최대 24배 빠른 vLLM의 비밀 파헤치기
최대 24배의 성능을 보인 vLLM, 코드 레벨까지 분석해보자!

LLM 시대로 들어오면서 서빙을 위한 다양한 최적화 방식들이 많이 개발되고 연구되고 있죠. 오늘은 허깅페이스 대비 최대 24배까지 성능을 높일 수 있었던 vLLM에 대해 분석해 보고자 해요. 지금 분석하고자 하는 내용은 vLLM이 릴리즈된지 얼마 안 됐을 때의 구현체 (v0.1.2)에 기반하기 때문에 일부 변경된 사항이 있을 수 있다는 점을 고려해 주세요. 코드 레벨까지 상당히 깊은 내용을 포함하고 있기 때문에 깊은 이해를 원하시는 분들께 추천합니다!
vLLM
vLLM은 PagedAttention 기법을 활용하여 문장 생성 속도를 비약적으로 높인 방법론이에요. 이뿐만 아니라 실제 서빙을 위해 많은 요소들이 포함되어 있죠. 예를 들어 멀티 클러스터 환경에서 안정적인 서빙을 하기 위한 Ray Cluster를 사용하거나 큰 모델과 데이터를 병렬로 처리할 수 있도록 Megatron LM의 Parallelism을 차용하고 있습니다. Ray Cluster나 Megatron LM은 관련된 많은 글들이 있으니 여기서는 설명을 생략하고, 이번 블로그에서는 vLLM의 핵심 기술이라고 볼 수 있는 PagedAttention과 Continuous Batching 기법을 코드 레벨까지 파악해 볼게요.
구조
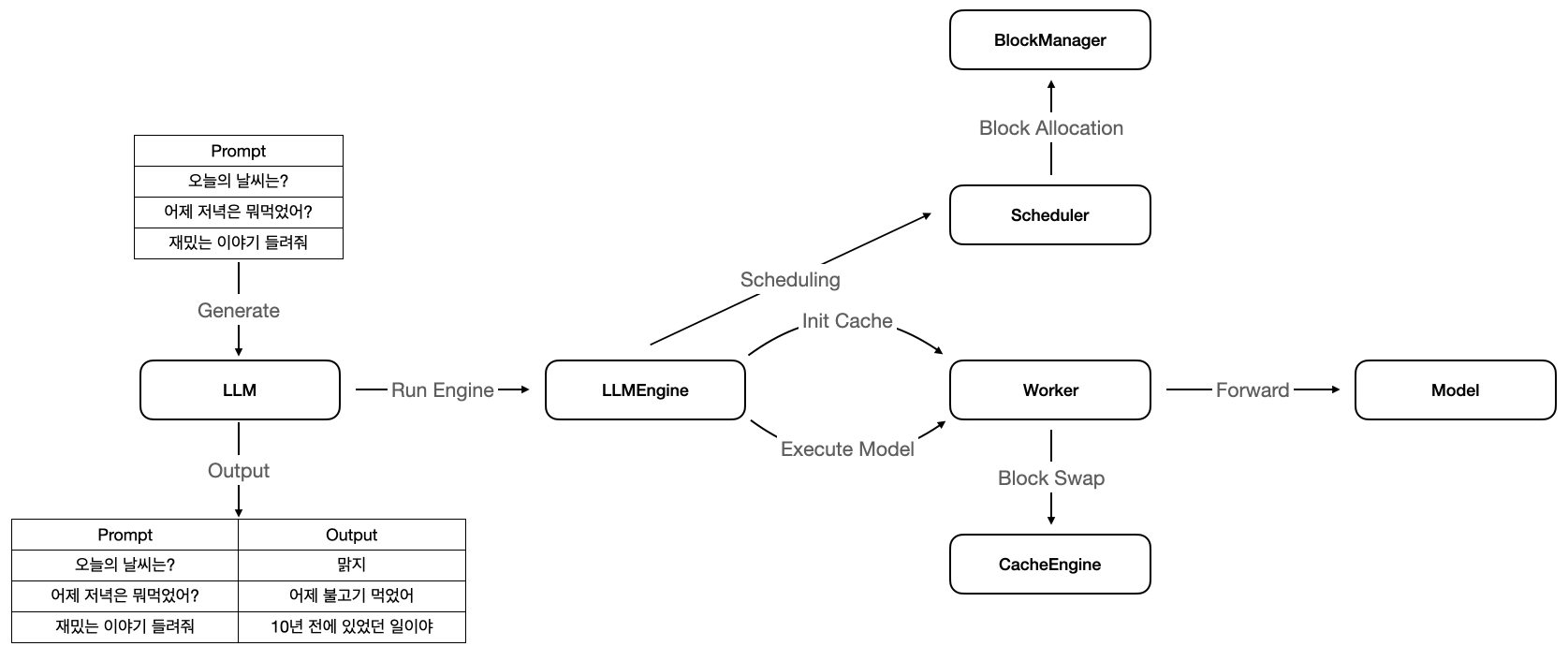
vLLM의 전체적인 구조입니다. LLMEngine에서 분산 처리를 위한 워커, PagedAttention의 블록을 관리하는 블록 매니저, KV 캐시 등을 관리하는
컴포넌트들을 생성하고, 매 요청 시 스케줄러를 통하여 요청된 프롬프트들의 생성 순서를 바꿔줍니다. LM에서 문장을 생성하기 위해서는 마지막 토큰이 나올 때까지 모델에 반복적으로 포워딩 해야 하는데,
스케줄러에 의해 메모리 및 우선순위를 따져 효율적인 방법으로 GPU 유틸리티를 달성하고 있습니다. 메모리의 효율성을 더욱 높이기 위해 PagedAttention 기법을 사용하며,
GPU 메모리가 부족할 경우 CPU 메모리에 스왑하는 방식으로 중간 계산 과정들에 대해서도 안정적으로 관리하고 있습니다.
이제 위 컴포넌트들 사이의 관계와 흐름을 차근차근 분석해 보겠습니다.
LLM Class
vLLM의 가장 기본적인 사용 방법으로, LLM() 클래스를 만들어 generate() 함수로 문장을 생성할 수 있습니다.
생성 함수
def generate(
self,
prompts: Optional[Union[str, List[str]]] = None,
sampling_params: Optional[SamplingParams] = None,
prompt_token_ids: Optional[List[List[int]]] = None,
use_tqdm: bool = True,
) -> List[RequestOutput]:
위 코드는 generate() 함수가 받는 인자의 목록입니다. prompts 변수에 문자열로 이루어진 프롬프트의 리스트를 입력받고, SamplingParams 인자를 받아 생성하고 있습니다.
SamplingParams 옵션 목록
class SamplingParams:
# 생성된 best_of개의 문장 중 가장 좋은 문장을 n개 선택합니다.
n: int = 1
# 각 프롬프트별 몇 개의 문장을 생성할지. 기본값은 n과 동일하며, 이 값은 n보다 같거나 커야합니다.
best_of: Optional[int] = None
# 이미 등장한 토큰들에 대한 패널티 (프롬프트 내 토큰 포함)
# 0보다 크면 등장한 적 없는 새로운 토큰을 생성할 경향이 높아지고,
# 0보다 작으면 토큰들 반복 생성할 경향이 높아집니다.
presence_penalty: float = 0.0
# 토큰의 등장 빈도에 대한 패널티 (프롬프트 내 토큰 포함)
# presence_penalty는 한 번 이라도 등장하면 같은 패널티를 먹이지만,
# frequency_penalty는 빈도에 따라 차등하여 패널티를 먹입니다.
# 마찬가지로 0보다 크면 새로운 토큰, 작으면 이미 등장한 토큰의 생성 경향이 높아집니다.
frequency_penalty: float = 0.0
temperature: float = 1.0
top_p: float = 1.0
top_k: int = -1
use_beam_search: bool = False
# 특정 문자열, 혹은 리스트를 지정하여 해당 문자열로 끝난다면 생성을 중단합니다.
stop: Union[None, str, List[str]] = None
# True이면 EOS가 나와도 생성을 계속합니다.
ignore_eos: bool = False
# 생성할 최대 토큰 개수입니다.
max_tokens: int = 16
# 생성된 토큰 외에도 가장 높은 확률을 지닌 토큰을 가져옵니다. logprobs에 지정된 개수만큼
# 높은 확률의 토큰을 반환하게 됩니다.
logprobs: Optional[int] = None
SamplingParams 클래스는 생성에 필요한 옵션들을 지정할 수 있습니다.
# prompts (문자열로 이루어진 프롬프트 리스트)가 주어지면 이 값을,
if prompts is not None:
num_requests = len(prompts)
# 주어지지 않으면 프롬프트의 토큰들을 사용합니다.
else:
num_requests = len(prompt_token_ids)
for i in range(num_requests):
prompt = prompts[i] if prompts is not None else None
if prompt_token_ids is None:
token_ids = None
else:
token_ids = prompt_token_ids[i]
self._add_request(prompt, sampling_params, token_ids)
return self._run_engine(use_tqdm)
generate() 함수의 로직입니다. prompts가 주어지지 않고 prompt_token_ids가 주어지면 이미 인코딩된 토큰들로 생성하고 있습니다. 그리고 생성은 각 프롬프트 별로 LLMEngine.add_request()로 프롬프트를 하나씩 넣어주며, 모두 넣어주었다면 _run_engine() 을 호출하고 있습니다.
LLMEngine 실행
def _run_engine(self, use_tqdm: bool) -> List[RequestOutput]:
# LLMEngine을 실행하여 문장을 생성하도록 합니다.
outputs: List[RequestOutput] = []
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
for output in step_outputs:
if output.finished:
outputs.append(output)
return outputs
_run_engine() 함수에서는 add_request()로 추가한 모든 프롬프트에 대해 완료될 때까지 LLMEngine.step()을 호출하고 있습니다. step() 함수는 모델 포워딩을 한 번 하여 배치 내의 프롬프트에 대한 토큰들을 하나씩 생성합니다.
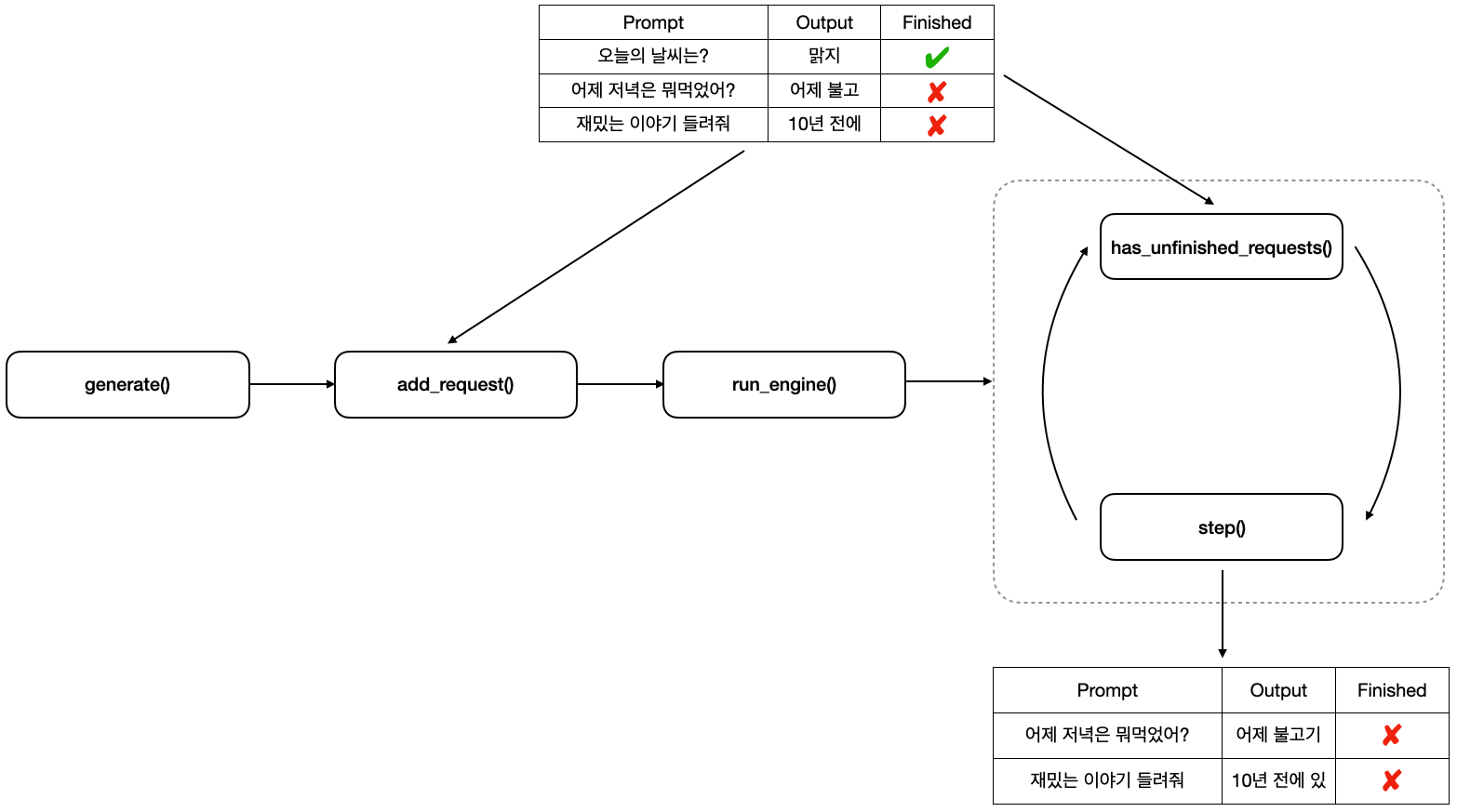
LLMEngine Class
LLMEngine은 실제 생성을 담당하는 엔진입니다. 초기화할 때 생성에 필요한 컴포넌트들(토크나이저, 워커, 스케줄러 등)을 모두 생성하고 초기화합니다. 이때 워커(Worker)는 병렬 작업을 위해 랭크마다 하나씩 생성합니다. 병렬화는 MegatronLM의 Parallelism을 사용하고 있으며, 분산 환경은 Ray Cluster를 사용하고 있습니다.
엔진이 초기화된 이후 KV Cache를 위한 초기 작업을 수행합니다.
캐시 초기화
KV 캐시를 저장하기 위해 _init_cache 함수를 통해 초기화를 진행합니다.
# profile_num_available_blocks() 함수 내부
# 먼저 모델 포워딩을 한 번 수행합니다.
self.model(
input_ids=input_tokens,
positions=input_positions,
kv_caches=[(None, None)] * num_layers,
input_metadata=input_metadata,
cache_events=None,
)
torch.cuda.synchronize()
# 할당 가능한 블록 수를 계산합니다.
peak_memory = torch.cuda.max_memory_allocated()
# 전체 GPU 메모리 크기를 구합니다.
total_gpu_memory = get_gpu_memory()
# 인자에 따른 캐시 블록 크기를 계산합니다.
cache_block_size = CacheEngine.get_cache_block_size(
block_size, self.model_config, self.parallel_config)
# 사용 가능한 메모리 크기로 최대 블록 개수를 계산합니다.
num_gpu_blocks = int((total_gpu_memory * gpu_memory_utilization
- peak_memory) // cache_block_size)
num_cpu_blocks = int(cpu_swap_space // cache_block_size)
num_gpu_blocks = max(num_gpu_blocks, 0)
num_cpu_blocks = max(num_cpu_blocks, 0)
_init_cache 함수는 Worker 클래스의 profile_num_available_blocks 함수를 통해 블록 수를 계산하고 있습니다. 블록이란 PagedAttention에서 사용되는 개념으로, OS의 메모리 관리 방법 중 하나인 Page와 유사한 개념이며, 하나의 블록에는 여러 토큰들이 저장됩니다.
아래 과정을 거쳐 계산됩니다.
- 주어진 인자들로 모델을 한번 포워딩 시킵니다.
- PyTorch의
max_memory_allocated함수를 사용하여 사용된 최대 GPU 메모리를 구합니다. - 인자로 주어진 최대 GPU 사용량의 제한 값 (gpu_memory_utilization)에서 2에서 구한 크기를 빼주어 블록을 저장하기 위해 사용 가능한 메모리 크기를 계산합니다.
- 이 크기로 사용 가능한 최대 블록 개수를 계산합니다. 즉, 포워딩에 필요한 GPU 외에 나머지를 캐시 메모리로 사용합니다.
def get_cache_block_size(block_size, model_config, parallel_config):
# MHA에서 각 헤드의 차원
head_size = model_config.get_head_size()
# 헤드 개수에 Tensor Parallel을 나눈 값 (Parallel은 Megatron LM의 인자)
num_heads = model_config.get_num_heads(parallel_config)
# 전체 레이어 수에 Pipeline Parallel을 나눈 값 (Parallel은 Megatron LM의 인자)
num_layers = model_config.get_num_layers(parallel_config)
# 블록 내에 포함되는 요소 개수 (block_size) X 각 요소에 포함되는 파라미터 수
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_layers * (key_cache_block + value_cache_block)
dtype_size = _get_dtype_size(model_config.dtype)
# cache_block_size = dtype_size * total
return dtype_size * total
cache_block_size 크기는 PagedAttention 에서 사용하는 블록이 차지하는 실제 메모리 크기를 의미합니다. 인자로 받는 것은 각 블록에 최대 몇 개의 토큰 정보가 들어갈지에 대한 것이기 때문에 실제 메모리를 얼마나 차지하는지는 별도로 계산해야 합니다.

프롬프트 큐잉
문장을 생성하기 위해 요청 프롬프트를 큐에 추가합니다. 이때 SamplingParams에 명시된 best_of 개만큼 시퀀스를 복제하여 큐에 저장합니다. 각 프롬프트는 하나의 Sequence 객체로 만들어지고, 하나의 요청(=프롬프트)를 best_of개 복제하여 SequenceGroup 객체를 Waiting 큐에 추가합니다.
