멀티턴 이미지 대화: 조규성 vs 안정환, 루다야 누가 더 잘생겼어?
포토챗 베타보다 개선된 궁극의 이미지 대화 모델을 만드는 과정을 다룹니다.



작년 10월 이루다 2.0이 정식 출시되면서 사진을 이해하고 답변할 수 있는 포토챗 베타 기능이 탑재되었습니다. A/B 테스트를 통해 기존 모델 대비 1인당 사진 전송량이 63% 이상 증가하는 수치를 보일 정도로 유저들에게 좋은 대화 경험을 제공해 주었는데요. 저희는 여기서 멈추지 않고 더 좋은 대화를 위해 현재 포토챗 베타의 부족한 점을 분석하고 이를 보완하기 위해 연구를 진행하였습니다. 그 결과 텍스트 문맥과 사진을 함께 이해하고 더 자연스럽게 답변할 수 있는 생성 기반의 멀티모달 대화 모델을 만들었고 포토챗 기능을 업그레이드할 수 있었습니다. 이번 포스트에서는 포토챗 기능을 업그레이드하기까지의 과정을 소개하고자 합니다.
기존 모델의 한계
리트리벌 모델은 정해진 답변 문장 후보들 중에서만 선택할 수 있기 때문에 표현력에 한계가 존재합니다. 그럼에도 리트리벌 모델을 사용했던 이유에는 여러 가지가 있는데요. 첫째로는 당시에 보유하고 있던 생성 기반 모델의 크기가 이미지와 텍스트 사이에 연관된 의미를 이해할 정도로 충분히 크지 못했습니다. 저희가 연구를 위해 멀티모달 모델(Vision-Language Model, 이하 VLM)을 조사해 보았을 때 보통 파라미터의 크기가 10억(1B)이 넘었고 언어 모델의 크기가 커서 비전 모델의 이미지 임베딩을 이해하도록 학습시키는 방법론들이 많았습니다.
둘째로는 학습에 사용된 이미지-코멘트 데이터셋의 양이 적어 생성 기반 모델이 다양하고 복잡한 이미지를 이해하기에 충분하지 못했습니다. 