Apache Beam으로 머신러닝 데이터 파이프라인 구축하기 3편 - RunInference로 모델 추론하기
Apache Beam Native API, RunInference로 대규모 데이터 모델 추론하기

Apache Beam으로 머신러닝 데이터 파이프라인 구축하기를 주제로 하는 3번째 글로 다시 찾아뵙게 되었어요. 1편: 도입과 사용에서는 Apache Beam이 무엇이고, 핑퐁팀이 왜 Beam을 사용하게 되었는지 설명해 드렸습니다. 2편: 개발 및 최적화에서는 머신러닝 파이프라인을 효율적으로 개발하고 유지보수하기 위해 어떤 점들을 고려해야 하는지 알아보았습니다. 이번 블로그 3편: RunInference로 모델 추론하기에서는 Dataflow 환경 위에서 대규모 데이터셋의 ML Model Bulk Inference를 어떻게 수행하는지에 초점을 맞추어 보려 해요. 이번 글은 1편과 2편을 먼저 본 다음 이어서 보시는 것을 추천드려요! 👩🏫
Why ML Model on Apache Beam?
학습된 머신러닝 모델을 활용하는 방법은 정말 여러 가지가 있어요. 저희 핑퐁팀이 만드는 이루다와 같이 사용자의 요청이 들어올 때마다 머신러닝 모델을 추론하는 Live Inference를 수행하는 경우도 있고, 주기적으로 대량의 데이터셋을 불러와서 머신을 띄우고 모델을 추론하는 Bulk Inference를 수행하는 경우도 있어요. 보통 이러한 작업을 수행하기 전 “어떻게 하면 데이터의 양에 따라 Scalable 하게 리소스를 할당할 수 있을까?”와 같은 고민을 하게 되죠. Live Inference의 경우에는 ML Model을 Inference 하는 서버를 GPU Util 또는 요청량에 따라 자동으로 Scaling시키는 방법을 생각해볼 수 있어요. (Kubernetes 위에서 요청량에 따라서 Scaling 하는 자세한 방법은 저희가 이전에 다른 블로그 글로 소개드린 바 있습니다!)
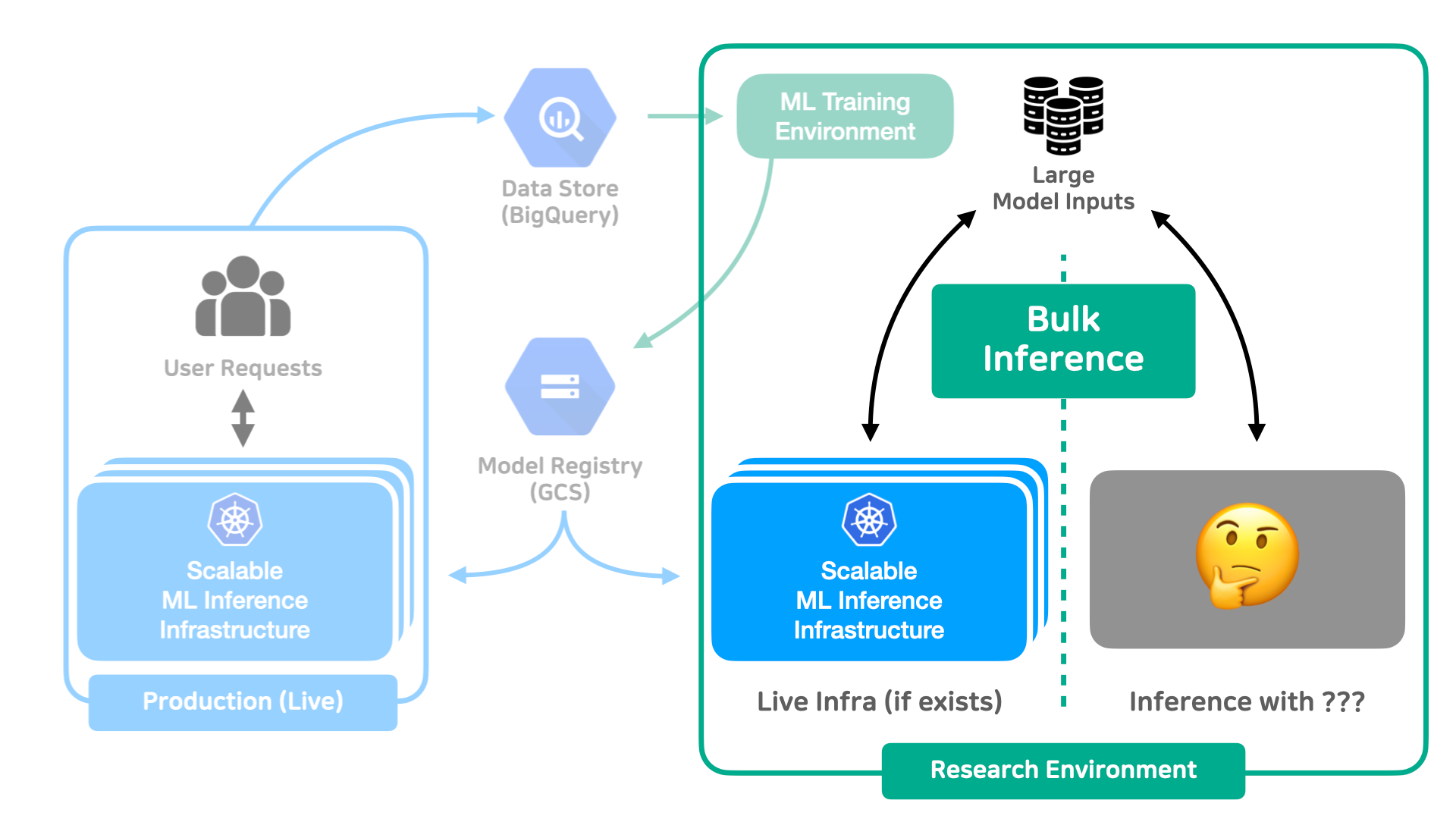