생성 스텝
스케줄러의 schedule() 함수로 현재 저장되어 있는 요청 큐에서 모델로 포워딩시킬 대상의 시퀀스들을 가져오고, PagedAttention을 적용하기 위해 캐시들의 블록을 준비합니다. 그런 다음 Worker.execute_model로 모델에 포워딩하여 다음 토큰들을 생성하여 저장합니다.
seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()
if (not seq_group_metadata_list) and scheduler_outputs.is_empty():
# Nothing to do.
return []
# Model의 포워딩을 지시합니다.
output = self._run_workers(
"execute_model",
seq_group_metadata_list=seq_group_metadata_list,
blocks_to_swap_in=scheduler_outputs.blocks_to_swap_in,
blocks_to_swap_out=scheduler_outputs.blocks_to_swap_out,
blocks_to_copy=scheduler_outputs.blocks_to_copy,
)
# 포워딩 이후의 결과들로 스케줄러를 업데이트합니다.
seq_groups = self.scheduler.update(output)
# 포워딩하여 생성된 토큰들을 디코딩 합니다.
self._decode_sequences(seq_groups)
# 생성 중단 기준에 도달한 Sequence들을 조정합니다.
self._stop_sequences(seq_groups)
# 생성이 완료된 Sequence를 큐에서 제거합니다.
self.scheduler.free_finished_seq_groups()
# 생성 결과를 저장합니다.
request_outputs: List[RequestOutput] = []
for seq_group in seq_groups:
request_output = RequestOutput.from_seq_group(seq_group)
request_outputs.append(request_output)
return request_outputs
스케줄링
다음으로 요청된 많은 프롬프트들을 한꺼번에 처리할 수 없으므로, 우선순위를 고려하여 한 번에 처리하려는 프롬프트를 정렬해주는 스케줄링 작업을 실시합니다. 그리고 PagedAttention 적용을 위해 메모리를 어떻게 관리하는지 알아보겠습니다.
들어가기에 앞서 용어 정리부터 하면,
- Sequence: 실제 모델에 포워딩 되는 시퀀스입니다.
- SequenceGroup: 각 프롬프트 별로 생성하는 문장 개수를 지정할 수 있는데, 이때 각 프롬프트 별로 묶은 그룹입니다. 만약 총 3개의 프롬프트를 이용하여 각 프롬프트당 4개의 문장을 생성하고자 한다면, 전체 Sequence 개수는 3 x 4 = 12개이며, SequenceGroup은 3개입니다.
- Block: PagedAttention에서 Sequence가 갖고 있는 토큰들의 Key, Value 값들은 일정 개수로 쪼개어 관리합니다. OS의 Page와 유사한 개념입니다.
- Slot: Block 내에서 하나의 토큰의 Key 또는 Value에 대해 할당되었거나 될 수 있는 공간입니다.
block_size가 8이라면 어떤 블록의 슬롯 개수는 8개입니다.
상태
상태는 총 3가지로 구분되어 나누어집니다.
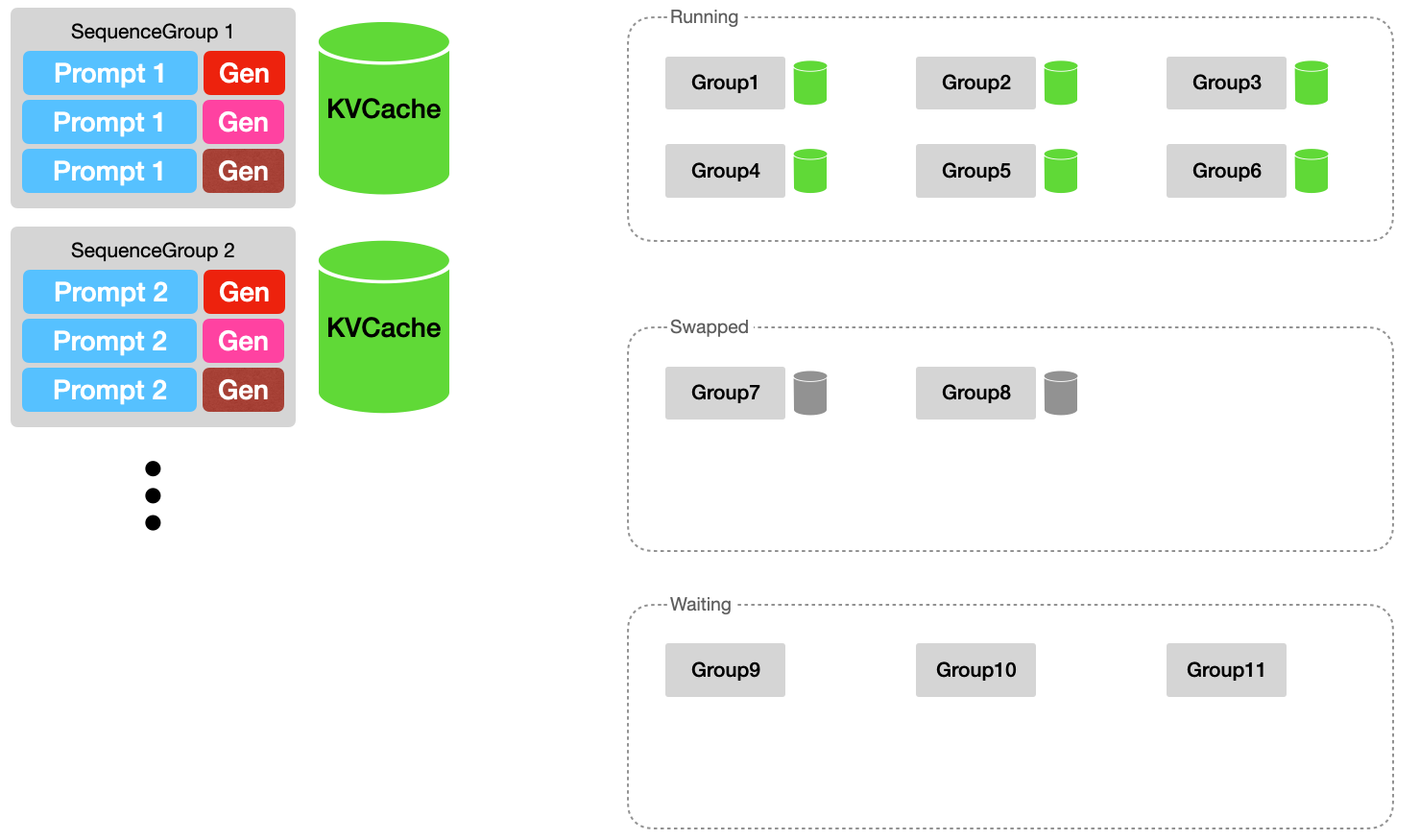
- Waiting
- 생성 대기 중인 SequenceGroup Queue 입니다. 여기에 들어있는 시퀀스 그룹들은 KVCache가 할당되지 않은 SequenceGroup 입니다.
- Running
- 모델에 포워딩되어 문장이 생성 단계에 있는 SequenceGroup Queue 입니다. 따라서 프롬프트 및 생성 토큰들에 대한 KVCache가 할당되어있습니다.
- Swapped
- SequenceGroup이 Running 단계에 있었다가 토큰들이 하나씩 생성되면서 메모리가 부족할 수 있는데, 이때 Running 상태에 들어가지 못하고 기다리고 있는 SequenceGroup Queue 입니다.
- KVCache는 CPU 메모리로 스왑되어 있습니다.
Slot Swap Out
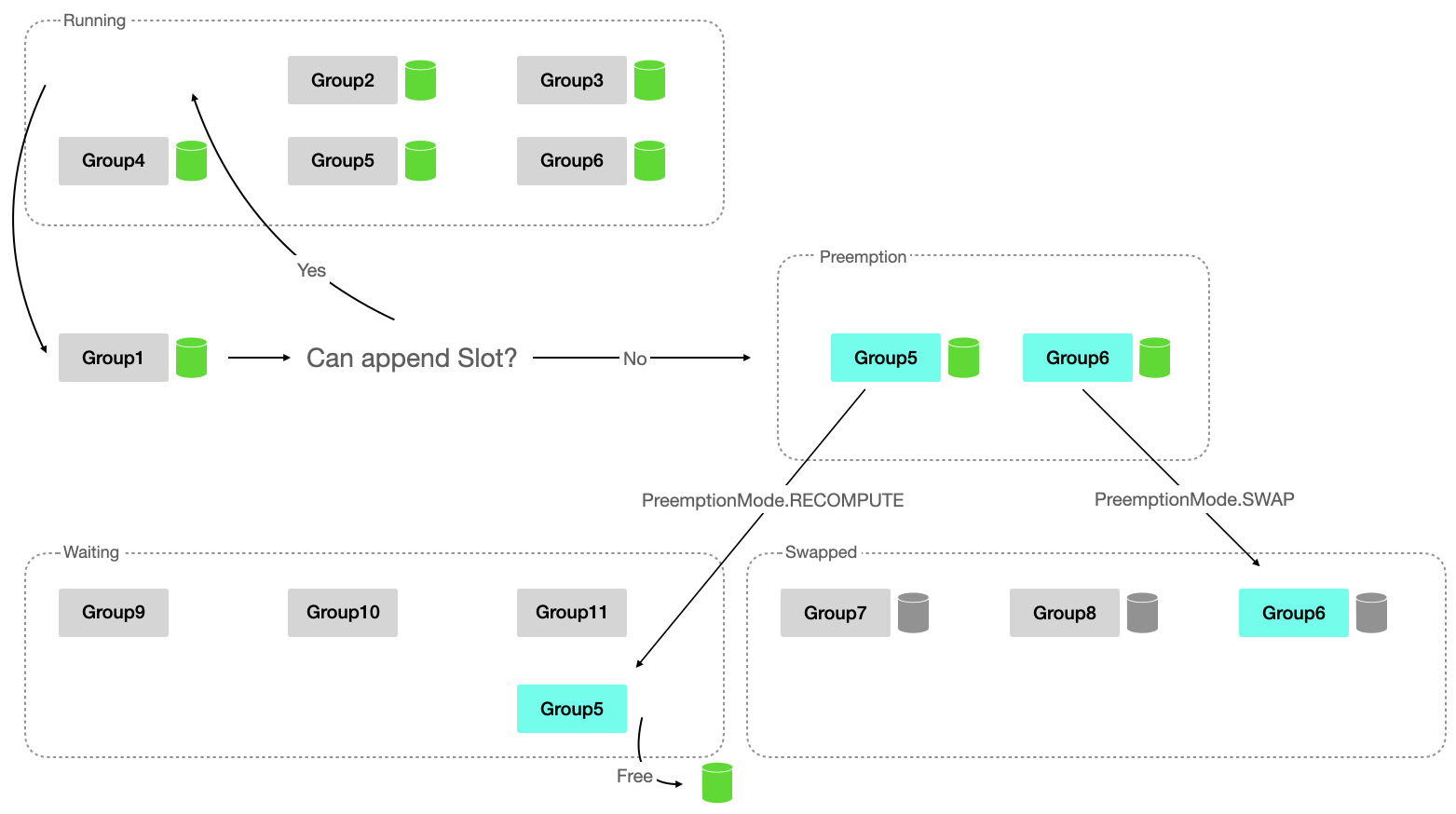
스케줄링의 가장 첫 번째 단계는 현재 실행 중인 (Running 상태인) SequenceGroup 중 우선순위가 높은 순으로 슬롯을 할당할 수 있는지 확인하는 것입니다. 토큰을 한 개씩 생성하면서 필요한 메모리는 증가하기 때문에 우선순위가 높은 SequenceGroup가 필요한 메모리가 부족하다면 낮은 우선순위의 SequengeGroup의 슬롯을 GPU 메모리에서 내리기 위함입니다.
이 과정은 아래 순서를 반복하여 달성합니다.
- 가장 우선순위가 높은 Running 상태의 SequenceGroup을 한 개 pop 합니다. (=GroupA)
- 이 그룹에 대해 캐시 블록 슬롯을 배정할 수 없다면, 아래 과정을 반복합니다.
- Running 상태의 그룹 중 가장 낮은 우선순위를 갖는 그룹을 하나 선택합니다. (=GroupB)
- 만약 없다면 현재 그룹(GroupA)을 Preemption 합니다.
- 선택된 그룹(GroupB)을 Preemption 합니다.
- Running 상태의 그룹 중 가장 낮은 우선순위를 갖는 그룹을 하나 선택합니다. (=GroupB)
- 현재 그룹(GroupA)을 Running 상태에 추가합니다.
Preemption 전략은 다음과 같습니다.
- SequenceGroup 내에서 생성이 완료되지 않은 Sequence 개수를 구합니다.
- 만약 이 값이 1이라면, 해당 시퀀스 그룹의 KVCache를 모두 Free 하고 Waiting 상태로 변경합니다.
- 다음에 SequenceGroup이 Running 상태로 변경될 때 KV 캐시가 재계산됩니다. (RECOMPUTE)
- 그렇지 않다면 KVCache 메모리를 Swap-out 합니다. (SWAP)
Swap Out이 예정된 그룹의 KV Cache 블록들은 blocks_to_swap_out 변수에 담깁니다.
Slot Swap In
다음으로 스왑된 시퀀스 그룹 중 슬롯을 할당할 수 있는 그룹을 찾아 Swap-in 합니다. 이는 우선순위가 높은 SequenceGroup의 생성이 끝나 GPU 메모리 공간이 여유로워졌기 때문에, 쫓겨난 그룹들을 다시 불러오기 위함입니다. 이때 Swap-out이 예정되어 있는 그룹이 없어야 합니다. 이때 역시 우선순위로 정렬하여 우선순위가 높은 그룹 순으로 Running 상태로 변경합니다.
Swap In이 예정된 그룹의 KV Cache 블록들은 blocks_to_swap_in 변수에 담깁니다.
Waiting 상태인 SequenceGroup 배정
Swap된 그룹이 없고 Waiting 상태인 그룹이 존재하면 해당 단계를 거쳐 Waiting 상태의 시퀀스 그룹을 Running 상태로 변경합니다. 이때에는 우선순위대로 정렬하지 않는데, 그 이유는 Swap 되지 않고 Preemption된 그룹 (즉, KV 캐시만 날아간 SequenceGroup)은 Waiting 큐 가장 앞부분에 담겨 있어 정렬하지 않습니다.
가장 앞쪽에 있는 시퀀스 그룹을 하나씩 가져와 아래 순서에 따라 실행됩니다.
- 만약 현재 스케줄링에 의해 이 그룹이 Preempted인 그룹이라면 건너뜁니다.
- 현재 메모리에 할당할 수 없다면 건너뜁니다.
- 만약 이 그룹에 의해 특정 기준 (최대 배치 크기, 최대 토큰 개수)가 넘어가면 건너뜁니다.
- 해당 시퀀스 그룹에 대해 KV Cache 공간을 할당하고 Running 상태로 변경합니다.
위 과정이 모두 끝나면 스케줄러의 출력물이 총 3가지가 나옵니다.
- blocks_to_swap_in: Swapped 상태인 그룹이 다시 Running 상태로 돌아와 프로세스를 진행해야 할 경우, Swap-in 시키기 위해 CPU↔GPU 간 블록 매핑 테이블
- blocks_to_swap_out: Running 상태였던 그룹이 Swapped 상태로 변경되어 Swap-out 시키기 위한 GPU↔CPU 간 블록 테이블
- blocks_to_copy: GPU 내에 있는 블록을 다른 위치로 복사할 블록 Pair 리스트. 블록 매니저 파트에서 다시 알아보겠습니다.
그리고 Running 상태의 시퀀스 그룹들을 대상으로 SequenceGroupMetadata를 생성하며, 아래의 항목이 포함되어 있습니다.
- request_id: 각 프롬프트 별로 한 개의 고유한 아이디를 부여받는 request_id 값
- is_prompt: Waiting → Running으로 바뀐 그룹인지에 대한 여부. KV Cache가 없을 때는 프롬프트를 이용하여 KV Cache를 계산해야 하는데, 이 값을 이용하여 모델에 프롬프트 토큰까지 넣어줄지 말지를 결정합니다.
- seq_data: 그룹 내에 있는 모든 시퀀스들에 대하여, ID를 key로 하고 ID에 대응되는 토큰들을 value로 하는 매핑 테이블
- sampling_params: 샘플링에 사용될 파라미터.
top_k,top_p등이 포함되어 있습니다. - block_tables: 해당 시퀀스 그룹 내 각 시퀀스들에 해당하는 Physical Block 리스트를 매핑 한 테이블. 블록 매니저 파트에서 다시 알아보겠습니다.