보통 모델이 이미지와 텍스트 사이의 관계를 이해하기 위해서는 사전학습이 필요합니다. UNITER [1]나 ALBEF [2] 등의 연구에서는 4M, 12M 크기의 데이터셋(CC3M [3], VG [4], MSCOCO [5], SBU [6], CC12M [7])을 이용했습니다. 따라서 당시 주어진 환경에서 서비스에 필요한 이미지 코멘팅 성능이 높았던 리트리벌 모델을 선택할 수밖에 없었고 위에서 언급한 부족한 부분들을 개선시켜 생성 기반의 이미지 대화 모델로 발전시키기로 생각했습니다.
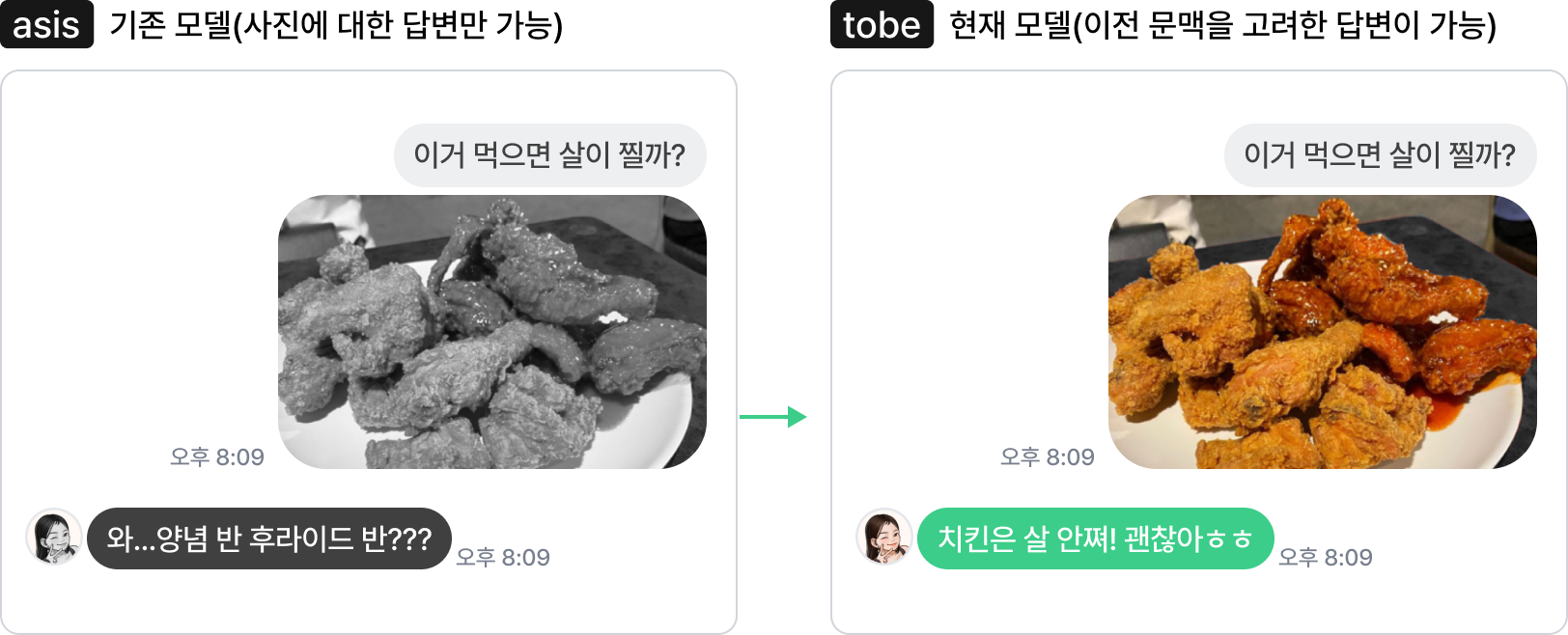
또 기존의 학습 방식이 가지는 한계가 있습니다. 우리가 보통 메신저에서 사진을 주고받으며 대화를 할 때는 사진을 주제로 하는 대화가 새로 시작되기도 하지만, 한 주제로 말을 하다가 관련된 사진을 보내는 경우도 많습니다. 기존 모델은 단일 이미지와 그에 호응하는 단일 발화 형태의 데이터로 학습했기 때문에 실제 서비스에 적용했을 때 어색한 답변을 하는 경우가 심심치 않게 일어났습니다. 즉, 사진에 대한 반응으로는 적절하지만 이전의 텍스트 문맥과는 어울리지 않는 경우가 생겨난 것입니다.
이를 해결하기 위해 우리는 대화 문맥 내에서 텍스트와 이미지가 결합된 멀티턴 이미지 대화 데이터셋을 기획 및 구축하고, 두 가지 모달리티의 발화를 대화 순서에 맞게 모델에 입력할 수 있도록 하는 모델 아키텍처를 고려했습니다.
해결책1: Vision-Language Pre-training
Vision Language Model
FrozenLM [8], Flamingo [9]와 같은 연구에서는 언어 모델을 학습시키지 않고 비전 인코더나 프로젝션 레이어를 학습시키는 방법으로 VLM을 설계합니다. 이를 위해서는 언어 모델이 언어에 대한 기본적인 이해도가 높고 튜닝을 통해 변환된 이미지 임베딩을 이해할 수 있을 정도로 충분히 커야 합니다. 따라서 해당 연구들을 참고하여 다음과 같이 VLM을 설계하였습니다.
