Apache Beam으로 머신러닝 데이터 파이프라인 구축하기 2편 - 개발 및 최적화
대규모 머신러닝 데이터 파이프라인 개발하고 최적화하기


지난 글에서는 핑퐁팀이 어떻게 Apache Beam을 도입하였는지를 설명드렸어요! 이번 글에서는 본격적으로 유지보수성을 높이면서 어떻게 머신러닝 데이터 파이프라인을 개발하였는지 차근차근 설명해 드릴게요. 😄
DoFn과 PTransform
Apache Beam은 거대한 규모의 데이터 파이프라인을 손쉽게 작성하기 위해 분산 데이터와 이에 대한 처리 방식을 높은 수준으로 추상화했어요. 대표적인 추상체로는 PCollection과 PTransform이 있어요.
- PCollection은 잠재적으로 분산되어서 저장될 수 있는 데이터셋을 In-memory 데이터처럼 활용할 수 있도록 도와주는 추상체에요.
- PTransform은 Pipeline의 Operation을 담당하며, 하나의 PCollection을 입력으로 받아서 유저가 작성한 코드를 기반으로 데이터를 각 element별로 처리를 한 뒤 그 결과를 PCollection로 내보내요.
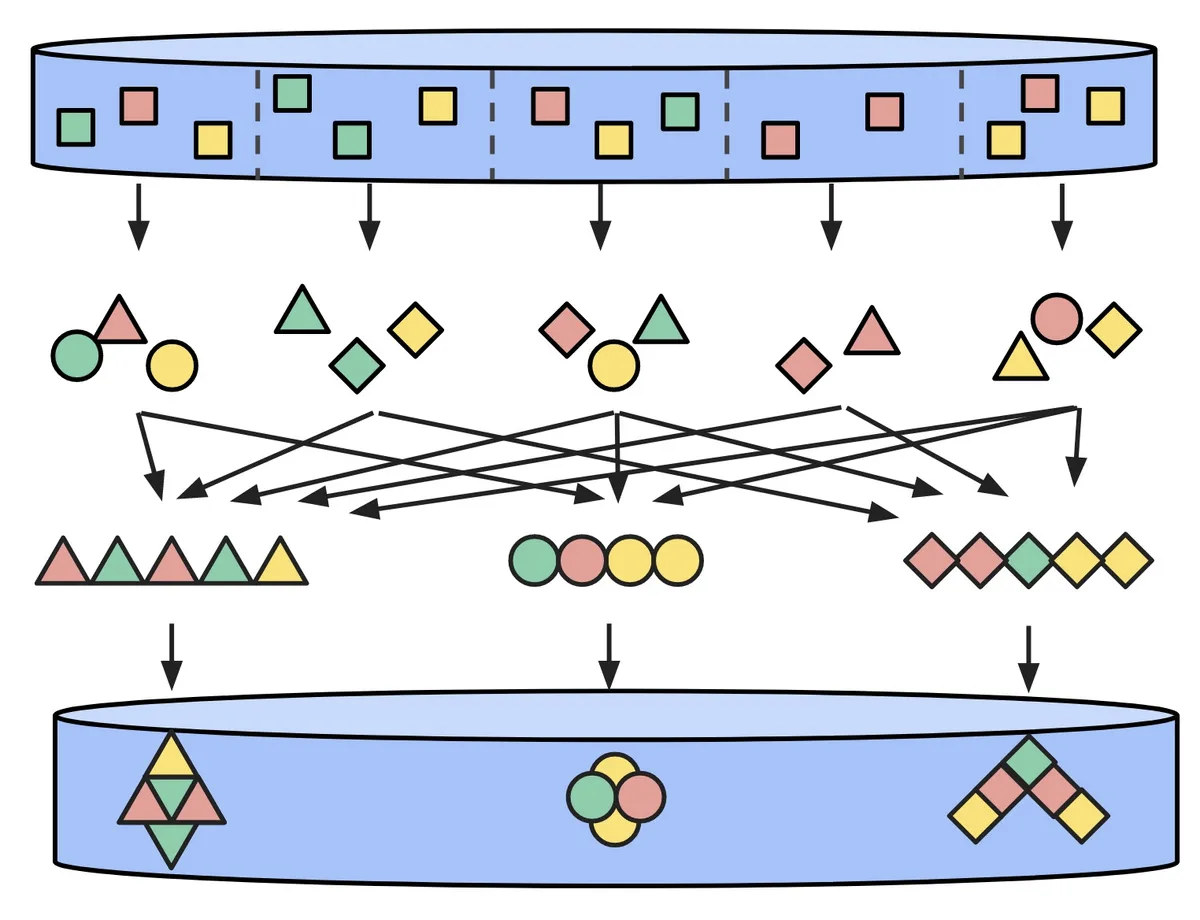
ParDo는 대표적인 PTransform중 하나로, 이름에서 알 수 있듯이 Parallel하게 사용자가 작성한 로직으로 데이터를 Transform시키고, 하나 또는 여러 개의 element를 내보내거나 아예 내보내지 않아요. MapReduce에서의 Map 과정과 유사한 동작을 해요! 이 ParDo의 처리 로직은 바로 DoFn을 통해 구현할 수 있어요.
혼돈의 DoFn 🤯
DoFn은 입력되는 PCollection의 각각의 요소에 적용할 처리 로직을 담아요.
보통 우리가 Beam에서 Pipeline의 Op을 구현했다는 것은 이 DoFn을 구현했다는 것을 의미하지요.
DoFn을 구현하기 위해선 아래와 같이 process()를 구현해서 하나의 element가 들어왔을 때 원하는 작업을 수행해요.
class ComputeWordLengthFn(beam.DoFn):
def process(self, element):
return [len(element)]