Block Manager
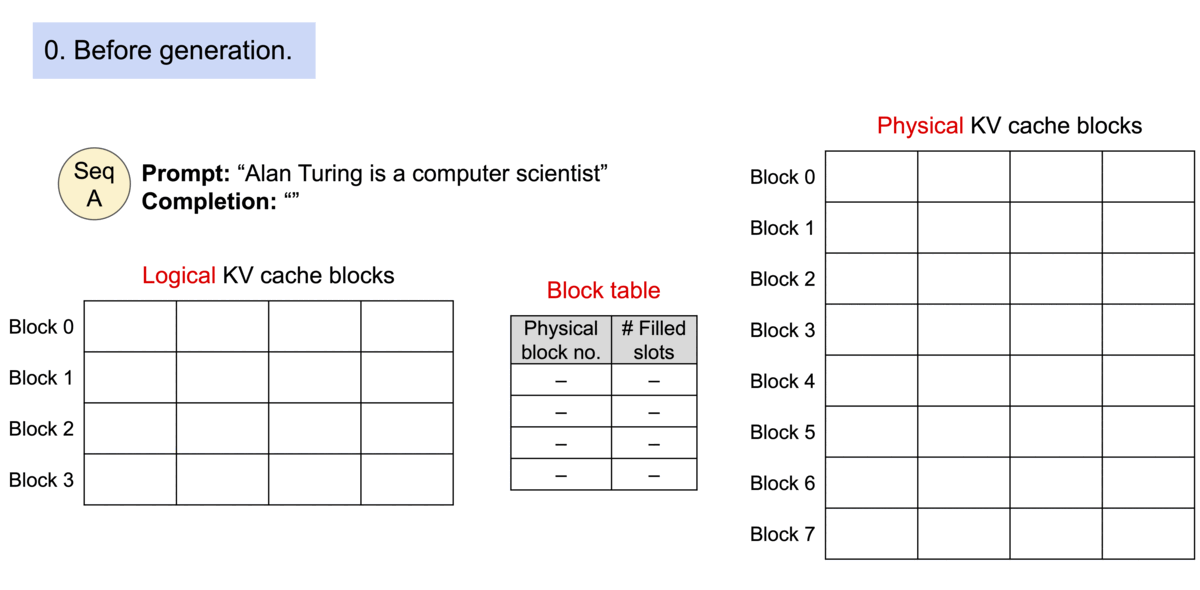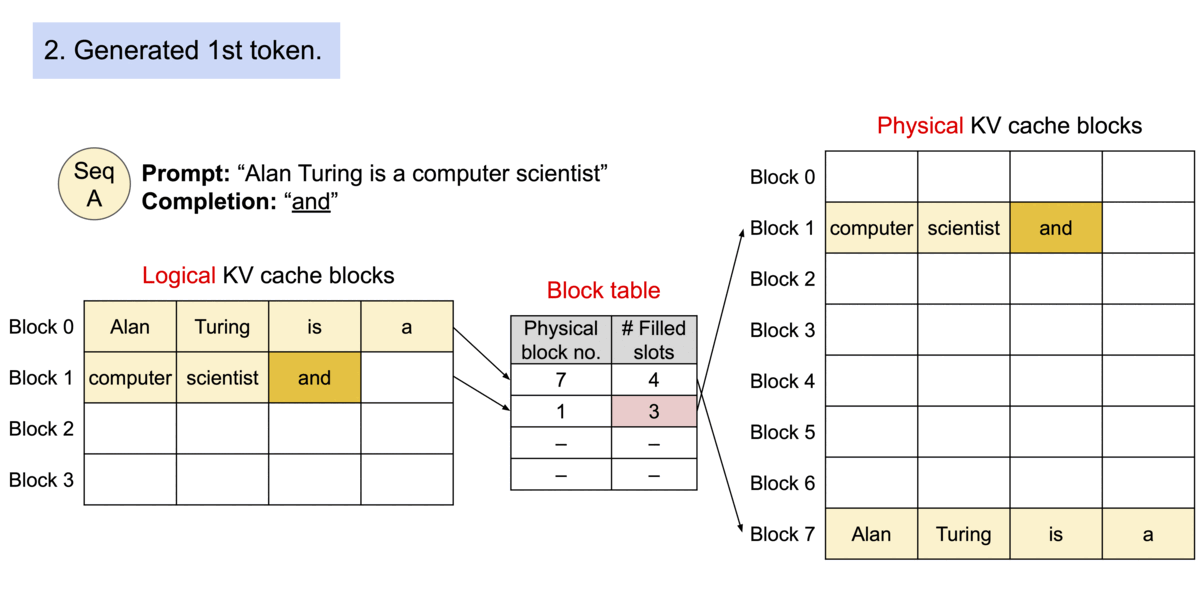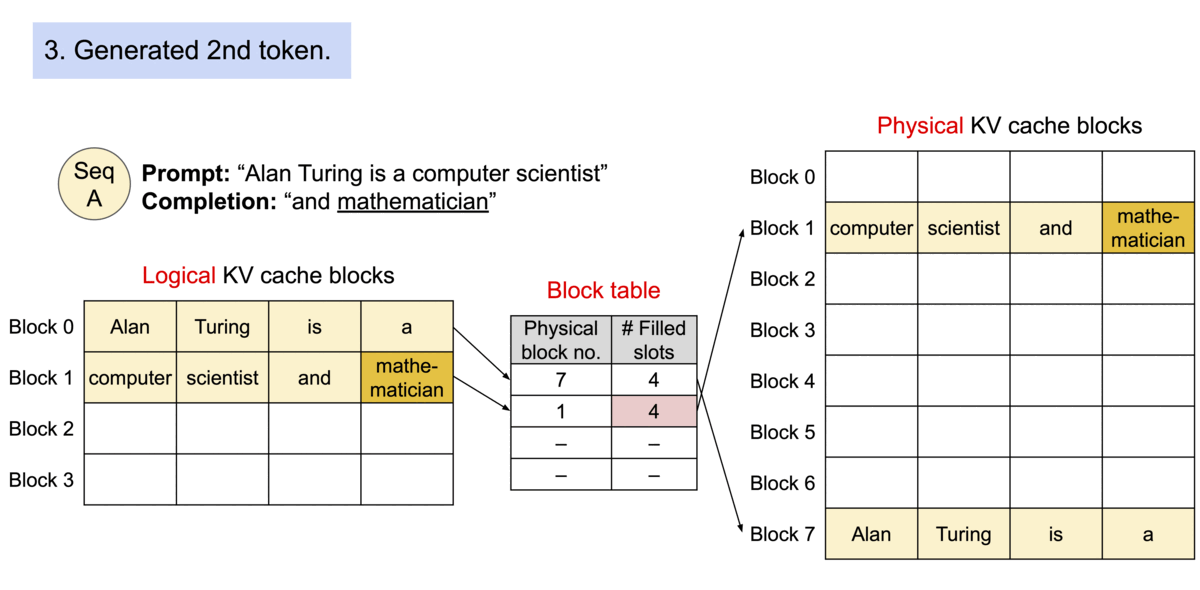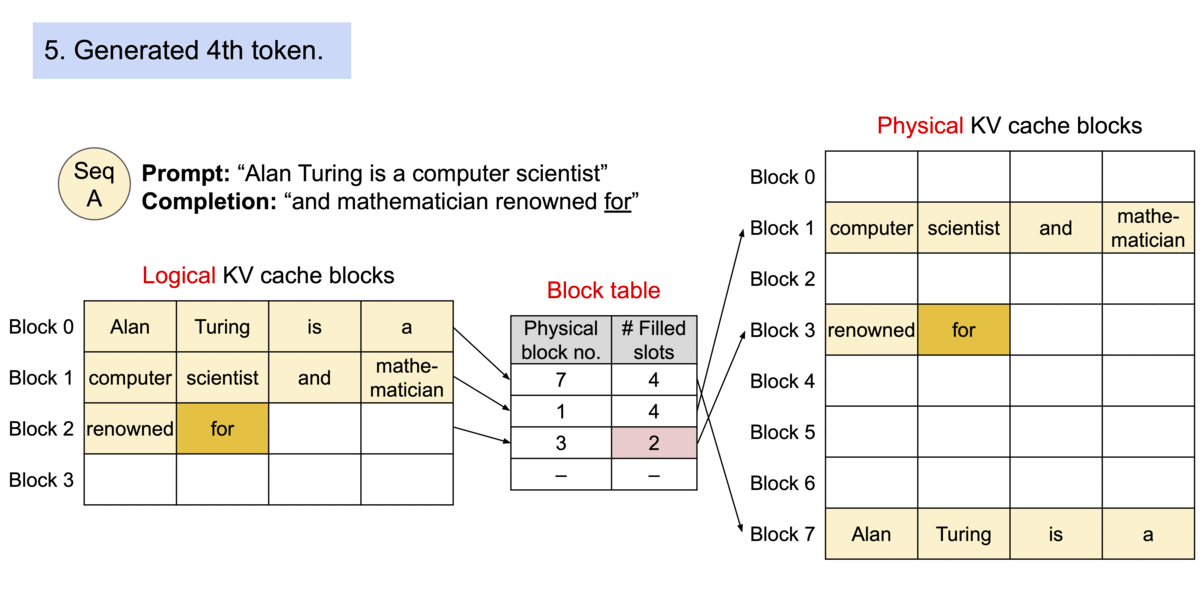
PagedAttention은 OS의 Virtual Memory와 유사하게 Logical ↔ Physical 파트로 나누고, 각 토큰의 KV 캐시 값을 블록이라는 단위로 파티셔닝하여 저장합니다. 이 두 작업을 모두 도맡아 해주는 컴포넌트가 BlockManager 입니다.
앞서 계산했던 대로 GPU, CPU 내에서 사용 가능한 최대 블록 개수로 매니저를 초기화합니다. 이때 사용하는 클래스는 BlockAllocator를 사용하는데, 다음 역할을 수행합니다.
- 할당되지 않은 블록 관리
- 블록 할당 및 해제
- Reference Count 관리
- vLLM에서는 같은 프롬프트로 여러 문장을 생성할 수 있는데, 이때 초기 프롬프트 토큰들은 공유되고 생성 중인 토큰들은 각자 갖고 있습니다.
- Sequence의 Logical Block과 Physical Block 사이의 매핑 테이블 관리 (Block Table)
Reference Count는 특정 블록이 사용되고 있는 Sequence의 개수를 의미하며, 블록 테이블은 Sequence의 블록들이 GPU 상에 있으면 GPU 블록을, Swap-out 되어 블록들이 CPU 상에 있으면 CPU 블록들을 담고 있습니다.
Allocation
def allocate(self, seq_group: SequenceGroup) -> None:
seq = seq_group.get_seqs()[0]
# 프롬프트 토큰을 저장하기 위해 Physical 블록을 새로 할당합니다.
block_table: BlockTable = []
for _ in range(len(seq.logical_token_blocks)):
block = self.gpu_allocator.allocate()
# 프롬프트 토큰은 모두 공유하기 때문에 Reference Count는
# Sequence Group 내의 모든 Sequence 개수로 초기화합니다.
block.ref_count = seq_group.num_seqs()
block_table.append(block)
# 각 Sequence 별 Block Table을 저장합니다.
for seq in seq_group.get_seqs():
self.block_tables[seq.seq_id] = block_table.copy()
블록 매니저는 SequenceGroup 또는 Sequence를 인자로 받아 블록 또는 슬롯(=블록 내에서 토큰이 자리 잡고 있는 공간)을 할당해 주고 있습니다. SequenceGroup은 마치 프로세스가 Virtual Memory를 관리하듯 자체적으로 Logical 블록을 관리합니다. 따라서 토큰을 저장하기 위한 블록은 실제 물리 메모리 크기와 상관없이 생성할 수 있으며, 각 블록 내 슬롯이 block_size 크기에 다다르면 새로운 Logical 블록을 새로 발행하여 할당합니다. 블록 매니저는 이 SequenceGroup이 갖고 있는 Logical 블록을 실제 CPU/GPU 메모리에 할당되어 있는 Physical 블록에 할당하는 역할을 담당합니다.
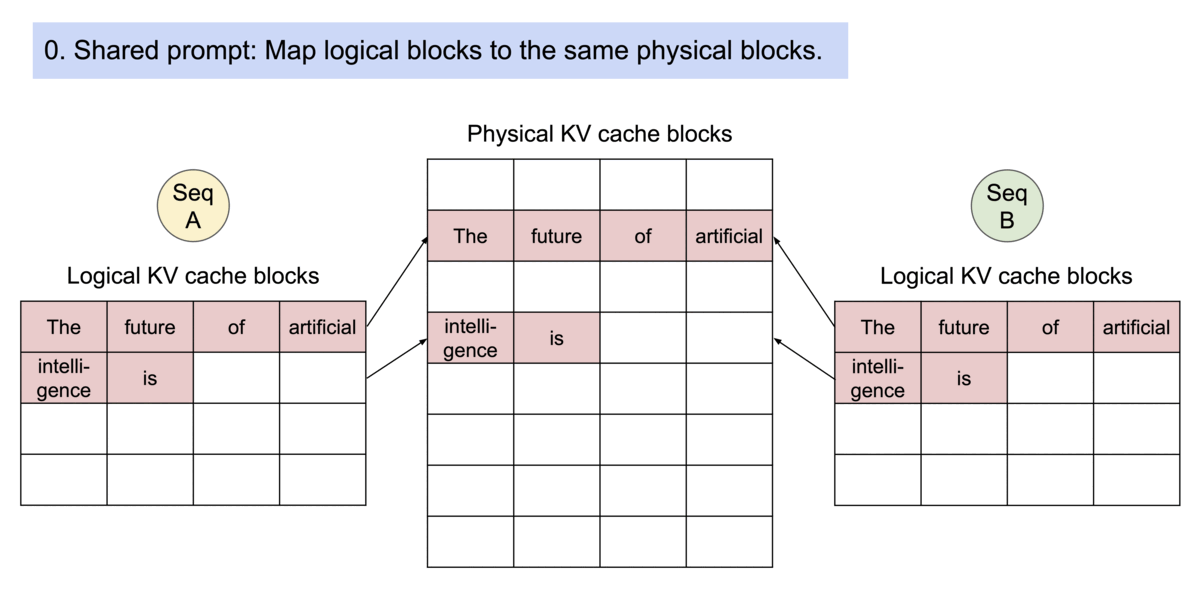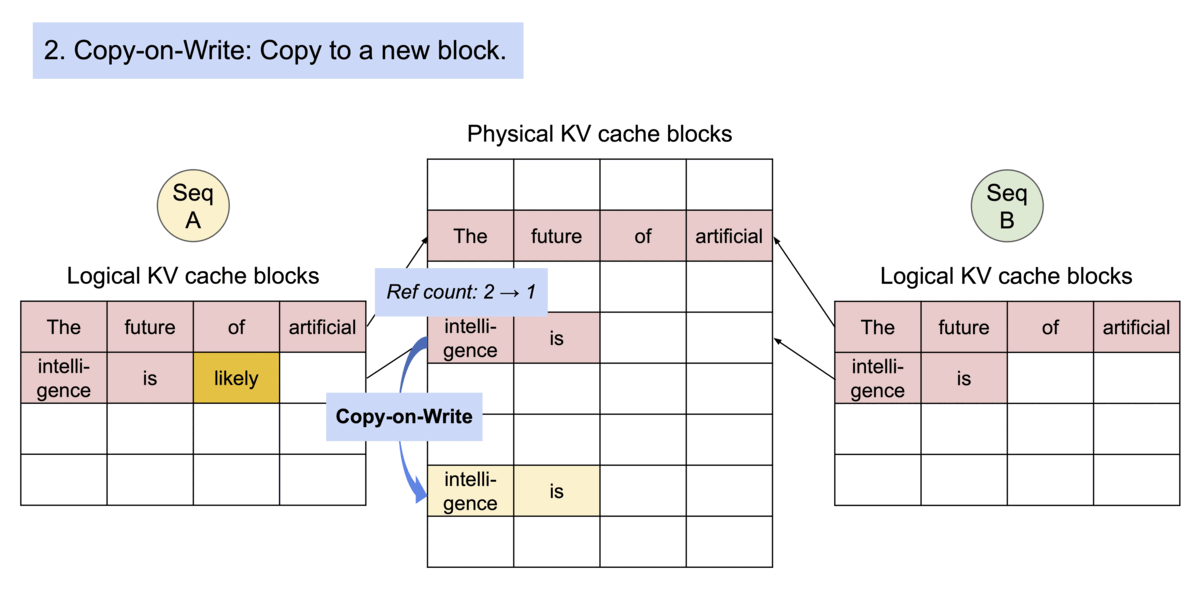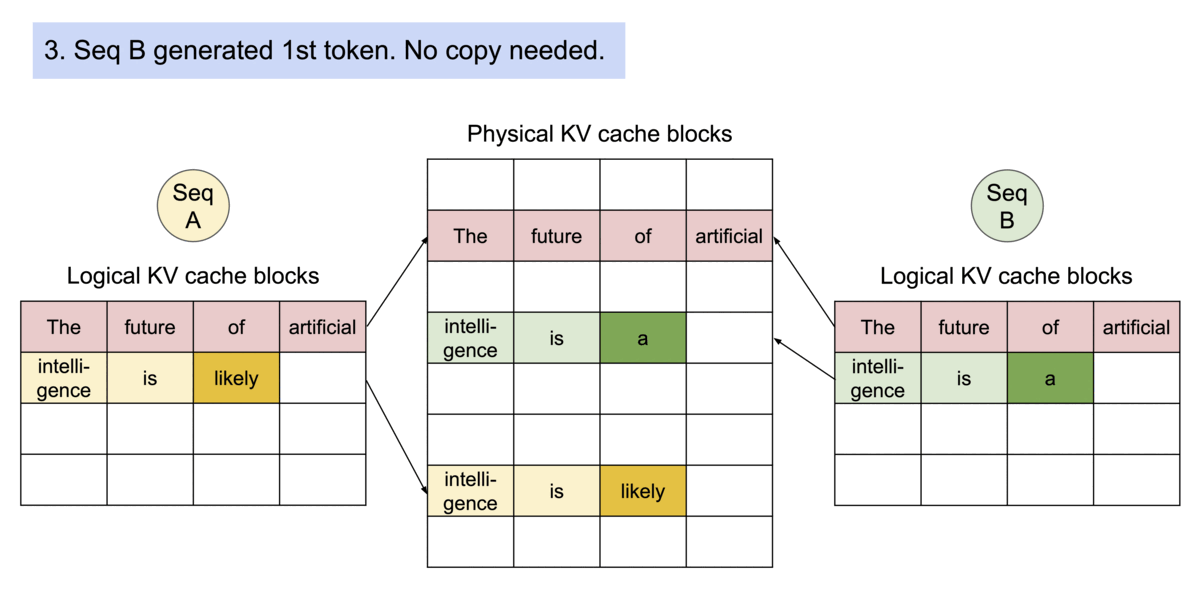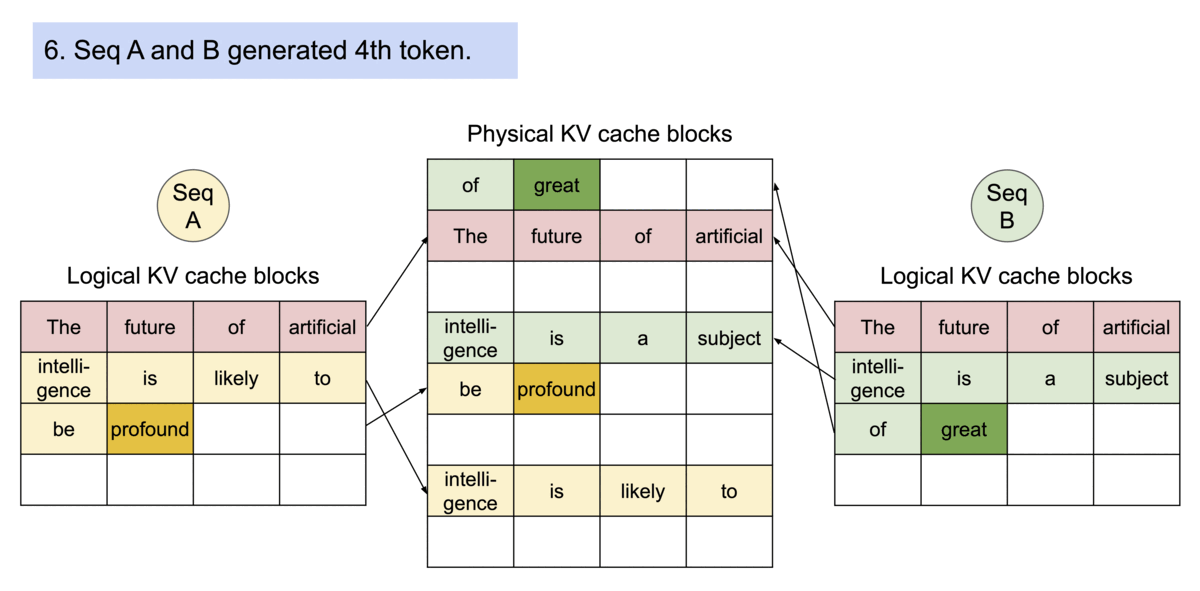
SequenceGroup을 위한 블록 할당은 allocate 함수로 할당되며, 실제로 할당된 블록은 블록 테이블에 저장됩니다.