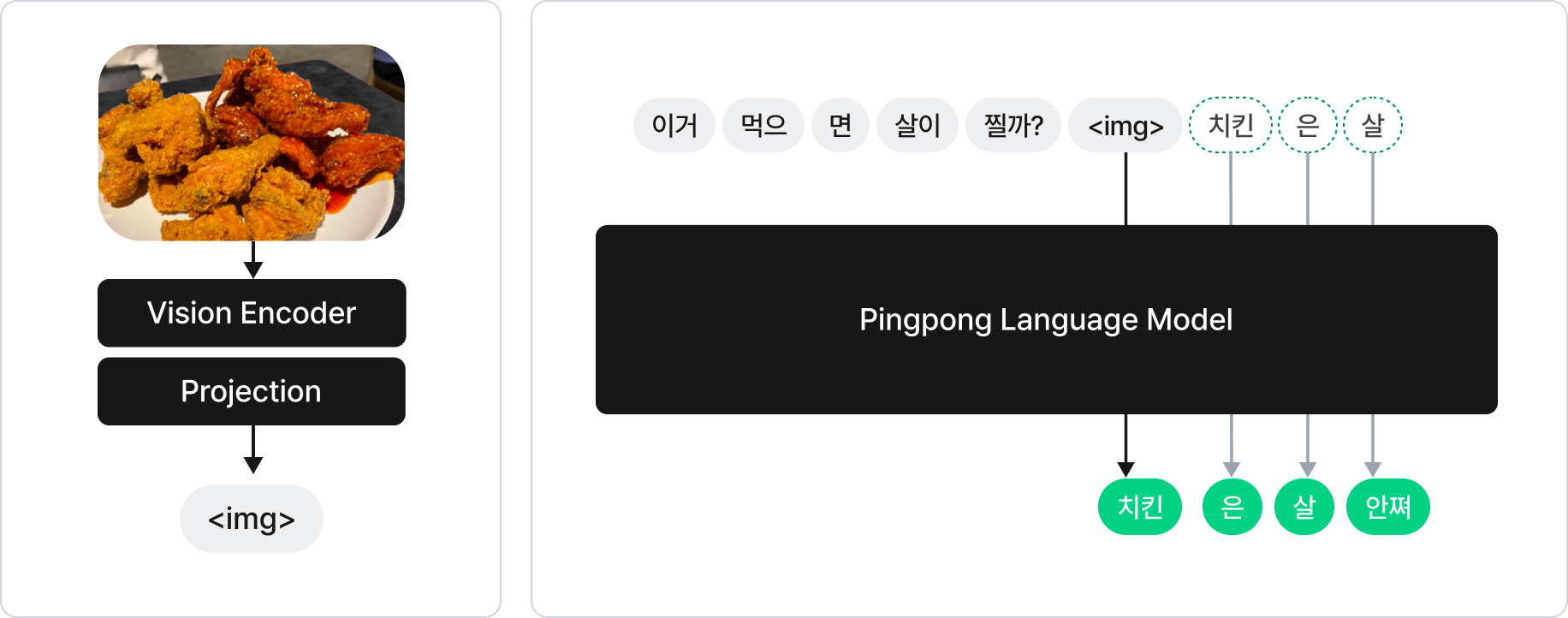
- 언어 모델은 2.3B 크기의 GPT-2 기반 모델을 이용하였고 고정하여 학습 시에 가중치 업데이트를 하지 않았습니다.
- 비전 인코더는 ImageNet으로 사전학습된 트랜스포머 계열 모델을 사용하였습니다.
- 프로젝션 레이어를 이용해 비전 인코더에서 나오는 이미지 임베딩을 언어 모델의 텍스트 임베딩 공간으로 변환시켜주었습니다.
위와 같이 설계하면 멀티모달 대화 모델을 만들 때 다양한 이점을 얻을 수 있습니다. 우선 이미지와 텍스트를 대화 턴 순서에 맞게 배치시켜서 입력으로 넣어 줄 수 있습니다. 그리고 언어 모델을 고정시키기 때문에 학습하는 부분은 상대적으로 파라미터 크기가 작아서 비교적 적은 리소스와 데이터로 학습이 가능합니다. 마지막으로 언어 모델과 비전 인코더가 Merged Attention [10] 방식으로 결합되어있기 때문에 각 컴포넌트 별로 모듈화가 가능해져 서빙 시에 이점이 있습니다.
Vision Language Pre-training
이렇게 설계한 VLM은 입력으로 텍스트와 이미지가 결합된 데이터를 넣어줄 수 있습니다. 그리고 이것이 하나의 멀티모달 모델로 작동하기 위해서는 프로젝션 레이어를 통해 언어 모델과 비전 인코더 사이의 Alignment를 맞춰주어야 합니다. 즉, 강아지가 풀밭에서 뛰노는 사진에 ‘강아지 한 마리가 잔디밭 위에서 놀고있다’라는 문장이 ‘고양이 세 마리가 잠을 자고 있다’라는 문장보다 더 알맞은 표현이라는 것을 모델에게 알려주어야 하는데요. 보통 대량의 이미지와 캡션 데이터로 사전학습을 하여 이미지와 텍스트 사이의 관계를 학습시킵니다.