즉, 데이터셋의 element 하나를 가져왔을 때 이 element를 다른 형태로 변형을 하거나, 특정 조건에 맞지 않으면 반환 자체를 하지 않거나, 하나의 element를 여러 개로 쪼개는 등 원하는 모든 작업이 가능해요.
하지만, 원하는 파이프라인 로직을 구현하기 위해 DoFn들을 생각없이 구현한다면 결국 여러 문제가 발생하게 되는데, 여러 DoFn들이 난립하면서 1) 각각이 데이터의 스키마를 어떻게 바꾸는지 추적하기 어렵고, 2) 동일 로직을 재사용시에 코드의 중복이 심하며, 3) 파이프라인의 전체 로직을 작은 단위로 자르기가 어려워 테스트가 굉장히 힘들어져요.
PTransform으로 로직 추상화하기
앞서 언급한 문제들 때문에 “어떻게 하면 파이프라인 코드의 재사용성을 높이면서 테스트를 편하게 할 수 있을까?” 같은 유지 보수적 관점에서의 고민이 생겨요. 이를 효과적으로 해결할 방법이 있는데, 여러 개의 PTransform을 묶어서 새로운 PTransform을 만드는 Composite Transform을 활용하면 앞선 문제들을 해결할 수 있어요!
예를 들어서 아래와 같은 파이프라인이 있다고 해볼게요.
output_a = (
input_a
| "TransformA1" >> beam.ParDo(DoFn1())
| "TransformA2" >> beam.ParDo(DoFn2())
)
if condition_a:
output_a | "SomeCondition" >> beam.ParDo(DoFn3())
output_b = (
input_b
| "TransformB1" >> beam.ParDo(DoFn1())
| "TransformB2" >> beam.ParDo(DoFn2())
)
if condition_b:
output_b | "SomeCondition" >> beam.ParDo(DoFn3())
이 파이프라인을 보면 앞서 언급하였던 문제가 전부 존재해요.
TransformA1, TransformA2를 거치면서 데이터의 스키마가 어떻게 변화하는지 추적하기 어렵고,
input_a를 처리하는 로직과 input_b를 처리하는 로직이 동일하여 코드 중복이 심하며,
파이프라인 로직의 단위를 쉽게 파악하기 어렵다는 것이 보이죠?