Bulk Inference의 경우에는 Live Inference 상황보다 Latency에 대한 제약이 비교적 적기 때문에, 더욱 다양한 방법을 생각해볼 수 있어요. 만약, Bulk Inference에서 활용할 모델이 Live Inference 때 사용했던 모델과 동일하다면 Live Inference에서 사용했던 인프라를 활용해서 Bulk Inference에 활용하는 방법을 생각할 수 있을 것 같아요. 가령 Live 환경의 모델 인프라를 그대로 복제해서 Airflow와 같은 Tool을 통해 주기적으로 모델 인프라의 서버에 모델 추론 요청을 보내도록 파이프라인을 구축할 수도 있죠. 하지만, 현재 조직 내에서 Live Inference를 수행하고 있지 않거나 Live 환경의 모델 인프라와는 전혀 다른 모델을 통해 추론하고 싶다면, 매번 파이프라인을 작성할 때마다 새로 인프라를 구축하는 일은 매우 번거로울 것이에요.
그러면 어떻게 하면 Bulk Inference 상황에서 데이터의 양에 따라 처리를 위한 머신을 자동으로 Scaling 해주고, 개발자는 Inference를 위한 코드에만 집중하도록 만들 수 있을까요? Apache Beam은 분산 데이터 스토리지와 파이프라인의 로직을 추상화하여 파이프라인을 개발하는 사람은 데이터 처리에 필요한 비즈니스 로직에만 집중하고, 그러면서도 GCP Dataflow 서비스를 활용해서 손쉽게 대규모 데이터에 대한 분산처리를 수행할 수 있었어요. 이 Beam을 ML Model Inference에 활용한다면 방금 던졌던 질문을 효과적으로 해결할 수 있을 것 같지 않나요?
Recap) Beam 위에서 ML Inference 하기

저희 블로그 2편의 머신러닝 모델을 데이터 파이프라인에 활용하기 절 에서 ML Model을 Apache Beam에서 활용하는 방법을 소개해 드린 바 있어요. 혹시라도 아직 이전 편을 안 보신 분들을 위해 간략하게 요약해보자면,
- Apache Beam에서는 데이터 처리를 위한 코드를 DoFn이라는 형태를 통해 구현을 진행하며, ML Inference 작업 역시 Inference를 수행하는 코드를 DoFn으로 구현할 수 있었어요.
