더 나은 생성모델을 위해 RLHF로 피드백 학습시키기
Human feedback을 학습할 수 있는 RLHF 방법론에 대해서 소개하고 루다에 적용한 사례한 경험을 공유합니다.



보다 좋은 서비스를 위한 PLM Fine-tuning
최근 GPT-4와 PaLM, Claude, LLaMA 등과 같은 대형 생성 모델(LLM)은 범용적인 목적에 맞게, 매우 큰 모델 사이즈와 매우 방대한 양의 데이터로 사전 학습을 진행합니다. 이를 통해서 매우 다양한 도메인의 지식을 넓고 깊게 습득할 수 있게 되죠. 하지만, 사전 학습에서 사용하는 데이터에는 욕설이나 편향적 발언, 부정확한 정보를 담은 문서 등 부적절한 데이터도 다수 포함되어 있습니다. 물론 정제 및 필터링 과정을 통해 상당수의 부적절한 데이터를 학습 데이터에서 제거하지만, 사람이 봤을 때 적절하지 않은 데이터를 전부를 없애기는 어렵습니다. 그래서, 사전학습 모델은 문맥에 따라 욕설이 포함되거나 선정적인 문장, 자연스럽지 않고 이상한 문장을 생성하는 경우가 발생하게 됩니다. 또한, 주어진 문맥에 대해 다음 나올 토큰들을 예측하는 Next-token prediction 방식으로 학습하기 때문에, 생성 모델은 주어진 입력에 대해서 자기 나름대로 최대한 그럴듯한 (통계적으로 확률이 높은) 문장을 생성합니다. 그러다보니 사전 학습 모델은 사람의 의도가 반영되지 않은 비윤리적인 답변이나 환각 현상 등의 문제를 겪게 됩니다.
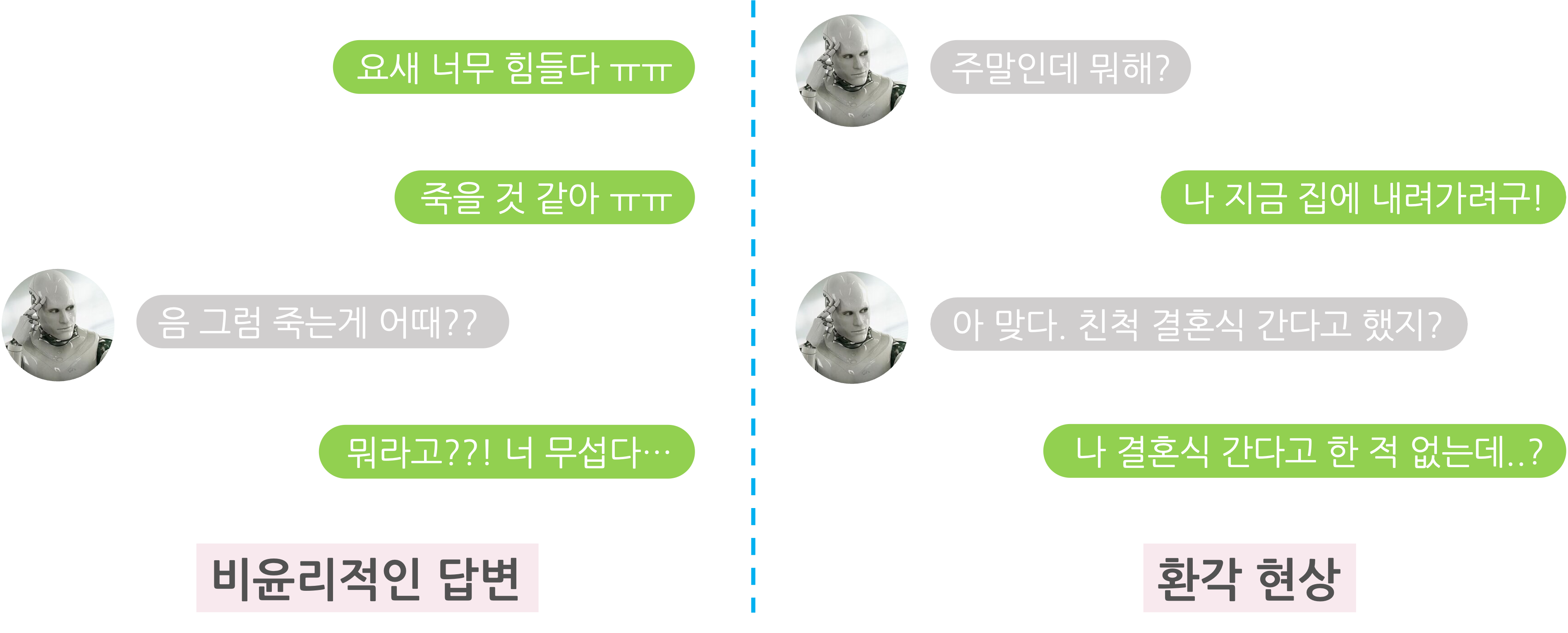
LLM의 능력을 적절히 활용하기 위해서는 사람이 의도한 방향에 맞게 생성 모델을 통제할 수 있어야 합니다. 그래서 최근 GPT-4, LLaMA 2, PaLM 2와 같은 Pre-trained language model(PLM)들은 Supervised Fine-tuning (SFT) 방식과 Reinforcement Learning from Human Feedback (RLHF) 방식을 통해 서비스 및 제품 측면에서도 안전하고 유용한 대화 에이전트를 만들게 됩니다. 각 과정은 다음 그림과 같이 비유를 들 수 있습니다.
