다. 본 글에서는 무슨 이유로 이 문제가 어려워서 그동안 풀리지 않았던 것인지, 또 OpenAI의 연구진은 어떤 방식으로 이 문제를 해결했는지를 중점으로 논문을 가볍게 리뷰해 보겠습니다.
1. 강화 학습, 탐색과 활용, 그리고 모방 학습
우리가 “모델을 가르친다”, “모델을 학습시킨다”라고 말한다면, 그 말은 모델이 주어진 문제에 대해 우리가 의도한 대로 행동하도록 만든다는 뜻입니다. 강화 학습에서는 각 문제를 환경(Environment), 문제에 대한 모델의 응답을 행동(Action) 이라는 용어로 표현합니다. 강화 학습의 목표는 모델이 주어진 환경에 알맞은 행동을 하게 만드는 것, 그래서 보상(Reward)을 많이 얻도록 하는 것입니다.
기본적으로 강화 학습은 모델의 행동을 바탕으로 이루어지며, 따라서 모델이 어떻게 행동할지 결정하는 과정은 매우 중요합니다. 강화 학습에서는 그 과정을 탐색(Exploration) 과 활용(Exploition)의 개념을 통해서 기술합니다.
이해를 돕기 위하여 간단한 예시를 들어보겠습니다. 회사원 핑퐁씨는 오늘도 열심히 일하고 있었습니다. 일하다보니 어느덧 점심시간이 되었습니다. 핑퐁씨에 자연스럽게 떠오른 질문: ‘오늘은 무엇을 먹지?’ 그래서 핑퐁씨는
- ‘다른 맛있는 곳을 찾아가 볼까?’라고 생각하며 새로운 식당을 찾기 시작했습니다. (탐색)
- ‘괜히 모험하지 말고, 먹던 거 먹어야겠다’라고 생각하며 늘 가던 단골집으로 향했습니다. (활용)
탐색은 어떤 상황에서 최적의 행동이 아닌 다른 행동을 시도하는 것입니다. 물론 그 과정에서 단기적으로는 손해를 보게 됩니다만(=”새로 찾아갔던 식당이 영 별로였어”) 장기적으로 더 나은 방향(=”찐맛집을 발견했네!”)으로 행동할 수 있게 됩니다. 활용은 반대로 어떤 상황에서 알려진 최적의 행동을 수행하는 것입니다. 탐색과는 반대로 그 상황에서는 손해를 보지 않지만,(=”지뢰를 밟느니 먹던 데서 먹는 게 낫지”) 더 나은 맛집을 찾아갈 가능성은 없어지게 됩니다. 당연한 말이지만 효과적인 문제 풀이를 위해서는 더 좋은 행동을 찾는 탐색과 배운 바대로 행동하는 활용 모두 중요합니다.
다시 핑퐁씨의 예로 돌아가봅시다. 어느 날, 핑퐁씨는 낯선 도시로 장기출장을 가게 되었습니다. 출장지에 관한 사전정보가 없었던 핑퐁씨는 매일 점심마다 새로운 식당을 시도해볼 수 밖에 없었죠. 그 과정에서 정말 맛없는 집을 간 적도 있었고, 운 좋게 맛집을 찾아간 경우에도 지뢰 메뉴를 골랐던 적도 있었습니다. 보다 못한 동료 한 분이 주변 식당에 대한 리뷰를 정리해서 주셨습니다. 리뷰를 확인한 핑퐁씨는 이제 더 맛집을 빠르게 찾아갈 수 있게 되었습니다.

처음에 식당을 찾아 헤맸던 핑퐁씨처럼, 초기 모델은 강화 학습 과정에서 많은 시행착오를 겪습니다: 시행착오가 잦으면 모델이 어떤 행동을 취했을 때 높은 보상을 얻는지 알기 어렵기 때문에 학습 효율이 떨어집니다. 이 때, 다른 모델의 ‘리플레이’(Replay)을 참조할 수 있다면 이런 초기의 시행착오를 피할 수 있어서 더 효율적으로 모델을 학습할 수 있습니다. 이렇게 다른 플레이어나 모델의 행동을 따라하여 학습 효율을 높이는 기법을 모방 학습(Imitation Learning)이라고 부르며 바둑이나 스타크래프트 등의 게임을 위한 인공지능을 개발하는 데 활용되고 있습니다.