- 하지만, Apache Beam에서는 하나의 Worker Node에서 특정 DoFn을 실행하기 위해 여러 개의 Process와 Thread가 생성될 수 있었는데, GPU 자원은 머신당 한정적이기 때문에 OOM(Out-of-Memory) 에러를 쉽게 볼 수 있었어요. Apache Beam 2.24.0에 구현된 Shared Class를 활용하면 Worker Thread들끼리 하나의 Object를 공유할 수 있었어요! 물론, 이렇게 하더라도 Thread들끼리만 공유하기 때문에 Process가 여러 개 뜨면 OOM이 똑같이 발생하므로,
experiments=no_use_multiple_sdk_containers옵션으로 Worker당 한 개의 Process만 뜨도록 강제해야 했어요. - ML Model은 연산 특성상 여러 개의 Element를 한 번에 처리해야 GPU Utilization을 훨씬 높일 수 있기 때문에, Batching이 필요하죠. Beam에 구현된
BatchElementsPTransform을 활용한다면, Minimum Batch Size와 Maximum Batch Size를 지정하는 것만으로 PCollection 내 여러 Item들을 효율적으로 Batching할 수 있었어요. - 지난 편에서는 설명을 안 드렸지만, GCP Dataflow를 활용한다면 Resource Hint를 통해 원하는 GPU의 Type과 개수를 쉽게 할당받을 수 있었어요! 가령 NVIDIA T4 GPU가 1개 필요하면
type:nvidia-tesla-t4;count:1;install-nvidia-driver와 같은 Option을 줄 수 있어요. (install-nvidia-driverOption을 사용하면 Dataflow가 동작하는 Node에 GPU Driver를 자동으로 설치해줘요!)
코드를 통해 보는게 더 이해가 빠르겠죠? 위 내용들을 종합해서 간단하게 머신러닝 모델을 추론하는 파이프라인을 아래와 같이 작성할 수 있었어요.
@dataclass
class WeakRefModel:
model: SomeModel
class MLInferenceShared(DoFn):
def __init__(self, shared_handle, gpu_model="nvidia-tesla-t4", gpu_count=1):
self.shared_handle = shared_handle
self.gpu_model = gpu_model
self.gpu_count = gpu_count
def setup(self):
def initialize_model():
model = SomeModel()
return WeakRefModel(model)
self.model = self.shared_handle.acquire(initialize_model)
def process(self, element):
# 1. Batch로 묶인 여러개의 Element들을 하나의 Tensor로 만듭니다.
batched_tensor = _batched_items_to_tensor(element)
# 2. Model Inference
inference_result = self.model(element)
# 3. Inference 결과 Tensor를 후처리합니다.
result = _postprocess_tensor(inference_result)
yield result
...
shared_handle = shared.Shared()
inferenced = (
raw_data
| beam.BatchElements(min_batch_size=1024, max_batch_size=4096)
| beam.ParDo(MLInferenceShared(shared_handle)).with_resource_hints(
accelerator=f"type:nvidia-tesla-t4;count:1;install-nvidia-driver",
min_ram="16GB",
)
)
Beam에서 ML Inference를 하는 Native한 방법: RunInference
Apache Beam 2.40.0 버전부터는 위에서 설명한 내용들을 신경 쓰지 않고 ML Inference를 수행할 수 있는 RunInference PTransform이 구현되었어요.
기존에는 ML Model을 Apache Beam에서 바로 활용하려면 TensorFlow 모델의 경우 tfx-bsl 패키지에 있는 API를 사용하거나,
앞서 소개한 코드처럼 Shared Class와 BatchElements PTransform을 활용하여 개발자가 직접 DoFn을 구현해야 했죠.
하지만, 2.40.0 버전부터는 Beam에서 공식적으로 제공하는 RunInference API를 통해 PyTorch 모델, TensorFlow 모델, 심지어 Scikit-learn 모델들까지 Beam에서 활용할 수 있어요.
# Model Handler는 외부 저장소로부터 Model을 불러오고,
# Input을 Batching해서 Model Inference를 수행하는 로직을 담당.
model_handler = PytorchModelHandlerTensor(
state_dict_path="path/to/model.pt",
model_class=SomePyTorchModule,
model_params={"some": "args"},
device="GPU",
)
# RunInference는 앞서 구현한 Model Handler를 이용해서 실제로 Inference를 수행.
result = tensors | RunInference(
model_handler=model_handler,
inference_args={"some": "args"},
)
RunInference API는 Model을 Load하고 Input을 원하는 형태로 Batching 하는 로직을 담당하는 ModelHandler와 미리 구현된 Model Handler를 이용하여 실제로 Inference를 수행하는 RunInference PTransform으로 나누어져 있어요.