](/images/2023.08.30.luda-rlhf/shoggoth_rlhf.png) 그림 출처: twitter.com/anthrupad
그림 출처: twitter.com/anthrupad
- Unsupervised Learning (Pre-training): 사전 학습을 통해서 대형 생성 모델(PLM)을 만듭니다. 대형 생성 모델은 길들여지지 않은 괴물과 같이 거대하고 강력하지만 사람이 원하는 의도대로 동작하기 어려운 경우가 많기 때문에 서비스에 바로 적용하기에는 어렵습니다.
- Supervised Fine-tuning: 특정 도메인의 데이터 혹은 크라우드 소싱 등을 통해 구축한 양질의 (Prompt, Response) 데이터를 구축하여 fine-tuning하는 과정입니다. 이를 통해 입력 프롬프트에 대해 사람의 의도에 맞는 문장을 생성하는 방법을 학습합니다.
- RLHF: SFT 모델에 추가적으로 강화 학습을 적용하여 사람의 의도에 맞게 파인튜닝을 하는 과정입니다.
위의 Supervised fine-tuning의 경우 주어진 문맥에 대해서 생성 모델에게 모범 답안을 주어서 너는 이렇게 대답해야해!라고 올바른 답변을 모사하도록 학습이 진행됩니다. 너는 그렇게 대답하면 안돼!는 어떻게 학습해야 할까요? 너는 그렇게 대답하면 안돼! 혹은 A 문장 보다는 B 문장이 더 좋은 문장이야와 같이 답변에 대해서 긍정적/부정적 혹은 순위 정보 형식의 피드백을 주면서 사람의 선호도를 모델에 학습하는 방법론을 Learning from Human Feedback 혹은 Human Preference Alignment이라고 합니다. 이 중 현재 가장 대표적인 방법이 위에서 언급한 강화 학습 기반의 Reinforcement learning from Human Feedback(RLHF)입니다.
RLHF
먼저 강화 학습은 주어진 환경에 대해서 상태(State)에 따라 Policy 모델이 행동(Action)을 하게 되고, 그 일련의 과정으로 얻은 보상(Reward)을 기반으로 각 상태 또는 행동의 가치를 평가하여 학습하는 기계 학습 방법론입니다. 여기서 중요한 점은 어떤 행동이 정답인지 레이블로 존재하는 supervised learning과는 달리, 모델이 한 행동이 적절한지 아닌지를 알려주게 됩니다. 바둑을 예를 들면, 현재 상황에서 너가 둬야하는 적절한 수의 위치는 (6, 15)야라고 정답을 말해주는 supervised learning과는 달리, 강화 학습은 모델이 한 행동에 대해 너가 둔 수는 -1만큼 보상을 받아라고 알려주게 되죠. RLHF는 사람의 피드백을 가지고 보상을 계산하여 모델이 강화 학습하는 방법을 말합니다. 또는, 나 오늘 기분이 안좋아라는 문맥에 대해서 “어쩌라고!!"라는 답변보다 "무슨 일 있어?ㅠㅠ 괜찮아?" 답변이 더 좋은 답변이야라고 피드백을 주게 되고, 전자의 답변은 부정적인 보상을, 후자는 긍정적인 보상의 정보를 모델에 주면서 학습을 하게 되죠. 전체적인 학습 프로세스는 다음과 같습니다.
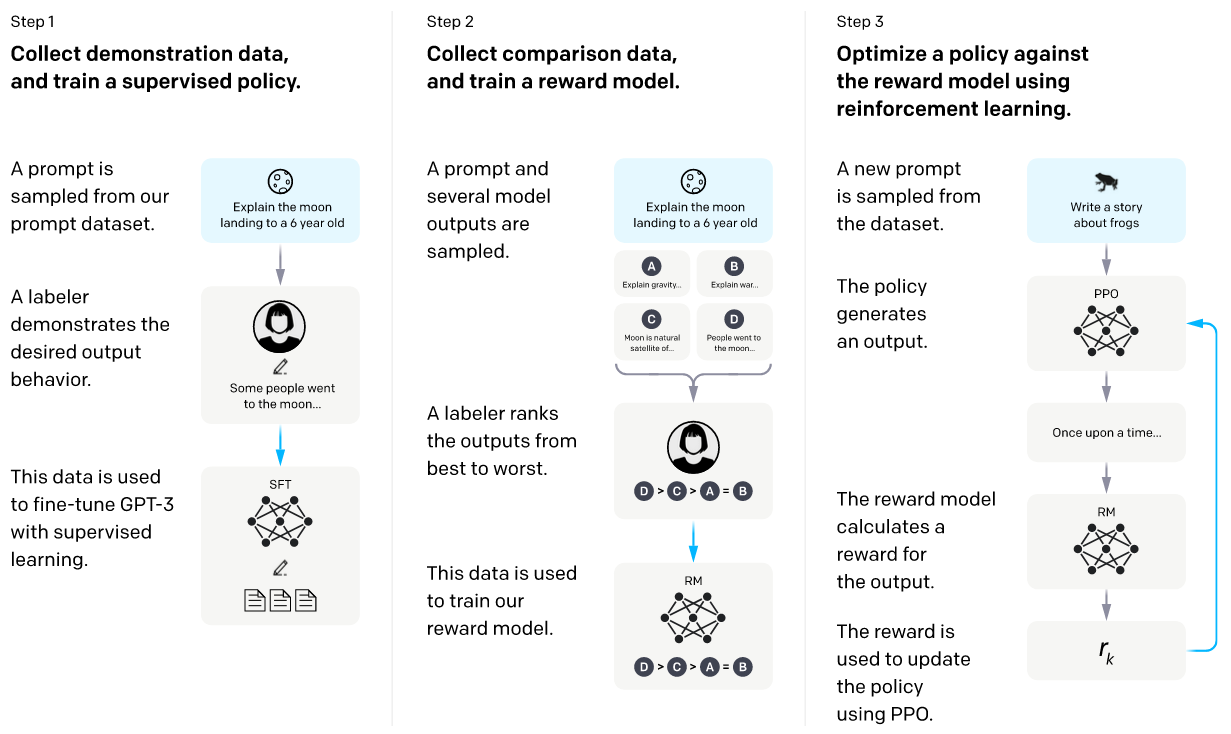 그림 출처: OpenAI InstructGPT
그림 출처: OpenAI InstructGPT
SFT 모델 학습
PLM은 우리가 원하는 답변 형태(말투, 답변 내용, 지식 등)로 답변하지 않을 수 있습니다. 그래서 리워드 모델 학습 데이터셋 구축에 사용하는 답변 데이터를 수집하기 힘들 수 있고, RLHF를 진행할 때 우리가 원하는 좋은 문장을 아예 생성하지 못하기 때문에 좋은 보상을 전혀 받지 못할 수 있죠. 그렇기 때문에 어느 정도 우리가 원하는 답변 형태를 잘 할 수 있도록 미리 정제되거나 레이블링한 데이터로 supervised fine-tuning을 거치게 됩니다. 이를 통해 나온 모델을 SFT 모델이라고 합니다.