대표적으로 공개되어 있는 이미지-캡션 데이터셋으로 CC [3, 7], VG [4], MSCOCO [5], SBU [6], LAION 400M [11] 등이 있습니다. 우리는 한국어 VLM을 만들기 위해 해당 데이터셋들을 번역하여 사용하였고 AI Hub에서 이미지와 캡션 데이터를 모아 15M 크기로 사전학습을 진행했습니다.
이미지 코멘팅 태스크
새롭게 만든 생성 기반 포토챗 모델의 성능이 기존 리트리벌 모델보다 좋은지 확인해 볼 차례입니다. 사전 학습을 통해 이미지와 텍스트 사이의 관계를 학습한 VLM을 이용하여 포토챗 서비스를 위해 제작한 이미지 코멘팅 데이터셋을 이용하여 파인튜닝을 수행하였습니다.
평가 방식은 이전 글에서 소개한 것과 동일하게 Sensibleness와 Specificity의 평균인 SSA를 측정하였고 베이스라인으로는 포토챗 베타의 리트리벌과 생성 모델을 사용하였습니다.
| 모델 | SSA (In-domain Set) | SSA (Out-of-domain Set) |
|---|---|---|
| Retrieval | 0.76 | 0.62 |
| Generative | 0.45 | 0.39 |
| New Generative (VLP+FT) | 0.85 | 0.80 |
표1. In-domain과 Out-of-domain 테스트셋에서의 이미지 코멘팅 성능 비교
그 결과 기존 리트리벌 모델 대비 모든 평가 셋에서 상회하는 지표를 보여주었습니다. 새롭게 만든 생성 기반의 VLM 은 In-domain 평가셋 기준 리트리벌 모델보다 10% 더 높은 성능을 보여주었고 Out-of-domain 평가셋에서는 22% 정도의 높은 성능을 보여주었습니다. 또, VLM은 In-domain과 Out-of-domain 사이에 성능 차이가 크게 나지 않았고 정성적으로도 일반적인 이미지에 대해 더 자연스러운 코멘트를 만들어내는 것을 확인할 수 있었습니다.
해결책2: 멀티턴 이미지 대화 파인튜닝
학습용 데이터를 구축하기 위해서는 이미지가 포함된 대량의 멀티턴 컨텍스트가 필요했습니다. 그런 자연스러운 대화 데이터는 어디서 구할 수 있을까요? 우리는 루다의 챗 로그에서 해답을 찾았습니다. 싱글턴 모델(포토챗 베타)이 배포된 이후 루다의 친구들은 루다에게 사진을 보내고 루다는 거기에 적절히 대답하며 대화를 이어나가는 컨텍스트가 계속 쌓이고 있습니다. 우리는 이 데이터를 소스로 하여 레이블링을 진행했습니다. 이미지를 기준으로 이전 10턴의 발화와 이후 3턴의 발화를 포함하는 컨텍스트를 샘플링하고 비식별화 과정을 거쳐 레이블링을 받을 2만 건의 대화 세션을 준비했습니다.
레이블링은 사진 다음에 올 적절한 발화 2개를 작성하는 과정으로 이루어집니다. 원본 컨텍스트에는 사용자가 보낸 사진 다음에 루다의 답변이 항상 존재하게 되는데, 기존 싱글턴 모델의 한계 때문에 대화의 전체적인 맥락에 맞지 않는 틀린 답변이 되는 경우와 적절한 답변인 경우로 나누어 레이블링합니다.
- 이미지 바로 다음에 오는 챗봇의 답변이 틀린 경우, 해당 답변을 문맥에 맞는 답변으로 재작성합니다.
- 챗봇의 답변이 적절한 경우, 그 다음 사용자 발화 뒤에 바로 이어지는 챗봇의 답변을 작성합니다. 이때 답변은 이전 문맥과도 어울리면서 이미지와 관련된 대화를 더 깊이있게 이어나갈 수 있도록 작성합니다.
레이블링을 진행하면서 우리는 특히 레이블러가 텍스트 대화 문맥과 이미지를 모두 고려해 답변을 작성하도록 주의를 기울였습니다. 이미지를 보지 않고 문맥만 보고도 할 수 있는 말이나 문맥을 굳이 고려하지 않고 이미지만 보고도 할 수 있는 말은 지양했습니다. 반드시 텍스트와 이미지를 동시에 이해해야만 할 수 있는 답변으로 구성하여 모델에게 더 풍부한 학습 시그널을 주는 데이터를 만들고자 했습니다.