PyTorch 모델을 사용할 때는 Beam에 미리 구현된 PyTorch 전용 Model Handler를 사용할 수 있어요. PyTorch Model Handler는 아래와 같이 두 종류가 있는데,
PytorchModelHandlerTensor는 RunInference의 Input으로 들어가는 Example의 형태가torch.Tensor, 즉 모델의 Input이 하나일 때 사용해요.PytorchModelHandlerKeyedTensor는 RunInference의 Input으로 들어가는 형태가Dict[str, torch.Tensor]일 때 사용해요. Model의 Input으로input_ids,attention_mask와 같이 여러 개의 Tensor를 넣고 싶을 때 사용할 수 있겠죠?
이외에도 TensorFlow Model을 사용하고 싶으면 tfx_bsl에 구현된 ModelHandler를 사용할 수 있고, Custom하게 구현한 다른 ML Framework을 사용하고 싶으면 ModelHandler를 상속해서 직접 구현할 수도 있어요.
RunInference Transform은 아래와 같이 PredictionResult라는 이름의 NamedTuple을 반환합니다. example에는 Model의 Input으로 사용한 Tensor가 담기고, inference에는 모델 추론 결과가 담겨요.
# Result
>>> result | beam.Map(print)
PredictionResult(
example=Tensor(<some_input_tensor>),
inference=Tensor(<inferenced_result>),
)
만약, RunInference의 Input으로 Tensor가 아니라 Tuple[str, Tensor]와 같이 해당 Element의 고유한 Key 값을 유지하고 싶다면 앞서 구현한 Model Handler를 아래와 같이 KeyedModelHandler로 Wrapping해서 사용할 수 있어요.
# Input is like: ("key", torch.Tensor(<some_tensor>))
result = tensors_with_key | RunInference(
model_handler=KeyedModelHandler(model_handler), # <--- KeyedModelHandler
inference_args={"some": "args"},
)
# Result
>>> result | beam.Map(print)
("key", PredictionResult( # <--- Output with key
example=Tensor(<some_input_tensor>),
inference=Tensor(<inferenced_result>),
))
RunInference로 Input Batching하기
RunInference는 기본적으로 Shared Class와 BatchElements PTransform을 통해 Model Inference를 수행하는 패턴을 Wrapping한 PTransform이에요. 그렇기에 기본적으로 PTransform 내에서 Input을 BatchElements PTransform으로 Batching을 하고, ModelHandler에 구현된 run_inference() 함수를 실행해요. BatchElements는 처리 속도에 따라 Batch Size를 자동으로 조절해주며, min_batch_size와 max_batch_size를 통해 최대/최소 크기를 지정해줄 수 있었죠? 공식 가이드에 따르면 ModelHandler에서는 클래스의 batch_elements_kwargs()를 아래와 같이 오버라이딩해서 Batch의 크기를 똑같이 조절할 수 있어요.
class PytorchNoBatchModelHandler(PytorchModelHandlerKeyedTensor):
def batch_elements_kwargs(self):
return {"min_batch_size": 1024, "max_batch_size": 4096}
Apache Beam 2.43.0 기준, 이렇게 Batching된 Element들은 ModelHandler의 run_inference()함수로 들어가게 되고, 구현체를 보면 아래처럼 Tensor의 List들을 torch.stack()을 통해 Batched Tensor로 만든 후, Model의 Input으로 넣어주고 있어요.
def run_inference(
self,
batch: Sequence[torch.Tensor],
model: torch.nn.Module,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
...
inference_args = {} if not inference_args else inference_args
# torch.no_grad() mitigates GPU memory issues
# https://github.com/apache/beam/issues/22811
with torch.no_grad():
batched_tensors = torch.stack(batch) # <--- Where Batched Tensor is made
batched_tensors = _convert_to_device(batched_tensors, self._device)
predictions = model(batched_tensors, **inference_args)
return _convert_to_result(batch, predictions)
Batch 내 Tensor의 Size가 모두 동일한 경우에는 문제가 없지만, Language Model을 사용할 때의 상황을 생각해보면 Tensor들의 Size가 문장의 길이에 따라 달라지는 경우 torch.stack이 아닌, pad_sequence처럼 Custom한 Padding 로직을 집어넣어야 해요. 공식 가이드에서는 이런 경우 Batch Size를 1로 설정하라고 안내하고 있지만, GPU의 Utilization을 매우 떨어뜨려서 파이프라인의 성능을 저하시키게 되죠! 이를 해결하기 위해 아래와 같이 PyTorch Model Handler를 상속해서 run_inference에서 직접 Padding하는 로직을 넣어줄 수 있어요.