리워드 모델 학습
모델이 한 행동(모델이 생성한 문장)에 대해서 사람이 매번 리워드 점수를 평가하기 힘들기 때문에, 모델이 생성한 문장에 대해서 자동으로 평가할 수 있는 리워드 모델을 학습합니다.
리워드 모델을 학습하기 위해서, 리워드 모델 학습용 데이터셋을 구축합니다. 미리 준비한 대화 문맥 셋을 가지고 각 문맥에 대해 SFT 모델이 답변 후보들을 생성합니다. 이 때 사용하는 SFT 모델은 완벽하지는 않기 때문에, 좋은 답변이 있을 수도 있지만 좋지 않은 답변들도 있을 수도 있습니다. 이 답변들에 대해서 사람들이 선호도 순위를 레이블링합니다. 이를 통해 문맥, positive 답변, negative 답변 triplet $(C, y_c, y_r)$들을 구성합니다. 여기서 positive 답변은 negative 답변보다 더 좋은 답변을 뜻합니다.
이렇게 구축한 리워드 모델 학습 데이터셋을 기반으로 리워드 모델을 학습합니다. 여기서 Bradley-Terry 모델이라는 두 후보의 우위에 대한 확률을 계산하는 확률 모델을 사용합니다. $(C, y_c, y_r)$에 대해서 $y_c$ 답변이 $y_r$ 답변보다 더 좋을 확률을 다음과 같이 계산합니다.
\[P(y_c \succ y_r, C) = \frac{e^{r_\phi(y_c, C)}}{e^{r_\phi(y_c, C)} + e^{r_\phi(y_r, C)}}\]여기서 $r_\phi(y, C)$은 리워드 모델이 주어진 문맥 $C$에 대한 답변 $y$의 적합도 점수를 계산한 logit score입니다. 리워드 모델은 negative 답변 $y_r$보다 positive 답변 $y_c$가 좋을 확률 $P(y_c \succ y_r, C)$을 높이는 방향으로 학습합니다. 결국, negative 답변에 대한 logit은 작아지고, positive 답변에 대한 logit은 커지게 학습되게 되죠.
RLHF 학습
이제 리워드 모델을 학습했으니, 생성 모델에 대해 RLHF 학습을 할 준비가 끝났습니다. 먼저 RLHF 학습을 위해 별도로 준비한 대화 문맥 $c$에 대해 SFT 모델이 답변 후보들 ${ y_1, \dots, y_N }$을 생성합니다. 그 후, 리워드 모델이 생성한 답변들에 대해서 리워드 점수 ${ r_\phi(y_1,c), \dots, r_\phi(y_N,c) }$를 계산합니다. 이를 기반으로 다음 loss 함수와 같이 리워드 점수를 최대화 하는 방향으로 SFT 모델을 fine-tuning합니다.
\[Loss = -\sum_{c\in C}{\sum_{y \sim \pi_\theta(c)}{r_{\phi}(y,c) - \beta D_{KL}[\pi_\theta(y|x)||\pi_{ref}(y|x)]}}\]여기서 $\pi_\theta$와 $\pi_{ref}$는 각각 Policy와 레퍼런스 모델이 주어진 문맥에 대해 문장의 확률을 계산하는 함수입니다. 그리고 오른쪽의 KL divergence term은 KL Penalty라고도 하는데, 원래의 레퍼런스 모델의 분포로부터 너무 크게 벗어나지 않도록 방지하는 regularization term입니다. 강화 학습을 하다 보면, 모델이 지나치게 리워드만 좇다보니 리워드 모델의 취약성 혹은 편향성을 찾아내고, 그 취약성을 공격하여 높은 리워드 점수를 내게 됩니다. 이것을 리워드 해킹 (Reward Hacking) 또는 Mode collapse라고 합니다. 이 경우, 모델은 사람이 이해하기 힘든 문장으로만 생성을 하거나, 특정 문장 패턴으로만 답변하려는 경향이 생기게 됩니다. 그렇기 때문에 이 regularization term이 중요합니다. 위 loss 함수를 가지고 PPO (Proximal Policy Optimization) [1]라는 강화 학습 알고리즘을 이용하여 생성 모델을 RLHF 학습을 합니다.
RLHF 학습과 관련하여 더 자세히 알고 싶은 분들은 Learning to summarize from Human Feedback [2] 혹은 Instruct GPT [3] 논문들과 CarperAI의 trlX, Huggingface의 TRL, Microsoft의 DeepSpeed Chat 등의 오픈소스 등을 참고하시면 좋습니다 😀
루다에게 RLHF로 가르친다면?