Composite PTransform으로 파이프라인 로직을 추상화하면 아래와 같이 코드를 작성할 수 있어요.
class SomeTransform(PTransform):
def __init__(self, condition):
self.condition = condition
def expand(self, pcoll):
output = (
pcoll
| "Transform1" >> beam.ParDo(DoFn1())
| "Transform2" >> beam.ParDo(DoFn2())
)
if self.condition:
output = output | "SomeCondition" >> beam.ParDo(DoFn3())
return output
...
output_a = input_a | SomeTransform(condition_a)
output_b = input_b | SomeTransform(condition_b)
파이프라인의 가독성이 훨씬 올라간 게 느껴지시나요?
파이프라인의 모듈화로 output_a와 output_b는 어떠한 SomeTransform과정에 의해서 데이터가 바뀌었는지가 쉽게 보이게 되었어요.
동일 로직이 SomeTransform으로 묶이게 되면서 파이프라인이 모듈화가 가능해졌고, 이는 추후에 해당 PTransform을 테스트하는 코드를 쉽게 작성할 수 있다는 것을 의미해요.
또한, SomeTransform을 거치면서 나오는 데이터의 스키마는 condition 변수에 의해서만 결정되기 때문에, input_a, input_b에서 output_a, output_b로 가는 스키마의 변화 역시 훨씬 추적하기가 쉬워졌어요!
이렇게 만든 PTransform을 사내에 공유한다면 사내 데이터셋을 일정한 형태로 불러온다든지, 공통 로직으로 데이터를 정제 및 샘플링을 한다든지 하는 작업을 누구나 쉽게 사용할 수 있게 되겠죠 😊
파이프라인 성능 최적화하기
가끔 Beam 파이프라인을 작성해서 Dataflow 위에서 돌리다 보면 Progress bar가 빨갛게 변하면서 파이프라인이 Stuck 되었다는 알림을 받아요. 이는 파이프라인 내 특정 Transform에서 병목이 생겼다는 것을 의미해요. 이 병목을 해결하기 위해 어떤 방법들이 있는지 같이 알아볼게요. 💫
Key를 적절하게 설정해서 Parallel Degree 높이기