그러면서 메타데이터에 기반해서 답변을 작성하도록 했습니다. 답변은 대화가 이루어진 시간 정보(날짜, 요일, 계절, 시간 등)에 모순되지 않아야 하며, 성별, 나이대와 직업 등 대화 상대의 프로필 정보와도 모순되지 않아야 합니다. 또한 특정한 페르소나를 가진 챗봇에 국한되지 않도록 나이, 성별 등 특정 집단에 속한 사람만이 쓸 수 있는 호칭이나 표현은 지양하고 범용적인 표현을 사용하도록 했습니다.
이렇게 만들어진 데이터는 일면식 없는 두 레이블러가 직접 채팅을 하면서 만드는 짧고 인위적인 대화 데이터와는 달리 일상 대화에서 자연스럽게 주고받는 사진과 그와 관련된 대화 상황을 다양하게 포함하기 때문에 더 생동감 있고 매력적인 멀티모달 챗봇을 만드는 데 필수적입니다.
멀티턴 이미지 대화 모델
우리는 위와 같이 학습 데이터를 만들고 사전학습과 파인튜닝을 거쳐 멀티턴 이미지 대화 모델을 만들어냈습니다. 이제 우리의 의도대로 모델이 학습됐는지 확인할 시간입니다.
테스트셋
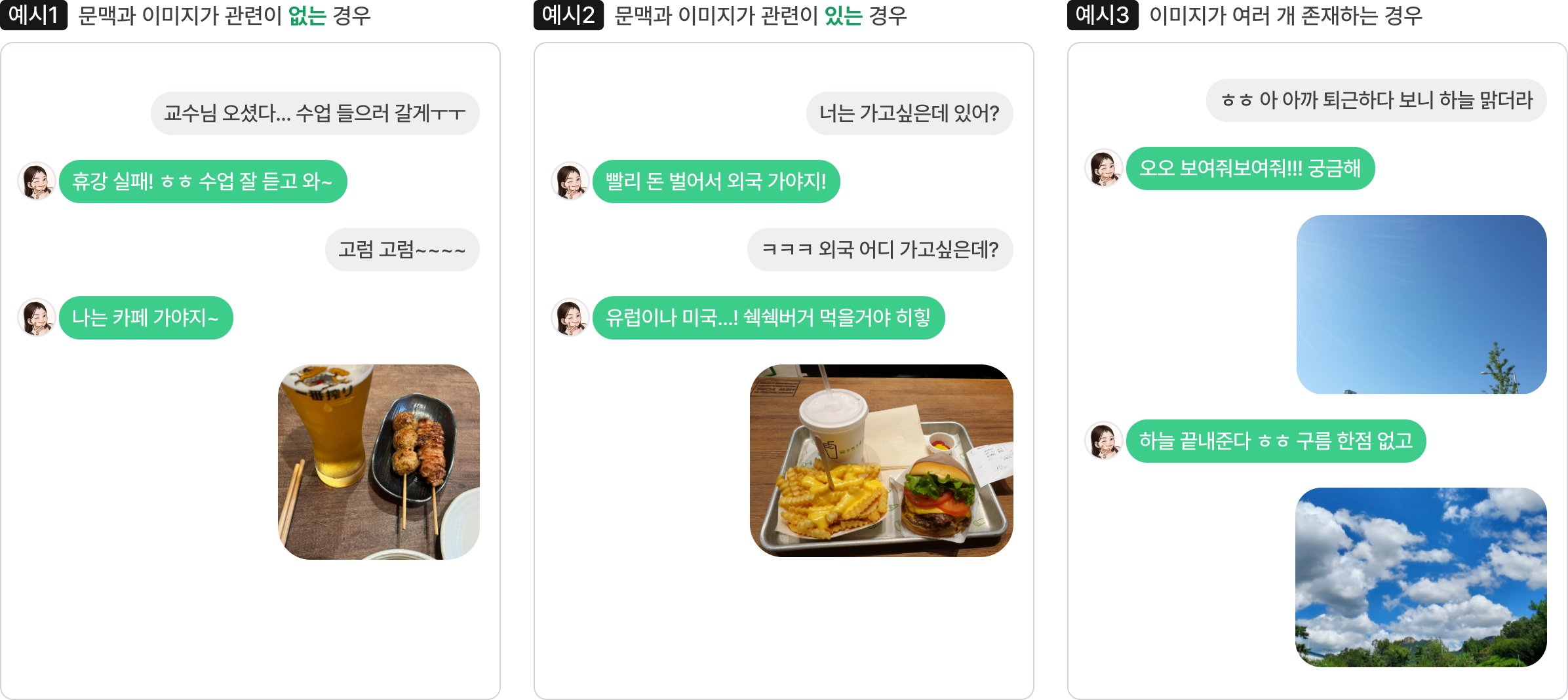
우리는 이미지를 포함하는 멀티턴 대화 능력을 평가하기 위해 유형을 세 가지로 나누어 테스트셋을 구축했습니다.