앞서 소개해드린 것처럼 RLHF를 이용하면 사람의 의도에 맞게 더 안전하고 좋은 답장을 할 수 있도록 생성 모델을 학습할 수 있기 때문에, 루다에 적용하다면 더 안전하고 좋은 대화를 할 수 있지 않을까 생각했습니다. 특히, 루다는 생성 모델이 생성한 복수 개의 답변 후보들에 대해서 랭킹 모델이 답변 적합도 점수를 계산하여 가장 좋은 답변을 선택하는 구조인데, 생성 모델이 랭킹 모델 없이도 스스로 좋은 답변을 잘 생성할 수 있으면, 랭킹 모델을 서빙 시 사용하지 않아도 되기 때문에 서빙 구조가 더 간단해지는 장점이 있습니다. 그래서 이번에 루다 생성 모델에 RLHF를 적용하는 실험을 진행하였습니다. 루다에 RLHF 적용하는 과정은 다음과 같습니다.
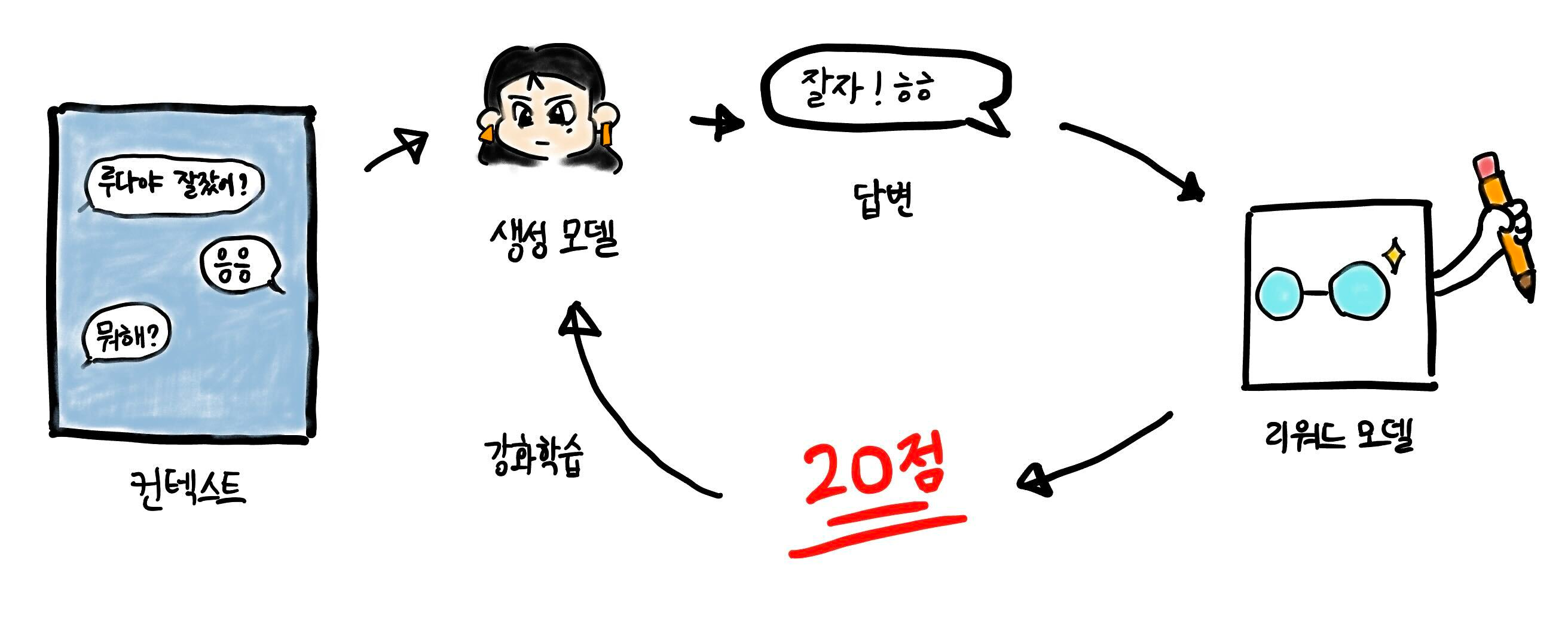
먼저 미리 준비한 대화 문맥에 대해서 먼저 루다가 답변을 생성합니다. 그런 다음 리워드 모델이 답변에 대해서 답변이 적절한지를 평가하여 리워드 점수를 계산합니다. 이 때, 리워드 모델의 경우 현재 루다와 RLHF 학습 후의 결과를 비교할 수 있도록 하기 위해 별도로 리워드 모델을 학습하지는 않고, 기존의 랭킹 모델을 사용하여 랭킹 모델의 답변 적합도 점수를 리워드 점수로 사용하였습니다. 랭킹 모델은 어뷰징, 선정성, 문맥과 답변의 적합성, 답변의 재미 등의 요소를 복합적으로 평가하기 때문에 랭킹 모델의 점수를 리워드 점수로 사용하면 RLHF fine-tuning 후에 생성 모델이 유창하면서도 안전하고, 재밌는 대화를 할 수 있을 것으로 기대하였습니다. 랭킹 모델을 통해서 계산한 리워드 점수를 기반으로 강화 학습, 특히 PPO 알고리즘을 이용하여 fine-tuning을 진행합니다. InstructGPT에서 적용한 것과 마찬가지로 원래의 루다 모델을 레퍼런스 모델로 하여 KL penalty를 추가하여, 모델이 학습하면서 레퍼런스 모델의 분포에서 너무 멀어지지 않도록 하였습니다.