class CustomPyTorchModelHandler(PytorchModelHandlerKeyedTensor):
...
def run_inference(
self,
batch: Sequence[Dict[str, torch.Tensor]],
model: torch.nn.Module,
inference_args: Optional[Dict[str, Any]] = None,
) -> Iterable[PredictionResult]:
inference_args = {} if not inference_args else inference_args
with torch.inference_mode():
# Model features (torch.nn.utils.rnn의 pad_sequence를 예시로 사용합니다.)
inputs = pad_sequence([features["input_ids"] for features in batch], batch_first=True, padding_value=0)
# To device
inputs = _convert_to_device(inputs, self._device)
# Inference
predictions = model(inputs, **inference_args)
# Inference Result to Apache Beam Compatable Results
return [PredictionResult(inputs, logit) for logit in predictions]
이 글을 작성하는 시점에는 Apache Beam Repo의 master Branch에 머지된 Pull Request들 중, 위 방법과 같이 상속을 하지 않고도 Custom한 Inference 로직을 주입시킬 수 있도록 구현한 Add custom inference function support to the PyTorch model handler #24062 Pull Request를 찾을 수 있었고, 추후 2.44.0, 또는 그 이후 버전 릴리즈 이후부터는 아래와 같이 Custom Inference Logic을 넣어줄 수 있을 것으로 보여요.
model_handler = PytorchModelHandlerTensor(
state_dict_path="path/to/model.pt",
model_class=SomePyTorchModule,
model_params={"some": "args"},
device="GPU",
inference_fn=custom_batching_logic, # <--- Custom Inference Logic
)
위 내용을 종합하면, 아래 코드와 같이 PyTorch Model을 사용하여 Inference를 하는 파이프라인을 작성할 수 있어요.
model_handler = PytorchModelHandlerTensor(
state_dict_path="path/to/model.pt",
model_class=SomePyTorchModule,
model_params={"some": "args"},
device="GPU",
inference_fn=custom_batching_logic, # 추후 릴리즈에서 변경 가능성이 있어요!
)
with beam.Pipeline() as p:
texts = (
p
| "ReadSentences" >> beam.io.ReadFromTextWithFilename("path/to/input.txt")
| "PreprocessTexts" >> beam.ParDo(Preprocess())
)
processed = (
texts
| "Tokenize" >> beam.ParDo(RunTokenizer(pretrained_path))
| "RunInference"
>> RunInference(KeyedModelHandler(model_handler)).with_resource_hints(
accelerator=f"type:nvidia-tesla-t4;count:1;install-nvidia-driver",
min_ram="16GB",
)
| "Postprocess" >> beam.Map(lambda x: (x[0], postprocess(x[1].inference)))
)
(
processed
| "DropFilename" >> beam.Map(lambda x: x[1])
| "WriteOutput" >> beam.io.WriteToText("path/to/output.txt")
)
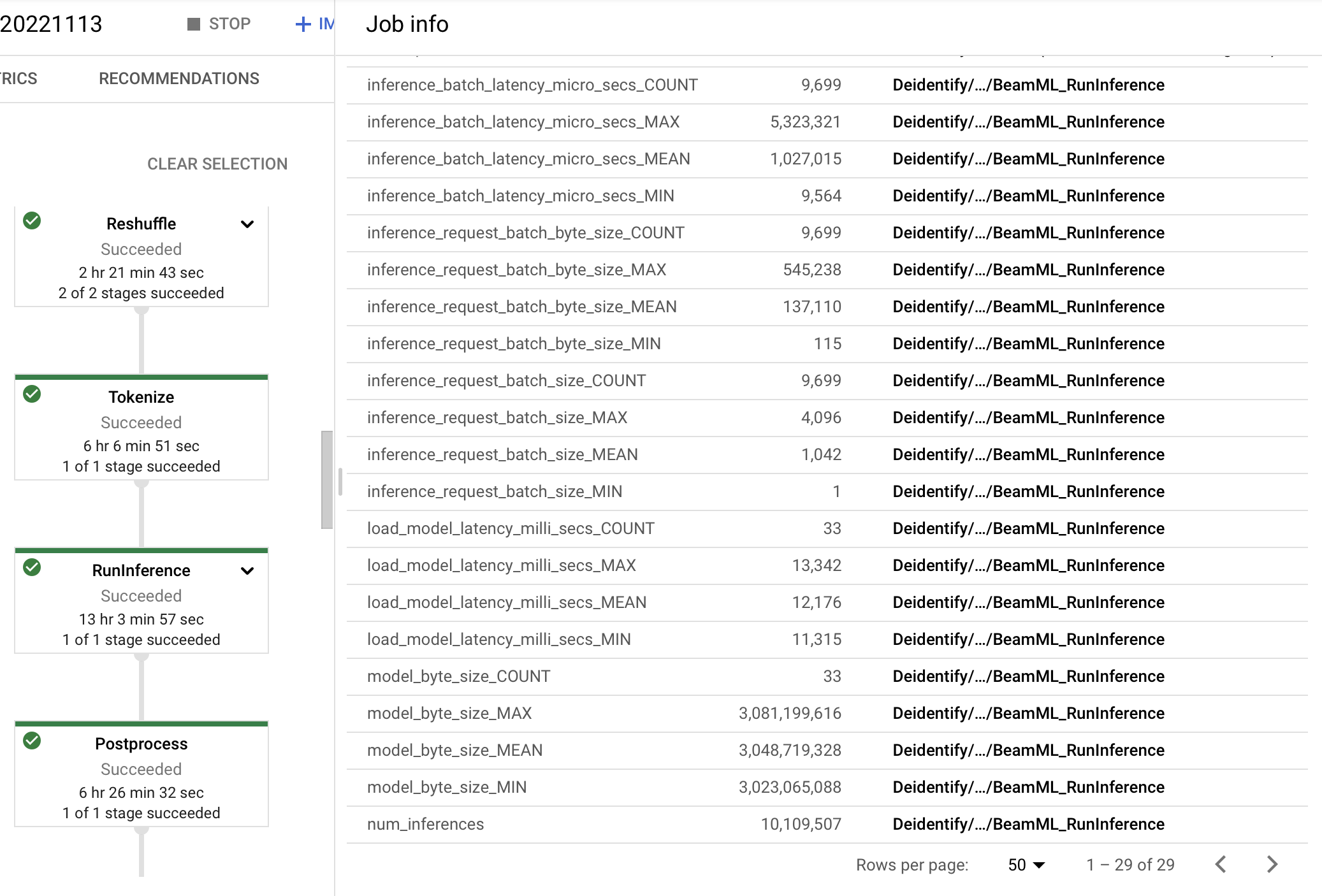
RunInference는 Model Inference와 관련된 metric들을 남기고 있기 때문에, Dataflow를 활용한다면 아래와 같이 파이프라인의 오른쪽 Panel에서 Model의 Input으로 들어가는 평균 Batch Size는 몇인지, Model에 Inference하는데 걸린 시간은 평균적으로 얼마나 걸렸는지 손쉽게 확인할 수 있어요!
마치며
지금까지 Apache Beam의 RunInference API를 이용해서 손쉽게 Bulk Inference Pipeline을 작성하는 방법을 알아보았어요. 이렇게 만든 Bulk Inference Pipeline은 조직 내에서 다양하게 사용될 수 있어요! 사내의 대규모 데이터셋들을 GCP의 Dataflow를 사용하여 주기적으로 Preprocessing하는 파이프라인을 만들 수도 있고, ML Model을 Production에 보내기 전 평가용 데이터셋으로 Inference를 수행하여 모델의 정량평가 결과를 빠르게 확인할 수도 있어요. 이제는 RunInference PTransform으로 모든 ML Inference 관련 로직들이 추상화되었기 때문에 PyTorch, TensorFlow와 같은 ML Framework를 사용할 줄만 안다면 손쉽게 Scalable 한 ML Inference 파이프라인을 구축할 수 있어요!
MLOps의 여러 복잡한 문제들을 저희와 함께 풀어보고 싶으시다면, 언제든 채용 공고를 참고해주세요! 🚀
참고할 만한 페이지들
- Apache Beam ML 공식 문서
- Beam Summit 2022 - RunInference
- apache/beam GitHub Repository, RunInference Examples
- RunInference Documentation
- Google Cloud - Integrating ML models into production pipelines with Dataflow