PCollection의 각 element는 key를 가져요. 이 Key는 보통 GroupByKey나, Combine 등의 Aggregation Operation에도 사용되지만, ParDo에서도 key 기반으로 몇 개의 Bundle로 분산 처리가 될지 Parallel Degree가 결정돼요. 그렇기에 key가 존재할 수 있는 key space가 너무 좁으면 결국 전체 작업량을 쪼개는 것이 어려워져 분산 처리가 효율적으로 이루어지지 않게 된답니다! Random string을 기존 key 옆에 붙이는 등 key space를 키워주면 분산 효율을 쉽게 높일 수 있어요.
Fusion을 막아서 분산 효율 높이기
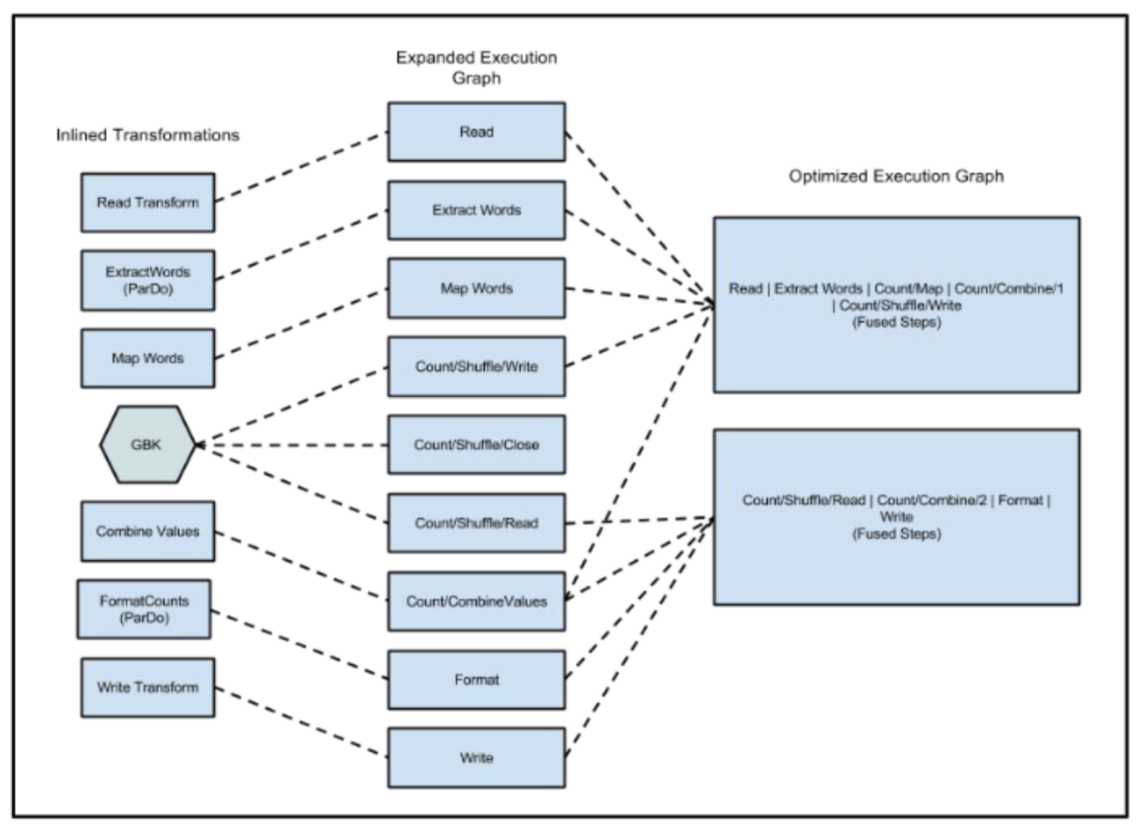
Beam에서 Worker 간에 통신할 때는 데이터를 Serialization 하는 과정이 필요해요. 데이터가 많아지게 되면 Serialization을 하는 과정이 좀 큰 오버헤드가 될 수 있어요! Dataflow 에서는 이를 최적화하기 위해 여러 개의 Transform을 하나로 묶어서 실행하는 Fusion이라는 Graph Optimization을 진행해요. Fusion이 일어나게 된다면 Transform 간에 데이터를 주고받을 때 Worker 간 통신이 불필요하므로 Serialization Cost를 크게 줄일 수 있어요.
하지만, 이러한 Optimization이 오히려 파이프라인의 성능을 느려지게 하는 경우가 있어요! 예를 들어서 A Transform은 High Fanout, 즉 들어오는 인풋은 하나인데 수백 수천 개의 아웃풋을 내놓고, 그 뒤에 B Transform이 실행되는 상황을 생각해 볼게요. Beam이 Optimization을 진행할 때는 A Transform과 B Transform이 정확히 어떤 Input과 Output을 가지는지 Build 때는 모르기 때문에 두 개의 Transform을 하나로 Fusing 하게 되겠죠. 이렇게 되면 A Transform의 Output 들이 적절하게 분산 처리되어서 여러 Worker로 분배가 되어야 하는데, B Transform과의 Fusion이 일어났기 때문에 분산 처리되지 못하고 하나의 Worker에서 모든 처리가 이루어져요.
Dataflow는 Aggregation을 진행하는 Transform이 있으면 해당 Transform 앞뒤로의 Fusion이 일어나지 않아요.
이러한 특징을 이용한다면, 앞서 설명해 드린 문제를 효과적으로 해결할 수 있는데, Beam에서 제공하는 Reshuffle이라는 Transform을 활용하면 데이터는 변화시키지 않으면서 Fusion이 일어나는 것을 방지할 수 있어요!
이외에도…
방금 설명해 드린 것들 말고도 여러 가지 최적화 방법론들이 존재해요!