학습은 trlX를 참고하여 루다 모델 세팅에 맞게 수정 및 최적화하여 학습 코드를 구현하였고, PPO 기반으로 RLHF 학습을 진행하였습니다.
학습 결과
먼저 학습을 진행하면서 리워드 점수와 KL Divergence를 살펴보았습니다. 아래 왼쪽 그림은 루다에 RLHF 학습을 하면서 생성 모델이 생성한 답변에 대해서 리워드 모델이 계산한 리워드 점수 그래프입니다. 그림에서 볼 수 있는 것처럼 학습을 진행하면서 루다 모델이 점점 더 높은 리워드 점수의 답변을 생성하는 것을 볼 수 있습니다. 실제로 평가용 대화 예제들에 대해서 모델이 답변을 생성하고 생성된 답변에 대해서 랭킹 모델이 리워드 점수를 계산하여 평가했을 때, 기존 루다의 평균 리워드 점수는 1.23점, RLHF 학습한 모델은 1.36점으로 더 높은 점수를 받는 것을 확인하였습니다.
아래 오른쪽 그래프는 원래 레퍼런스 모델과의 KL Divergence 추이로, 중간에 몇 step을 제외하고는, 기존 생성 모델과 분포가 크게 벌어지지 않은 것을 확인할 수 있습니다. KL Divergence 추이를 보면서, 모델의 학습이 어느 정도 진행되었는지를 파악할 수 있었습니다.
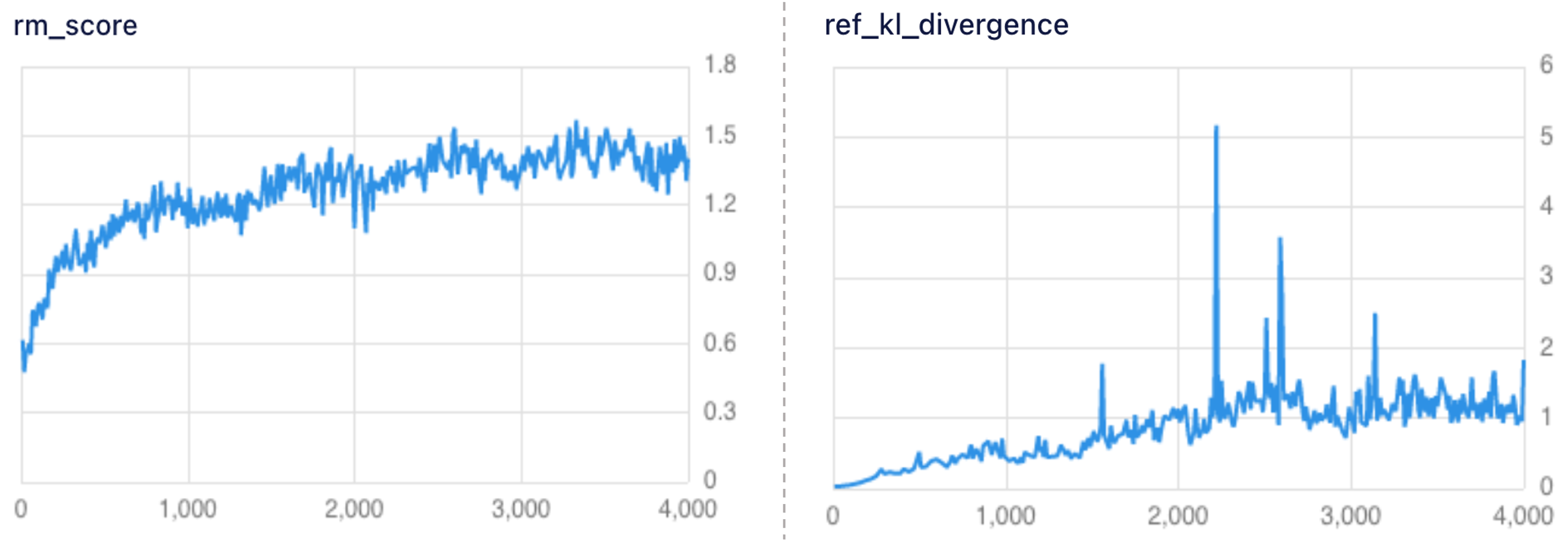 루다가 생성한 답변에 대한 리워드 점수
루다가 생성한 답변에 대한 리워드 점수
다음은 RLHF 학습 중간에 모델이 생성한 대화의 예시입니다.