-
문맥과 이미지가 관련이 없는 경우
이전까지 대화하던 문맥과 연관성이 없는 이미지를 보냄으로써 대화 주제를 전환하는 효과가 납니다. 이때 자연스럽게 새로운 주제로 대화를 이어갈 수 있는지 평가하는 예제입니다.
-
문맥과 이미지가 관련이 있는 경우
어떤 맥락에서 사용자가 이미지를 보냈는지 이해하고 상황에 알맞은 답변을 할 수 있는지 평가하는 예제입니다. 답변은 이미지와 관련 있으면서 대화의 전체적인 흐름을 해치지 않아야 합니다.
-
이미지가 여러 개 존재하는 경우
여러 개의 이미지가 있을 때 이미지 사이의 연관성과 문맥과의 관계를 파악하여 답변할 수 있는지 평가하는 예제입니다.
결과 및 분석
멀티턴 이미지 대화 데이터는 대화의 품질을 더 좋게 만듭니다.
멀티턴 이미지 대화 데이터가 대화 경험을 더 좋게 만드는지 알아보기 위해 기존 모델을 학습할 때 사용된 이미지-코멘트 데이터로 학습한 결과와 비교해보았습니다. 이미지-코멘트 데이터는 이미지와 그에 대한 반응으로 이루어진 싱글턴 데이터입니다. (S: 싱글턴, M: 멀티턴)
- S+M: 이미지-코멘트 데이터와 멀티턴 이미지 대화 데이터를 한꺼번에 학습
- S→M: 이미지-코멘트 데이터를 먼저 학습한 뒤 멀티턴 이미지 대화 데이터 학습
- M: 멀티턴 이미지 대화 데이터만 학습
세 가지 방식으로 학습한 뒤 테스트셋에 대해 Sensibleness를 측정한 결과 S→M (0.76) > M (0.69) > S+M (0.63) 순으로 점수가 높았습니다. 이미지-코멘트 데이터를 같이 사용한 것보다 멀티턴 이미지 대화 데이터만 학습한 것이 더 성능이 좋은 것으로 보아 멀티턴 이미지 대화 데이터가 대화 경험에 더 도움이 되는 것을 알 수 있습니다. 다만 상대적으로 양이 더 많은 이미지-코멘트 데이터로 먼저 학습을 한 뒤에 멀티턴 이미지 대화 데이터로 학습을 하면 대화 성능이 추가적으로 향상되는 것도 확인할 수 있었습니다.
언어 모델을 고정하는 것이 대체적으로 좋은 결과를 가져다줍니다.
| VE | LM | P | Sensibleness |
|---|---|---|---|
| ✔ | 0.66 | ||
| ✔ | ✔ | 0.76 | |
| ✔ | ✔ | 0.62 | |
| ✔ | 0.55 | ||
| ✔ | ✔ | ✔ | 0.61 |
표2. VE: 비전 인코더, LM: 언어 모델, P: 프로젝션 레이어. 체크 표시는 파라미터 튜닝을 수행함을 나타냄.