- 전체 데이터의 크기를 줄이는 Transform은 최대한 파이프라인의 앞에 두면 뒤에 있는 Transform의 불필요한 처리를 줄일 수 있어요.
- Dataflow 에서 너무 많은 Log를 남길 시 Cloud Logging 단의 부하로 인한 오버헤드가 발생하기 때문에 되도록 DoFn을 구현할 때
process()에서는 로깅을 자제해요. - DoFn 안에서 외부 데이터베이스, 또는 서버와 통신하게 된다면 이러한 Op은
process()에서 매번 요청하는 것이 아닌, DoFn의 생애주기를 활용하여start_bundle과finish_bundle과정에서 Batching을 하면 외부와의 통신으로 인한 부하를 줄일 수 있어요.
머신러닝 모델을 데이터 파이프라인에 활용하기
Beam 위에서 ML Inference 하기
핑퐁팀에서는 다양한 목적으로 ML Model을 데이터 파이프라인에서 활용하고 있어요. ML Inference를 Beam 위에서 구현하려면 보통 DoFn 안에서 Model을 부르는 로직을 작성하게 되겠죠. ML Inference를 하는 방법은 크게 두 가지가 있어요. 하나는 외부에 ML Inference 서버를 띄우고 DoFn 안에서 해당 서버를 호출하는 방식이고, 나머지 하나는 직접 Beam Worker에 ML Model을 올려서 로컬에서 바로 Inference를 하는 방법이 있어요. 핑퐁팀은 데이터 파이프라인을 동작시키기 위해 매번 Inference 서버를 띄우는 것은 번거로우므로 ML Model을 직접 메모리에 올리는 후자의 방법을 택했어요!
머신러닝 데이터 파이프라인은 일반적인 데이터 파이프라인과 달리 특별한 점이 하나 있어요. 바로 메모리를 상당히 차지하는 ML Model이 존재한다는 점이죠.
class MLInference(DoFn):
def setup(self):
self.model = SomeModel()
def process(self, element):
yield self.model(element)
위와 같이 Beam 위에서 메모리에 대한 아무런 고려 없이 DoFn 위에서 ML Model을 올린다면 GPU 메모리를 초과했다는 OOM 에러를 자주 맞이할 수 있답니다. 분명히 Beam을 Dataflow 위에서 실행한다면 알아서 Node를 Scaling 해준다고 알고 있었는데, 왜 메모리를 초과하게 될까요? 이는 Dataflow가 Beam Worker를 관리하는 방식 때문에 이러한 문제가 발생해요.

하나의 Beam Worker에서는 특정 DoFn을 실행하기 위해 여러 개의 Process가 생성될 수 있어요. 보통 Worker Process의 개수는 Worker의 vCPU 개수에 따라서 달라져요. 하나의 Process 안에서는 몇백 개의 Thread가 동시에 실행될 수 있어요. 이렇게 해서 Beam은 컴퓨팅 자원을 최대한 Utilize 시키게 된답니다.
다시 본 문제로 돌아와 볼게요. Worker Thread가 수백 개가 생성된다는 것은 DoFn 안에서 Initialize 한 Model의 개수가 수백 개가 될 수 있다는 것을 의미해요. GPU의 메모리는 굉장히 한정적이기 때문에 Model이 수백 개가 뜬다면 아직 아무런 Inference를 하지 않았는데도 메모리가 초과하여 파이프라인을 실행할 수 없어요. 그럼 어떻게 해야 할까요? 모든 Worker Thread가 하나의 모델을 공유할 방법은 없을까요?
Shared Object로 메모리 최적화하기
Apache Beam 버젼 2.24.0 이후부터 Worker Thread들끼리 하나의 Object를 공유할 수 있는 Shared Class를 사용할 수 있어요. 아래 코드를 한번 볼게요.