또한 새로운 토큰을 생성하려면 새로운 슬롯이 추가될 수 있어야 합니다. allocate 함수는 SequenceGroup이 갖고 있는 Logical 블록을 Physical 블록에 할당하는 함수라면, append_slot은 SequenceGroup 내 각 시퀀스들이 새로운 토큰을 위한 슬롯을 위해 블록을 새로 할당해 주는 함수입니다.
아래와 같은 순서로 진행됩니다.
- 만약 SequenceGroup 내 Logical 블록 개수가 블록 매니저가 관리하는 SequenceGroup의 블록 테이블에 들어있는 블록 개수보다 많다면 새로운 토큰을 위해 Logical 블록을 새로 할당했다는 의미이므로 새로운 Physical 블록을 할당하여 블록 테이블에 저장합니다.
- 그렇지 않다면 기존에 갖고 있는 블록 내에 슬롯을 할당했다는 의미입니다. vLLM은 SequenceGroup 내의 시퀀스들은 생성 시 공유하고 있는 프롬프트에 해당하는 블록을 제외하고 각자 생성 토큰을 위한 블록을 갖고 있으므로, 가장 마지막 블록의 Reference Count를 보고, 1인지 확인합니다.
- 1이라면 각 Sequence는 자신마다 새로운 블록이 이미 할당되어 사용되고 있으므로 새로운 블록을 할당하지 않습니다.
- 만약 1이 아니라면 해당 블록을 다른 Sequence에서도 사용하고 있다는 의미이므로 해당 블록에 대한 Reference을 제거하고 (free) 새로운 블록을 할당합니다. 이때 반환되는 값은 기존의 Block Number와 새로 할당된 Block Number를 리턴하여 추후에
blocks_to_copy매핑 테이블에 넣을 수 있도록 합니다. 이렇게 되면 기존에 공유하고 있던 블록은 복제되어 각 Sequence 마다 각기의 블록들을 갖게 됩니다.
Swap
def swap_out(self, seq_group: SequenceGroup) -> Dict[int, int]:
# GPU block -> CPU block.
mapping: Dict[PhysicalTokenBlock, PhysicalTokenBlock] = {}
for seq in seq_group.get_seqs():
if seq.is_finished():
continue
new_block_table: BlockTable = []
block_table = self.block_tables[seq.seq_id]
for gpu_block in block_table:
if gpu_block in mapping:
cpu_block = mapping[gpu_block]
cpu_block.ref_count += 1
else:
cpu_block = self.cpu_allocator.allocate()
mapping[gpu_block] = cpu_block
new_block_table.append(cpu_block)
# Free the GPU block swapped out to CPU.
self.gpu_allocator.free(gpu_block)
self.block_tables[seq.seq_id] = new_block_table
block_number_mapping = {
gpu_block.block_number: cpu_block.block_number
for gpu_block, cpu_block in mapping.items()
}
return block_number_mapping
BlockManager는 Swap-In/Out을 위해 block_table을 수정하는 역할도 담당합니다. Swap-Out이 발생하면 GPU 메모리 상에 존재하는 블록을 CPU로 옮겨야 합니다.
- CPU Allocator로 GPU 상에 존재하는 모든 블록에 대응되는 블록들을 할당합니다.
- GPU 블록을 Free 한 다음 SequenceGroup의 블록들을 1에서 할당된 블록으로 대응시켜줍니다.
- GPU 상에 존재했던 Block Number와 CPU 메모리에 새로 할당된 Block Number의 매핑 테이블을 반환합니다.
Swap-In이 발생하면 위 과정의 역을 수행합니다.
Worker
if blocks_to_swap_in:
self.cache_engine.swap_in(blocks_to_swap_in)
issued_cache_op = True
if blocks_to_swap_out:
self.cache_engine.swap_out(blocks_to_swap_out)
issued_cache_op = True
if blocks_to_copy:
self.cache_engine.copy(blocks_to_copy)
issued_cache_op = True
스케줄러에 의해 어떤 블록이 Swap In/Out이 되고, 어떤 블록이 복제되어야 하는지 (blocks_to_copy), 모델에 포워딩되어야 하는 SequenceGroup이 무엇인지 결정되었습니다. 하지만 지금까지 했던 과정에서 실제 GPU↔CPU 메모리 간의 데이터 이동은 일어나지 않았습니다. 단순히 어떤 데이터를 옮겨야 하는지에 대한 내용이므로, CacheEngine 컴포넌트를 이용하여 실제로 데이터를 옮겨줍니다.
# Prepare input tensors.
input_tokens, input_positions, input_metadata = self._prepare_inputs(
seq_group_metadata_list)
# Execute the model.
output = self.model(
input_ids=input_tokens,
positions=input_positions,
kv_caches=self.gpu_cache,
input_metadata=input_metadata,
cache_events=cache_events,
)
최종적으로 토큰을 생성하기 이전 필요한 모든 밑작업들이 끝마쳤습니다! 이제 생성을 위해 시퀀스 그룹의 토큰 ID를 준비(_prepare_inputs)하고 모델에 포워딩합니다.
Prepare Inputs
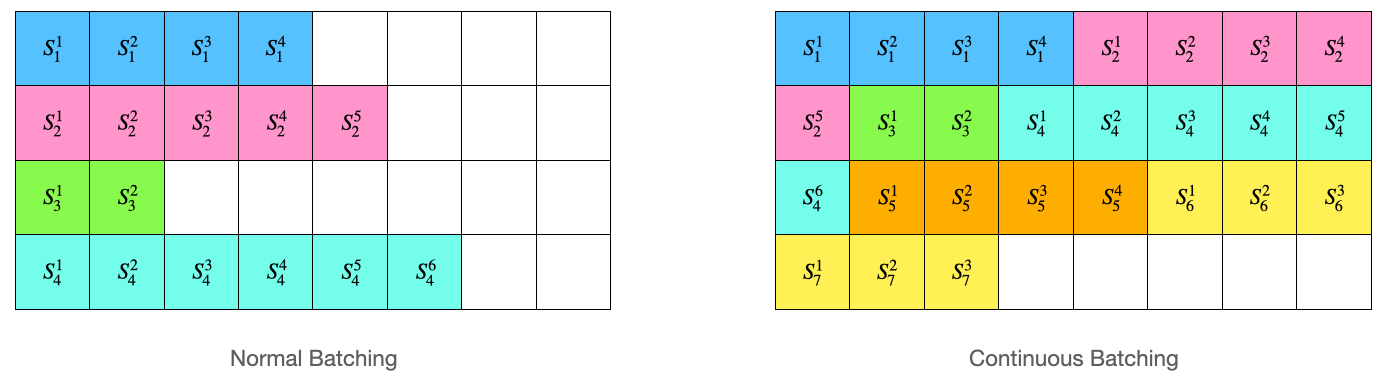
모델 입력은 _prepare_inputs 함수로 변환하고 있습니다. 배칭은 Continous Batching으로, 위 그림처럼 배칭을 해주고 있습니다. 따라서 빈 공간을 최대한 효율적으로 사용하여 메모리를 절약하고, 빠른 속도로 추론을 할 수 있습니다. 보다 자세한 설명은 vLLM 블로그 글을 참조해 주세요!
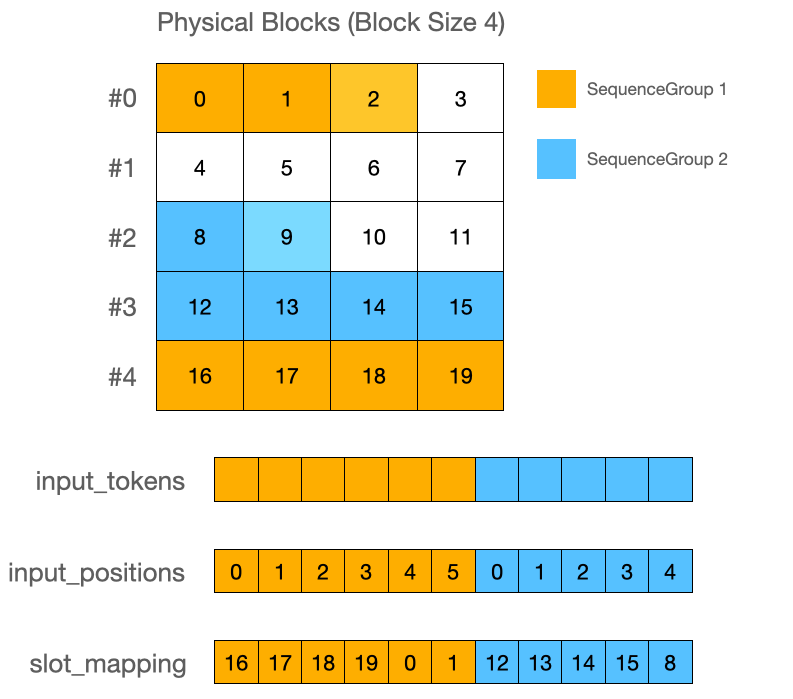
먼저 프롬프트 토큰들에 대해 입력 ID를 만듭니다. SequenceGroup 내에 속한 Sequence 토큰들을 모두 가져와 input_tokens 변수에 확장합니다. 그리고 프롬프트 크기로 input_positions에 위치 정보 배열을 넣어줍니다. 이 값은 position_ids의 역할을 담당합니다. 마지막으로 각 토큰 ID마다 어느 슬롯에 배정되어 있는지 슬롯 매핑 테이블을 생성합니다. (slot_mapping)
프롬프트 토큰들은 Waiting에서 Running 상태로 막 변경된 SequenceGroup에 대해서만 들어갑니다. 즉, KV Cache가 계산되어 있지 않은 SequenceGroup에 대해서만 넣어주고, Swap된 그룹이거나 이전에 Running 상태였던 (KV Cache가 이미 계산되어 있던) 그룹에 대해서는 프롬프트 토큰을 넣어주지 않습니다.
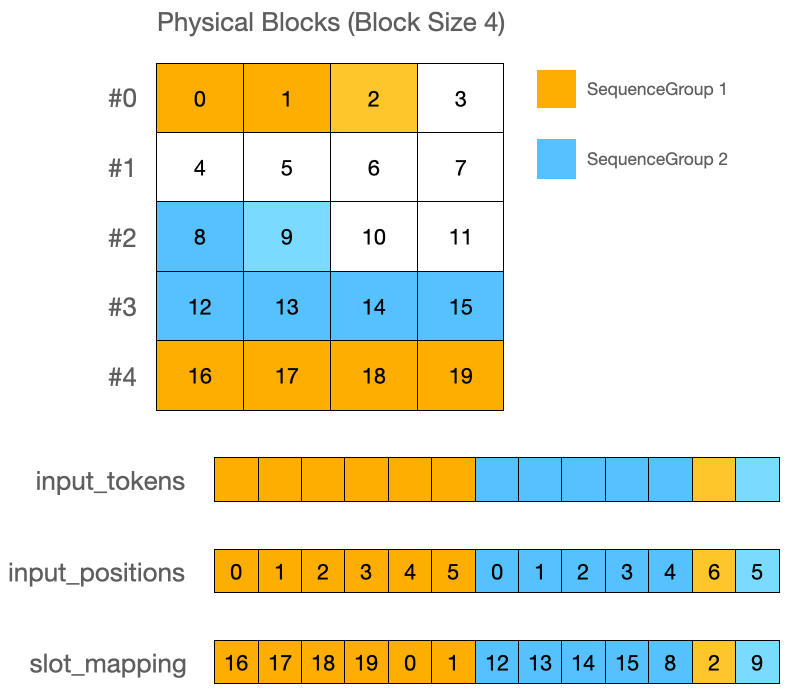
다음으로 생성 토큰을 각 시퀀스 별로 한 개씩 추가합니다. 토큰 ID는 프롬프트의 가장 마지막 토큰 ID로 해주며, 이 토큰에 해당하는 블록 및 슬롯은 스케줄러에서 Running 상태인 모든 SequenceGroup에 대해 미리 할당해 주고 있습니다.
이렇게 만들어진 input_tokens, input_positions, slot_mapping과 SequenceGroup의 블록 테이블, 기타 메타정보 (프롬프트 길이, 컨텍스트 길이)가 모델의 입력으로 들어갑니다.
Attention
트랜스포머 모델의 핵심 기능인 어텐션에 대해 알아보겠습니다. (이 글에서는 GPT2의 멀티 헤드 어텐션만 언급하겠습니다.) vLLM의 구현체에서 위 구조를 따라 크게 바뀐 점은 어텐션 뿐이며, 나머지는 Parallel 관련 구현체를 제외하면 모두 동일합니다.
# Reshape the query, key, and value tensors.
query = query.view(-1, self.num_heads, self.head_size)
key = key.view(-1, self.num_heads, self.head_size)
value = value.view(-1, self.num_heads, self.head_size)
# Pre-allocate the output tensor.
output = torch.empty_like(query)
# Compute the attention op for prompts.
num_prompt_tokens = input_metadata.num_prompt_tokens
if num_prompt_tokens > 0:
self.set_attn_bias(input_metadata)
self.multi_query_kv_attention(
output[:num_prompt_tokens],
query[:num_prompt_tokens],
key[:num_prompt_tokens],
value[:num_prompt_tokens],
input_metadata,
)
어텐션 레이어의 입력은 다음과 같이 세 개의 텐서를 받습니다.
- Query: [num_tokens, num_heads * head_size] 모양의 텐서
- Key: [num_tokens, num_heads * head_size] 모양의 텐서
- Value: [num_tokens, num_heads * head_size] 모양의 텐서
즉, 모든 토큰을 일렬로 나열하고 멀티 헤드 어텐션에 따라 헤드 개수만큼 차원이 존재합니다. 각 텐서를 [num_tokens, num_heads, head_size]의 크기로 다시 분할합니다.
이후에 프롬프트 부분에 해당하는 토큰, 다시 말해 가장 마지막 N(=Sequence 개수) 개의 토큰을 제외한 나머지 토큰에 해당하는 Q, K, V에 대해 멀티 헤드 어텐션을 적용합니다.
즉, 전체 QKV에 대해서 하지 않고 캐시가 존재하지 않은 SequenceGroup에 대해 일반적인 어텐션 계산을 수행하고 있습니다. 어텐션은 xformers의 커널을 이용합니다. (xops.memory_efficient_attention_forward)
# Key, Value를 캐시에 저장
cache_ops.reshape_and_cache(
key[:num_valid_tokens],
value[:num_valid_tokens],
key_cache,
value_cache,
input_metadata.slot_mapping,
)
# Single Query Attention
self.single_query_cached_kv_attention(
output[num_prompt_tokens:num_valid_tokens],
query[num_prompt_tokens:num_valid_tokens], key_cache,
value_cache, input_metadata)
어텐션 계산 이후 Key, Value 값을 캐시에 저장한 뒤에 캐시와 생성 토큰 (컨텍스트의 가장 마지막 토큰)을 가지고 Single Query Attention을 적용합니다.
쿠다 구현체
쿠다 구현체는 쿠다 아키텍처에 대한 사전 지식이 필요합니다. 짧게 요약해 보자면, GPU에서는 Warp 단위로 SIMT(Single Instruction Multiple Threads)가 수행되며, 쿠다 커널을 실행하려면 Grid/Block 크기로 총 스레드 수를 설정하여 처리해야 합니다. (이때의 Block은 PagedAttention의 Block과 다른 개념입니다. 따라서 이 블록은 쿠다 블록으로 호칭하겠습니다.)
저는 쿠다에 대한 지식과 테크닉이 깊지 않기 때문에 일부 내용은 부정확할 수 있다는 점 양해 부탁드립니다. 🙇♂️
KV 캐시 저장
CacheEngine 으로부터 Swap-In/Out, KV 캐시 저장의 쿠다 커널이 호출됩니다. 이때 Swap-In/Out의 구현체는 따로 알아보지 않고 어텐션 계산을 위해 KV 캐시를 저장하는 함수를 알아봅니다.
dim3 grid(num_tokens);
dim3 block(std::min(num_heads * head_size, 512));
vllm::reshape_and_cache_kernel<scalar_t><<<grid, block, 0, stream>>>(
key.data_ptr<scalar_t>(),
value.data_ptr<scalar_t>(),
key_cache.data_ptr<scalar_t>(),
value_cache.data_ptr<scalar_t>(),
slot_mapping.data_ptr<int>(),
key_stride,
value_stride,
num_heads,
head_size,
block_size,
x
);
어텐션을 계산하기 이전에 Key, Value 값을 reshape_and_cache 함수를 통해 캐시에 저장하고 있습니다. 이 함수는 [num_tokens, num_heads, head_size] 크기의 Key, Value 값들을 캐시에 복제합니다.