2. 왜 이 문제가 어려운가?
이제 다이아몬드 곡괭이를 만드는 모델을 학습시키기 어려운 이유를 살펴봅시다.

첫 번째 이유는 참조할 만한 리플레이가 없어서입니다. 바둑이나 체스는 각 플레이어의 행동이 기보의 형태로 저장되어 있고, 스타크래프트 등의 RTS 게임은 리플레이 파일 내에 게임 오브젝트(유닛, 건물, 지형) 등의 정보와 각 프레임에서의 플레이어의 입력이 저장되어있습니다. 하지만 마인크래프트는 1인칭 샌드박스 게임으로, 제3자에게 공유할 수 있는 형태의 리플레이 파일을 기본으로 제공하고 있지 않습니다. 물론 플레이 영상은 아주 많이 찾아볼 수 있지만, 해당 영상에 연동하여 플레이어의 입력이 저장되어 있지 않은 것이 문제입니다.
두 번째 이유는 행동의 방향성이 모호해서입니다. 위에서도 말했듯이 마인크래프트는 샌드박스 게임입니다. 마인크래프트에도 엔딩이 있기는 합니다만, 대부분의 플레이어는 엔딩과 별개로 각자 자기가 원하는 형태로 게임을 즐깁니다. 플레이어마다 게임을 즐기는 방식이 다르다는 것은 각자가 어떻게 행동하는지가 제각각이라는 뜻이며, 모델을 학습하는 입장에서 뚜렷한 신호를 줄 수 없다는 뜻이기도 합니다. 위에서 말씀드렸던 바둑이나 스타크래프트에서는 소위 ‘정석’이나 ‘빌드’라고 부르는 방식들이 잘 알려져있고, 대부분의 플레이어가 그런 방식으로 플레이하는 것과 대조적입니다.
마지막 이유는 한 목표를 달성하기 위한 선행 단계들이 많아 각 단계를 학습하는 것이 어려워서입니다. 다이아몬드 곡괭이를 만드는 과정을 살펴보면 다음과 같습니다.(각 단계에서 수행하는 반복작업은 생략하였습니다만 실제로는 재료 확보를 위해 많은 반복이 필요합니다.)

이렇게 선행 단계들이 많은 작업을 모델에게 학습시키는 것은 정말 어렵습니다. 새로운 작업을 수행하는 방법을 배우면, 기존의 작업을 수행하는 방법을 잊어버리는 현상(Catastrophic Forgetting)이 발생하기 때문입니다. RTS 게임이나 격투 게임에서 진행에 따라 목표나 게임 양상이 크게 바뀌지 않는 것과 비교해보면, 왜 이 문제가 어려운지 이해할 수 있을 것입니다.
3. 데이터 구축: Inverse Dynamic Model & Data Cleaning
이 문제를 풀기 위하여, OpenAI의 저자들은 다음과 같이 생각했습니다: ‘마인크래프트 동영상은 인터넷에 많으니까, 해당 동영상에서 플레이어가 어떤 키를 눌렀는지를 예측하는 모델만 있다면, 방대한 양의 리플레이를 만들어낼 수 있지 않을까?’ 이를 위해서 저자들은 먼저 소수의 마인크래프트 플레이어들에게 마인크래프트를 플레이하도록 주문하였습니다. 해당 플레이어들이 플레이했던 PC에는 리플레이를 기록하는 특별한 녹화 모드가 설치되어 있어서, 게임 내 매 틱마다 플레이어가 보는 화면과 대응되는 플레이어의 입력을 동영상 리플레이의 형태로 저장하였습니다. 저자들은 총 2천 시간에 달하는 ‘마인크래프트 리플레이’를 확보할 수 있었으며, 이 데이터를 활용해서 저자들은 “화면을 보고 입력을 역으로 예측”하는 Inverse Dynamic Model (IDM)을 훈련할 수 있었습니다. 특기할 점은 과거의 화면만을 참조하는 일반적인 예측 학습과 다르게, 해당 IDM은 미래의 화면 또한 참조하여 어떤 행동을 수행했는지를 예측한다는 점입니다.