@dataclass
def WeakRefModel:
model: SomeModel
class MLInferenceShared(DoFn):
def __init__(self, shared_handle):
self.shared_handle = shared_handle
def setup(self):
def initialize_model():
model = SomeModel()
return WeakRefModel(model)
self.model = self.shared_handle.acquire(initialize_model)
def process(self, element):
yield self.model(element)
...
shared_handle = shared.Shared()
data | beam.ParDo(MLInferenceShared(shared_handle))
MLInferenceShared DoFn은 생성자로부터 shared_handle을 받아요.
이 handle은 Beam 파이프라인을 정의할 때 받아요!
(이렇게 하면 하나의 PTransform 에서 사용한 shared object를 다른 PTransform 에서도 활용할 수 있겠죠?)
MLInferenceShared DoFn이 setup되는 시점에는 shared_handle로부터 Model을 acquire 받습니다.
이때 가장 먼저 acquire를 하는 DoFn Thread는 initialize_model() 함수를 통해 ML Model을 받게 되고, 다른 Thread들은 이를 기다립니다.
ML Model 로딩이 완료된 시점에는 하나의 Thread에서 초기화한 ML Model을 다른 Thread들이 공유하여 쓸 수 있게 되는 것이죠!
한 가지 중요한 점은 이렇게 Share한 Model은 각각의 Thread끼리는 공유하게 되지만, Process끼리는 공유하지 못하여 하나의 Worker에서는 Process의 개수만큼 Model이 생성됩니다.
물론 Model의 크기가 그렇게 크지 않다면 CPU의 개수를 적절하게 조절해서 해결하는 방법도 있지만, experiments=no_use_multiple_sdk_containers 옵션을 켠다면 하나의 Worker에는 하나의 Process만 생성되도록 강제할 수 있어요.
Batching으로 GPU Utilize하기
이제 ML Model을 Beam 위에서 올릴 수 있다는 것은 알게 되었어요. 하지만, GPU를 사용하는데도 파이프라인이 생각보다 느리다는 것을 발견할 수 있어요. Beam에서 ParDo가 동작하는 방법을 다시 짚어보면 PCollection 내에서 데이터를 하나씩 꺼내서 처리한다는 것을 알 수 있죠. 이렇게 되면 ML Model로 들어가는 데이터는 한 번에 하나의 데이터밖에 입력되지 못해요. 물론, 데이터 하나하나가 커서 GPU를 잘 Utilize 할 수 있다면 파이프라인의 성능 하락을 크게 체감하지 못할 수도 있지만, 데이터 하나의 크기는 작은데 데이터의 개수가 많은 경우에는 GPU로 한 번에 적은 양의 데이터만 입력되기 때문에 GPU를 100% 활용할 수가 없어요. 이를 위해 Apache Beam에서는 BatchElements 라는 PTransform을 제공해요.
(
data
| beam.BatchElements(min_batch_size=1, max_batch_size=10000)
| beam.ParDo(MLInference())
)
BatchElements에서는 한번에 몇 개의 Element를 Batching할지 Batch Size의 최솟값과 최댓값을 지정할 수 있으며, Beam 파이프라인이 실행되면 Runtime때 최적의 Batch Size를 자동으로 찾아나갑니다!
TFX의 Inference Op 사용
지금까지 ML Inference를 위해 Shared Object를 통한 Thread별로 Model을 공유하도록 하여 메모리를 최적화하였고, BatchElements를 통해 ML Model로 들어오는 Input을 Batching하여 GPU Utilization을 증가시켰어요. 그런데, 이 과정을 한 번에 해주는 Op이 있어요! TFX에서 제공하는 RunInference Transform을 활용하면 앞서 설명해 드린 과정을 직접 구현할 필요 없이 Tensorflow SavedModel만 있으면 바로 불러와서 효율적으로 Inference를 수행할 수 있어요. 이미 생성한 AI Platform Prediction Model Endpoint가 있다면, 해당 Endpoint를 지정해서 Beam에서 바로 활용할 수도 있어요.
tfexample_beam_record = tfx_bsl.public.tfxio.TFExampleRecord(file_pattern=predict_values_five_times_table)
with pipeline as p:
result = (
p
| tfexample_beam_record.RawRecordBeamSource()
| RunInference(
model_spec_pb2.InferenceSpecType(
saved_model_spec=model_spec_pb2.SavedModelSpec(
model_path=save_model_dir_multiply
)
)
)
)
Beam 위에서의 Vector Embedding Search
핑퐁팀에서는 ML Inference로부터 나온 결과물을 바탕으로 데이터 파이프라인 안에서 임베딩 서치를 통한 샘플링을 수행해요. 임베딩 서치를 위한 Framework로는 Faiss를 많이 사용하고 있으며, Apache Beam을 사용하기 이전에도 Faiss를 통해서 많은 작업을 수행하고 있었어요.