- Key Cache: [num_blocks, num_heads, head_size/x, block_size, x] 크기
- Value Cache: [num_blocks, num_heads, head_size, block_size] 크기
Key Cache의 x값은 16 / element_size 값이며, 고속 계산 및 고속 메모리 접근을 위한 테크닉으로 보입니다. (bfloat16 기준으로 x=8 입니다)
그리드의 크기는 입력 텐서에 포함된 전체 토큰 개수만큼 설정하고, 쿠다 블록은 min(num_heads * head_size, 512) 크기로 설정합니다.
template<typename scalar_t>
__global__ void reshape_and_cache_kernel(
const scalar_t* __restrict__ key, // [num_tokens, num_heads, head_size]
const scalar_t* __restrict__ value, // [num_tokens, num_heads, head_size]
scalar_t* __restrict__ key_cache, // [num_blocks, num_heads, head_size/x, block_size, x]
scalar_t* __restrict__ value_cache, // [num_blocks, num_heads, head_size, block_size]
const int* __restrict__ slot_mapping, // [num_tokens]
const int key_stride,
const int value_stride,
const int num_heads,
const int head_size,
const int block_size,
const int x
) {
// 각 블록 (쿠다 블록) 내에서 하나의 토큰을 담당합니다.
const int token_idx = blockIdx.x;
// 각 토큰에 대한 캐시가 어떤 슬롯 위치에 들어있는지 인덱스를 구합니다.
const int slot_idx = slot_mapping[token_idx];
const int block_idx = slot_idx / block_size;
const int block_offset = slot_idx % block_size;
캐싱하는 쿠다 커널은 한 쿠다 블록당 하나의 토큰을 담당하고 있습니다.
const int n = num_heads * head_size;
// Hidden Dimension 크기만큼 값이 들어있어서 전체 스레드가 동시에 최대 512개 만큼
// 병렬로 겹치지 않게 복제하고 있습니다.
for (int i = threadIdx.x; i < n; i += blockDim.x) {
// Key, Value는 [num_tokens, num_heads, head_size] 크기이므로
// stride = num_heads * head_size 값으로 토큰 위치를 찾습니다.
// 토큰 위치를 찾으면 각 스레드가 맡은 공간을 찾습니다.
// 즉, num_heads * head_size 크기의 배열을 512개의 스레드 (=blockDim.x)가 복제합니다.
const int src_key_idx = token_idx * key_stride + i;
const int src_value_idx = token_idx * value_stride + i;
// Cache 위치의 Stride 및 인덱스를 계산합니다.
const int head_idx = i / head_size;
const int head_offset = i % head_size;
const int x_idx = head_offset / x;
const int x_offset = head_offset % x;
// Key 캐시 크기: [num_blocks, num_heads / x, head_size, block_size, x]
const int tgt_key_idx = block_idx * num_heads * (head_size / x) * block_size * x
+ head_idx * (head_size / x) * block_size * x
+ x_idx * block_size * x
+ block_offset * x
+ x_offset;
// Value 캐시 크기: [num_blocks, num_heads, head_size, block_size]
const int tgt_value_idx = block_idx * num_heads * head_size * block_size
+ head_idx * head_size * block_size
+ head_offset * block_size
+ block_offset;
key_cache[tgt_key_idx] = __ldg(&key[src_key_idx]);
value_cache[tgt_value_idx] = __ldg(&value[src_value_idx]);
}
쿠다 블록 내 각 스레드는 캐시에 들어있는 한 개의 값을 글로벌 메모리로 복사합니다. 그러기 위해 Source 인덱스와 Target 인덱스를 계산하고, 이 값들을 이용하여 복사합니다.
Single Query Attention
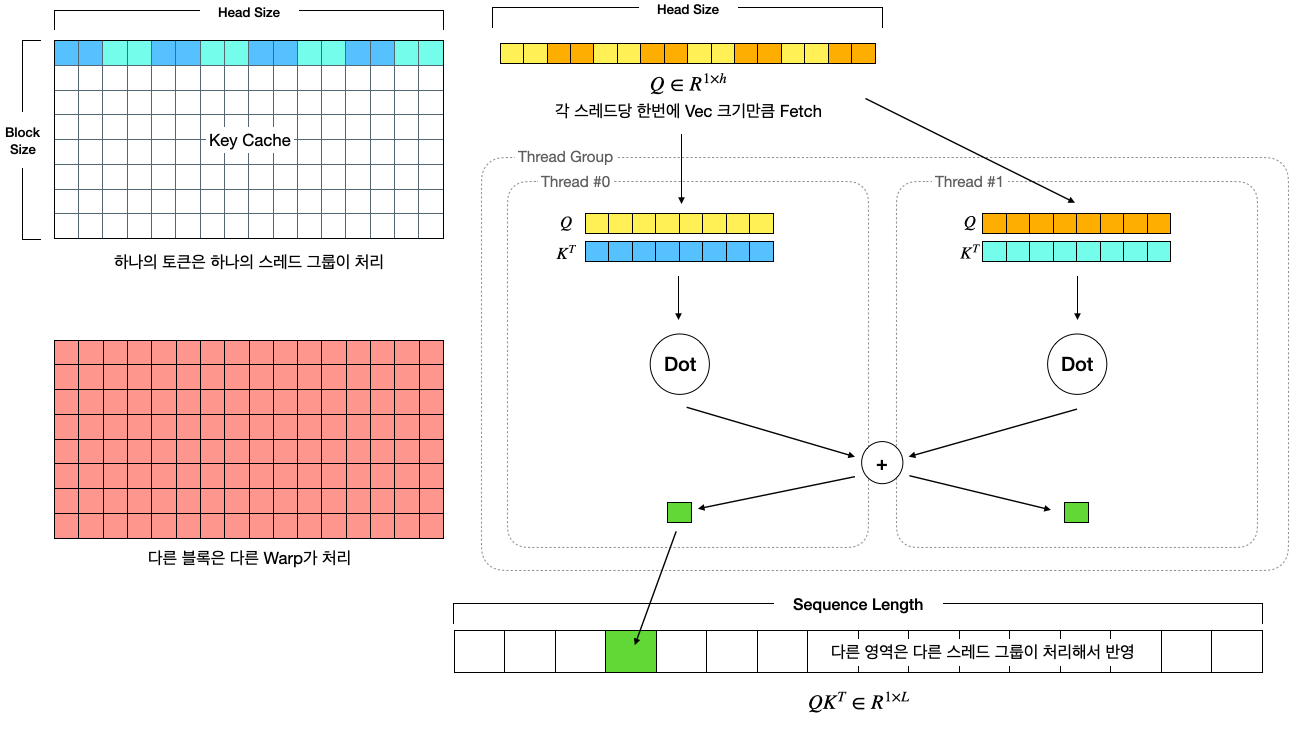
어텐션 계산을 고속화하기 위해 어텐션 계산을 KV Cache와 가장 마지막 토큰의 Query만 가지고 어텐션을 계산합니다. (Huggingface의 use_cache=True의 쿠다 버전 구현체라고 생각해도 됩니다.) 정확한 명칭은 모르겠으나, 편의상 Single Query Attention 이라고 부르겠습니다. 원본 구현체는 FasterTransformer에 있으며, vLLM은 이 구현체를 PagedAttention에 맞추어 새로 포팅 한 버전입니다.
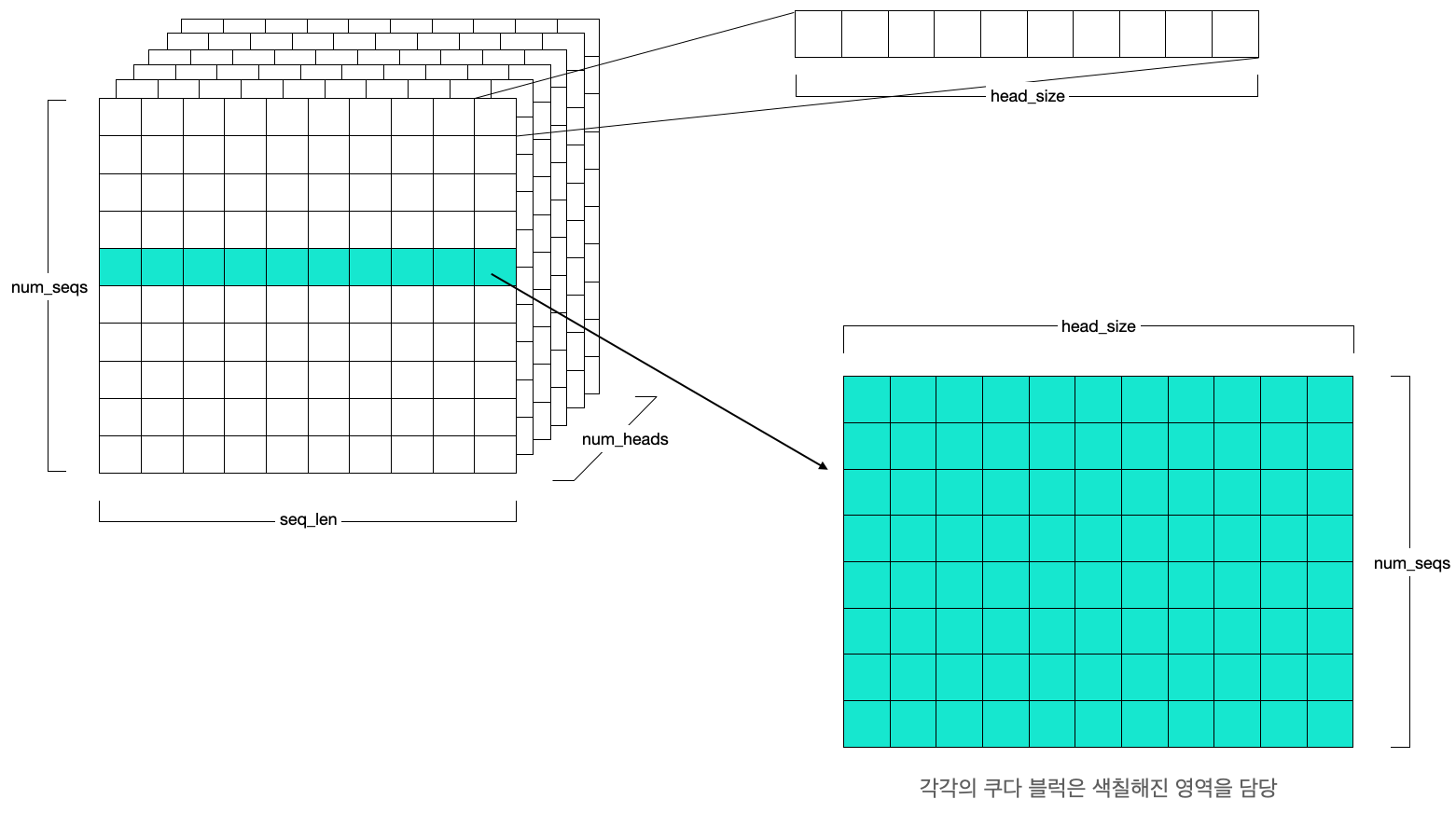
커널은 아래의 셋팅으로 실행됩니다.
- 그리드 크기: [num_heads, num_sequences] 크기의 2차원
- 쿠다 블록 크기: [128] 크기의 1차원
즉, 각 쿠다 블록은 하나의 Sequence와 하나의 헤드에 대한 연산을 수행하도록 병렬화되어 있습니다. 각 헤드와 시퀀스는 병렬적으로 실행될 수 있으므로, 블록으로 병렬화 수준을 나눈 것으로 볼 수 있습니다. 그리고 각 블록은 총 128개의 스레드에서 나누어 병렬적으로 계산하고 최종적으로 Reduce 하여 연산을 합칩니다. 따라서 각 쿠다 블록은 아래 차원의 QKV를 계산합니다.
\[Q \in R^{1 \times h} \\ K, V \in R^{L \times h}\]이때 $L$은 Sequence 길이이고, $h$는 하나의 헤드의 hidden diemension (=head_size) 입니다.
먼저 어텐션 수식을 살펴보겠습니다.
\[Attention(Q, K, V)=\text{softmax} \left( {QK^T \over \sqrt{d_k}} \right)V\]이를 파이썬 코드로 작성하면 아래와 같습니다.
def calculate_attention(query, key, value, mask):
# query, key, value: (n_batch, seq_len, d_k)
# mask: (n_batch, seq_len, seq_len)
d_k = key.shape[-1]
attention_score = torch.matmul(query, key.transpose(-2, -1)) # Q x K^T, (n_batch, seq_len, seq_len)
attention_score = attention_score / math.sqrt(d_k)
if mask is not None:
attention_score = attention_score.masked_fill(mask==0, -1e9)
attention_prob = F.softmax(attention_score, dim=-1) # (n_batch, seq_len, seq_len)
out = torch.matmul(attention_prob, value) # (n_batch, seq_len, d_k)
return out
이제 쿠다로 작성된 구현체를 분석해 보겠습니다.
병렬 계산 사전 작업
// WARP_SIZE = 32, BLOCK_SIZE = 16 (기본값인 경우)
// THREAD_GROUP_SIZE = 2, NUM_TOKENS_PER_THREAD_GROUP = 1
// 블록 내 전체 토큰 16개를 스레드 32개가 처리하도록 합니다. 따라서 토큰당 2개의 스레드가 붙어 계산합니다.
// (각 스레드 그룹에는 2개의 스레드가 있고, 각 스레드 그룹 (2개의 스레드)는 1개의 토큰에 대해 계산합니다.)
constexpr int THREAD_GROUP_SIZE = MAX(WARP_SIZE / BLOCK_SIZE, 1);
constexpr int NUM_TOKENS_PER_THREAD_GROUP = (BLOCK_SIZE + WARP_SIZE - 1) / WARP_SIZE;
// 전체 스레드 개수를 WARP_SIZE로 나누어 전체 Warp가 몇 개인지 계산 (기본값 4)
constexpr int NUM_WARPS = NUM_THREADS / WARP_SIZE;
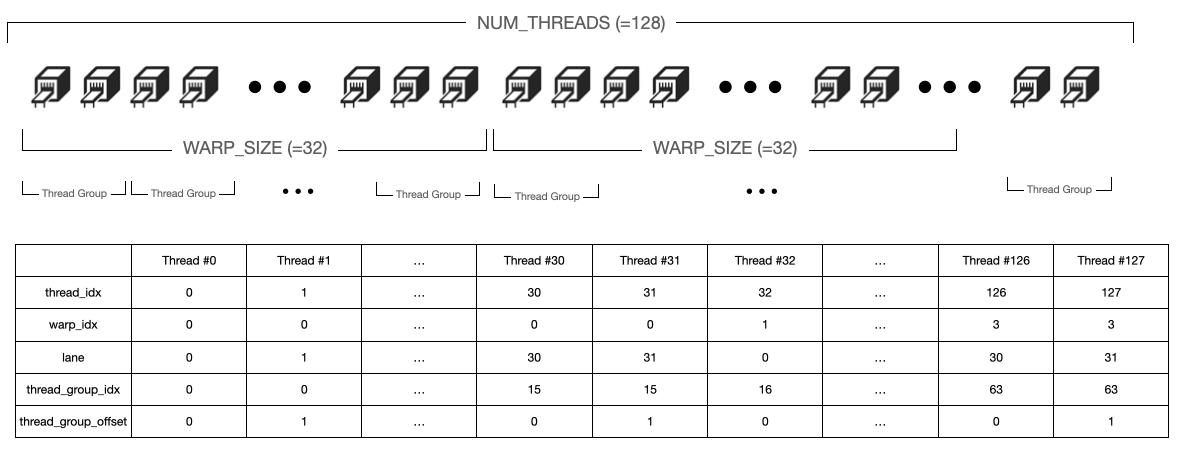
각 쿠다 블록은 하나의 헤드 및 시퀀스에 대해서 어텐션을 계산합니다. 이때 각 쿠다 블록은 128개의 스레드가 있으므로, 이 스레드가 병렬로 작업하기 위해 특정 그룹으로 나눕니다. 먼저 Thread Group 이라는 그룹이 존재하는데, 이는 하나의 Warp를 Block size 개수로 나눈 값으로 그룹 크기를 결정합니다. 따라서 블록 내에 저장되어 있는 토큰들을 Warp 내의 스레드들이 균등하게 나눠 갖고 처리하도록 합니다. (즉, 각 스레드 그룹이 Block 내 한 개의 토큰을 처리함). Warp는 Cuda의 SIMT (Single Instruction Multiple Threads) 대상의 Execution Unit 이며, A100 기준으로 Warp 내에 들어있는 스레드 개수는 32개입니다.
// thread_idx는 0~NUM_THREADS-1 사이의 값
const int thread_idx = threadIdx.x;
// 자신의 스레드 인덱스로 몇 번째 Warp인지, 그리고 몇 번째 Lane인지 계산
// warp_idx는 추후에 다른 Warp들 간의 동기화를 위해 필요하며, lane은 Warp 내에서 동기화를 위해 필요합니다.
const int warp_idx = thread_idx / WARP_SIZE;
const int lane = thread_idx % WARP_SIZE;
// 그리드 자체가 (num_heads, seq_len) 크기로 되어있으므로,
// 이 정보로부터 아래 값들을 가져올 수 있습니다.
const int head_idx = blockIdx.x;
const int num_heads = gridDim.x;
const int seq_idx = blockIdx.y;
그리고 각 스레드가 처리해야 하는 블록 또는 토큰 등의 인덱스를 지정합니다.
// 각 스레드가 소유하고 계산하기 위해 배열의 크기를 구합니다. 만약 스레드 그룹 크기가 4라면 각 스레드는 16 / 4 = 4 바이트를 처리하며,
// Element 크기에 따라 배열 크기는 달라지므로 sizeof(scalar_t)를 다시 나누어 실제 배열 크기를 구합니다. (fp16이면 4 / 2 = 2 개의 크기의 배열임)
constexpr int VEC_SIZE = MAX(16 / (THREAD_GROUP_SIZE * sizeof(scalar_t)), 1);
// 아래 Vec 타입은 실제로 벡터를 저장하기 위해 사용되는 것이 아니라, 컴파일 단계에서 미리 정의된 템플릿을 이용하여
// 배열의 타입을 구하기 위해 사용됩니다.
using K_vec = typename Vec<scalar_t, VEC_SIZE>::Type;
using Q_vec = typename Vec<scalar_t, VEC_SIZE>::Type;
Key, Value를 위해 크기를 계산합니다. 각 스레드 그룹은 동시에 16 바이트를 처리하도록 설계되어 있으며, 이 값은 파이썬 분석 파트에서의 x 값 (16 / element_size)과 대응됩니다. 스레드 그룹이 16 바이트를 처리하므로, 그룹 내 포함되는 스레드 수와 Element 크기를 곱한 값을 16에서 나누어주어 각 스레드가 처리하는 바이트 크기를 계산하고 있습니다.