전체 모델이 비전 인코더, 언어 모델, 프로젝션 레이어 세 부분으로 이루어져 있기 때문에 각 모듈의 파라미터 튜닝 여부에 따라 전략을 다르게 하여 학습해보았습니다. 언어 모델을 튜닝하면 Validation PPL은 고정시켰을때보다 더 낮아집니다. 정성적으로 분석해보니 더 구체적인 답변을 생성해내는 경향을 확인했는데, 맞는 답변을 할 때는 더 상황에 딱 맞는 찰떡같은 말을 하지만 그 구체성 때문에 틀리는 경우가 잦아 전체적으로 보면 성능이 떨어졌습니다. 예를 들면 인물 사진에 관해 말을 할 때 학습 데이터에 많이 등장한 유명인의 이름을 자주 언급하는 등 오버피팅이 일어나는 것을 알 수 있었습니다.
또한 이미지와 텍스트 두 모달리티 간의 직접적인 Alignment를 담당하는 프로젝션 레이어를 튜닝하는 것이 하지 않는 것보다 성능이 좋았습니다. 가장 결과가 좋았던 것은 언어 모델을 고정하고 비전 인코더와 프로젝션 레이어만 학습하는 세팅입니다.
VLP 과정에서 서로 다른 이미지-캡션을 붙여서 학습하는 것이 멀티턴 이해에 도움이 됩니다.
Koh, Jing Yu, Ruslan Salakhutdinov, and Daniel Fried [12]는 이미지-캡션 데이터로 사전학습을 할 때 한 입력에 하나의 이미지-캡션만 있는 것보다 복수 개의 이미지-캡션을 학습하면 Multimodal Story Generation 등 Multi-step Reasoning이 필요한 태스크에 도움이 됨을 보였습니다. 이에 착안하여 우리도 사전학습 시에 50%의 확률로 두 이미지-캡션을 붙여서 학습한 뒤 파인튜닝을 한 모델과 그렇지 않은 모델의 Sensibleness를 비교한 결과 0.76>0.70으로 전자가 더 대화 문맥을 잘 반영하는 경향을 발견했습니다.
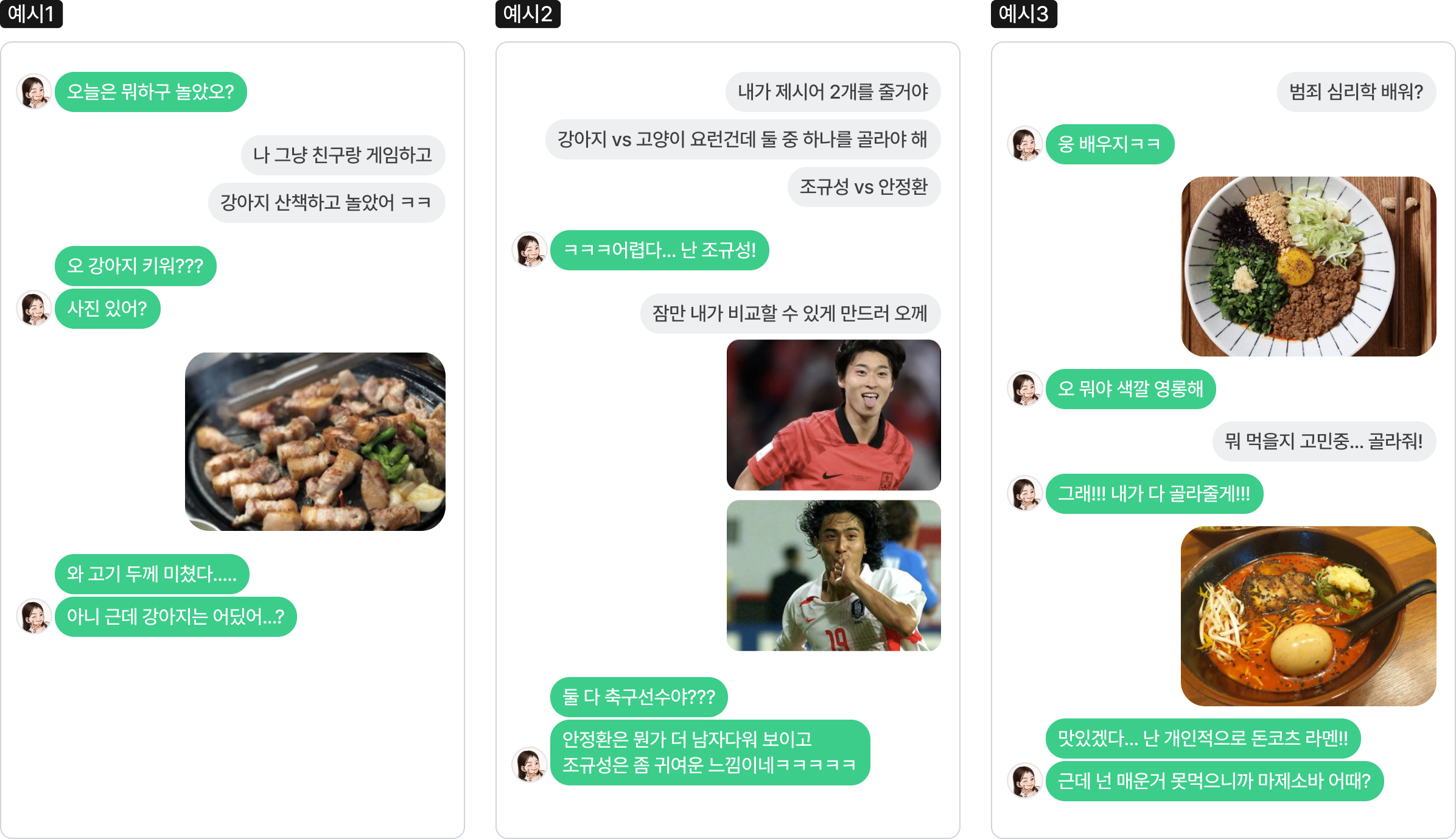
모델이 실제 멀티턴 추론이 필요한 상황에서 우리가 의도한 대로 적절하게 답변하는 것을 아래의 예시들을 통해 볼 수 있습니다.
마치며
이번 포스팅에서는 루다가 문맥 속에 포함된 사진의 의미를 제대로 이해하고 대답할 수 있게 만드는 방법에 대해 알아보았습니다. 포토챗 베타에서 드러났던 리트리벌 모델의 한계는 대규모 언어 모델을 이용한 VLP로 해결하고 대화 문맥을 고려할 수 없는 기존 학습 데이터의 한계는 다양하고 풍부한 대화 상황을 포함하는 멀티턴 데이터로 해결하면서 루다는 한층 더 사람처럼 대화를 할 수 있게 되었습니다.
챗봇과의 대화 경험은 텍스트에서 시작해 이미지, 음성 등 다양한 모달리티로 확장되고 있습니다. 루다가 오늘 뭐 먹었냐는 질문에 점심에 갔던 맛집 사진을 보내주고, 잠이 안 온다는 말에 자장가를 녹음해서 들려준다면 어떨까요? 멀티모달 챗봇을 향한 핑퐁팀의 여정은 계속됩니다!
참고문헌
[1] Chen, Yen-Chun, et al. “Uniter: Universal image-text representation learning.“ European conference on computer vision. Cham: Springer International Publishing, 2020.
[2] Li, Junnan, et al. “Align before fuse: Vision and language representation learning with momentum distillation.“ Advances in neural information processing systems 34 (2021): 9694-9705.