\[P_{IDM}(a_t|o_1,...o_t,...o_T)\]
IDM을 학습한 이후, OpenAI의 저자들은 양질의 마인크래프트 동영상을 수집하는 작업에 착수하였습니다. 실제 모델이 실행되는 환경과 최대한 유사한 리플레이를 수집할 필요가 있었으므로, 실행 환경과 동일한 버전/모드/기기의 마인크래프트 영상만을 검색하여(“minecraft survival longplay”, “minecraft survival guide 1.16” 등등) 수집하였습니다. 물론 그렇게 수집된 영상들이 모두 조건을 만족한다는 보장이 없었습니다. 따라서 CLIP 모델을 활용하는 SVM 기반 분류기를 만들어서 원하는 카테고리(마인크래프트 생존 모드 - 별도의 중계 화면이나 모딩 없음)에 해당하는 영상만 골라내었습니다.
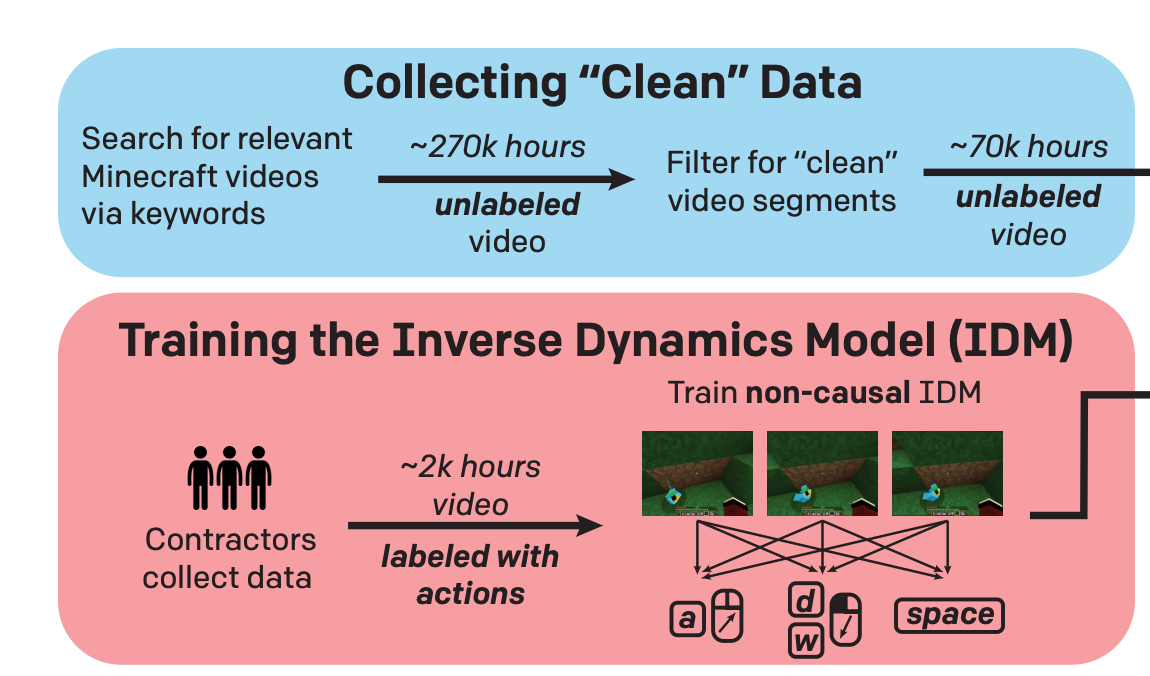
IDM과 정제 데이터를 활용하여 OpenAI의 저자들은 총 7만 시간에 달하는 리플레이 데이터를 구축할 수 있었습니다.