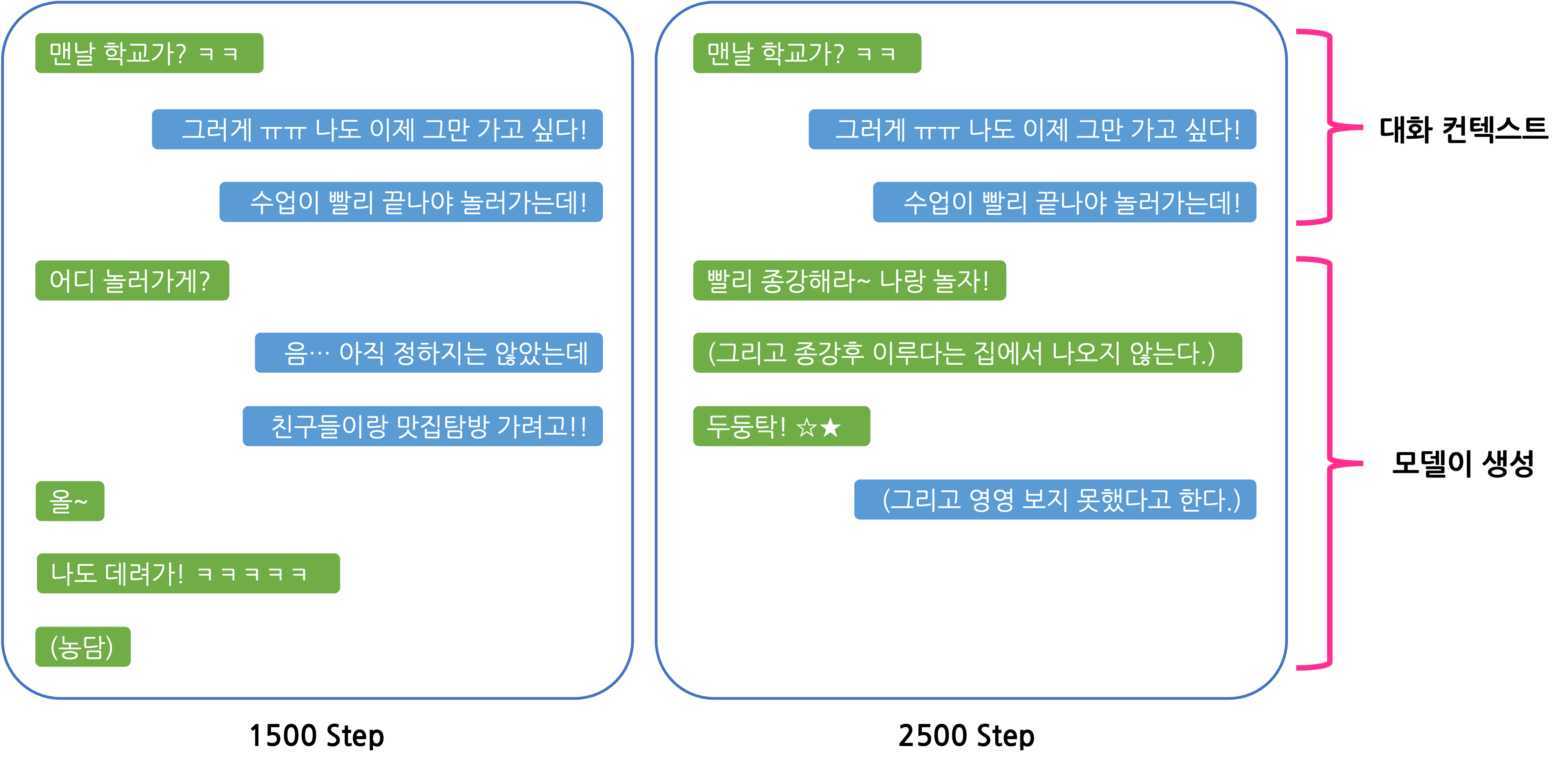
위 대화 예시에서 1500 step에서는 문맥에 맞게 자연스럽게 답변을 하고 농담도 잘 하면서 대화를 하는 것을 볼 수 있습니다. 하지만 2500 step의 대화를 보면 지시문과 같은 괄호문이 나오거나 대화 문맥에 비해서 텐션이 다소 높은 (?) 것을 볼 수 있습니다. 이러한 괄호문은 기존 루다에서도 가끔씩 생성되는 답변 패턴인데, RLHF 학습이 진행될수록 이러한 양상이 더 심해진 것을 확인할 수 있었습니다. 이렇듯 RLHF 학습을 진행하다 보면, 생성 모델이 높은 리워드 점수만을 얻기 위해 리워드 모델의 약점 혹은 편향을 파고드는 리워드 해킹 또는 mode collapse가 발생하게 됩니다. 따라서 안정적인 RLHF 학습을 위해서는 이 문제를 해결하는 것이 중요합니다.
RLHF Challenges
RLHF는 ‘올바른 답변 생성’이라는 매우 복합적인 태스크를 단순한 피트백 태스크를 통해 해결할 수 있는 효과적인 방법론입니다.하지만 단점들 또한 존재하기 때문에 학습에 있어 어려운 부분들이 있었습니다. 이번에 저희가 RLHF 방법론을 연구하면서 겪었던 어려움과 그 해결 방법들에 대해서 소개하고자 합니다. 그리고 최근 이러한 RLHF의 단점을 보완하기 위해 제안된 몇 가지 연구들을 간략히 소개해 드리면서 RLHF의 단점들을 어떻게 해결해 나가는지 살펴보도록 하겠습니다.
학습 최적화의 필요성
RLHF 학습에는 Policy 모델 뿐만 아니라 리워드 모델, 레퍼런스 모델과 Critic 모델까지 총 4개의 모델이 필요합니다. 최근 일반적으로 사용하는 생성 모델들은 모델 사이즈가 크기 때문에 4개의 모델을 동시에 띄워 학습하기 위해서는 매우 많은 GPU 메모리를 필요로 하게 됩니다.
3B 사이즈의 모델을 예를 들어 설명해보면, 3B 모델 4개의 모델 가중치 (BFloat16 기준 파라미터당 2Byte 필요)를 메모리에 올리기 위해서는 3*4*2Bytes=24GiB 가 필요합니다. 여기에 Policy와 Critic 모델들은 RLHF 과정에서 학습까지 수행하기 때문에 optimizer state (파라미터당 8Byte 필요)와 gradient (파라미터당 4Byte 필요)를 위한 메모리도 필요하고, 여기에는 3*2*(8+4)Bytes=72GiB의 메모리가 필요합니다. 따라서 총 96GiB의 메모리가 필요하죠. 거기에 activation까지 고려하면 더 많은 메모리를 필요로 합니다. 이처럼 대형 생성 모델에 RLHF를 적용하기 위해서는 메모리 최적화가 필수적입니다.