// 각 스레드 별 처리하는 원소 개수
constexpr int NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE;
// Vec 타입의 배열에 담기 위해 몇 개의 Vec이 필요한지
// Vec에 대한 개인적인 생각을 아래에 정리해 두었습니다.
constexpr int NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE;
// 특정 스레드가 몇 번째 스레드 그룹에 속해 있는지
const int thread_group_idx = thread_idx / THREAD_GROUP_SIZE;
// 특정 스레드가 스레드 그룹 내 몇 번째의 스레드인지
const int thread_group_offset = thread_idx % THREAD_GROUP_SIZE;
다음으로 각 스레드 및 그룹이 처리해야 하는 요소의 개수 및 벡터의 개수를 구합니다. 각 스레드 그룹은 NUM_TOKENS_PER_THREAD_GROUP 개의 토큰에 대해서 계산을 수행해야 합니다. 각 토큰은 HEAD_SIZE 만큼의 Element가 존재하므로 각 스레드는 그룹 내에서 균등하게 분할하여 가져갑니다.
Vec 자료구조의 의미?
만약 Element 타입이 float16이고, 각 스레드가 32개를 필요로 한다면 float16 vec[32]로 하면 될 것인데, 왜 중간에 Vec을 두어서 Vec<float16, 2> vec[16] 을 했을까요? Vec 타입을 뜯어보면 Element 타입과 VEC_SIZE 마다 별도의 Type을 선언한 것을 볼 수 있습니다.
// FP16 vector types for Q, K, V.
template<>
struct Vec<uint16_t, 1> {
using Type = uint16_t;
};
template<>
struct Vec<uint16_t, 2> {
using Type = uint32_t;
};
template<>
struct Vec<uint16_t, 4> {
using Type = uint2;
};
template<>
struct Vec<uint16_t, 8> {
using Type = uint4;
};
즉, 스레드 그룹이 동시에 16바이트를 처리해야하고, 그 처리를 여러번 반복 (HEAD_SIZE 만큼 처리해야 하니까) 가장 빠르게 돌 수 있도록 코드를 선언해둔 것인데, 아래 예를 들어보면 이해가 됩니다.
만약 float16 크기의 배열 32개를 처리한다고 가정합니다. 만약 단순히 float16 vec[32]로 선언한다면, 총 32번의 Iteration이 돌 수밖에 없습니다.
FOR(i, 32) vec[i] = vec[i] + some[i];
그런데 만약 코어가 동시에 2개의 float16을 처리할 수 있다면 (SIMD), 아니면 파이프라이닝을 적용할 수 있다면 속도가 더 빠를 것입니다.
// SIMD
FOR(i, 16) simd_vec[i] = simd_vec[i] + simd_some[i];
// Pipelining
FOR(i, 16) {
vec[2 * i] = vec[2 * i] + some[2 * i];
vec[2 * i + 1] = vec[2 * i + 1] + some[2 * i + 1];
}
따라서 위와 같이 계산을 고속화 시키기 위해 중간에 Vec을 두었다고 생각할 수 있습니다.
실제로 구현체를 살펴보면, Vec<uint16_t, 2>의 경우 Type이 uint32_t인 것을 볼 수 있습니다. 즉, float16 두 개 묶음을 한 번에 처리한다는 뜻입니다. 그리고 이 벡터 타입일 때의 덧셈을 보면 아래처럼 두 개의 float16 타입 덧셈을 어셈블리 단에서 Instruction 한 개로만 수행하는 것을 볼 수 있습니다(SIMD).
inline __device__ uint32_t add(uint32_t a, uint32_t b) {
uint32_t c;
asm volatile("add.f16x2 %0, %1, %2;\n" : "=r"(c) : "r"(a), "r"(b)); // <---
return c;
}
위 내용을 도식화 하면 다음과 같이 나타낼 수 있습니다.
Query 로드 및 메모리 할당
// 쿠다 블록이 담당하는 헤드 및 시퀀스에 해당하는 원소들(=head_size개)이 위치한 주소로 이동
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
// 하나의 스레드 그룹은 토큰 단위로 계산하기 때문에 특정 토큰의 HEAD_SIZE 개의 원소를 불러와야 합니다.
// 이때 각 스레드 그룹 내의 스레드는 HEAD_SIZE / THREAD_GROUP_SIZE 개의 원소를 불러와 처리합니다.
// 중간에 Vec이 끼어있기 때문에 NUM_VECS_PER_THREAD는 이 크기가 아니지만,
// 불러오는 원소 개수는 총 HEAD_SIZE / THREAD_GROUP_SIZE 개 입니다.
Q_vec q_vecs[NUM_VECS_PER_THREAD];
// unroll을 통해 반복문을 펼쳐주고 있습니다. 컴파일 단계에서 함수는 특정 값들에 대해 오버로드된 함수가 많이 생성됩니다.
// 따라서 아래처럼 컴파일 시점에 정할 수 있는 반복문들은 모두 unroll로 펼쳐 loop (jump) instruction을 제거한 모습입니다.
#pragma unroll
for (int i = 0; i < NUM_VECS_PER_THREAD; i++) {
// 쿠다 블록 내 모든 스레드 그룹은 같은 Q 값을 읽어옵니다. 스레드 그룹 내 스레드 끼리는 띄엄띄엄 불러옵니다.
// 예를 들어 Thread Group Size 가 4라면, 0번째 스레드는 0, 4, 8번째 원소(정확히는 Vec)을 읽어오고,
// 1번째 스레드는 1, 5, 9번째 원소를 읽어옵니다.
const int vec_idx = thread_group_offset + i * THREAD_GROUP_SIZE;
// scalar_t q[size] 짜리를 곧바로 Vec<scalar_t, VEC_SIZE>로 읽어들일 수 있습니다.
// 마치 float[2] 포인터로 struct { float x; float y } 를 읽을 수 있는 것처럼 말이죠.
q_vecs[i] = *reinterpret_cast<const Q_vec*>(q_ptr + vec_idx * VEC_SIZE);
}
먼저 [num_seqs, num_heads, head_size] 크기의 쿼리를 레지스터로 로드합니다. 각 스레드는 각자 다른 파트의 쿼리 값을 불러옵니다. 이때 하나의 쿠다 블록에서는 하나의 Sequence 및 헤드에 대해 담당하므로, 실제로 불러와야 하는 크기는 head_size 개의 원소입니다.
extern __shared__ char shared_mem[];
float* logits = reinterpret_cast<float*>(shared_mem);
__shared__ float red_smem[2 * NUM_WARPS];
다음으로 출력 및 중간 계산을 위해 Shared Memory를 할당합니다. shared_mem 변수의 동적 크기는 logits의 크기와 쿠다 블록의 출력에 필요한 크기 중 큰 값으로 설정합니다. red_smem은 쿠다 블록 내 각 스레들끼리 Reduction 하기 위해 사용합니다. Warp 내부에서는 이 리덕션이 __shlf_XXX 함수로 메모리를 거치지 않고 할 수 있으므로, Warp 끼리의 리덕션에 사용하는 모습입니다. (크기는 Warp 별 float * 2 = 8바이트)
QK 계산을 위한 변수 계산
// x == THREAD_GROUP_SIZE * VEC_SIZE
// 각 스레드 그룹은 한 번에 x 개의 Key 요소를 읽어옵니다.
constexpr int x = 16 / sizeof(scalar_t);
float qk_max = -FLT_MAX;
한 번에 처리하려는 원소의 개수인 x를 계산합니다. qk_max는 Softmax 계산에 사용됩니다. 일반적으로 Softmax 계산할 때 단순히 exp()를 취하면 값이 매우 커질 수 있기 때문에 최댓값을 0으로 조정하여 오버플로가 발생하지 않도록 하는데, 이를 계산하기 위해 사용됩니다.
const int* block_table = block_tables + seq_idx * max_num_blocks_per_seq;
const int context_len = context_lens[seq_idx];
const int num_blocks = (context_len + BLOCK_SIZE - 1) / BLOCK_SIZE;
하나의 Sequence에는 여러 토큰들이 있고, 여러 블록이 있습니다. 담당하는 Sequence에 해당하는 블록 테이블과 컨텍스트 길이, 블록의 개수를 가져옵니다.
QK 계산
// 각 Warp는 하나의 블록을 처리합니다.
for (int block_idx = warp_idx; block_idx < num_blocks; block_idx += NUM_WARPS) {
const int physical_block_number = block_table[block_idx];
// ...
하나의 쿠다 블록은 하나의 시퀀스에 대해서 계산해야 합니다. 이때 각 토큰들은 블록 내에 block_size 만큼 존재하고 있습니다. 각 Warp는 하나의 블록을 처리합니다. 따라서 전체 블록 개수만큼 반복을 하면서 하나의 블록에는 하나의 Warp가 처리하도록 바깥쪽 Loop가 선언되어 있습니다.
// Warp 내 각 스레드 그룹이 담당하는 토큰에 대해서 두 번째 반복문을 실행합니다.
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
// thread_group_idx는 Warp 내에서 유일한 게 아닌 쿠다 블록 내에서 유일합니다.
// 다시 말해, Warp 내에서 유일하다면 다른 Warp의 스레드 그룹은 중복되는 thread_group_idx가 존재할 수 있지만,
// 쿠다 블록 내에서 유일하다면 중복되지 않으며, thread_group_idx로도 warp_idx를 구할 수 있다는 뜻이 됩니다.
const int physical_block_offset = (thread_group_idx + i * WARP_SIZE) % BLOCK_SIZE;
// 계산하려는 특정 토큰이 해당 Sequence 내에서 몇 번째 토큰에 해당하는지를 나타냅니다.
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
K_vec k_vecs[NUM_VECS_PER_THREAD];
그리고 하나의 스레드 그룹은 총 NUM_TOKENS_PER_THREAD_GROUP 개의 토큰에 대해 처리합니다. 이 값은 block_size보다 작으므로, 위의 코드처럼 두 번째 중첩 Loop가 실행되며, 각 반복마다 한 개의 토큰을 처리합니다. physical_block_offset 값은 특정 스레드 그룹이 블록 내에서 어느 위치에 해당하는 토큰을 계산하는지의 인덱스입니다.
for (int j = 0; j < NUM_VECS_PER_THREAD; j++) {
// key 캐시는 [num_blocks, num_heads, head_size / x, block_size, x] 크기
// 특정 스레드 그룹이 불러올 때 공통으로 적용할 수 있는 인덱스인 [num_blocks, num_heads, block_size]
// 부분의 오프셋은 미리 계산하여 k_ptr에 저장합니다.
const scalar_t* k_ptr = k_cache + physical_block_number * num_heads * HEAD_SIZE * BLOCK_SIZE
+ head_idx * HEAD_SIZE * BLOCK_SIZE
+ physical_block_offset * x;
// 스레드 그룹 내 특정 스레드는 head_size / THREAD_GROUP_SIZE 개의 원소를 불러와야 합니다.
// 남은 파트인 [head_size / x, x] 부분을 2차원으로 축소하여 생각하면
// head_size / x 부분의 인덱스는 offset1으로, x 부분의 인덱스는 offset2로 저장하여
// 불러옵니다. 이때 각 스레드는 한 번의 x 개의 원소를 불러올 수 있습니다.
const int vec_idx = thread_group_offset + j * THREAD_GROUP_SIZE;
const int offset1 = (vec_idx * VEC_SIZE) / x;
const int offset2 = (vec_idx * VEC_SIZE) % x;
k_vecs[j] = *reinterpret_cast<const K_vec*>(k_ptr + offset1 * BLOCK_SIZE * x + offset2);
}
각 스레드는 이제 Key 캐시로부터 데이터를 로드합니다. 이때 각 스레드 그룹은 한 번에 하나의 토큰에 대해 불러오므로, 스레드 그룹 내의 스레드는 토큰에 대한 데이터를 나누어 로드합니다. 즉, 스레드 그룹이 head_size 개의 원소를 불러오고 각 스레드는 head_size / THREAD_GROUP_SIZE 개의 원소를 불러옵니다.
이때 Key 캐시에 들어있는 Shape은 [head_size, block_size] 꼴의 형태입니다. (즉, Transpose 되어있습니다.)
// --- attention_utils.cuh ---
// Q*K^T operation.
template<int THREAD_GROUP_SIZE, typename Vec, int N>
inline __device__ float qk_dot_(const Vec (&q)[N], const Vec (&k)[N]) {
using A_vec = typename FloatVec<Vec>::Type;
// Compute the parallel products for Q*K^T (treat vector lanes separately).
A_vec qk_vec = mul<A_vec, Vec, Vec>(q[0], k[0]);
#pragma unroll
// 각 스레드가 갖고 있는 Q와 K의 원소를 곱해 누적합을 구합니다.
for (int ii = 1; ii < N; ++ii) {
qk_vec = fma(q[ii], k[ii], qk_vec);
}
// Finalize the reduction across lanes.
float qk = sum(qk_vec);
#pragma unroll
// 각 스레드 그룹 내에 있는 스레드들끼리 리덕션을 수행하여
// 스레드 그룹의 모든 스레드가 최종적으로 더해진 스칼라 값 하나를
// 갖도록 합니다.
for (int mask = THREAD_GROUP_SIZE / 2; mask >= 1; mask /= 2) {
qk += __shfl_xor_sync(uint32_t(-1), qk, mask);
}
return qk;
}
// --- end of attention_utils.cuh ---
// In-Thread Dot Production을 해주고 스레드 그룹 내에서 리덕션을 수행하여 최종적으로
// 스레드 그룹 내의 스레드들이 계산한 모든 값을 더한 결과를 서로가 갖고 있습니다.
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(q_vecs, k_vecs);
Key 값들을 불러왔다면, Q와 K를 곱해주어 하나의 스칼라 값으로 만들어줍니다. QK_dot() 함수는 스레드 그룹 내에서 Dot Production를 계산하고, 하나의 값으로 더해주는 reduction 작업이 포함되어 있습니다.
// slope은 1/2^n 꼴의 Slope, 뒤의 항은 ALiBi의 수식의 Penalty이며 두 값을 곱해 더해줍니다.
qk += (alibi_slope != 0) ? alibi_slope * (token_idx - context_len) : 0;
// 스레드 그룹의 대표가 logits에 추가해줍니다.
if (thread_group_offset == 0) {
// 부분적으로 Reduction 된 값을 Shared Memory에 저장합니다.
const bool mask = token_idx >= context_len;
logits[token_idx] = mask ? 0.f : qk;
// 최댓값을 갱신합니다.
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
마지막으로 각 스레드 그룹의 첫 번째 스레드가 대표로 자신이 속한 스레드 그룹이 맡은 토큰의 QK 값을 Shared 메모리에 저장하며, 맡은 토큰들의 최대 QK 값을 갖고 있습니다.
QK 값의 최댓값
위 과정이 모두 끝나면 이제 logits 변수에는 $QK^T$ 값이 저장되어 있습니다. 이제 이 값들 중 최댓값을 구해야 합니다. 이 과정에 사용하는 Reduction 기법은 Butterfly Reduction 이라는 기법을 사용하여 수행하고 있습니다.
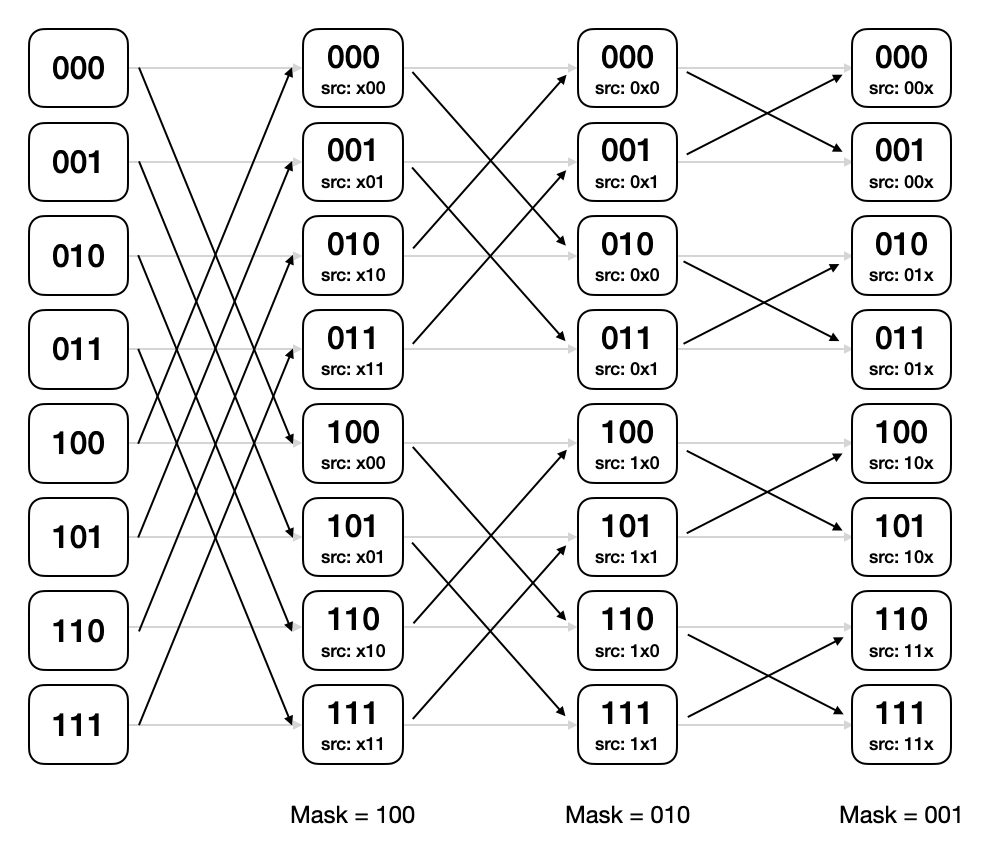
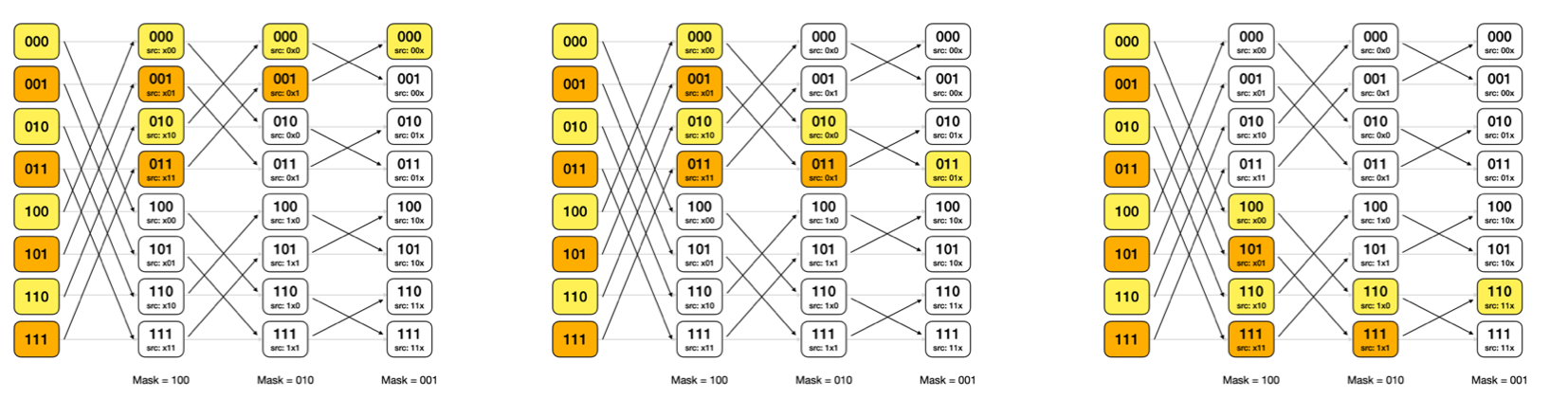
Butterfly Reduction?