4. VPT: Video Pre-Training
OpenAI의 저자들은 구축한 대량의 리플레이 데이터에 대해서 모델이 리플레이의 행동을 따라하도록(=Negative Log-likelihood Loss를 최소화하도록) 720개의 V100을 동원하여(!) 9일동안 학습시켰습니다. (이는 요즘 NLP와 Vision 양 분야에서 활용되고 있는 Pre-Training - Fine-Tuning 프레임워크에서 Pre-Training 단계에 해당합니다.)
\[\underset{\theta}{\min} \sum_{t \in (1,2,...T)} -log\, \pi_{\theta} (a_t|o_1,..o_t), \quad \text{where } \, a_t \sim P_{IDM}(a_t|o_1,...,o_t,...o_T)\]해당 Video PreTrained 모델(이하 VPT 모델)의 Zero-shot 세팅에서의 성능을 확인하기 위하여 각 1시간의 에피소드마다 평균 몇 개의 아이템을 만들어냈는지를 확인해보았습니다. 그 결과, VPT 모델은 다른 기존의 강화 학습 모델보다 빠르게 나무를 확보하여 제작 테이블을 만들어내는 것을 확인할 수 있었습니다.

물론 사람이 1시간동안 평균 5.44개의 테이블을 만든 것에 비하면, VPT 모델이 평균 0.19개의 테이블만을 만든 것은 보잘 것 없어 보일지 모릅니다. 하지만 해당 모델은 테이블을 만드는 것뿐만 아니라 좀비와 동물을 사냥하고 나무열매를 채집하고 심지어는 사람들이 사용하는 “꼼수”인 기둥 점프(점프를 하고 착지하기 전에 타일을 설치해서 높은 위치에 올라가는 기술)를 따라하는 모습을 보여주었습니다. 즉, 마인크래프트라는 게임의 기본기를 구사할 수 있는 능력이 생긴 것입니다.
5. Fine-Tuning with Behavioral Cloning
비록 VPT 모델이 마인크래프트의 ‘기본기’를 익히는 데 성공했지만 세부적인 작업을 하는 데에는 부족한 면이 있습니다. 새로운 지식을 배우기 위해서는 NLP나 Vision Task에서와 같이 특정 지식에 대한 데이터셋으로 Fine-Tuning을 진행하여야 합니다. 논문의 저자들은 크게 다음 2가지 기초 아이템을 만드는 방법을 배우는 Fine-tuning 데이터셋을 준비했습니다.
- contractor_house: 마인크래프트 플레이어에게 10분동안 바로 채집할 수 있는 기본 재료(나무, 모래, 흙)만 활용하여 집을 완성하도록 주문하고 리플레이를 저장하여 구축한 데이터셋입니다.
- earlygame_keyword: “new world”, “let’s play episode 1”과 같이 초기 단계임을 나타내는 키워드를 가진 동영상들을 원 VPT 셋에서 골라낸 후, 해당 영상에 IDM을 적용하여 구축한 데이터셋입니다.
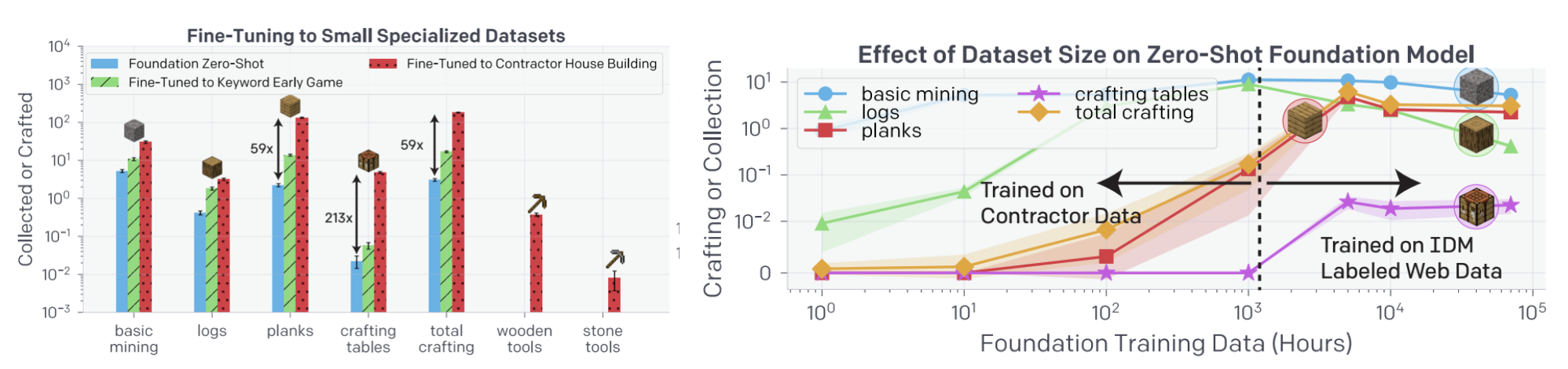
실험 결과, 이미 VPT 모델에서 수행 가능한 판자 만들기나 테이블 만들기 등의 작업도 상당히 능숙하게 수행하는 것을 확인하였으며, 심지어는 VPT 모델이 배우지 못했던 나무 도구 제작, 돌 도구 제작 방법도 학습하여 적용하는 것을 확인하였습니다.