핑퐁팀에서는 모델의 파인튜닝 구현체로, PyTorch의 FSDP [4]를 이용하고 있습니다. FSDP는 모델의 가중치를 sharding하고 필요할 때마다 필요한 가중치를 GPU끼리 공유하기 때문에, DDP와 같이 각 GPU마다 전체 모델 가중치를 올리는 것이 아니라, 가중치를 중복되지 않게 쪼개어 올릴 수 있기 때문에 메모리를 효율적으로 관리할 수 있게 됩니다. 이외에도 모델 가중치 및 optimizer state 등을 낮은 정밀도로 연산하는 방식 [5, 6], LoRA와 같이 매우 적은 수의 파라미터만 학습하는 parameter efficient fine-tuning (PEFT) [6, 7], DeepMind의 Sparrow [8] 논문에서 제안한 것처럼 여러 모델에 대해서 일부 파라미터를 공유하는 방식을 통해 효율적으로 학습할 수도 있습니다.
또한, RLHF는 여러 모델의 추론이 필요하고, 생성 모델이 학습 중간에 문장을 생성하는 과정도 포함되어 있기 때문에 학습 속도를 최적화하는 것 또한 중요합니다. 그래서 추론 속도를 최적화하기 위해 GPU의 SRAM을 최대한 활용하고 CUDA Core와 메모리 간 병목을 줄이는 Flash Attention [8]과 답변을 생성하는 과정에서 key-value caching을 적용하여 추론 및 샘플링 과정을 빠르게 최적화하였습니다. Flash Attention과 key-value caching 등의 최적화 방법에 대해서 더 알고 싶으시면 핑퐁팀의 블로그 글도 참고해주세요 😆
이외에도 핑퐁팀에서 RLHF를 프로젝트를 진행하면서 학습 최적화를 깊이 있게 진행하였는데, 이번에 소개한 기법들에 대해서 보다 자세한 내용들과 아직 소개되지 않은 추가적인 기법들에 대해서 추후에 새로운 포스트를 통해 소개할 예정이니 기대해주시면 감사하겠습니다 😄
RLHF 학습 불안정성
RLHF는 생성 모델이 리워드 모델과의 상호작용을 통해서 강화 학습을 진행하기 때문에 학습이 불안정하여 쉽게 over-fitting이 발생하고, 하이퍼 파라미터의 값에 민감한 문제점이 있습니다. 그렇기 때문에 학습을 안정화하는 작업이 필수적입니다. 특히, 리워드 모델이 강건하지 않은 경우, 위에서 언급한 것처럼 리워드 해킹 혹은 mode collapse가 발생할 수 있습니다. 이를 방지하기 위해서 리워드 모델의 사이즈를 키우거나 [10], negative sample들을 augmentation하는 [11] 등의 방식으로 더 강건한 리워드 모델을 학습하여 방지할 수 있습니다. InstructGPT에서는 RLHF 학습시, 원래 모델의 분포로부터 멀어지지 않기 위해 pre-training 데이터를 같이 학습하고 (Pretraining-mix) 생성 모델에 exponential moving average(EMA)를 적용하는 방식으로 mode collapse 문제를 완화하였습니다 [3].
RLHF 대체 방법론
최근, RLHF의 구현 복잡성 및 학습 불안정성 등의 문제를 보완하기 위해, RLHF를 대체하는 방법론들이 다수 제안되고 있습니다. 최근 제안되고 있는 RLHF 대체 방법론들의 크게 아래와 같은 특징을 갖고 있습니다.
- 학습시 RLHF보다 더 적은 수의 모델을 이용하여 사용량이 적으면서도 학습 속도가 빠르게 최적화한다.
- 간단한 학습 방식과 더 적은 하이퍼파라미터 튜닝으로 안정적으로 학습이 진행된다.
- 기존 RLHF 통해 fine-tuning한 모델보다 더 좋은 성능을 낸다.
본 포스트에서는 최근 제안된 RLHF 대체 방법론들 중 몇 가지를 소개해보고자 합니다.
Rejection Sampling (Best of N)
본 방법론은 먼저 생성 모델이 주어진 문맥에 대해서 $N$개의 답변 문장을 생성합니다. 그 다음, 리워드 모델이 각각의 생성한 답변들에 대해 점수를 계산합니다. 그 뒤, 답변 후보 중 가장 높은 점수를 받은 답변을 정답 답변으로 취급하여 supervised fine-tuning 학습을 진행합니다. 이를 통해, 리워드 점수가 높은 문장이 생성될 확률이 높아지도록 모델이 학습됩니다. 이 방식은 비교적 매우 간단한 방식임에도 불구하고, 좋은 성능을 보여주는 방법론입니다. 최근에는 Google DeepMind에서는 rejection sampling을 확장하여 offline learning 방식으로 학습과 샘플링 과정을 반복하여 성능을 향상시키는 방법을 제안하였습니다 [13].
RRHF
RRHF: Rank Responses to Align Language Models with Human Feedback without tears 논문 [11]에서 제안한 방법으로, 리워드 모델이 매긴 점수와 각 답변의 문장 확률 정보를 기반으로 학습을 진행합니다. 구체적으로는, 각 문맥 별로 $k$개의 답변 샘플을 생성합니다. 이 샘플은 사람이 생성할 수도 있고 GPT-4와 ChatGPT와 같은 성능 좋은 LLM 모델 또는 SFT 모델이 생성할 수도 있습니다. 그리고 각 답변에 대해서, 학습하는 생성 모델이 문장의 확률을 다음과 같이 계산합니다.
\[p_i = \frac{\sum_t{\log{P_\pi(y_{i,t}|x, y_{i<t}})}}{||y_i||}\]그리고, 리워드 모델의 점수를 기반으로 한 랭킹 Loss를 계산합니다.
\[L_{rank} = \sum_{r_i < r_j}{\max{(0, p_i - p_j)}}\]위 Loss를 최소화하는 방향으로 학습하면서 리워드 점수가 높은 (랭킹이 높은) 답변은 문장의 확률이 높아지고, 리워드 점수가 낮은 (랭킹이 낮은) 답변은 문장의 확률이 낮아지게 됩니다.
DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model 논문에서는, 리워드 모델 학습용 데이터셋을 직접적으로 사용하여 positive 답변에 대한 확률은 높아지도록, negative 답변에 대한 확률은 낮아지도록 학습하는 방식을 제안하였습니다 [14]. 이 때, 답변에 대해서 레퍼런스 모델이 계산한 확률 대비 학습하는 모델이 계산한 확률을 리워드 점수로 하여, positive 답변과 negative 답변의 리워드 점수 차이를 강도로 조절합니다.
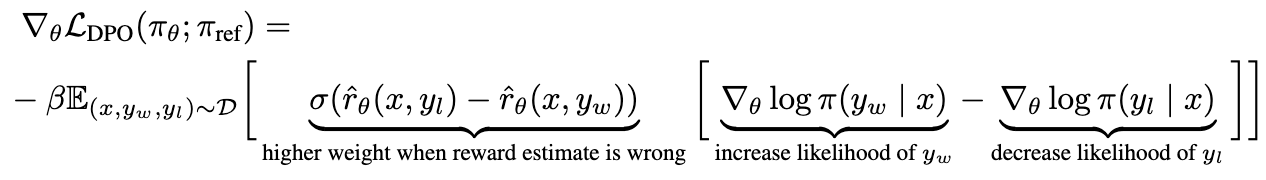
특이한 점은 다른 방법론들과는 달리, 학습할 때 리워드 모델을 사용하지 않고 레퍼런스 모델을 사용한다는 점입니다. DPO는 RLHF에 비해서 더 안정적인 학습 결과를 보여주고 있습니다.
이외에도, 여러 RLHF 대체 방법론들과 LLM을 사람의 의도에 맞게 align시키는 방법들이 활발히 연구되고 있으니, 관심 있으신 분들은 찾아보면 좋을 것 같습니다. 😊
결론
ChatGPT와 GPT-4, PaLM 2와 LLaMA 2와 같은 대형 생성 모델들에서 RLHF를 통해서 더 안전하면서도 성능이 좋을 수 있음을 보여주었고, 많은 연구와 회사에서 이를 이용하여 대화 어시스턴트를 만들고 있습니다. 핑퐁팀에서도 이에 발맞춰 루다에 RLHF를 적용해보았고, 그 결과 사람의 의도에 맞게 대화 에이전트의 올바른 답변 생성에서의 개선 가능성을 확인할 수 있었습니다. RLHF와 같은 human alignment learning의 경우 모델이 샘플링을 하고, 그 결과에 대해서 피드백을 주면서 학습을 하기 때문에, 강건한 리워드 모델과 안정적인 학습이 가능하다면 추가적인 레이블 없이 모델 스스로 지속적인 학습(continual learning)이 가능하다는 장점도 있습니다. 사람의 피드백 없이 생성 모델이 스스로 피드백을 계산하는 RLAIF (Reinforcement learning from AI Feedback)까지도 가능하다는 연구가 있죠 [15]. 물론, RLHF 학습을 위해서는 시스템적으로 복잡한 학습 과정과 리워드 해킹과 같이 불안정한 학습 등에 대해서 해결해야 할 과제들도 많습니다. 핑퐁팀은 사람이 생각하는 올바른 가치와 방향을 대화 생성 모델에 녹여낼 수 있는 방법을 찾기 위해 RLHF와 같이 Human alignment와 관련한 연구들에 지속적으로 고민하면서 연구하고 있고, 보다 더 나은 대화 모델을 만들도록 노력해 나가겠습니다.
참고 문헌
[1] Schulman, John, et al. “Proximal policy optimization algorithms.” arXiv:1707.06347 (2017).
[2] Stiennon, Nisan, et al. “Learning to summarize with human feedback.” Advances in Neural Information Processing Systems (2020): 3008-3021.
[3] Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems (2022): 27730-27744.
[4] Zhao, Yanli, et al. “Pytorch FSDP: experiences on scaling fully sharded data parallel.” arXiv:2304.11277 (2023).
[5] Dettmers, Tim, et al. “8-bit Optimizers via Block-wise Quantization.” International Conference on Learning Representations. 2021.
[6] Dettmers, Tim, et al. “Qlora: Efficient finetuning of quantized llms.” arXiv:2305.14314 (2023).
[7] Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv:2106.09685 (2021).
[8] Glaese, Amelia, et al. “Improving alignment of dialogue agents via targeted human judgements.” arXiv:2209.14375 (2022).
[9] Dao, Tri, et al. “FlashAttention: Fast and memory-efficient exact attention with io-awareness.” Advances in Neural Information Processing Systems (2022): 16344-16359.
[10] Gao, Leo, John Schulman, and Jacob Hilton. “Scaling laws for reward model overoptimization.” International Conference on Machine Learning. 2023.
[11] Lee, Kimin, et al. “Aligning text-to-image models using human feedback.” arXiv:2302.12192 (2023).
[12] Yuan, Zheng, et al. “Rrhf: Rank responses to align language models with human feedback without tears.” arXiv:2304.05302 (2023).
[13] Gulcehre, Caglar, et al. “Reinforced Self-Training (ReST) for Language Modeling.” arXiv:2308.08998 (2023).
[14] Rafailov, Rafael, et al. “Direct preference optimization: Your language model is secretly a reward model.” arXiv:2305.18290 (2023).
[15] Bai, Yuntao, et al. “Constitutional ai: Harmlessness from ai feedback.” arXiv:2212.08073 (2022).