병렬처리에서 Reduction을 그룹 내에서 빠르고 효율적으로 처리하는 방식입니다. 특히 Warp 내에서 레지스터를 통해 고속으로 리덕션을 수행할 수 있다는 점에서 매우 빠릅니다. 방법은 다음과 같습니다.
- 스레드 개수 N(=2^k)에 대해서 마스크 M = N / 2 로 초기화하며, 각 스레드는 0부터 N - 1 까지 번호가 메겨져 있습니다.
- 각 스레드는 자신의 번호에 마스크 M을 XOR 연산 후 나온 값 T에 대해서 스레드 T번이 갖고 있는 데이터와 교환하여 받아온 뒤, 연산을 수행합니다.
- 각 스레드는 연산 후 결과를 저장하고, M = M / 2로 변경합니다.
- 위 과정을 M이 0이 될 때까지 반복합니다.
def reduce_sum(tid, value):
mask = NUM_THREADS >> 1
while mask > 0:
value += exchange(tid ^ mask, value)
mask >>= 1
__synchronize()
return values[0]
아래는 총 8개 스레드에서 동작하는 원리입니다.
최종적으로 어느 스레드를 선택해도 모든 스레드의 값들을 반영합니다.
// Butterfly Reduction
#pragma unroll
for (int mask = WARP_SIZE / 2; mask >= THREAD_GROUP_SIZE; mask /= 2) {
qk_max = fmaxf(qk_max, __shfl_xor_sync(uint32_t(-1), qk_max, mask));
}
if (lane == 0) {
red_smem[warp_idx] = qk_max;
}
__syncthreads();
먼저 Warp 내에서 Butterfly Reduction 방법으로 리덕션을 수행합니다. 각자가 갖고 있는 QK의 최댓값을 서로 동기화하여 결국엔 Warp 내의 모든 스레드는 같은 값을 갖게 됩니다. 그런 다음 Warp의 대표(0번 Lane)가 Shared 메모리에 Warp Index 위치에 최댓값을 작성합니다. 이 값은 이후에 서로 다른 Warp 끼리 최댓값을 동기화하기 위해 사용됩니다.
qk_max = lane < NUM_WARPS ? red_smem[lane] : -FLT_MAX;
#pragma unroll
for (int mask = NUM_WARPS / 2; mask >= 1; mask /= 2) {
qk_max = fmaxf(qk_max, __shfl_xor_sync(uint32_t(-1), qk_max, mask));
}
다음으로 Warp 내에서 일부 스레드가 Shared 메모리에 저장된 최댓값들을 불러옵니다. 이를 통해 하나의 Warp는 다른 Warp에서 계산된 최댓값을 보유하고 있습니다. 최댓값을 보유하고 있는 스레드들끼리 리덕션을 수행합니다. (Butterfly Reduction)
qk_max = __shfl_sync(uint32_t(-1), qk_max, 0);
마지막으로 Warp의 대표 스레드가 Warp 내 다른 스레드들에게 자신의 값을 전달하여 최종적으로 쿠다 블록 내 모든 스레드가 서로 같은 최댓값을 볼 수 있게 됩니다.
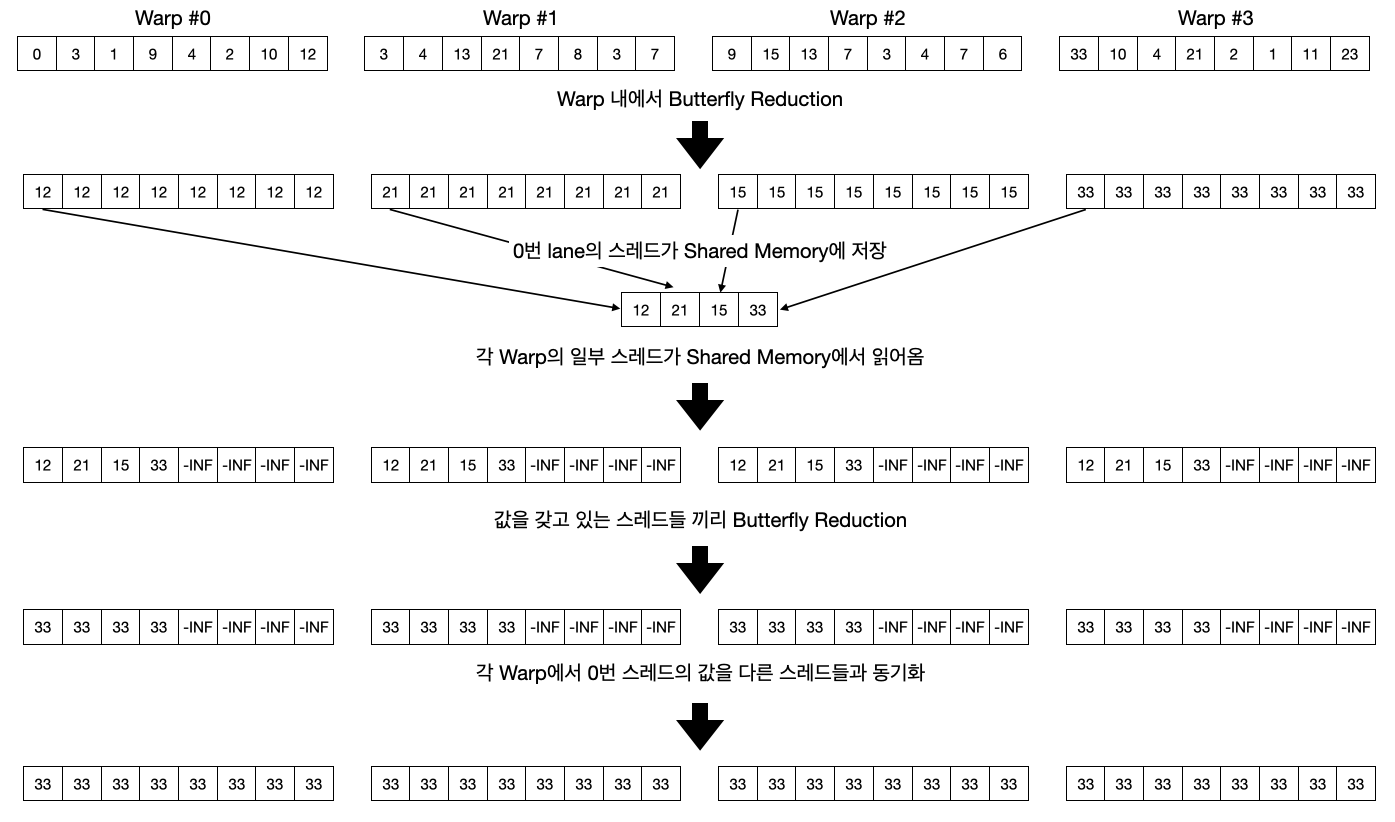
Softmax
float exp_sum = 0.f;
// 각 스레드들의 번호로 Logit을 가져옵니다.
for (int i = thread_idx; i < context_len; i += NUM_THREADS) {
// 앞에서 구한 QK 최댓값을 빼주어 Exp를 취해줍니다.
float val = __expf(logits[i] - qk_max);
logits[i] = val;
exp_sum += val;
}
// QK Max를 구한것 처럼 쿠다 블록 내에서 리덕션을 수행합니다. (Reduce Sum)
exp_sum = block_sum<NUM_WARPS>(&red_smem[NUM_WARPS], exp_sum);
// Softmax를 계산합니다.
const float inv_sum = __fdividef(1.f, exp_sum + 1e-6f);
for (int i = thread_idx; i < context_len; i += NUM_THREADS) {
logits[i] *= inv_sum;
}
__syncthreads();
이제 Softmax를 취해 값을 구합니다. 스레드는 Logits 내의 값들 중 자신의 스레드 번호 (thread_idx)에 해당하는 스칼라 값 한 개를 가져와 exp()를 취한 뒤에 각자가 갖고 있는 값들로 위에서 했던 것처럼 Reduction을 수행합니다. 이때는 Max를 취하는 게 아닌 덧셈을 취합니다. (block_sum 함수) 그런 다음 Softmax의 분모 부분을 구해 나눠줍니다.
QKV 계산
어텐션 계산의 마지막 부분으로, 어텐션 스코어 $\text{softmax} \left( {QK^T \over \sqrt{d_k}} \right)$ 값에 $V$를 곱해야 합니다. 여기서는 QK값을 구했을 때와는 달리 스레드 그룹이 더 이상 사용되지 않습니다.
constexpr int V_VEC_SIZE = MIN(16 / sizeof(scalar_t), BLOCK_SIZE);
using V_vec = typename Vec<scalar_t, V_VEC_SIZE>::Type;
using L_vec = typename Vec<scalar_t, V_VEC_SIZE>::Type;
using Float_L_vec = typename FloatVec<L_vec>::Type;
먼저 QK를 계산했을 때와 마찬가지로 Vec이라는 개념이 사용되며, 하나의 스레드가 16바이트를 읽어올 수 있도록 Vec의 크기를 설정합니다. logits은 보다 정밀한 Softmax를 구하기 위해 float32로 변환되어 계산되었습니다. 여기서는 다시 scalar_t 값으로 역으로 변환되어 계산되기 때문에 float32의 값들을 scalar_t 타입으로 읽어올 수 있도록 Float_L_vec 타입을 선언한 모습입니다.
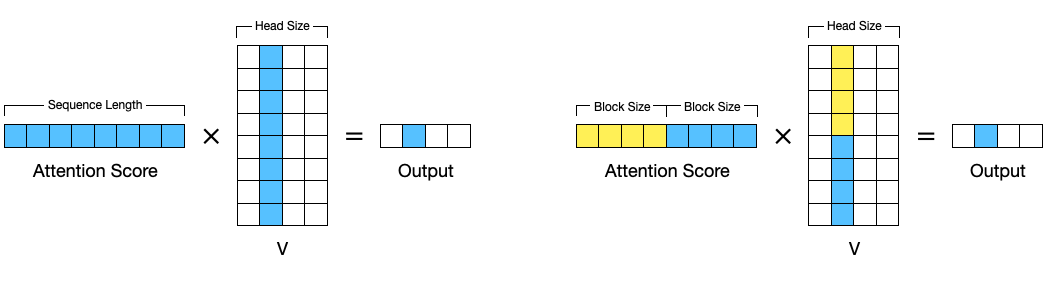
다음으로 각 스레드가 챙겨야 하는 크기들을 계산합니다. 어텐션 스코어에 V를 곱할 때 V는 위 그림과 같이 열단위의 데이터가 필요합니다. (저장되어 있는 Shape은 [head_size * block_size] 이므로, 실제로 접근하는 건 Row 단위)
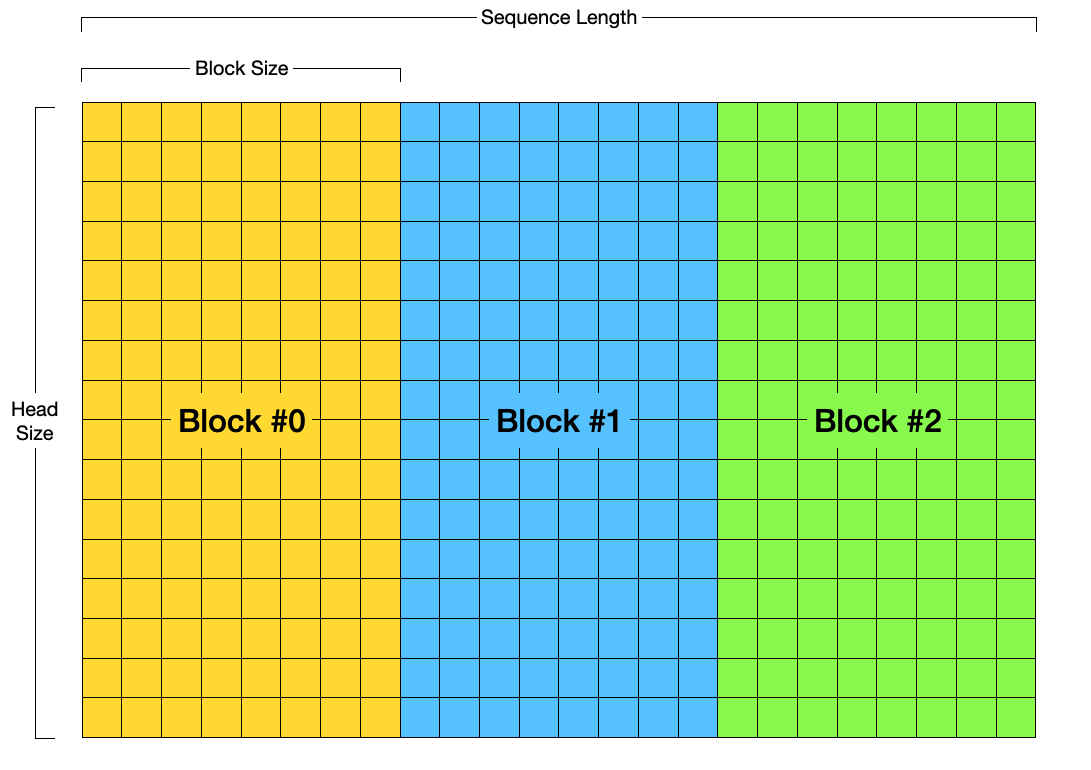
하나의 Warp는 하나의 블록을 담당합니다. 즉, 32개의 스레드는 block_size 개의 토큰에 대한 QKV를 계산하는 것이 됩니다. 이를 각 스레드 별로 분할하여 나중에 합치게 되는데, 스레드 별로 몇 개의 데이터를 불러와 계산해야 하는지를 정합니다. 최종 Output은 모든 블록(=모든 토큰)에 대해서 합쳐야 하므로, 가장 마지막에 수행됩니다.
// V 행렬에서는 위 그림에서 열에 해당하는 원소가 필요합니다.
// 각 스레드는 한 번에 16바이트를 읽어야 하므로, 블록 크기에 V_Vec 크기를 나누어 몇 번으로 나누어 읽어야 하는지 계산합니다.
// 즉, 블록 내에서 하나의 Row에 대해 행렬 곱셈을 수행하려면 몇 개의 Vec이 필요한 지 나타냅니다.
// 각 Row는 Block Size 개의 원소가 들어있으므로, 아래 수식이 완성됩니다.
constexpr int NUM_V_VECS_PER_ROW = BLOCK_SIZE / V_VEC_SIZE;
// 하나의 Row에 대해 Warp 내 각 스레드에게 나눠주어 곱을 계산하는데, 균등하게 나눠줄 경우, 총 몇 개의 Row에 대해서 계산할 수 있는지
// 나타냅니다. 예를 들어 Row의 크기(=Block Size)가 32이고 V_Vec 크기가 8이라면, 각 Row에 대해서 V_Vec 4개가 필요하고
// Warp에서 한 번에 32개의 V_Vec을 가져올 수 있으므로, 하나의 Warp는 한 번에 32 / 4 = 8개의 Row에 대해서 처리할 수 있습니다.
constexpr int NUM_ROWS_PER_ITER = WARP_SIZE / NUM_V_VECS_PER_ROW;
// 하나의 Warp에서는 한 번에 NUM_ROWS_PER_ITER 개의 Row에 대해서 처리할 수 있습니다.
// 이 과정을 Head Size 개를 모두 처리할 때까지 반복해야 하므로, 총 Head Size / NUM_ROWS_PER_ITER 번 반복해야 합니다.
constexpr int NUM_ROWS_PER_THREAD = (HEAD_SIZE + NUM_ROWS_PER_ITER - 1) / NUM_ROWS_PER_ITER;
위의 코드에서 ROW의 의미는 V 캐시에 저장된 [head_size, block_size] 꼴의 행렬에서 head_size 파트 부분입니다. (즉, 위 그림에서 V 쪽의 열 부분)
float accs[NUM_ROWS_PER_THREAD];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
accs[i] = 0.f;
}
각 스레드가 계산에 사용한 결과를 저장하기 위한 공간을 할당하고 초기화합니다.
for (int block_idx = warp_idx; block_idx < num_blocks; block_idx += NUM_WARPS) {
// QK 값을 계산할 때처럼 오프셋을 계산합니다.
const int physical_block_number = block_table[block_idx];
const int physical_block_offset = (lane % NUM_V_VECS_PER_ROW) * V_VEC_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
// logits에는 float32 타입의 원소가 저장되어 있습니다. 이를 scalar_t 타입의 공간에
// 캐스팅하여 저장합니다. 실제 계산은 float32로 다시 캐스팅하여 연산합니다.
// 한 번에 16바이트를 읽어옵니다.
L_vec logits_vec;
from_float(logits_vec, *reinterpret_cast<Float_L_vec*>(logits + token_idx));
// V 캐시에 알맞은 위치로 이동합니다. 이때 특정 쿠다 블록이 바라보는 캐시는 [head_size, block_size]
// Shape의 공간이므로, 아래 그림을 Transpose 한 상태로 보면 됩니다.
const scalar_t* v_ptr = v_cache + physical_block_number * num_heads * HEAD_SIZE * BLOCK_SIZE
+ head_idx * HEAD_SIZE * BLOCK_SIZE;
하나의 Warp는 여러 개의 블록을 처리합니다. 즉, [1, block_size] 크기의 어텐션 스코어와 [block_size, head_size] 크기의 V 행렬 과의 곱셈을 수행합니다. 계산은 float32로 캐스팅하여 계산합니다.