Fine-tuning 시의 성능을 살펴보면 contractor_house 데이터셋이 earlygame_keyword 데이터셋에 비해서 더 효과적이라는 것을 알 수 있었습니다. 하지만 저자들은 이 결과를 자동으로 구축한 데이터셋이 쓸모가 없다고 해석해서는 안된다고 설명하며, 해당 데이터셋은 적은 비용으로도 대량으로 구축할 수 있다는 점을 강조합니다. 논문의 저자들은 해당 데이터셋을 다른 데이터셋과 같이 활용하는 경우, 충분히 성능을 높이는 데에 활용할 수 있다는 것을 보여주었습니다.
6. Fine-Tuning with Reinforcement Learning

위의 VPT 모델이 Fine-Tuning을 통해서 돌 도구를 만드는 능력이 있다는 것이 증명되었으므로, 논문의 저자들은 최종 목표인 “10분안에 다이아몬드 곡괭이 만들기”를 달성하는 데 착수하였습니다. 저자들은 모델이 다이아몬드 곡괭이의 선행 아이템들을 하나씩 만들 때마다 소정의 보상 값을 부여하였습니다. 이 때, 모델이 계속해서 한 기초 아이템을 만들도록 학습하는 것을 방지하기 위하여 하위 아이템을 통해 받을 수 있는 보상에 제한을 두고, 또 상위 아이템을 만들수록 더 큰 보상을 받도록 설계하였습니다. 해당 보상 함수를 활용하여 약 130만 에피소드로 248M 크기의 모델에 대한 학습을 진행하였습니다.
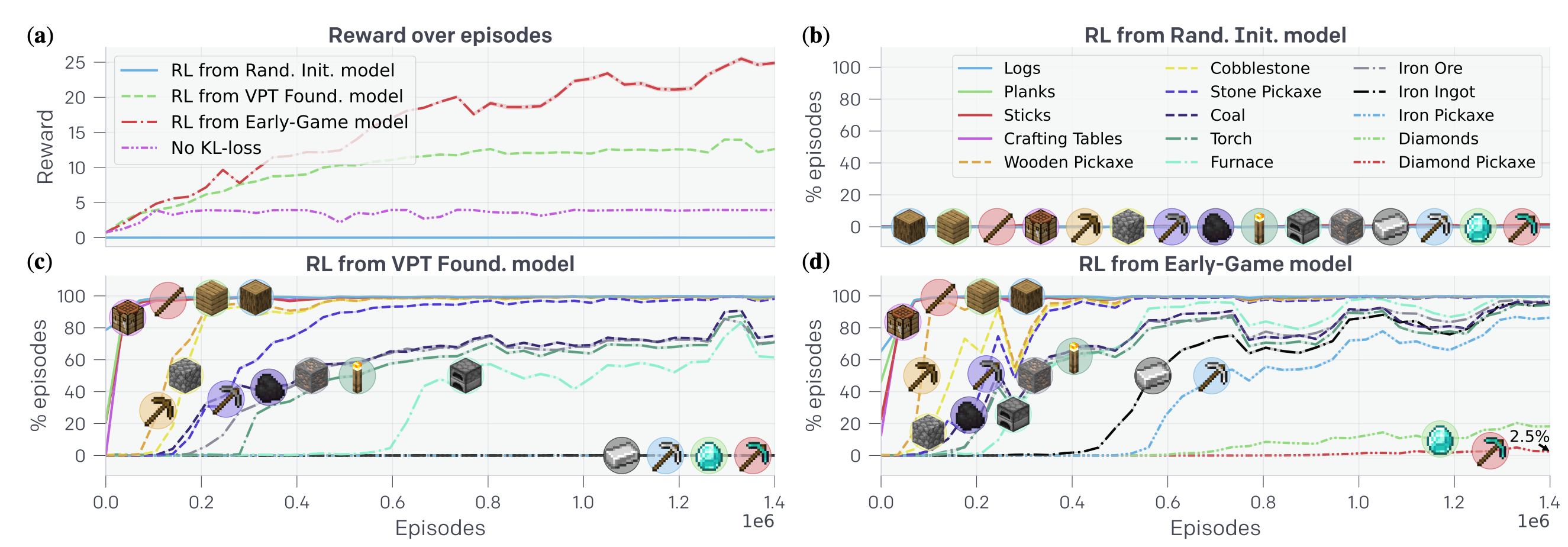
저자들은 문제를 푸는 데 가장 큰 난점을 위에서도 말했던 “Catastrophic Forgetting”이었다고 언급합니다. 실제로 무작위로 초기화된 모델에서는 학습이 거의 이루어지지 않았으며, 심지어 기본기를 충실하게(?) 학습한 VPT 모델 위에서도 학습이 제대로 이루어지지 않았습니다. 저자들은 이를 보완하기 위해서, 새로 갱신된 파라미터가 기존 파라미터와 차이가 나지 않도록(= 그래서 기존에 배운 지식을 잊어버리지 않도록) KL-divergence Loss를 추가로 부여하였습니다. 이 방법으로 모델에게 상위 아이템을 제작할 수 있는 방법을 가르칠 수 있었으며, 2.5%의 확률로 다이아몬드 곡괭이를 만드는 모델을 학습하는 것에 성공하였습니다!