Faiss Index를 바탕으로 샘플링을 진행하는 파이프라인을 예로 들어볼게요. ML Model로부터 나온 임베딩들을 입력으로 Faiss Index를 빌드하고, 빌드한 Index를 바탕으로 Embedding Search를 진행하는 과정이 필요하겠죠. Faiss Index를 빌드하기 위해서는 빌드를 위한 임베딩 벡터들이 하나의 Op으로 모여야 하는데, 가장 쉽게 생각할 수 있는 방법은 Aggregation을 통해서 모든 임베딩 벡터를 하나로 모은 뒤, 한 번에 Faiss Index를 빌드하는 방법을 생각해볼 수 있어요. 아래 코드처럼 말이죠.
(
embeddings
| "Aggregate" >> beam.transforms.combiners.ToList()
| "FaissIndexing" >> beam.ParDo(FaissIndexing())
)
하지만 이렇게 파이프라인을 구현하게 된다면 아래와 같은 오류를 맞닥뜨리게 됩니다.

Beam에서 Op끼리 데이터를 주고받는 원리
사실 앞서 언급한 Indexing Pipeline을 구현하기 전에 한가지 크게 간과한 점이 있어요. 공개된 Beam의 코드를 보면 알 수 있듯, Beam은 Worker끼리 gRPC를 통해 데이터를 주고받아요. 즉, 하나의 PTransform 안에서 처리되는 모든 데이터는 protobuf의 형태로 serialization이 일어나요. 이때 생기는 한계점이 있는데, 바로 하나의 Element는 최대 2GB의 데이터만 품을 수 있다는 점이에요. Faiss Indexing을 활용하는 상황은 보통 임베딩 벡터의 크기가 대단히 크기 때문에 임베딩 벡터들을 전부 하나의 Element로 Aggregate하게 된다면 2GB를 넘는 경우가 대다수에요!
Side Input을 잘 활용하기
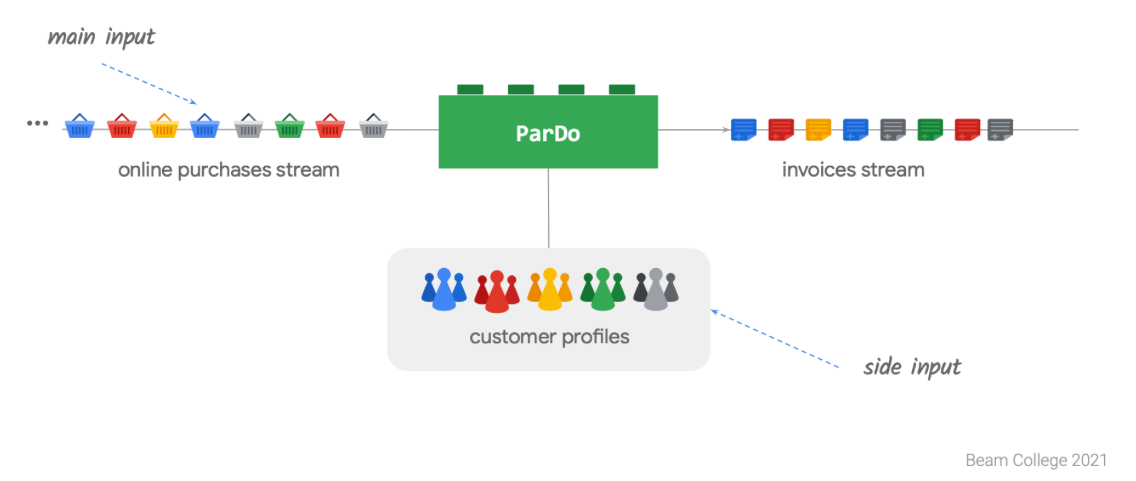
Side Input은 DoFn으로 입력될 수 있는 부수적인 데이터로, 매 Processing 과정마다 DoFn이 항상 접근할 수 있는 데이터에요. Side Input으로 들어올 수 있는 데이터는 어떤 형태든 가능해요. 파이프라인을 만들어줄 때 상수 자체를 집어넣을 수도 있고, 다른 PTransform의 결과로 출력된 PCollection을 넣는 것도 가능해요.