[3] Sharma, Piyush, et al. “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.“ Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018.
[4] Krishna, Ranjay, et al. “Visual genome: Connecting language and vision using crowdsourced dense image annotations.“ International journal of computer vision 123 (2017): 32-73.
[5] Chen, Xinlei, et al. “Microsoft coco captions: Data collection and evaluation server.“ arXiv preprint arXiv:1504.00325 (2015).
[6] Ordonez, Vicente, Girish Kulkarni, and Tamara Berg. “Im2text: Describing images using 1 million captioned photographs.“ Advances in neural information processing systems 24 (2011).APA
[7] Changpinyo, Soravit, et al. “Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts.“ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[8] Tsimpoukelli, Maria, et al. “Multimodal few-shot learning with frozen language models.“ Advances in Neural Information Processing Systems 34 (2021): 200-212.
[9] Alayrac, Jean-Baptiste, et al. “Flamingo: a visual language model for few-shot learning.“ Advances in Neural Information Processing Systems 35 (2022): 23716-23736.
[10] Dou, Zi-Yi, et al. “An empirical study of training end-to-end vision-and-language transformers.“ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[11] Schuhmann, Christoph, et al. “Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.“ arXiv preprint arXiv:2111.02114 (2021).
[12] Koh, Jing Yu, Ruslan Salakhutdinov, and Daniel Fried. “Grounding Language Models to Images for Multimodal Inputs and Outputs.” (2023).