마치며
VPT가 가지는 의의는 단순히 게임의 한 아이템을 만드는 것보다 훨씬 큽니다. 논문의 저자들이 증명한 것은 대량의 리플레이 데이터를 수집할 수 있다면, 아니 단순히 영상 데이터를 수집할 수 있다면 이를 통해서 모델을 학습할 수 있다는 것입니다. 물론 우리가 일상에서 접하는 문제는 20분짜리 다이아몬드 곡괭이를 만드는 것 이상으로 어렵겠지만 그마저도 많은 데이터와 세심한 Reward 설계를 통해서 학습할 수 있다는 가능성을 보여준 것입니다.
2010년대 이후로 딥러닝이 학계의 주된 패러다임으로 자리잡게 된 이유는 성능이 우수해서였다고 생각합니다. 그러나 돌이켜 생각해보면 실제로 딥러닝이 우리에게 보여준 것의 핵심은 “데이터를 모델의 행동으로 바로 해석할 수 있는 가능성”을 열어준 것에 있다고 생각합니다. 핑퐁팀은 모델이 사람보다 더 사람 같은 대화를 할 수 있게 되는 가능성을 실현하기 위하여 오늘도, 그리고 내일도 노력하겠습니다. 글 읽어주셔서 감사합니다!
참고문헌
- Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos (Bowen Baker et al., 2022)
- Mastering the game of Go with deep neural networks and tree search (David Silver et al., 2017)
- Grandmaster level in StarCraft II using multi-agent reinforcement learning (Oriol Vinyals et al., 2019)
- Learning Inverse Dynamics: A Comparison (Duy Nguyen-Tuong et al., 2008)
- Learning Transferable Visual Models From Natural Language Supervision (Alec Radford et al., 2021)