PCollection을 Side Input으로 변환해주기 위해 Beam에서는 pvalue.AsList나, pvalue.AsIterable처럼 PCollection을 Python에서 바로 사용 가능한 형태로 바꾸어주는 Util Function들이 존재해요.
Side Input은 DoFn이 시작되기 전에 Side Input으로 들어오는 PCollection이 준비될 때 까지 기다린 뒤, 완료되었다면 PCollection을 앞선 Util Function들을 활용하여 실제 메모리에 데이터를 올리게 된답니다.
이 Side Input을 활용한다면 전체 임베딩 벡터를 하나의 Element로 Aggregate할 필요 없이, 임베딩 벡터가 담긴 PCollection 자체를 Side Input으로 넣어줄 수 있어요. 이렇게 된다면, Protobuf의 한계로 인한 데이터 용량제한도 존재하지 않으며, Faiss Index가 빌드되기 전에 임베딩 벡터가 담긴 PCollection이 준비될때 까지 기다리기 때문에 한 번에 전체 데이터를 Indexing하는것이 가능해요!
Faiss Indexing 역시 전체 인덱스의 크기가 커지기 때문에 ML Model에서 활용하였던 Shared Class를 동일하게 활용해요. Side Input과 Shared Class를 통해서 아래와 같은 Faiss Indexing Pipeline을 구현할 수 있어요.
class Faiss(beam.DoFn):
def __init__(self, dimension, shared_handle):
self.dimension = dimension
self.shared_handle = shared_handle
def process(self, element, vectors):
import faiss
import numpy as np
def construct_index():
index = faiss.IndexFlatIP(self.dimension)
index.add(np.array(vectors).astype(np.float32))
return index
index = self.shared_handle.acquire(construct_index)
searched = index.search(element, 5)
yield searched
...
shared_handle = shared.Shared()
(
queries
| "FaissIndexing" >> beam.ParDo(
Faiss(dimension, shared_handle),
beam.pvalue.AsList(embeddings)
)
)
마치며
Apache Beam은 일반적인 데이터 파이프라인뿐만이 아니라 ML Model을 Inference 하거나, Vector Search를 하는 등 ML Field에서는 일반적으로 사용되는 방법론들을 그대로 활용할 수 있었어요. 또한, 이 모든 과정을 간단한 Python 코드로 구현할 수 있기 때문에, 기존의 ML Workflow를 이전하기 굉장히 쉽답니다. 이러한 특징 덕분에 핑퐁팀에서는 대부분의 데이터 파이프라인들을 손쉽게 Beam으로 이전할 수 있었고, 엔지니어뿐만 아니라 리서쳐도 활발하게 Beam을 사용하고 있어요! 🔥
MLOps의 여러 복잡한 문제들을 저희와 함께 풀어보고 싶으시다면, 언제든 채용 공고를 참고해주세요! 🚀
참고할 만한 페이지들
- Apache Beam 공식 사이트 - Apache Beam Programming Guide
- Apache Beam Python Docs
- Beam College 2021 Materials
- Google Cloud - Machine learning patterns with Apache Beam and the Dataflow Runner, part I
- Google Cloud - Using TFX inference with Dataflow for large scale ML inference patterns
- TFX RunInference API Documentation