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE) {
const int offset = row_idx * BLOCK_SIZE + physical_block_offset;
// 16바이트 크기의 원소를 읽어와 곱한 뒤에 accs 변수에 저장합니다.
V_vec v_vec = *reinterpret_cast<const V_vec*>(v_ptr + offset);
// 만약 어떤 Warp가 다른 블록에 대해서 이미 수행했다고 하더라도 전체적으로 봤을 때
// 같은 Row에 대해서 Dot Production을 수행하므로, 이전의 블록 때 계산했던 값에 더하면 됩니다.
accs[i] += dot(logits_vec, v_vec);
}
}
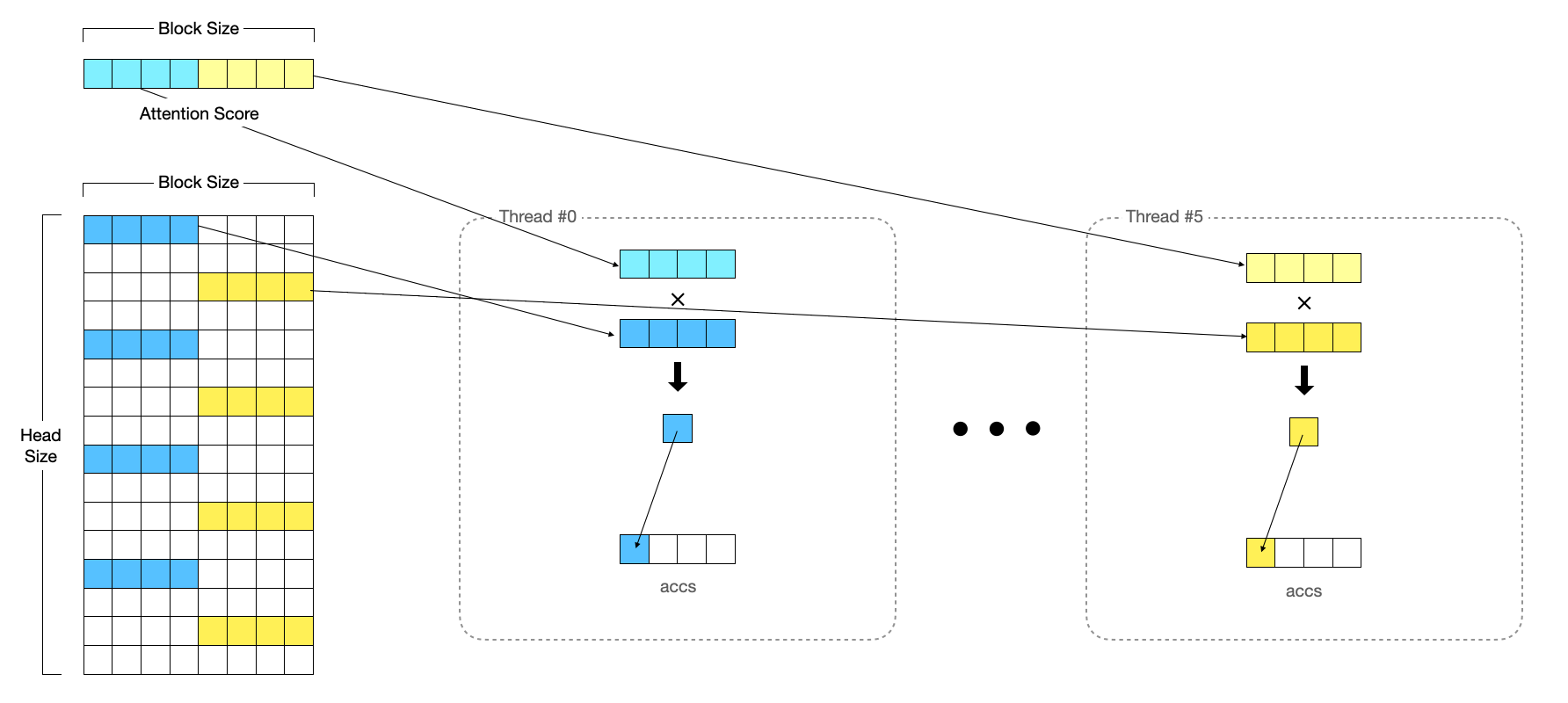
각각의 스레드가 맡은 파트의 Dot Production를 수행합니다.
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
float acc = accs[i];
#pragma unroll
// 같은 Row에 대해 계산한 스레드들끼리 Reduction 수행
for (int mask = NUM_V_VECS_PER_ROW / 2; mask >= 1; mask /= 2) {
acc += __shfl_xor_sync(uint32_t(-1), acc, mask);
}
// 최종적으로 특정 블록에 대한 Dot Production 결과가 담김
accs[i] = acc;
}
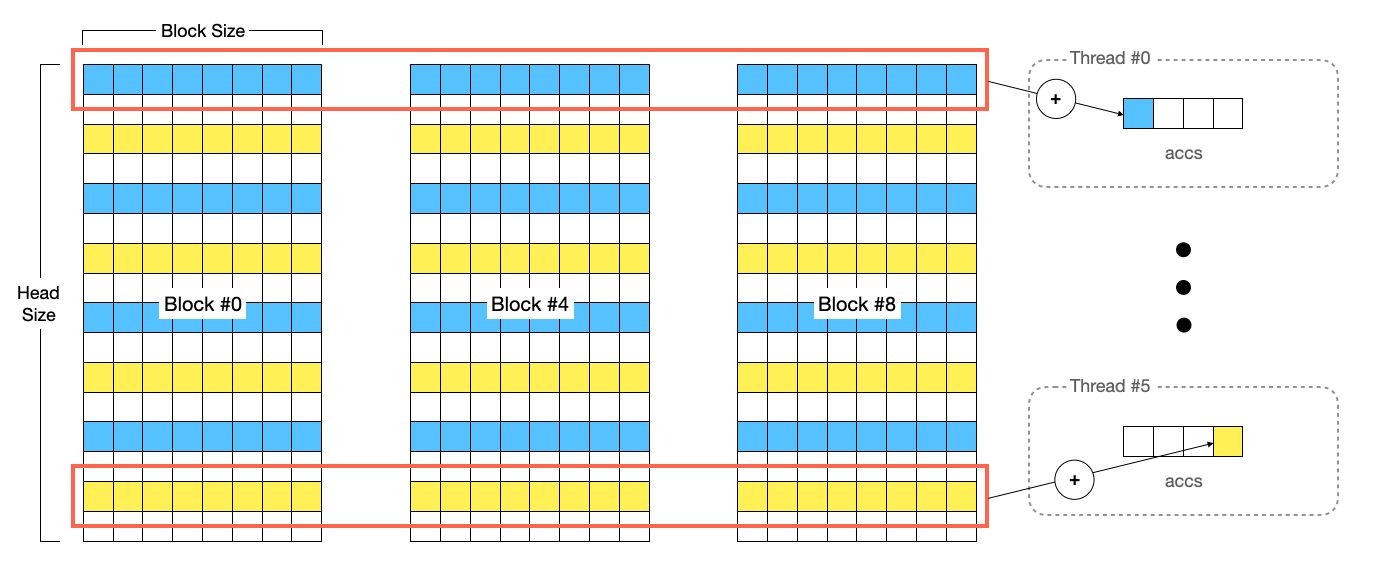
하나의 스레드는 V 행렬의 Row 중 일부분을 담당하고 있습니다. 실제 Dot Production는 Row 전체에서 합을 구해야 하므로, 같은 Row를 담당하는 스레드들끼리 Butterfly Reduction을 수행하여 실제 합을 구합니다.
// 동기화에 필요한 메모리를 설정합니다. 이때 logits을 계산하고 저장하기 위해 사용했던
// Shared 메모리를 재사용합니다.
float* out_smem = reinterpret_cast<float*>(shared_mem);
#pragma unroll
// 동기화 대상의 Warp들을 선정합니다. 진행될수록 동기화해야 할 Warp의 수는
// 절반씩 감소됩니다.
for (int i = NUM_WARPS; i > 1; i /= 2) {
int mid = i / 2;
// 절반의 상위 Warp들 내의 스레드들은 Shared 메모리에 작성만 합니다.
// 위치는 자신이 맡았던 모든 Row입니다.
if (warp_idx >= mid && warp_idx < i) {
float* dst = &out_smem[(warp_idx - mid) * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
// 특정 Row를 맡은 스레드들 중 대표로 하나의 스레드만 Shared Memory에 작성합니다.
// (lane % NUM_V_VECS_PER_ROW == 0)
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
dst[row_idx] = accs[i];
}
}
}
__syncthreads();
// 절반의 하위 Warp들 내의 스레드들은 Shared 메모리에 작성된 다른 Warp의 값들을 불러와
// 자신이 갖고 있던 결과에 더해줍니다. 위치는 자신이 맡았던 모든 Row입니다.
if (warp_idx < mid) {
const float* src = &out_smem[warp_idx * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
// 특정 Row를 맡은 스레드들 중 대표로 하나의 스레드만 Shared Memory에서 불러옵니다.
// (lane % NUM_V_VECS_PER_ROW == 0)
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
accs[i] += src[row_idx];
}
}
}
__syncthreads();
}
아직까지는 블록 단위로 행렬 곱셈을 수행하였습니다. 이제 다른 Warp가 담당했던 블록들과의 동기화가 필요합니다. 이때 사용하는 방식은 Butterfly Reduction과 유사한 방식으로 수행합니다. 차이점은 Butterfly Reduction 이후에는 모든 스레드들은 최종적으로 같은 값을 갖게 되지만, 이 동기화 방식은 0번 Warp의 스레드들만 최종 값을 갖게 됩니다.
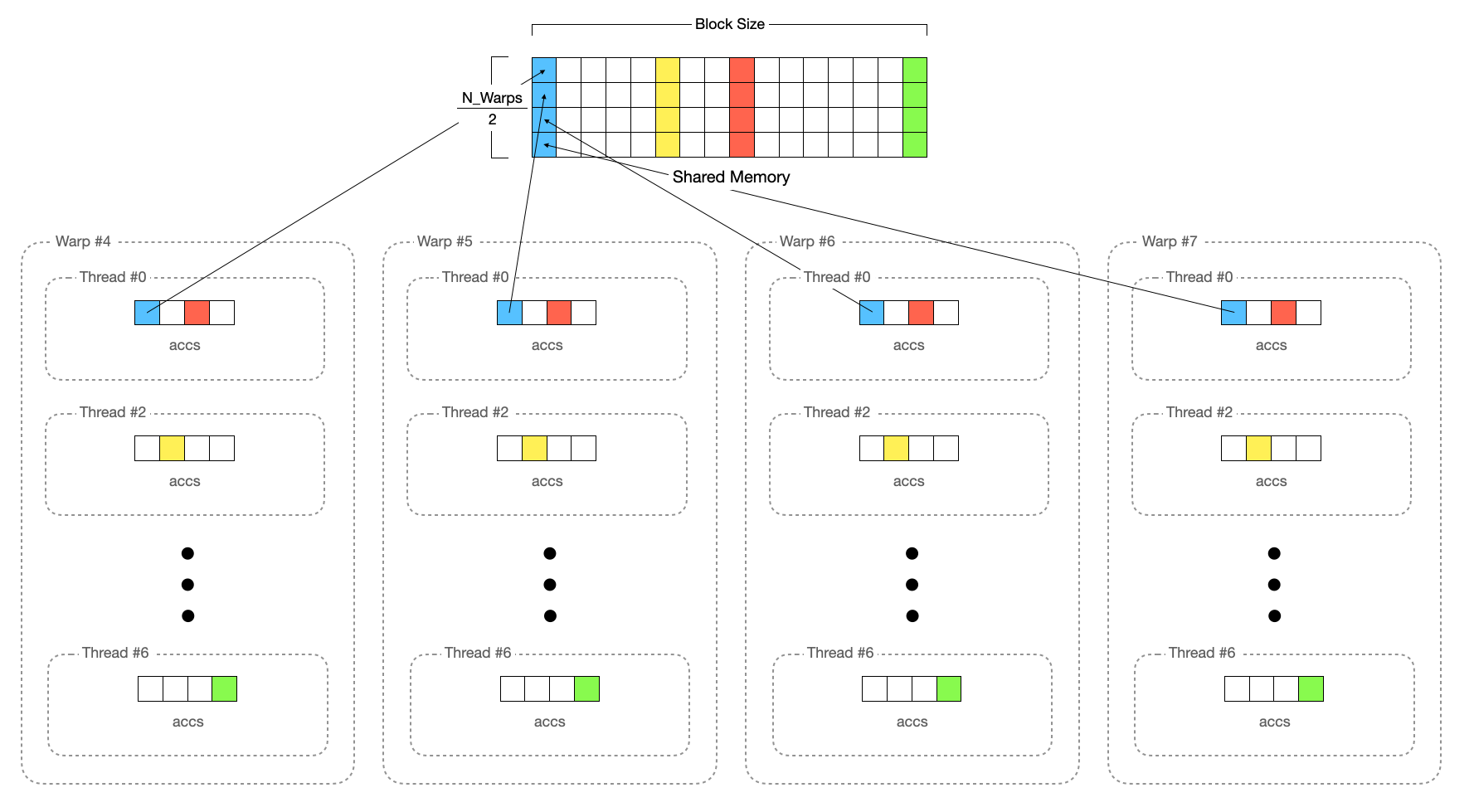
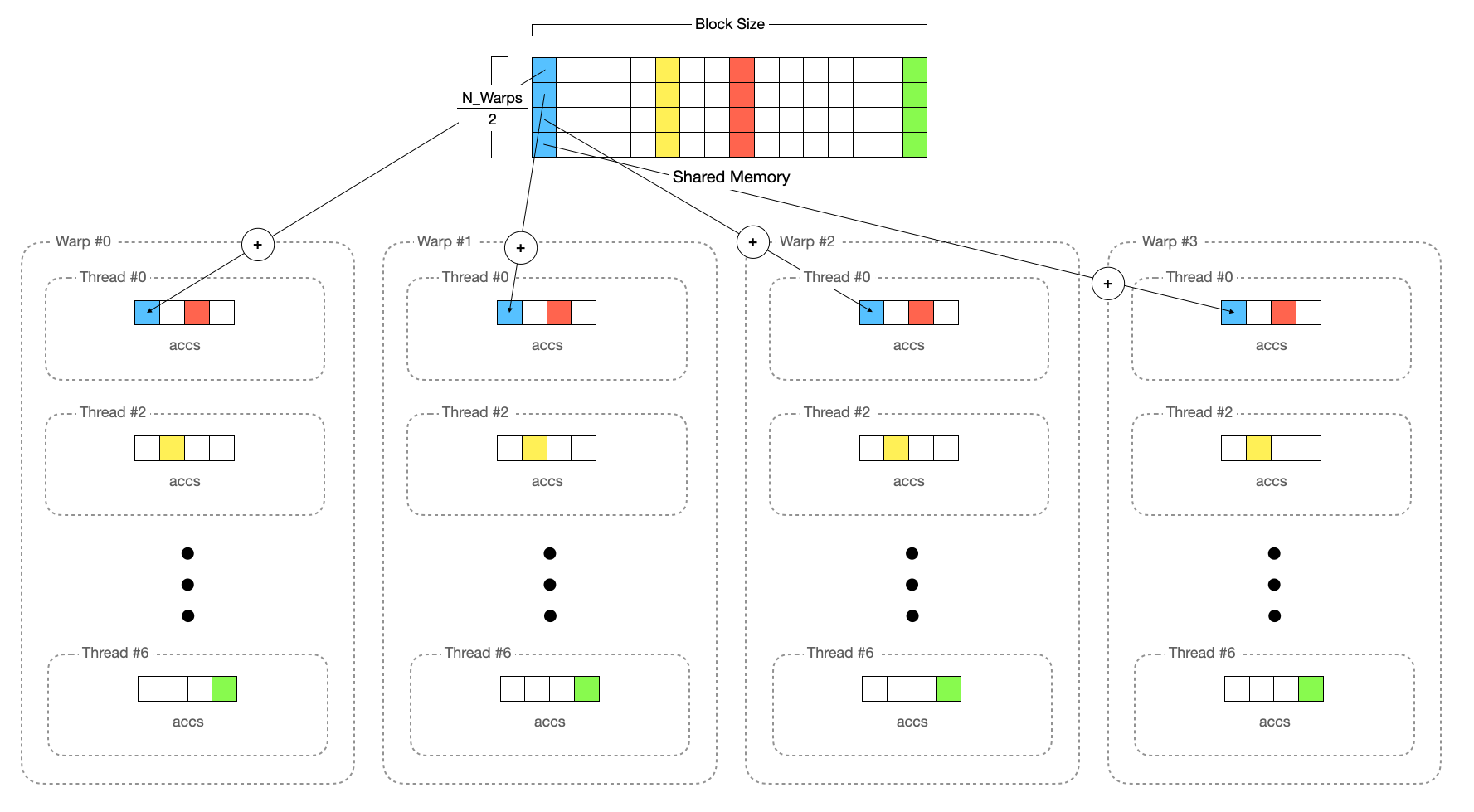
이때 동기화해야 할 대상은 각기 다른 블록이 아닌 Warp 간의 동기화입니다. 하나의 Warp가 이미 여러 블록에 대해서 계산하고 합을 구해놨기 때문입니다.
이 과정을 반복하면 0번 Warp는 최종적으로 [1, head_size] 크기의 어텐션 값을 갖게 됩니다.
// 0번 Warp만 복사를 수행합니다.
if (warp_idx == 0) {
scalar_t* out_ptr = out + seq_idx * num_heads * HEAD_SIZE + head_idx * HEAD_SIZE;
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
from_float(*(out_ptr + row_idx), accs[i]);
}
}
}
이제 마지막으로 최종 출력 텐서에 값을 복사해주면서 마무리 됩니다.
마치며
지금까지 vLLM이 어떻게 구현되어 있는지 자세하게 알아보았습니다. 깊은 내용을 담고 있다 보니 내용이 길고 복잡하지만 최대한 이해하기 쉽게 작성해보았습니다. 그리고 현재도 vLLM은 계속 업그레이드 되어가고 있으면서 구현체가 상당 부분 다른 점도 있을 수 있기에 참고해 주시기 바랍니다.